Inspiration When we started, we noticed a huge problem, many businesses are excited about what AI can do, but the cost of using large language models is skyrocketing because the prompts they send are often too long and inefficient. We wanted to build something that could make working with these models more affordable without harming the quality of the outputs. That’s how PromptOptima was born: a tool to smartly shrink prompts and save money while keeping the meaning intact.
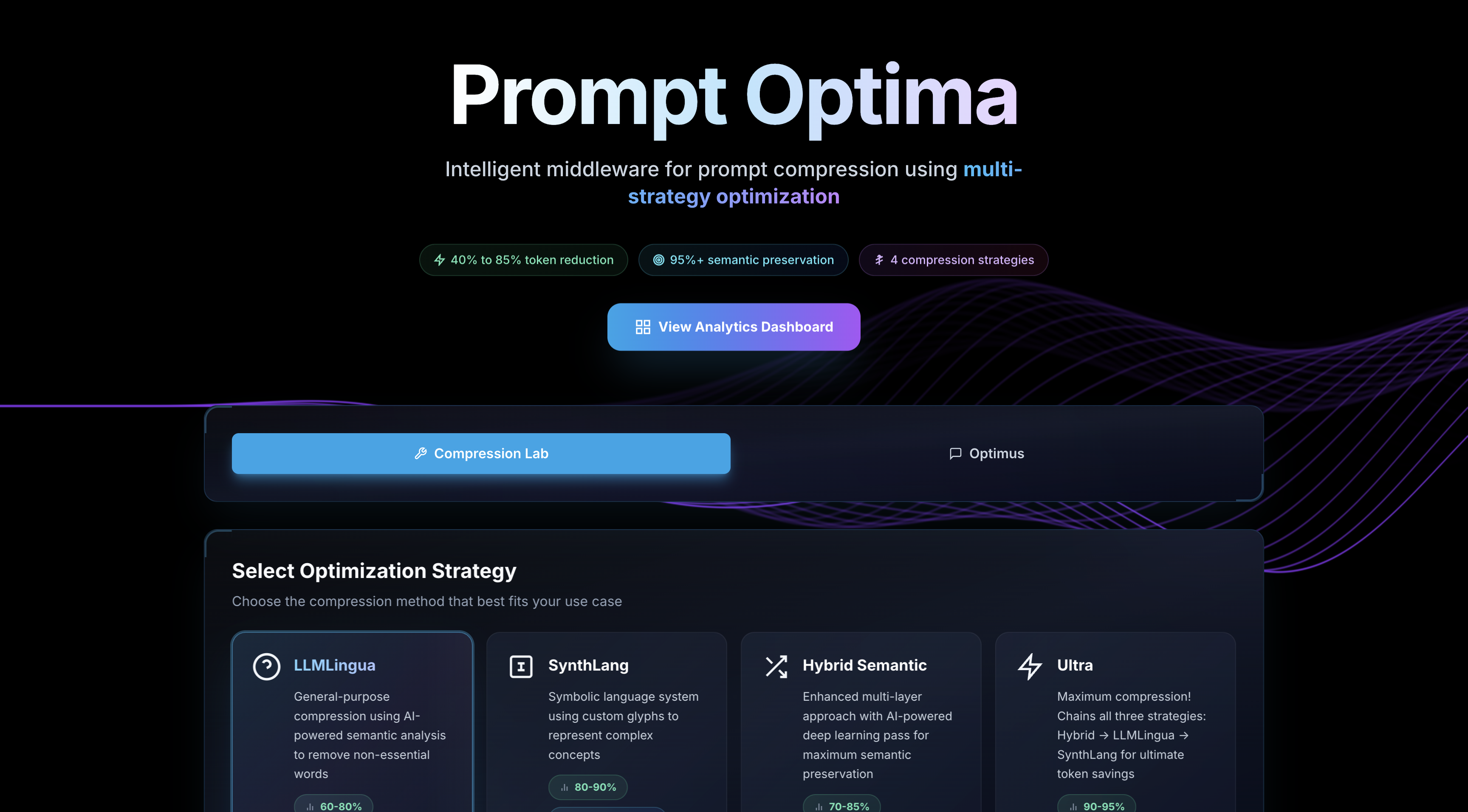
What it does PromptOptima sits between your app and the AI service. It automatically shrinks your prompts, cutting down the number of tokens sent to the AI by 60% to 95%. And the best part? It makes sure the compressed prompt still says what you meant with over 95% accuracy. It offers several ways to compress, from straightforward AI-powered edits to a unique symbolic language for super tight compression. Plus, it shows you how much you’re saving in real time.
How we built it We used modern web tech like Next.js and React for the frontend because it lets us build smooth, responsive interfaces quickly. On the backend, we created modular APIs that handle different compression methods and connect with the powerful Google Gemini AI to make sure we don’t lose meaning. We also built smart analytics dashboards so users can see their tokens saved and cost reductions live. It was really about blending clever algorithms with real-world tools people trust.
Challenges we ran into Keeping the meaning while cutting down the prompt is tricky. It was a challenge to balance aggressive compression with preserving nuance especially since some prompts are complex and domain-specific. Integrating our own symbolic compression alongside AI-based techniques into one flow took a lot of testing. Another tough part was making the system fast enough so users don’t have to wait—some AI calls can take a few seconds, so we optimized around that. Lastly, making sure the system is secure and reliable with external APIs was a serious priority.
Accomplishments that we're proud of We successfully built a fully working system that can cut tokens up to 95% while keeping quality high, proven across different real-world prompts. Our unique symbolic “SynthLang” compression was a standout, compressing complex sentences into just a handful of characters. The fact that users get instant reports on savings and semantic quality sets us apart too. We also created a sleek UI with live analytics, which makes the tech accessible to all levels of users.
What we learned We realized that many companies don’t even fully understand how much they’re spending on AI tokens until it’s too late and that token waste is huge. Compression isn’t just a tech challenge; it’s a financial one. Combining AI tools with symbolic languages opens new doors that raw AI alone can’t reach. We also learned that user trust depends on clear quality metrics; so validation and transparency are key. And finally, real-world usage demands flexible, fast processing with good error handling.
What's next for PromptOptima We plan to add user accounts so people can save their history and preferences. We want to build browser extensions and IDE plugins to bring compression directly where developers work. Expanding support to other LLMs like GPT-4 and Claude is also on our roadmap. More advanced enterprise features like team collaboration, single sign-on, and custom branding will come next to help businesses scale PromptOptima across their operations.



Log in or sign up for Devpost to join the conversation.