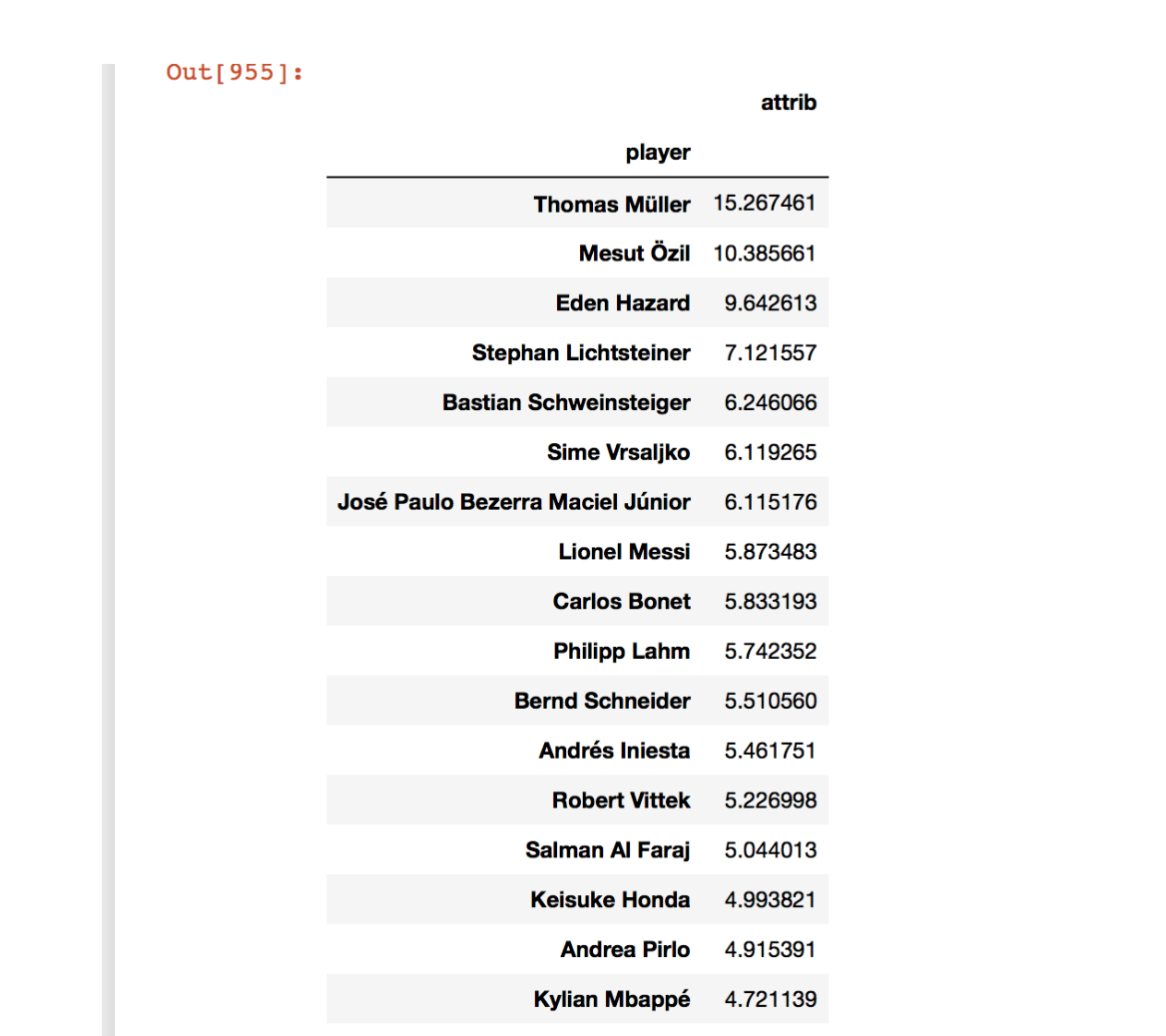
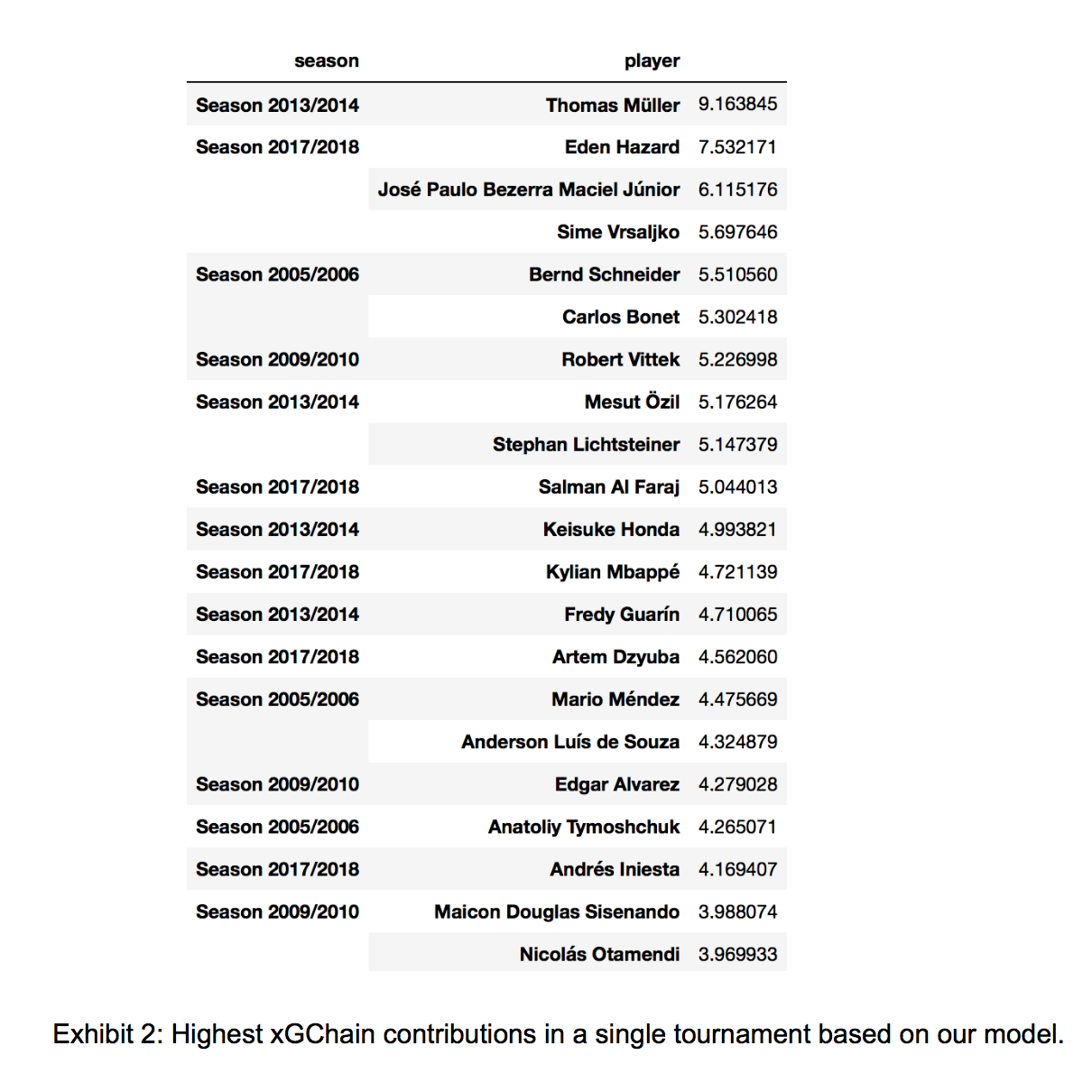
xgChain is a great tool for obtaining the probability distribution for passing sequences. However, xgChain models just assign the expected Goals value of a passing sequence to every player involved in that sequence regardless of the quality of their contribution. We disaggregated the passing sequence into a series of events and obtained an importance value for each discrete part of the sequence. Using these importances we attributed the xG value of a shot to each player involved in the sequence instead of assigning the entire xG value to each player involved in the sequence.
Variables in the model:
Long_ball Cross Head_pass Through_ball Attacking_pass Chipped Launch Flick_on Pull_back Switch_of_play Pass_end_x Pass_end_y Take_ons Big_chance Event_type
Variables from 1 to 13 were aggregated by passing sequence.
In order to extract passing sequences we looked at the event sequences which ended in a shot. From there we isolated distinct passing sequences by collecting row numbers where the teamid switched. Using these row numbers, we subsetted the original dataset leaving us with a dataframe containing passing sequences ending in shots. We extracted some features to describe these passing sequences. Using these we built a classification model to predict the probability of a passing sequence resulting in a ‘big chance.’ We obtained the importance of each feature in the sequence in predicting the probability. These feature importances were propagated back to each discrete step in the passing sequence and thus we obtained the contribution of each player involved in the sequence. We aggregated the xgChain contribution of each player in the World Cup listed in the data made available for this competition.
Inspiration - Sleep deprivation, excessive caffenation. But the primary reason was attribution of same xG score to each player involved in a passing sequence. This is the current state of the art method employed by clubs all across the globe and it constricts appropriate measure of player evaluation, by treating each player to be equally valuable within a passing sequence. Further, we also wanted to explore what features ensure that a passing sequence will lead to a “big chance” which in-turn has a high probability of being a goal scoring opportunity.
What it does: Apportions the xG value of a shot to each player involved in the sequence fairly. Each player contributes to a passing sequence in a different way. Our classification model gave us an importance score for each contribution. The weighed importance of that contribution was used to attribute the xG contribution for the player who made it.
How we built it
It first builds sequences of passes that lead to shots, which can be ‘regular’ or ‘big chances’ We then extracted the features from each sequence, which accurately summarized the sequence We used that information to build a classification model. (Dependent variable - binarized ‘big_chance’ From the machine learning model we obtained probabilities of a passing sequence leading to a big chance outcome Depending on the features available in each passing sequence we were able to attribute the importance of each feature available in each passing sequence to the eventual outcome These feature importances were propagated back to each distinct step in the passing sequence based on the weighted score of importances
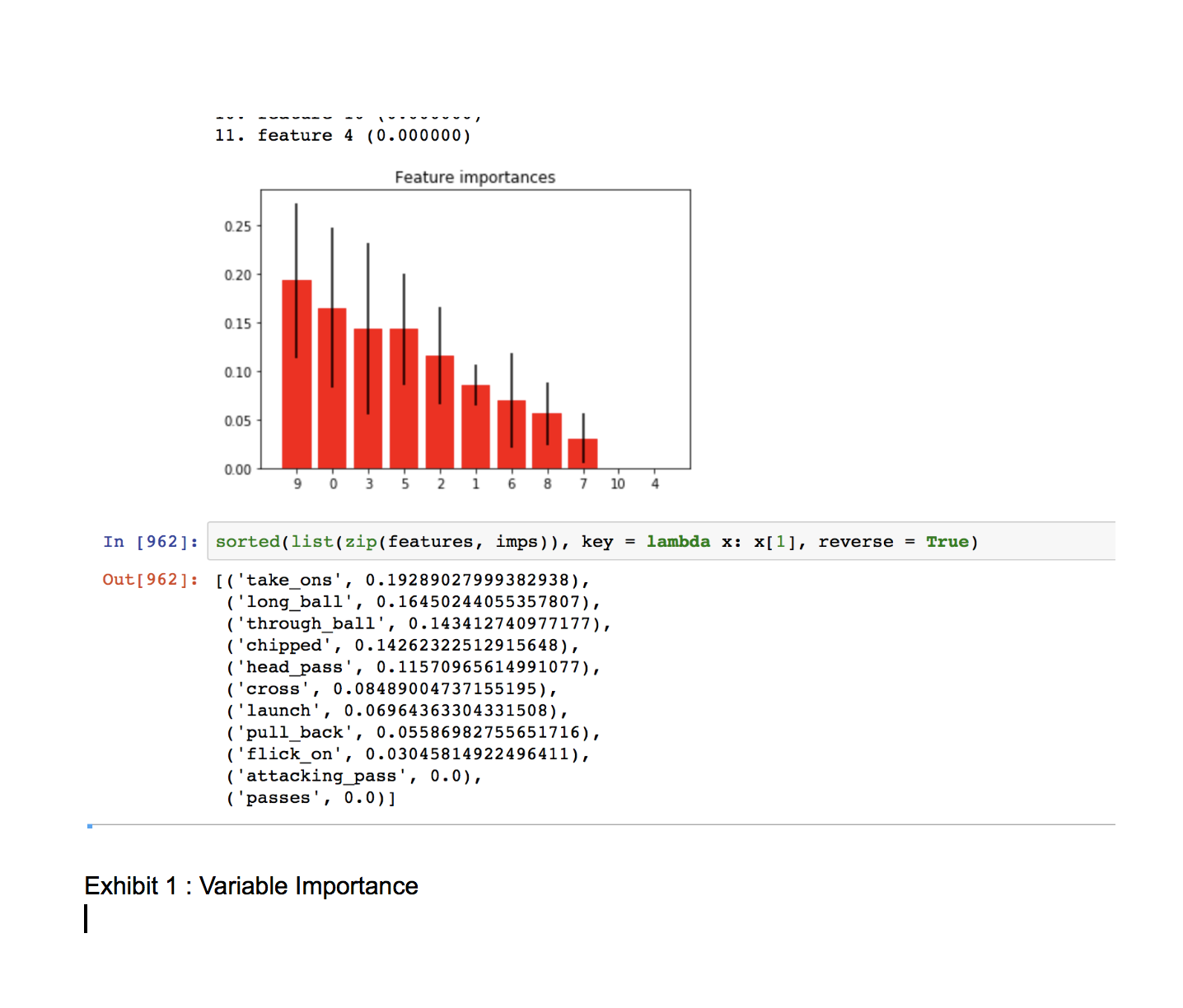
We obtained a fairly high accuracy rate of 93% in predicting if a sequence will lead to “big_chance”. This accuracy rate was achieved through Random Forest algorithm.
Further, we wanted to benchmark our model across other machine learning algorithms as well. Extreme Gradient Boosting was the next algorithm on our list, however even after employing exhaustive brute force grid search, we were unable to obtain better results as compared to our earlier algorithm.
Challenges we ran into
There were numerous challenges we ran in to: Firstly, obtaining the passing sequence was a huge challenge as it was not easily extractable from the data set. We had to build some logic around grouping these sequences then extracting the data into a subset. The dataset had a large amount of field which were rarely used or poorly documented. We relied heavily on the USSF staff to explain or explore how each field was being built. Some of the original ideas we had for the project were limited by having only data related to World Cup and MLS rather than the entire universe of club teams.
What's next for Possible improvement to the xGChain model
As the dataset for MLS and World Cup are formatted similarly the analysis and code can be applied to the MLS dataset easily. Due to time constraints were not able to do this.
Results:
The chart below gives us a comparison of the features we used in our machine learning algorithm. Using the importance of variables and the predicted probability values we were able to formulate a new method to assign xG scores to the players.
Built With
- jupyter-notebooks
- pandas
- python
- r
- scikit-learn


Log in or sign up for Devpost to join the conversation.