-
-
promptops flow v1
-

thumbnail

Inspiration
While using Bolt, I imagined a future where a computer could work like a human—taking a high-level prompt and autonomously producing results without constant supervision. That vision sparked PromptOps: a local-first agent that mimics human behavior using LLM reasoning and screen interaction.
What it does
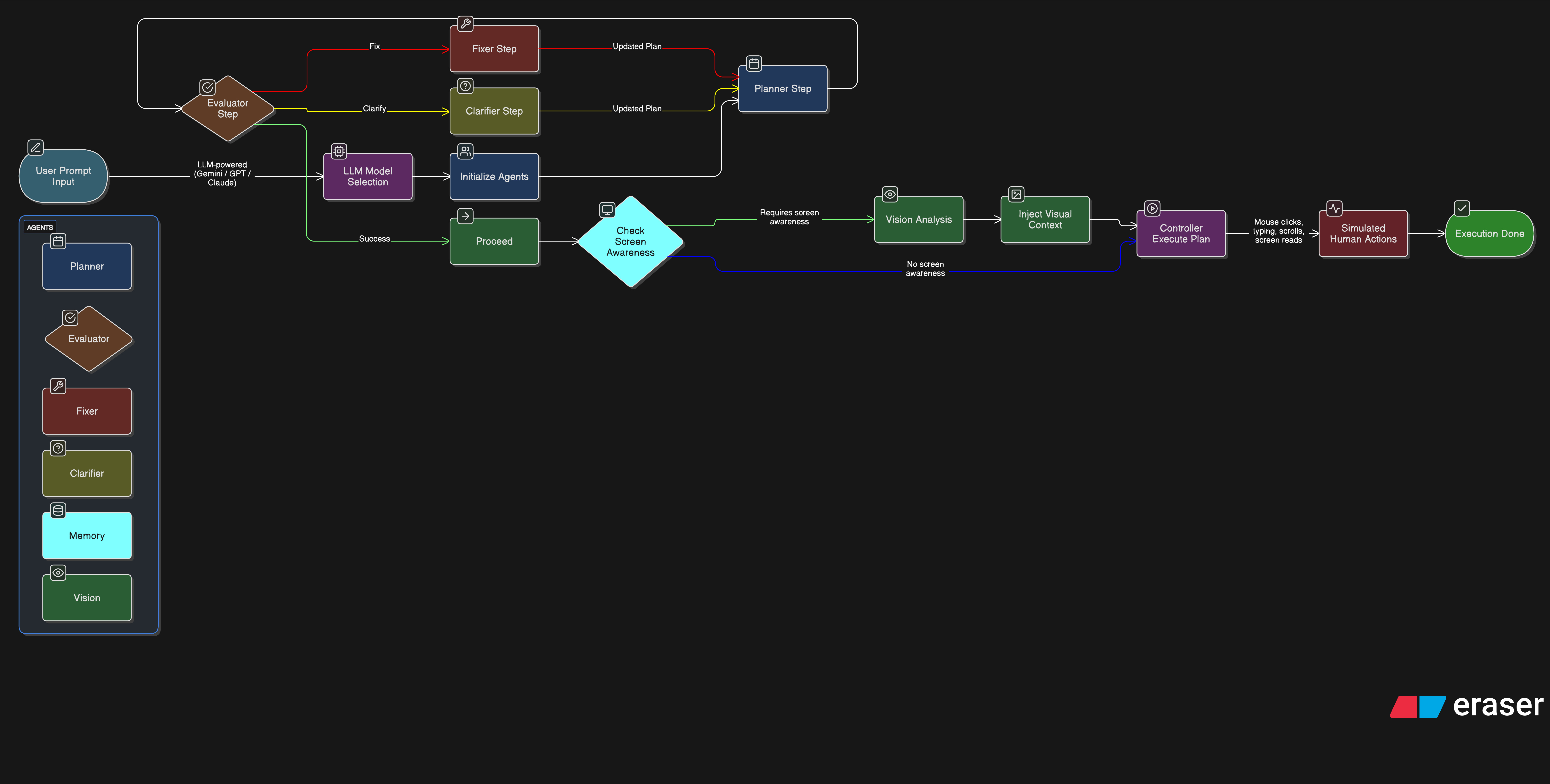
PromptOps takes natural language prompts, plans the necessary steps, and simulates human-like actions—typing, scrolling, reading screen content—to execute the task on a desktop autonomously.
How we built it
We used Python for core logic, integrating pyautogui/pynput for UI simulation and Gemini for LLM reasoning. The system includes a planner, a skill execution engine, and a vision layer that parses screen content to guide decisions.
Challenges we ran into
- Reliable UI control without clicking
- Parsing dynamic screen content contextually
- Balancing flexibility with deterministic execution
- Designing prompt interpretation without rigid skill trees
Accomplishments that we're proud of
- A modular LLM-agent pipeline with screen-grounded actions
- Local-first design with no external APIs required
- Real-time execution based on visible UI context
- Planner that adapts actions based on outcomes
What we learned
- LLMs can simulate goal-directed human behavior when grounded in visual input
- Skill-based design is brittle early on; prompt-based planning is more flexible
- Abstracting actions into reusable modules improves maintainability and growth potential
What’s next for PromptOps
- Add support for dynamic skill generation using LLMs
- Integrate full vision-based UI navigation
- Build memory and long-term goal management
- Extend to goal-based software creation from prompts

Log in or sign up for Devpost to join the conversation.