-
-
Homepage of the Product
-
Login Page
-
Dashboard (Default Page after Login) with Saved Players
-
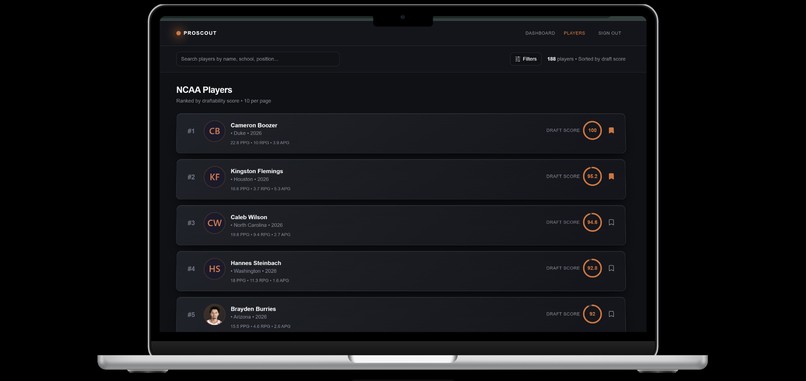
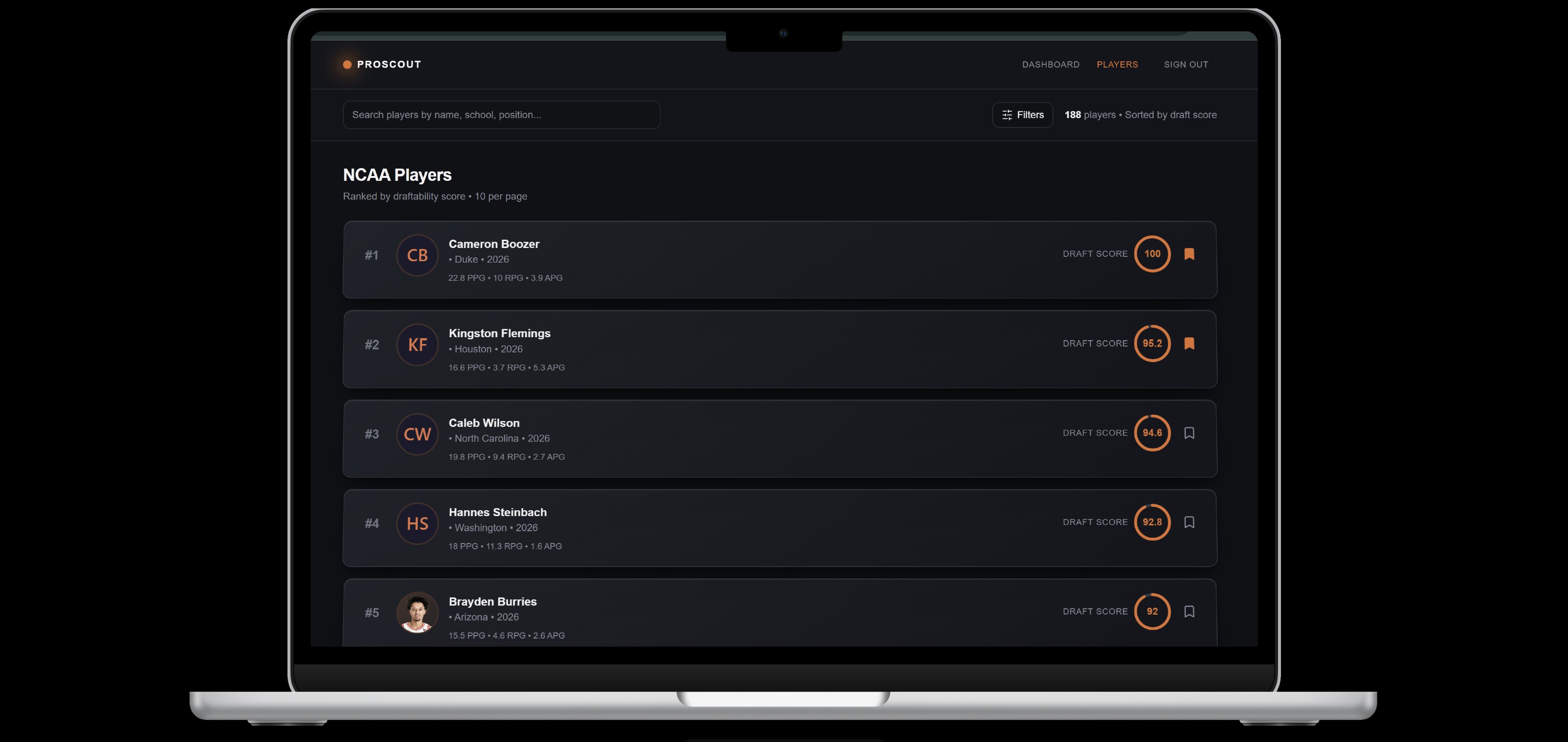
All Players Page
-
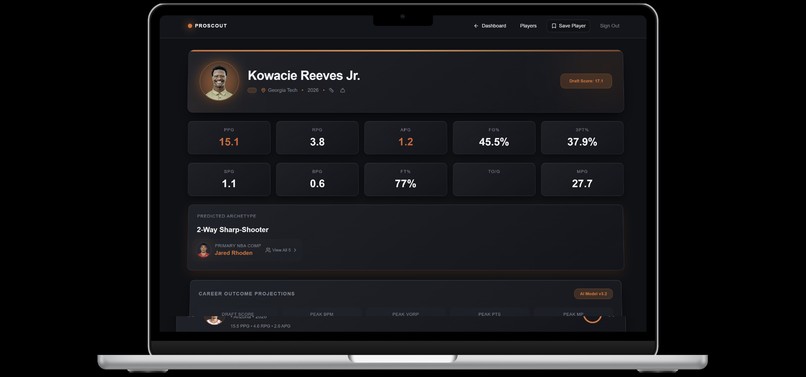
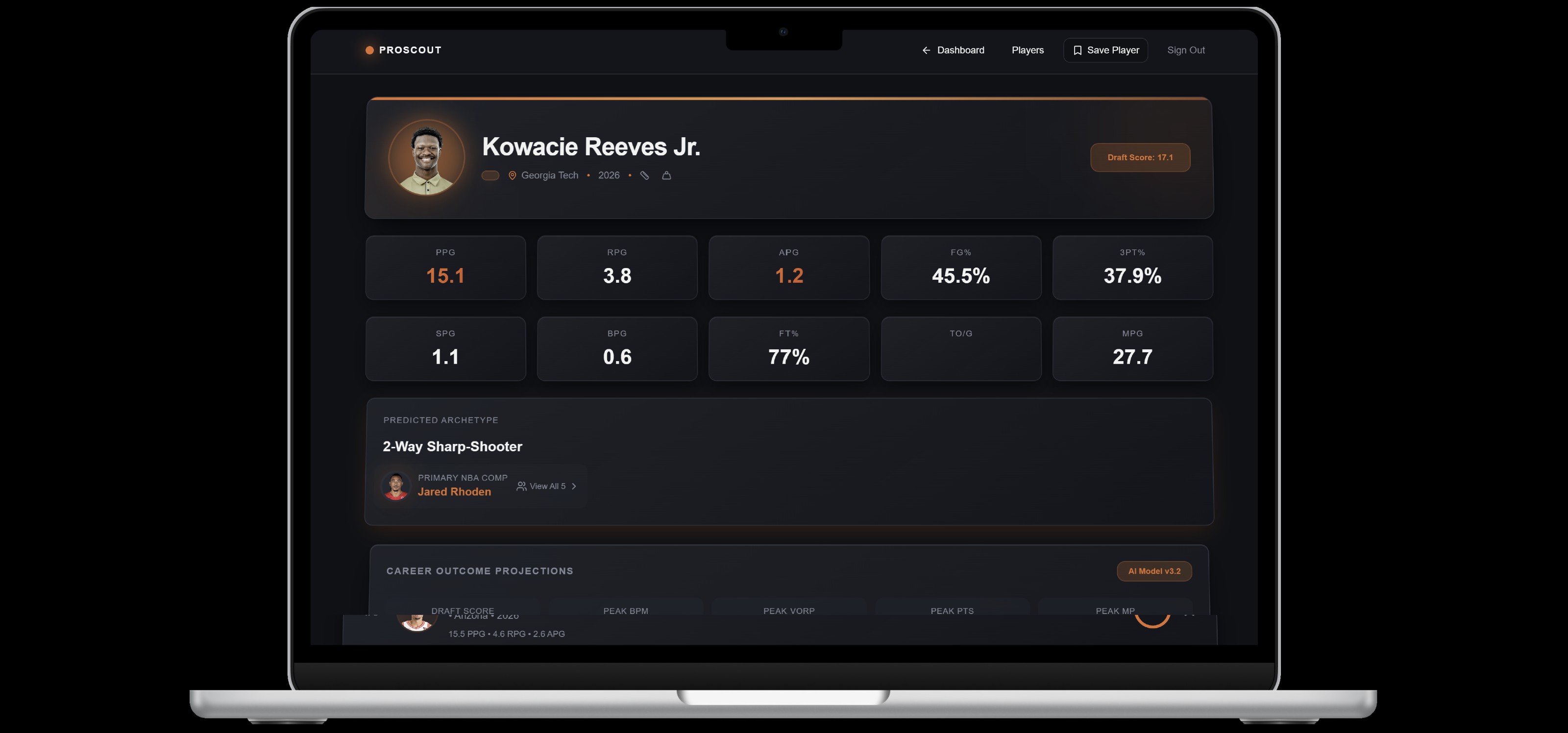
Specific Profile Player Page (scroll down for more stats)
-
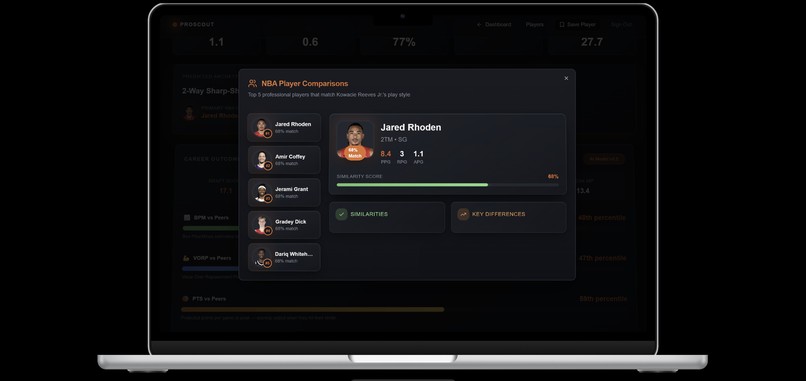
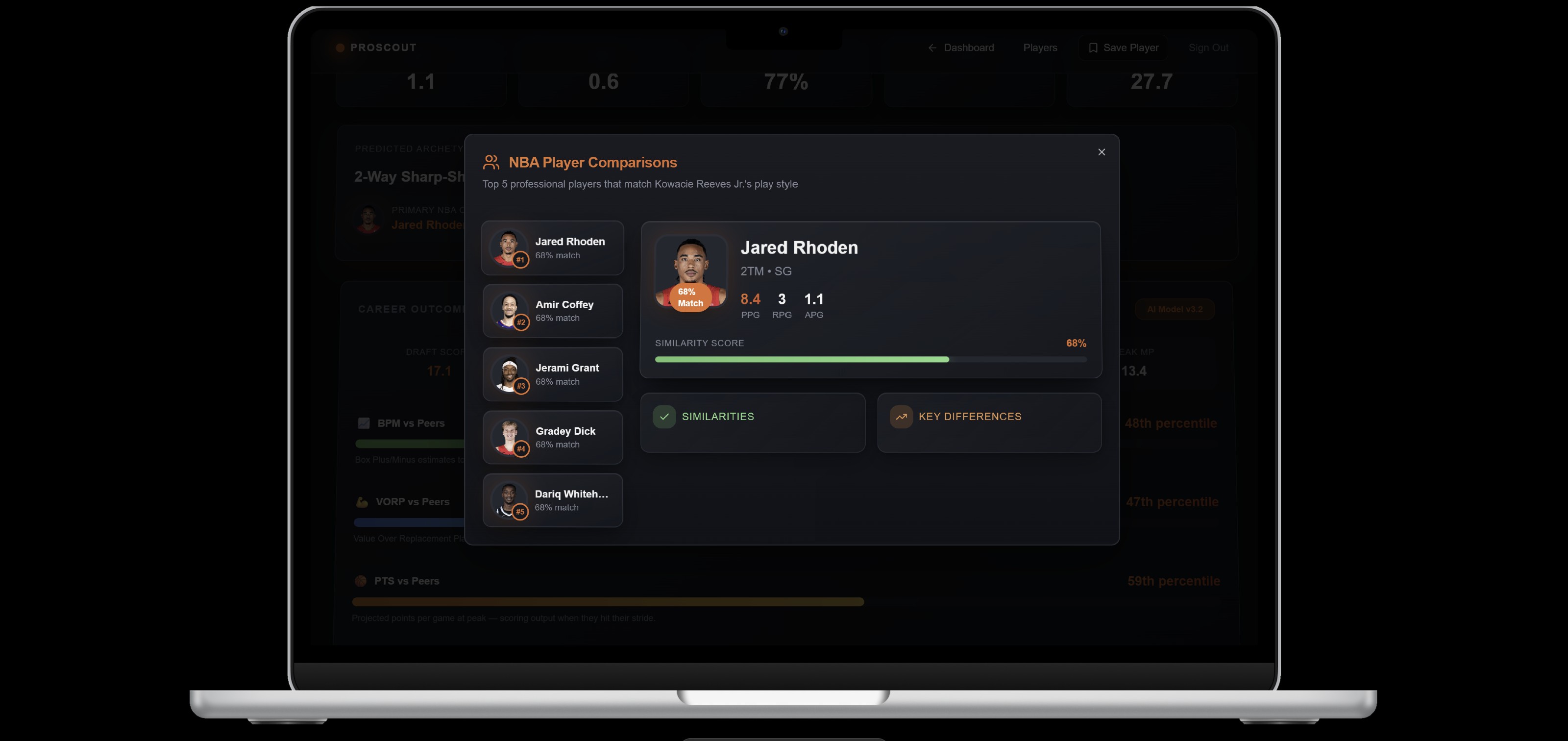
NBA Comparisons Example Page
-
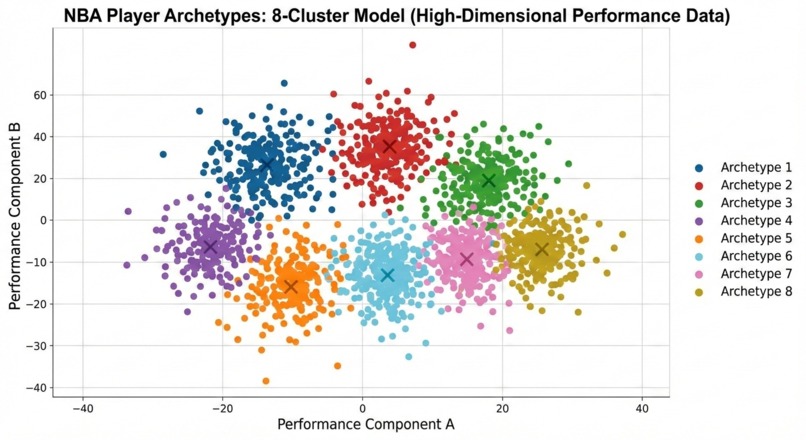
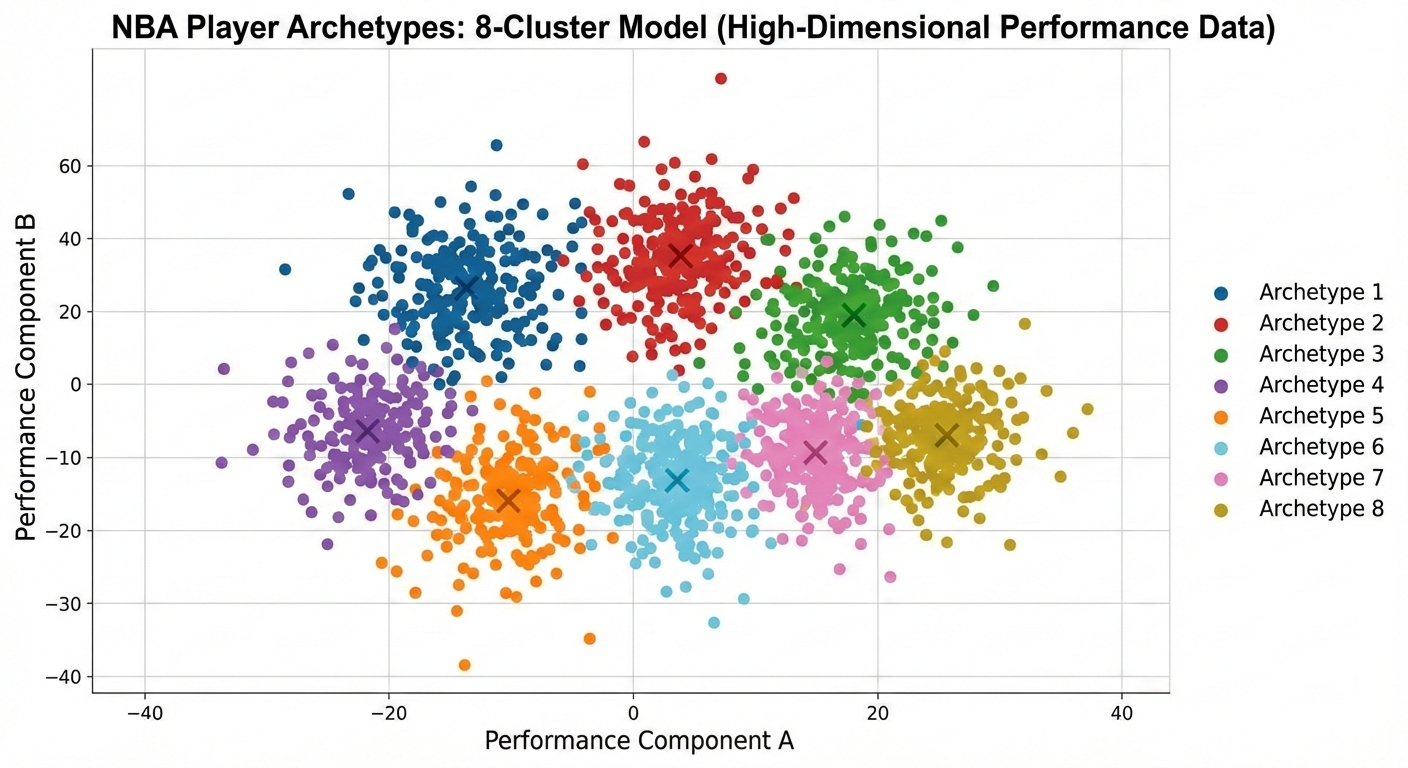
K-Means clustering is a tool to organize data into groups. We used high-dimensionality k-means clustering to group player archetypes.
-
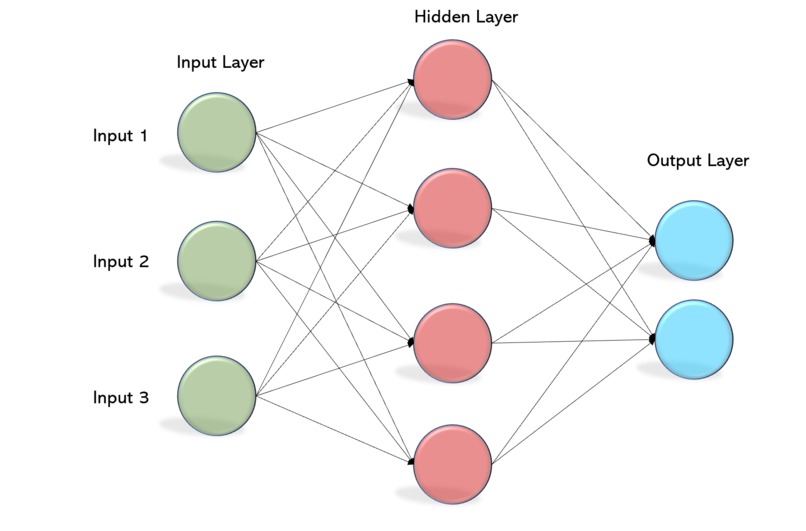
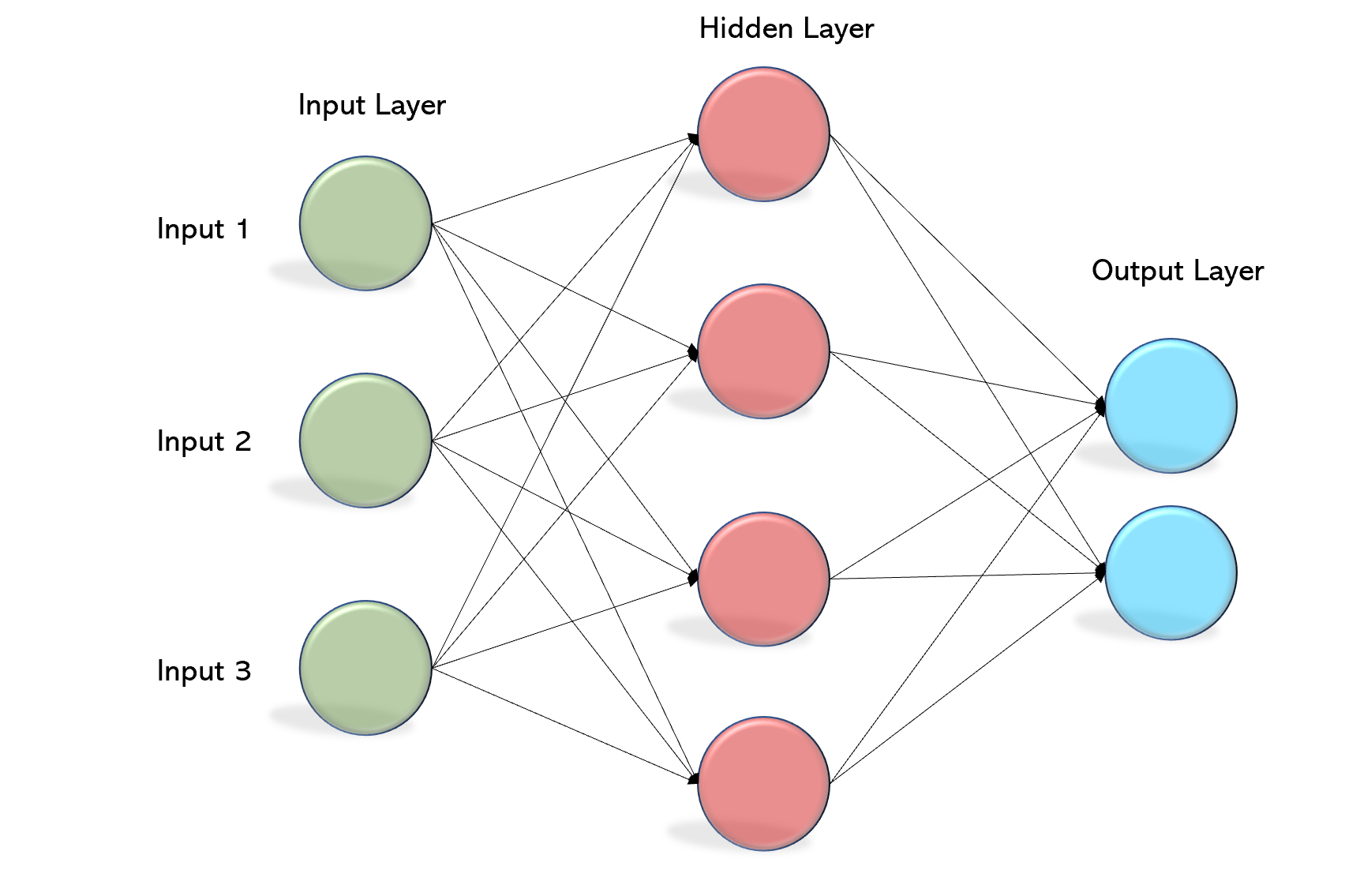
An MLP processes inputs through layered connections to learn patterns and produce a prediction.
-
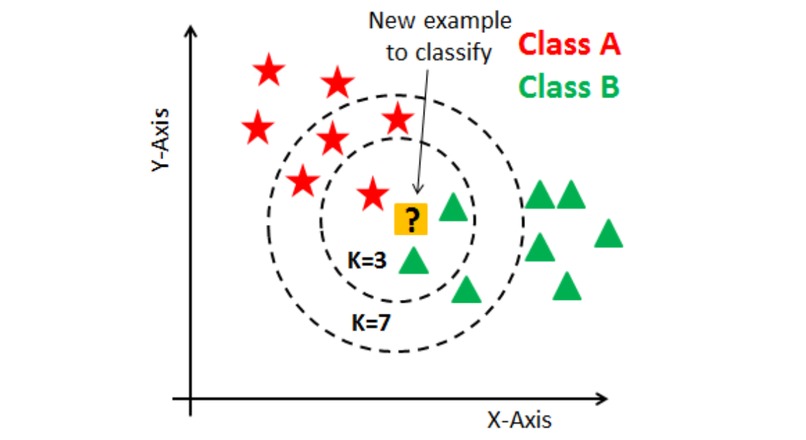
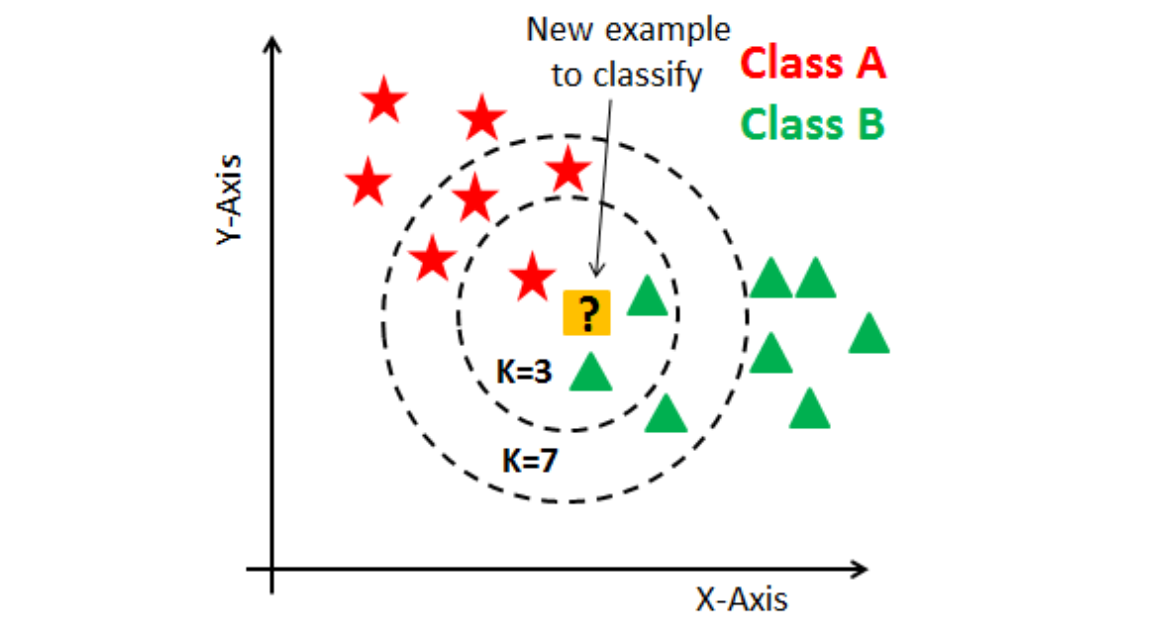
KNN compares a point to its closest neighbors and assigns it the class most common among them.
Inspiration
Research from MIT’s Schwarzman College of Computing shows that investment in data analytics directly translates to competitive advantage in the NBA. Their findings indicate that for every 0.8 of a data analyst added to a team’s staff, a team gains approximately one additional win per season. That marginal win corresponds to an estimated $9.6 million increase in roster salary value. Analytics is not simply a back-office function. It is a measurable performance multiplier with direct financial impact.
At the same time, NBA draft picks represent some of the league’s most expensive guaranteed assets. Top selections often command rookie-scale contracts exceeding $8–$13 million annually, totaling $40–$60 million over four years. These contracts are fully guaranteed, meaning teams assume substantial financial risk before a player has proven themselves at the professional level.
Despite the financial stakes, the NBA draft process remains heavily influenced by subjective scouting, eye tests, and inconsistent statistical evaluation. While traditional scouting is invaluable, it often lacks systematic models that translate college performance into projected NBA outcomes.
We built ProScout to bridge data science with basketball intuition. Our goal is to reduce uncertainty in one of the most financially consequential decisions in professional sports by transforming historical college-to-NBA data into structured, predictive intelligence.
What it does
Data and Machine Learning
ProScout is a predictive analytics platform that generates a complete scouting profile for NCAA players.
It produces:
A Draftability Score using a Multi-Layer Perceptron (MLP) trained on historical college-to-NBA outcome data
Comparable players using K-Nearest Neighbors (KNN)
Archetype classifications using K-Means clustering
By combining prediction, similarity modeling, and role identification, ProScout delivers both quantitative forecasts and interpretable insights.
User Interface
The frontend enables users to:
Search players by name or school
View projections, comparable players, archetypes, and season statistics
Explore interactive player profiles
A login system allows users to save and track players, creating a personalized scouting dashboard tailored to individual evaluation needs.
How we built it
We built ProScout as a full-stack application using Flask for the backend and React for the frontend.
We aggregated and cleaned NCAA (2009–2021) and NBA datasets, engineered features to align college and professional metrics, and trained an MLP to map college statistics to projected NBA outcomes. KNN was implemented for similarity modeling, and K-Means clustering was used to define role archetypes.
Our backend stack includes Python, pandas, numpy, scikit-learn, and TensorFlow. The trained models are exposed through a Flask API, which the React frontend consumes dynamically to display projections and player insights in real time.
Challenges we ran into
One of the most significant challenges was translating college performance into meaningful NBA projections. This required careful feature selection, normalization, and alignment across leagues with different play styles and statistical distributions.
We also encountered inconsistent naming conventions and missing data across sources, requiring extensive cleaning and reconciliation. Integrating the frontend and backend while maintaining responsiveness and clarity of complex model outputs was another key technical hurdle.
Accomplishments that we're proud of
Within a hackathon timeframe, we built a complete machine learning pipeline and full-stack application capable of projecting NBA outcomes from college data.
By combining MLP for prediction, KNN for interpretability, and K-Means for structural role classification, we created a system that produces realistic comparisons and actionable archetypes. We paired this with an intuitive frontend that translates complex analytics into accessible, decision-ready insights.
What we learned
We learned that different models serve distinct and complementary roles:
MLP for predictive performance
KNN for transparency and comparability
Clustering for structural understanding
We also reinforced the importance of high-quality data, thoughtful feature engineering, and scalable architecture when building applied machine learning systems. Most importantly, we learned that powerful analytics must be paired with clear, intuitive design to be truly usable.
What's next for ProScout
We plan to integrate real-time inference from gameplay footage, enabling automated feature extraction such as heatmaps, movement tracking, and spatial positioning analysis.
In the long term, we aim to expand our longitudinal modeling to track player development from college through the NBA, combining statistical and video-based insights to continuously refine how skills translate across levels of competition.
ProScout’s vision is to evolve from a draft evaluation tool into a comprehensive player development intelligence platform.

Log in or sign up for Devpost to join the conversation.