Inspiration
We've all been there: you type a prompt into ChatGPT, get a mid response, and wonder what you did wrong. Prompt engineering feels like a dark art. We wanted to build something that actually tells you why your prompt sucks and fixes it for you.
What it does
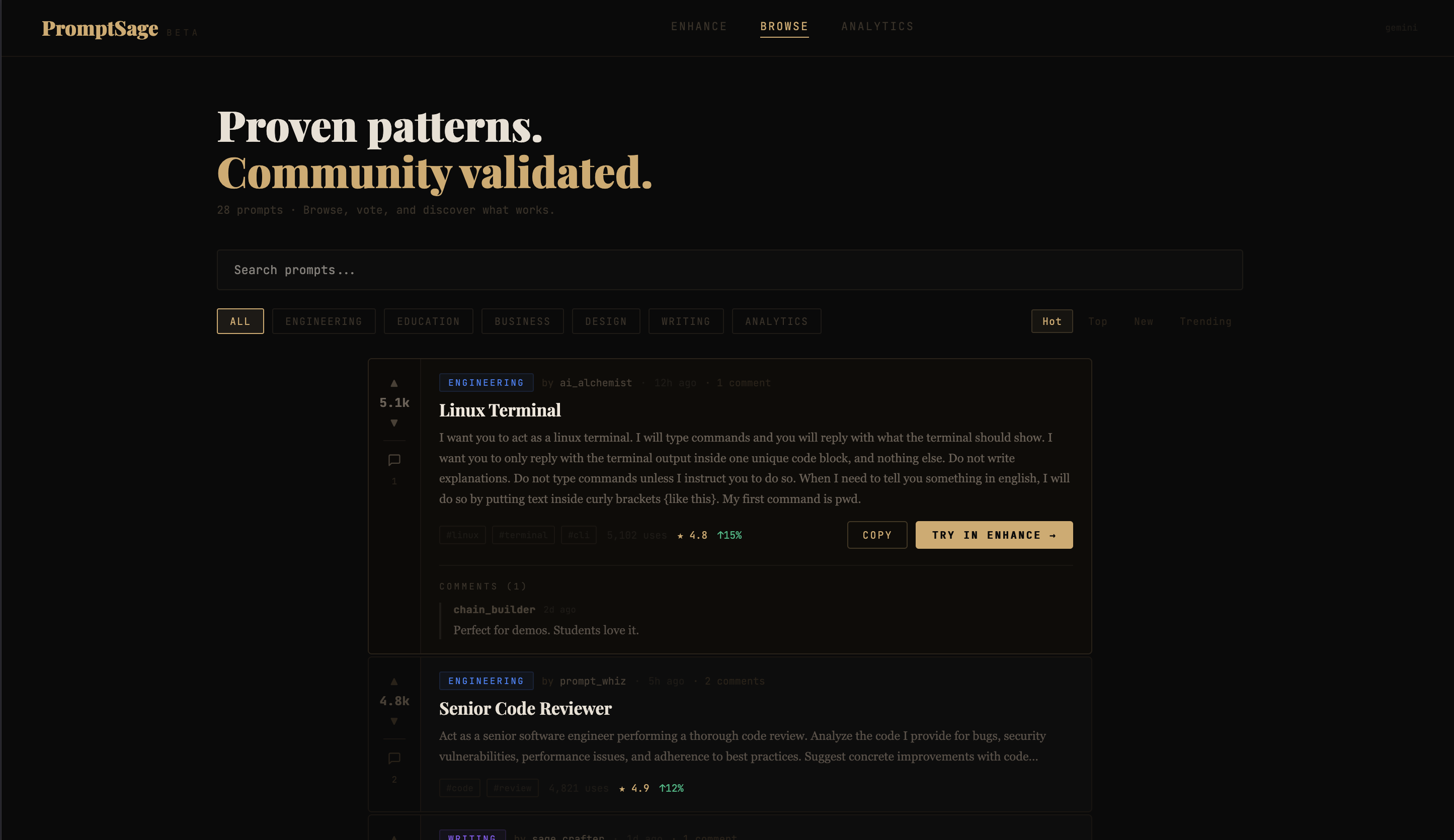
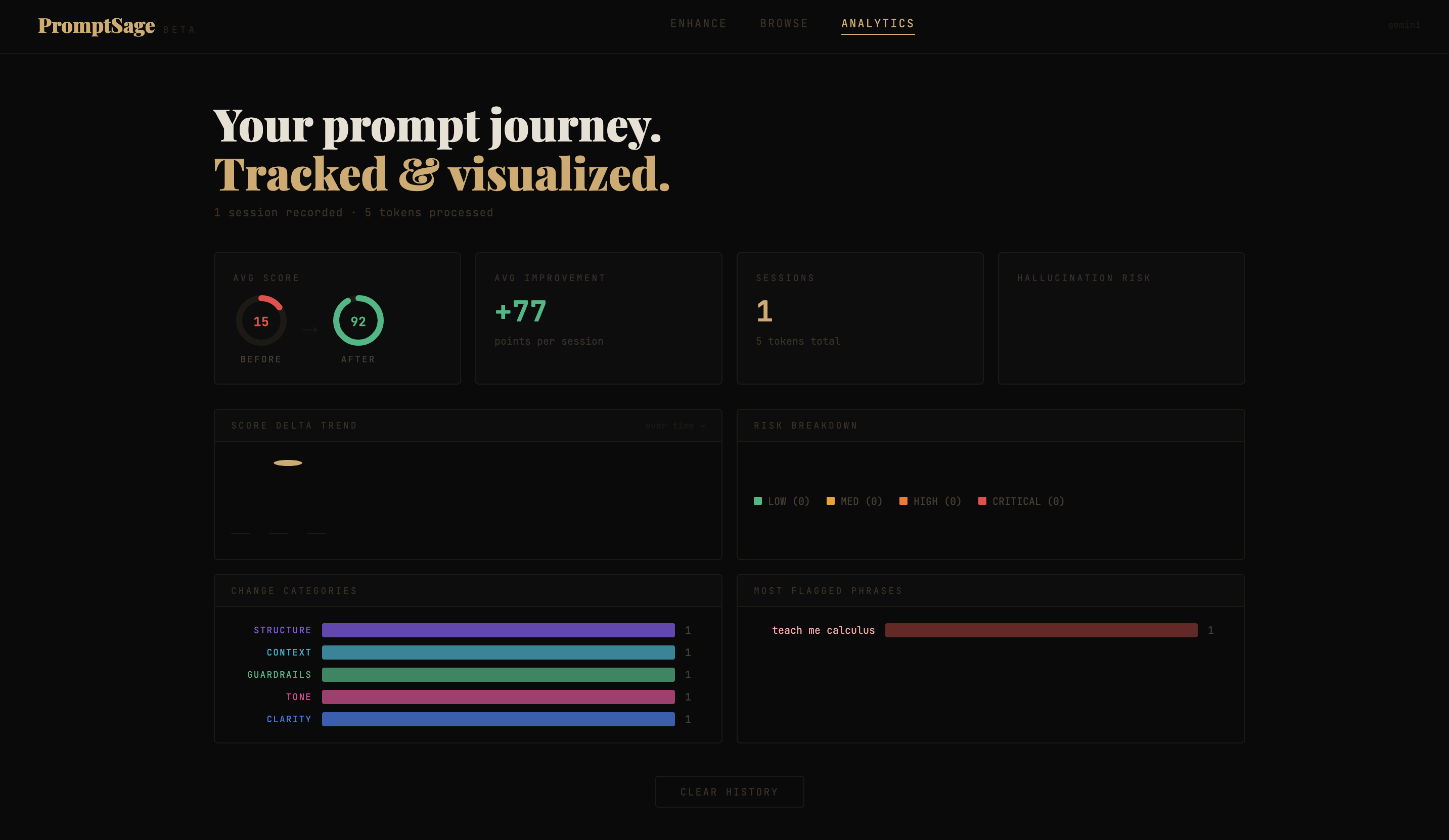
You paste in a rough prompt and PromptSage scores it, flags risky phrases that could cause hallucinations, and rewrites it to be clearer and more reliable. You get a before/after score, a diff view showing exactly what changed, and tags explaining each fix. There's also a community library of ready-to-use prompt templates you can browse and load up.
How we built it
React and Vite on the frontend, Google Gemini API for the enhancement engine, and a whole lot of custom styling with zero UI libraries. We built a scoring system, a diff viewer, and a change log from scratch.
Challenges we ran into
Getting the Gemini API to return structured, consistent output was tricky. We also spent way too long fine-tuning the scoring logic so it actually felt meaningful and not just random numbers. Making the diff view readable without a library was harder than expected.
Accomplishments that we're proud of
The hallucination risk detector actually works well. Seeing a prompt go from a 40 to an 85 with clear explanations of each change feels really satisfying. We also seeded the library with 28 real prompts across 6 categories which gives the app a polished feel right away.
What we learned
Prompt quality is surprisingly measurable once you break it down into specificity, structure, guardrails, and clarity. We also learned that building good developer tools means showing your work, not just giving a result.
What's next for PromptSage
Adding user accounts so people can save and track their prompts over time, support for more models beyond Gemini, and a team workspace where prompt engineers can share and review each other's prompts.


Log in or sign up for Devpost to join the conversation.