ProofLayer — About the Project
💡 What Inspired Me
It started with a video.
A few months ago, I watched a clip of a world leader apparently declaring war — completely fabricated, AI-generated, indistinguishable from real footage. It had already been shared millions of times before anyone flagged it. That moment stuck with me.
We've spent decades building the internet as a system for sharing information — but we never built the infrastructure for verifying it. Every image, every article, every video exists in a trust vacuum. You either believe it or you don't. There's no middle ground.
When I saw the theme AI for Good, I didn't think about chatbots or recommendation systems. I thought about that video. And I asked one question:
What if every piece of content had a cryptographic identity — something that couldn't be faked, forged, or erased?
That question became ProofLayer.
🔨 How I Built It
ProofLayer is built on three pillars that work together as a pipeline:
1. AI Detection Layer
For image deepfake detection, I used a pretrained EfficientNet / XceptionNet model fine-tuned on deepfake datasets, accessed via the HuggingFace Inference API:
import requests
API_URL = "https://api-inference.huggingface.co/models/umm-maybe/AI-image-detector"
def detect_image(file_bytes: bytes, token: str) -> dict:
headers = {"Authorization": f"Bearer {token}"}
response = requests.post(API_URL, headers=headers, data=file_bytes)
return response.json()
The model returns a probability score which I normalize into a human-readable Authenticity Score from 0–100:
$$\text{Authenticity Score} = \left(1 - P(\text{fake})\right) \times 100$$
For AI text detection, I used a RoBERTa-based classifier. The model outputs a probability that the text is AI-generated, combined with a perplexity score — a measure of how "surprised" a language model is by the text. Human writing has high perplexity (unpredictable); AI writing has low perplexity (smooth and uniform).
$$\text{Perplexity} = \exp\left(-\frac{1}{N}\sum_{i=1}^{N} \log P(w_i \mid w_1, \ldots, w_{i-1})\right)$$
A low perplexity score (e.g. \( H < 20 \)) is a strong signal of AI-generated content.
2. Cryptographic Certificate Layer
Every scan generates a tamper-evident certificate using SHA-256 hashing:
import hashlib, uuid, datetime
def generate_certificate(content: bytes) -> dict:
sha256_hash = hashlib.sha256(content).hexdigest()
verification_id = f"PL-{datetime.datetime.now().year}-{str(uuid.uuid4())[:5].upper()}"
return {
"hash": sha256_hash,
"verification_id": verification_id,
"timestamp": datetime.datetime.utcnow().isoformat() + "Z",
"model_version": "deepfake-v2.1"
}
The hash is computed before the result is stored — meaning the certificate is a fingerprint of the original content, not the result. If anyone tampers with the original file later, the hash won't match. That's the core guarantee.
To add tamper-evidence across records, each new entry hashes the previous record's ID into itself — a lightweight audit chain without blockchain complexity:
$$H_n = \text{SHA256}(H_{n-1} | \text{content}_n | t_n)$$
3. Backend & Public Verification
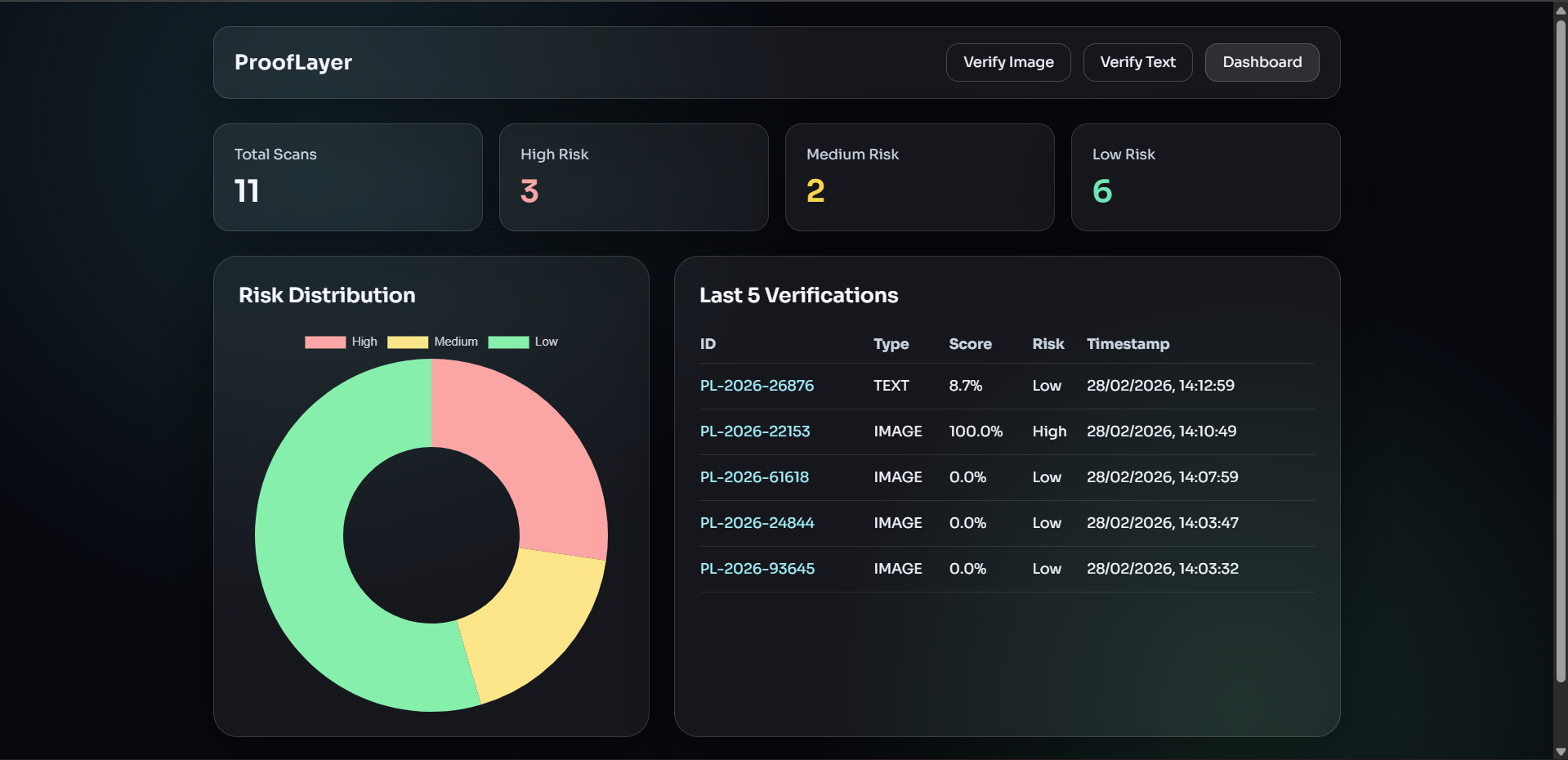
The backend is built with FastAPI and stores all results in SQLite. The critical design decision was making verification public and stateless — anyone with a Verification ID like PL-2026-00231 can hit:
GET /verify/PL-2026-00231
...and get the full certificate back, without an account, without trust in ProofLayer as a company. The hash speaks for itself.
📚 What I Learned
This project pushed me across multiple disciplines simultaneously — and honestly, that was the point.
On the ML side, I learned that raw model probability scores are almost always poorly calibrated. A model saying "0.84 probability AI" doesn't actually mean 84 out of 100 similar cases are AI — it means the model's internal activation crossed a threshold. I implemented basic Platt scaling (temperature calibration) to make scores more meaningful:
$$P_{\text{calibrated}} = \frac{1}{1 + e^{-(a \cdot z + b)}}$$
where \( z \) is the raw logit and \( a, b \) are learned calibration parameters.
On the cryptography side, I learned the difference between signing and hashing — and why for this use case, a hash is actually more appropriate than a signature. A hash is verifiable by anyone with no key. A signature requires trusting the signer. For public content verification, trustless is better.
On system design, I learned that the hardest part of building infrastructure isn't the feature — it's the trust model. Who trusts what? What happens when the model is wrong? What's the liability? These questions don't have code answers.
🧱 Challenges I Faced
Model Cold Starts
HuggingFace free-tier models go to sleep between requests. The first inference call can take 15–20 seconds while the model loads. I had to add async polling and a loading state in the UI so users didn't think the app had crashed.
Score Interpretation
The biggest UX challenge: what does "72% AI probability" actually mean to a journalist or a judge? Numbers alone aren't enough. I had to design a risk classification system that translated raw scores into human language:
| Score Range | Risk Level | Meaning |
|---|---|---|
| 0–30 | 🟢 Low | Likely authentic |
| 31–60 | 🟡 Medium | Inconclusive — review recommended |
| 61–85 | 🟠 High | Strong indicators of manipulation |
| 86–100 | 🔴 Critical | Almost certainly synthetic |
The False Confidence Problem
The hardest challenge wasn't technical — it was ethical. What if ProofLayer says something is real, and it's not? What if it says something is fake, and it's real? I had to be very deliberate about framing every result as a probabilistic assessment, not a verdict. The certificate says "Confidence: 91%" — not "This is fake." That distinction matters enormously in high-stakes contexts like journalism or legal proceedings.
🔭 What's Next
ProofLayer in its current form verifies images and text. But the roadmap is bigger:
- Phase 2 — Video deepfake detection (frame-by-frame analysis)
- Phase 3 — Document & PDF certification for legal and academic use
- Phase 4 — Browser extension that verifies content inline as you browse
The long-term vision is a world where every piece of digital content has a verifiable identity — where authenticity is infrastructure, not an afterthought.
"We didn't build a detector. We built a foundation."
Built solo in 24 hours for the AI for Good Hackathon, 2026.
Built With
- fastapi
- hashlib
- huggingface
- pillow
- roberta-base-openai-detector
- sqlite
- tailwind
- tamper-evidence
- uvicorn

Log in or sign up for Devpost to join the conversation.