-
-
Main app page
-
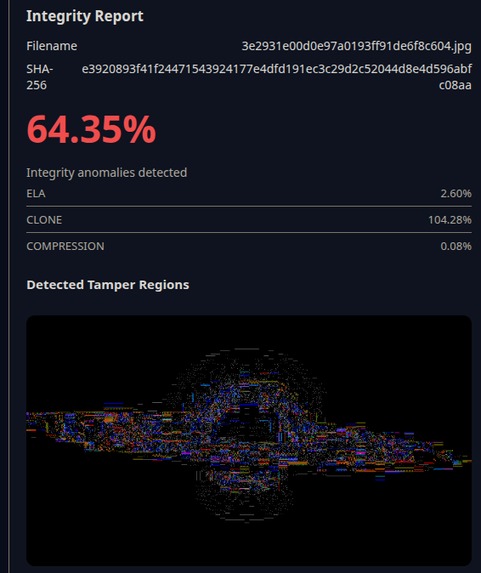
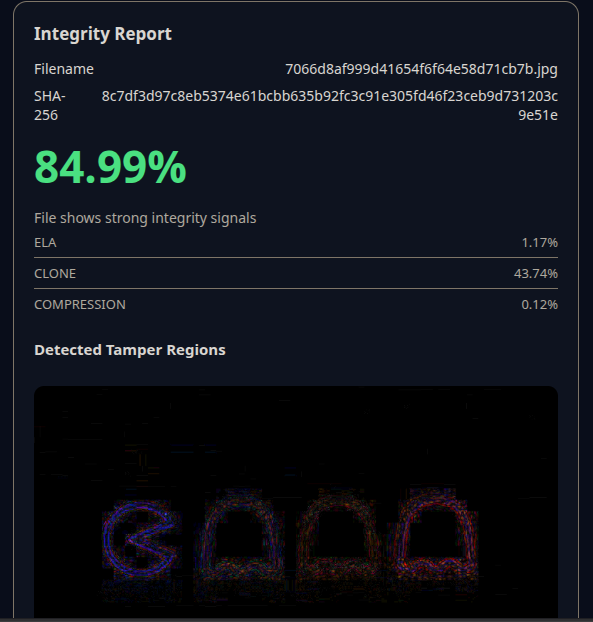
Result of test
-
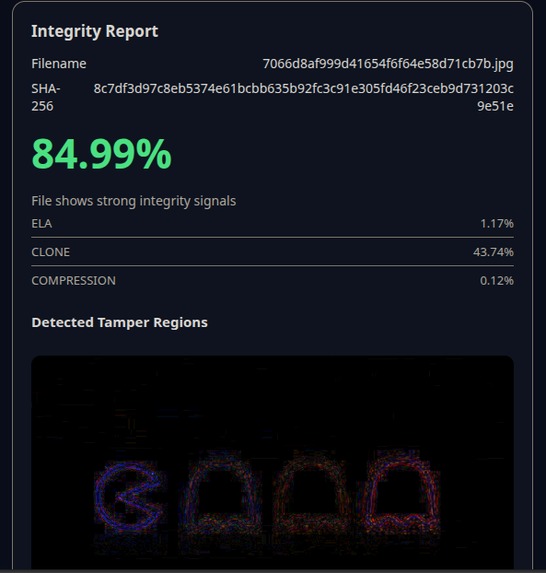
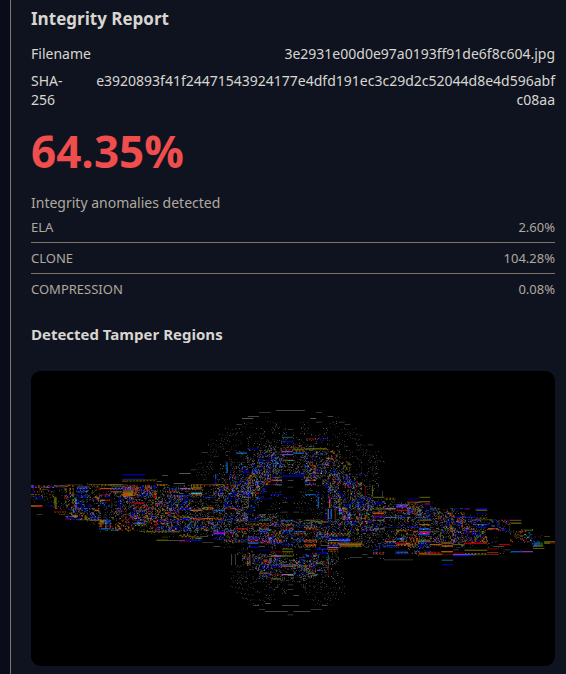
Result of test
Inspiration
I noticed how easily digital files are trusted without question. Screenshots, images, documents, and certificates are shared every day, yet most people have no real way to tell if something has been altered. Existing tools either rely on gut feeling, complex systems that require prior setup, or AI results that don’t explain themselves. ProofLayer was inspired by the idea that people deserve clearer, more transparent signals before deciding what to trust.
What it does
ProofLayer helps users understand the integrity of a digital file. When a file is uploaded, the system analyzes it for signs of manipulation and inconsistency, then presents the findings in a clear, structured way. Instead of simply saying a file is “real” or “fake,” ProofLayer shows what the file reveals about itself, allowing users to make informed decisions based on evidence rather than assumptions.
How I built it
I built ProofLayer as a simple but robust pipeline. A backend service accepts uploaded files and runs them through several focused checks, such as file fingerprinting, metadata inspection, and image analysis techniques that highlight unusual patterns. These results are combined into a single report and displayed through a clean, responsive frontend. Every part of the system was designed to be lightweight, understandable, and easy to extend.
Challenges I ran into
One of the biggest challenges was keeping the system reliable across different environments while avoiding unnecessary complexity. I also had to be careful not to overwhelm users with technical details, while still preserving transparency. Striking the right balance between depth, clarity, and usability required several iterations.
Accomplishments that we're proud of
I'm proud of building a complete, working prototype that delivers meaningful results without relying on black-box models or external services. ProofLayer runs locally, produces consistent results, and clearly explains what it finds. I also maintained a clean structure that makes the project easy to understand and build upon.
What I learned
I learned that trust improves when systems are honest about uncertainty. Users don’t always need definitive answers; they need clear signals and context. I also learned that focusing on fundamentals and simplicity can be more powerful than adding features for the sake of complexity.
What's next for ProofLayer
Next, I want to support more file types, improve visual feedback for detected anomalies, and refine how results are presented to different audiences. In the long term, ProofLayer could become a reusable integrity-checking layer that other applications can easily integrate, helping people make better trust decisions across the web.

Log in or sign up for Devpost to join the conversation.