-
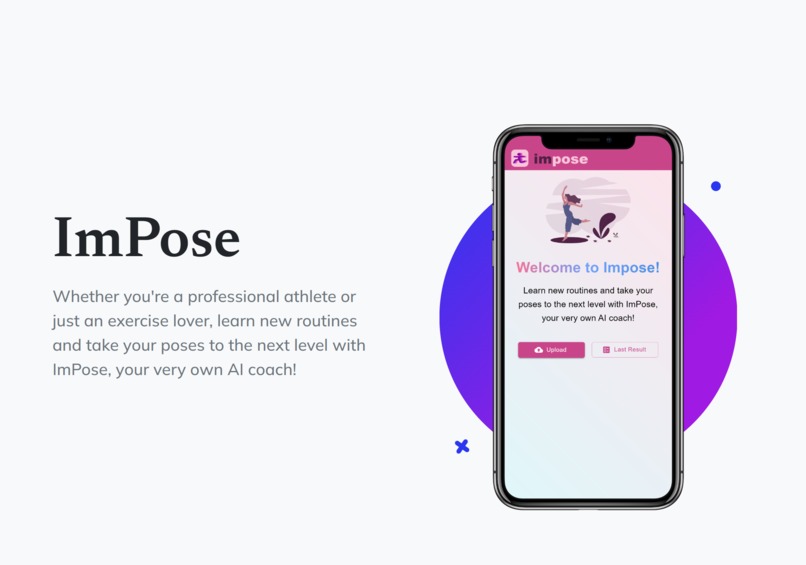
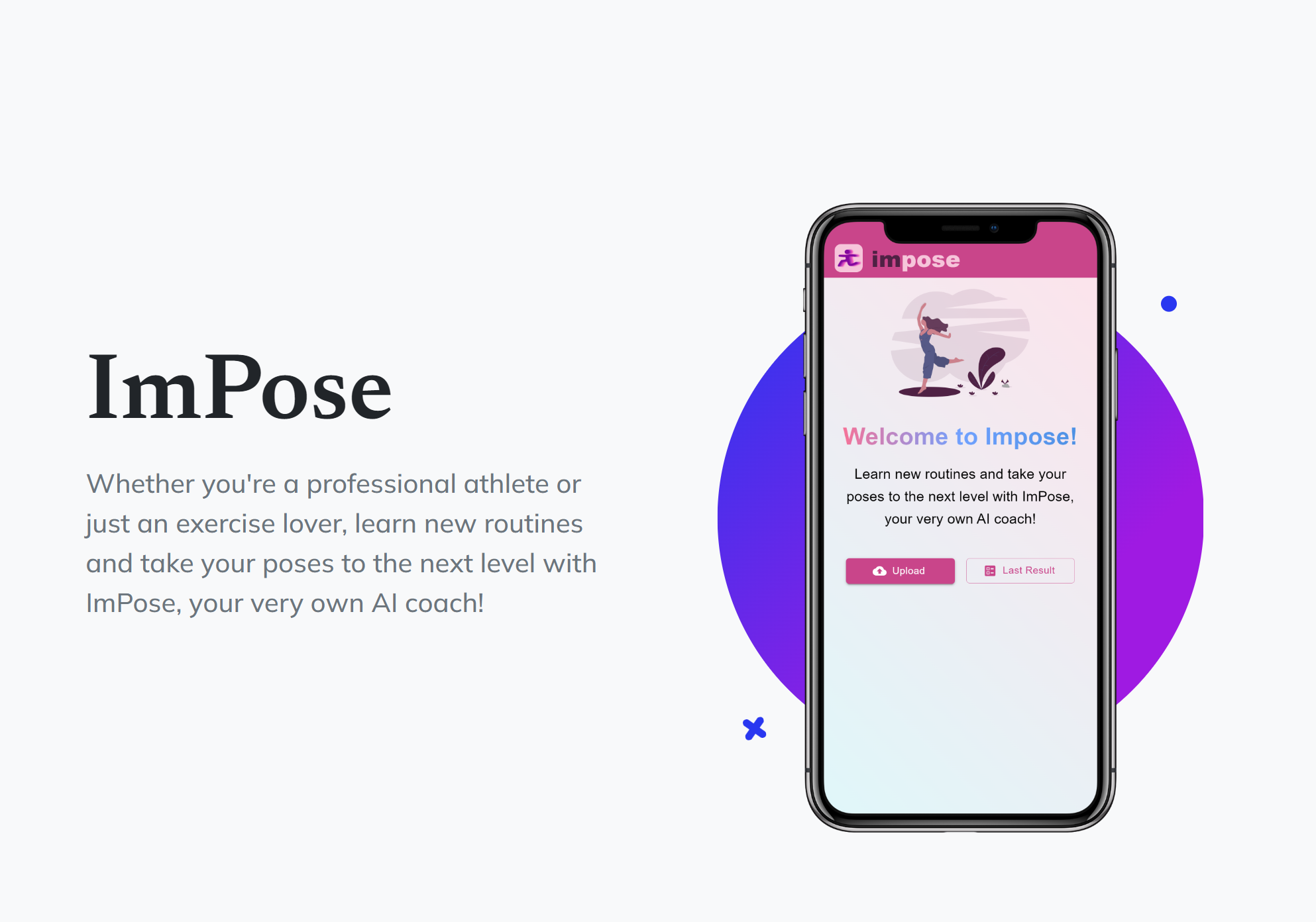
ImPose is a mobile app compares your poses and routines to an expert demo, with the help of AI
-
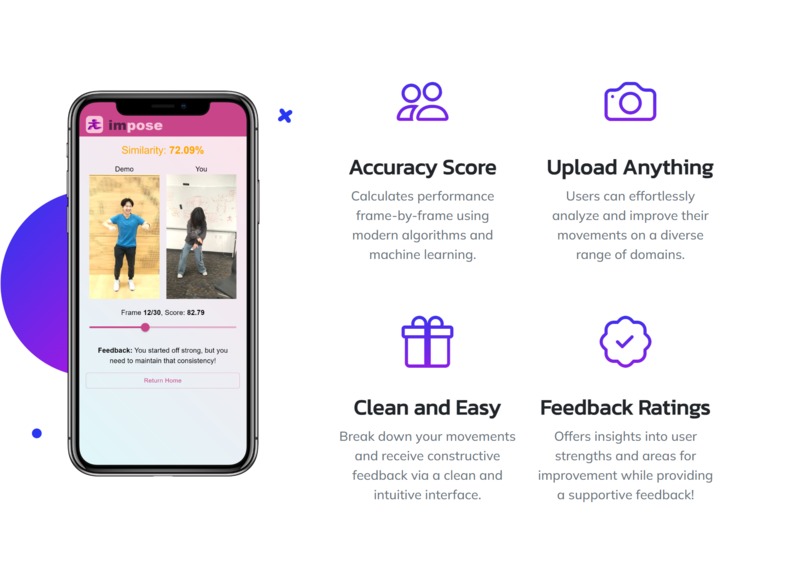
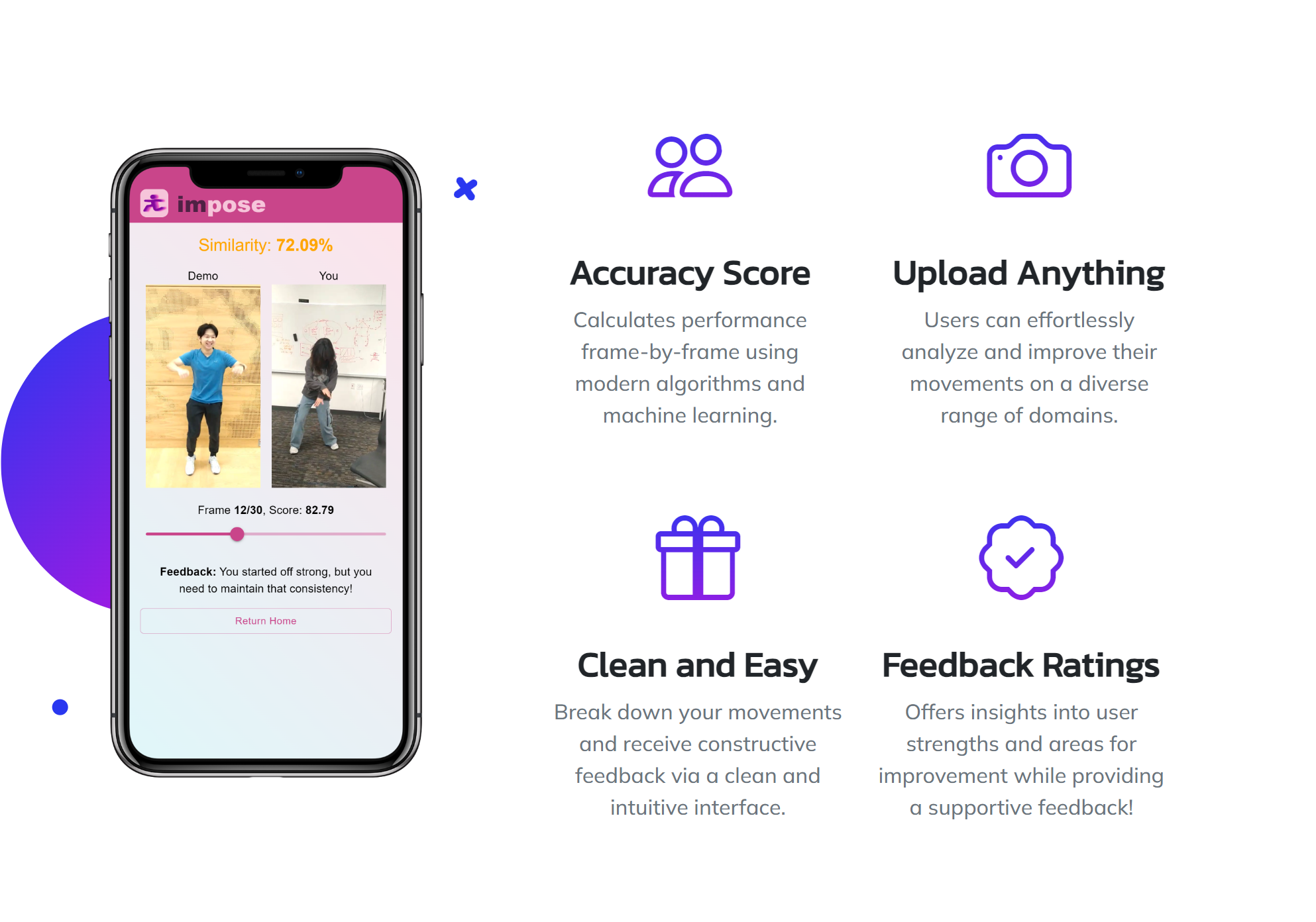
ImPose offers a variety of features to help take your aesthetics and performance to the next level
ImPose 🔥
Whether you're a professional dancer, yoga hobbyist, or just someone who wants to learn some new moves, do you find tutorials too daunting and hard to follow? Are you unsure whether you're executing a move correctly? Don't worry, learn new routines and take your poses to the next level with ImPose, your very own AI coach!
Our team members come from a variety of sports and exercise backgrounds, including tennis, martial arts, ice skating, basketball, and dance. Many of these areas are challenging to self-learn because it's difficult to correct your moves yourself: it's hard to look at an image or video of yourself and see what's wrong, especially when in motion. Thus, we introduce ImPose: a mobile app compares your poses and routines to an expert demo, with the help of AI.
ImPose gives personalized feedback on both picture-to-picture comparison and video-to-video comparison. Our algorithmic design ensures that our video comparison is robust to varying speeds of motions in the videos (see below).
Example applications:
- Learning new dance moves
- Learning new yoga poses
- Correcting sports form (tennis serve, basketball shot, etc.)
- ... And much more!
Technology 🤖
Technology Stack
- Tensorflow: Vision models for pose estimation
- React JS: User interface framework
- Material UI: Styling library
- Ionic Capacitor: Builds our React code into cross-platform native code (Java for Android and Swift for iOS)
Inference Pipeline
We take input from your demonstration and the expert demonstration, and extract body keypoints by passing the images/frames through Tensorflow MoveNet.
We pre-process and normalize keypoints, and then calculate your score for different body parts using cosine similarity with the expert.
For video sequences, compute pairwise similarities between frames from the two videos, and use Dynamic Time Warping to find the optimal time matching between the two sequences. This allows our video comparison to be robust to temporal differences; for example, the expert being slower or faster for some move will not cause the whole sequence to be offset.
Use a data-driven approach to provide personalized feedback on image poses or video routines.
Challenges ⛰️
Challenges we overcame as a team
- Converting formats between the Capacitor API for media upload and formats accepted by the Tensorflow API
- Debugging our math equations and algorithm implementations
- Passing image/video data from our upload page to our results page
Challenges where we gave our best but could not solve in time
- Streaming functionality for live pose estimation
- Custom optimization of our pose comparison and dynamic time warping algorithms, for faster inference time
- Getting sleep 😭
Accomplishments 🚀
- Accurate and compelling similarity scores between individual pictures/frames
- Successful optimal frame matching between video sequences
- We learned some new dance moves in the process!
What we Learned ❤️
First and most importantly, this experience again reminded us that teamwork is so important! Each member of our team contributed to an important part of the idea, whether in our creative process, algorithmic design, or implementation.
We've also helped each other improve our skills noticeably throughout our day together. For example, part of our team had little prior coding experience, but under the help of others on the team, was able to make changes to our React infrastructure by the end of the day. Another part of our team had little prior design experience, but learned a lot about color theory and UI design during our collaboration.
This is also the first time anyone on our team has worked with Tensorflow (in any language), which was a very exciting and humbling experience.
Future Work 👀
- Allow for live streaming based on a demo picture or video
- Live to picture: Replicate a pose over a live camera feed, and save the frames where you're closest to perfect!
- Live to video: Follow along with an expert demonstration in real time and see how you compare!
- Get frame-specific feedback on videos
- Account for camera calibration with linear algebra; we already normalize our inputs, but notice that inconsistencies among different cameras still cause for minor inaccuracies
- Optimize the algorithmic efficiency of video comparisons, and thus support longer video lengths
Built With
- capacitor
- css
- javascript
- material-ui
- react
- redux
- tensorflow







Log in or sign up for Devpost to join the conversation.