Inspiration
LLMs are capable of many things... But... Are they capable of predicting the future? In predictive events like "What will Fed funds rate in May be?" (seen commonly in predictive markets like Kalshi), data sources are often noisy and strategic. The question is then is, Compared with humans, how well can LLMs collect and distinguish from these noisy data sources, and how well do they predict the outcomes?
What it does
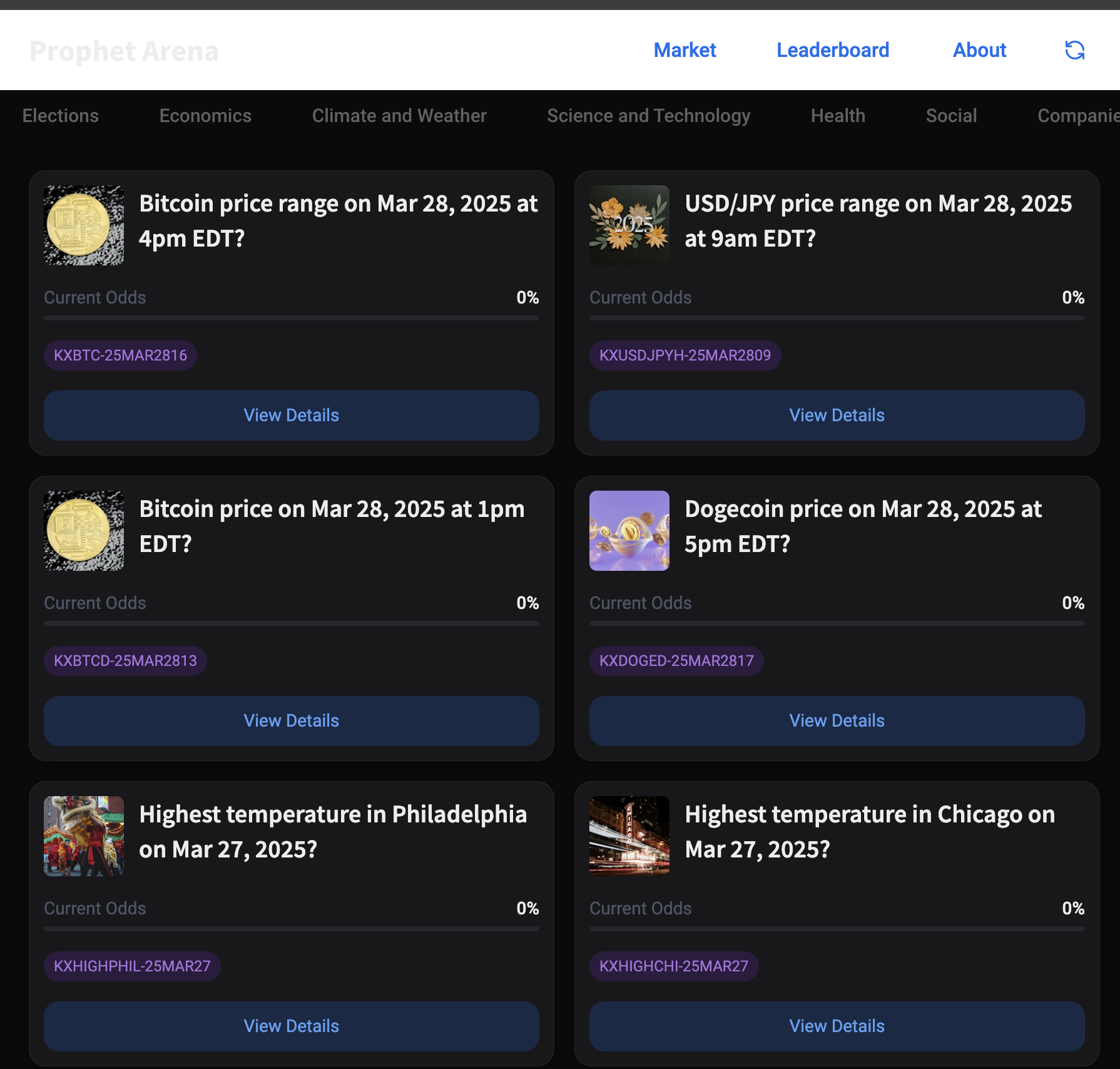
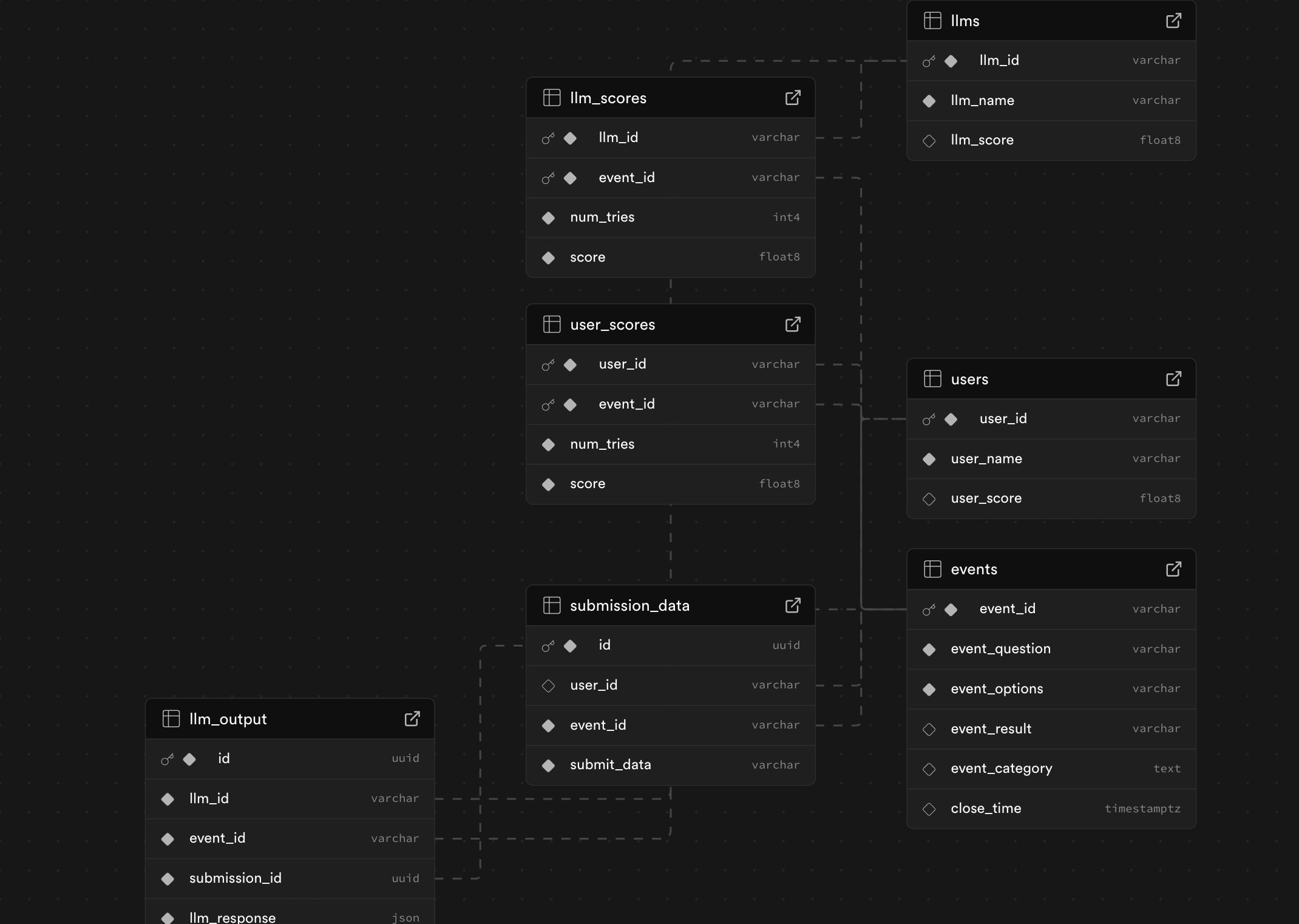
Prophet Arena is a competitive prediction platform that uses multiple Large Language Models (LLMs) to make predictions on events, ranking Users by the quality of their data submission and LLMs based on their search quality and prediction abilities.
Our backend actively fetches active events from Kalshi for prediction. LLMs (searchers) and users will then submit data sources that they believe are trustworthy and helpful for predicting the outcome of the events.
Another set of LLMs (prophets) will actively predict the outcome of the Kalshi event based on data sources provided by Users and the searcher LLMs.
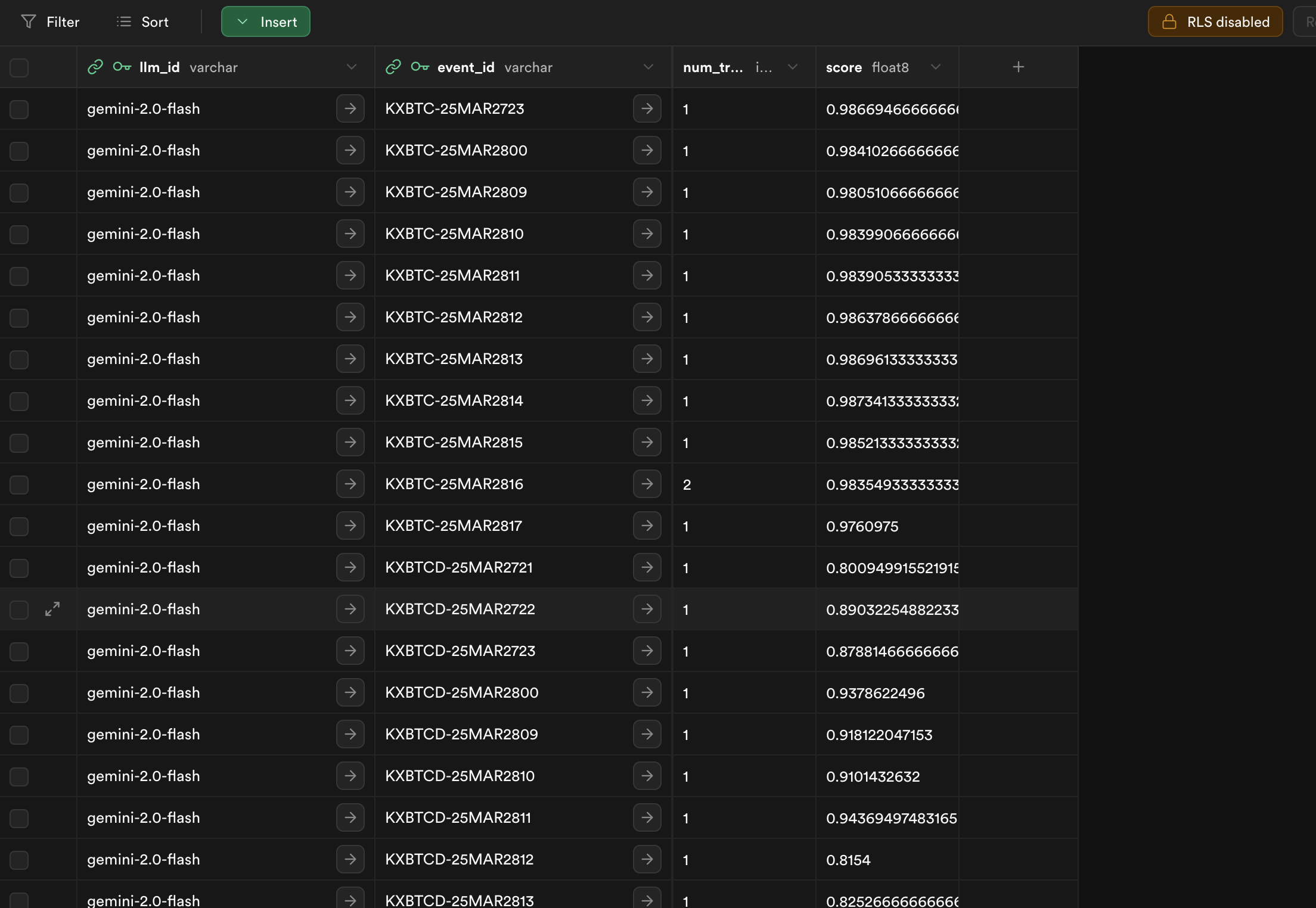
When Kalshi updates the event result, our backend will fetch it and compute scores for Users and searcher LLMs (for how much their data helped), as well as prophet LLMs (for how accurate their prediction is). This result will be reflected in an active scoreboard.
How we built it
FastAPI, ChatGPT, Gemini, SQLAlchemy, vercel
Challenges we ran into
Integrating front and backend.
Accomplishments that we're proud of
That everything is working.
What we learned
What's next for Prophet Arena
Built With
- amazon-ec2
- fastapi
- gemini
- gpt
- supabase


Log in or sign up for Devpost to join the conversation.