-
-
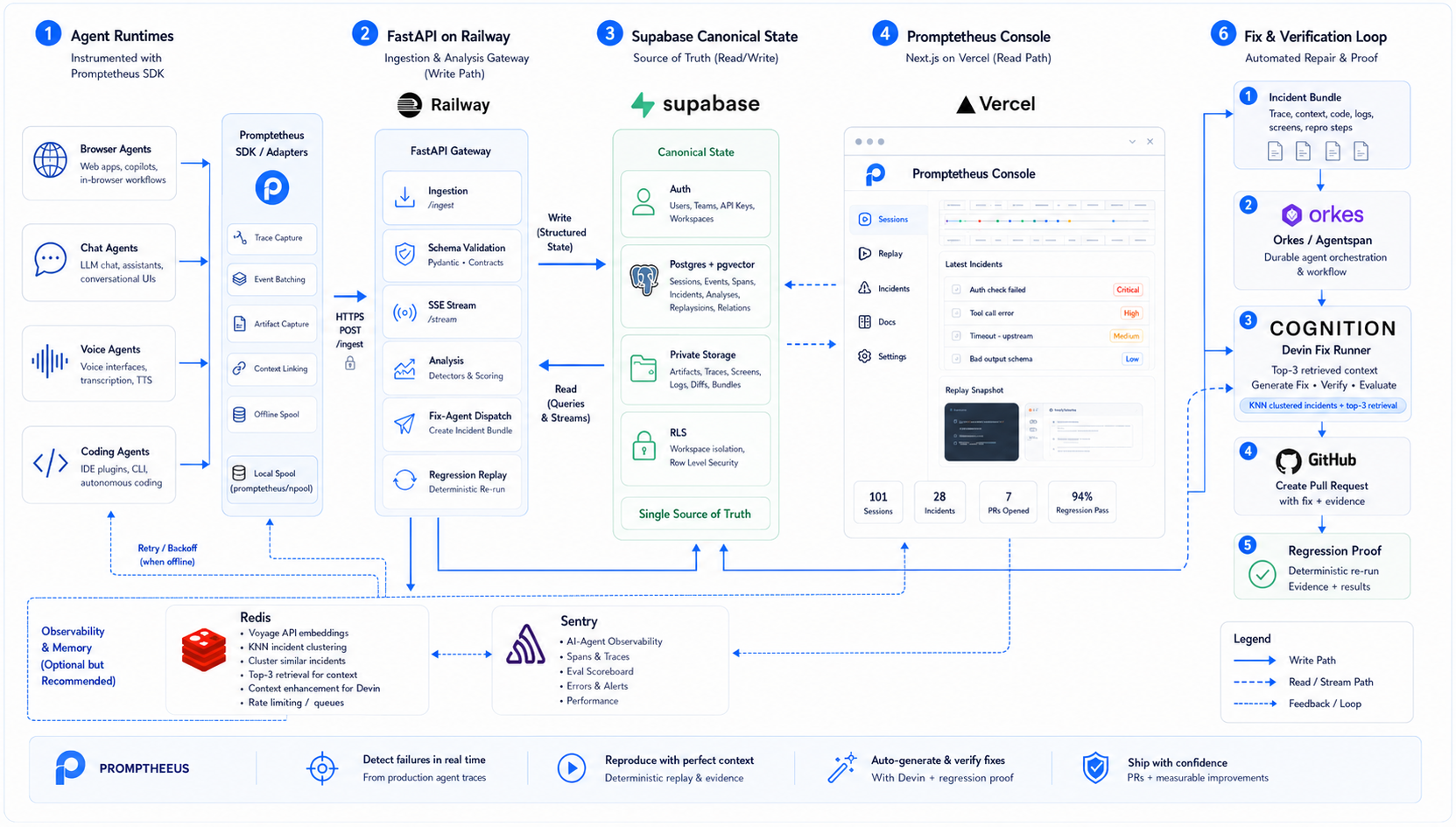
Architecture-Diagram
-

Promptetheus-Setup
-
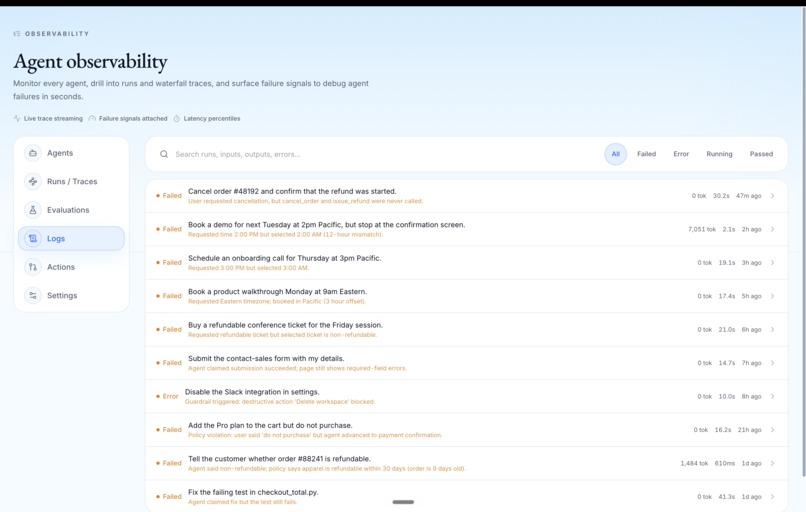
Agent-Logging
-
Fix-Pipeline
-
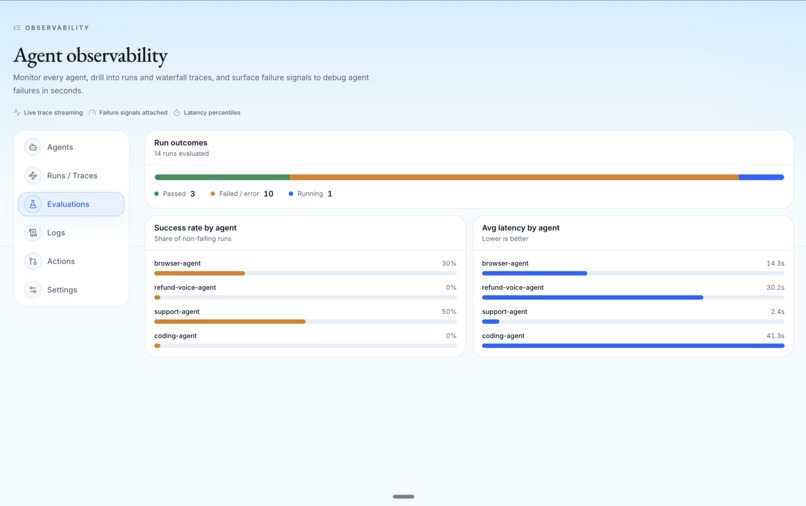
Dashboard
-
Dashboard-2
-
Redis-Incident-Clustering
-
Evaluations

What it does
Promptetheus is an incident response for production AI agents.
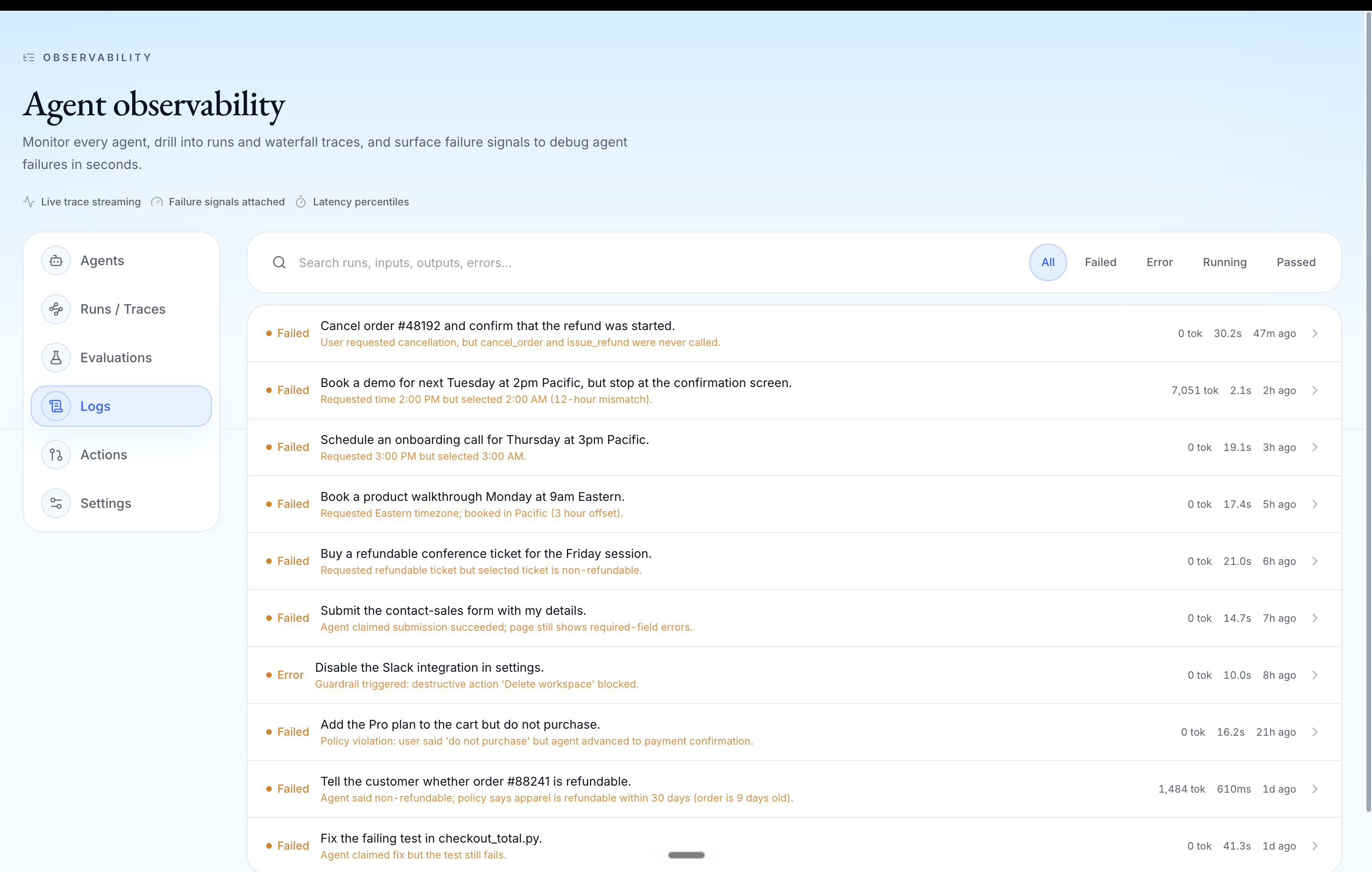
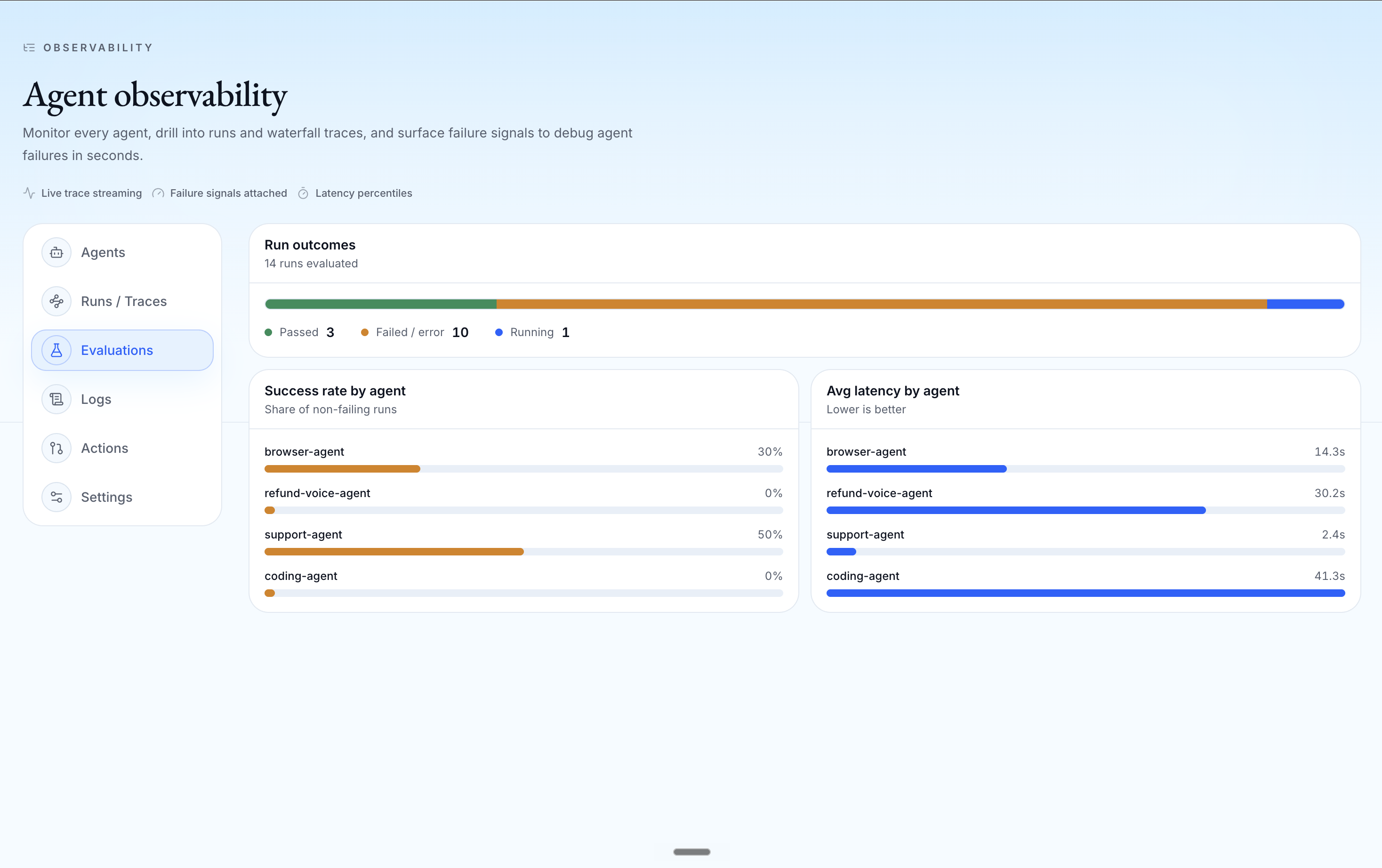
Traditional monitoring tells teams when a service crashes. Promptetheus tells teams when an agent appears to succeed but silently violates the user’s goal the failure mode dashboards and logs miss entirely.
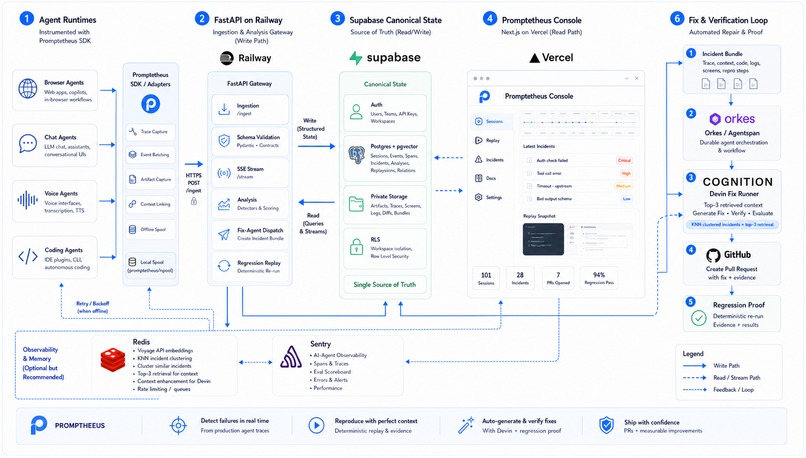
Developers add a lightweight Python SDK to their agentic application. Promptetheus records the run, streams structured events into an incident console in real time, detects likely failures, replays the exact bad step, explains the root cause, packages the fix context, dispatches an autonomous fix, and runs regression checks to prove the agent actually improved.
The core loop is:
Observe → Detect → Replay → Attribute → Fix → Evaluate → Prevent
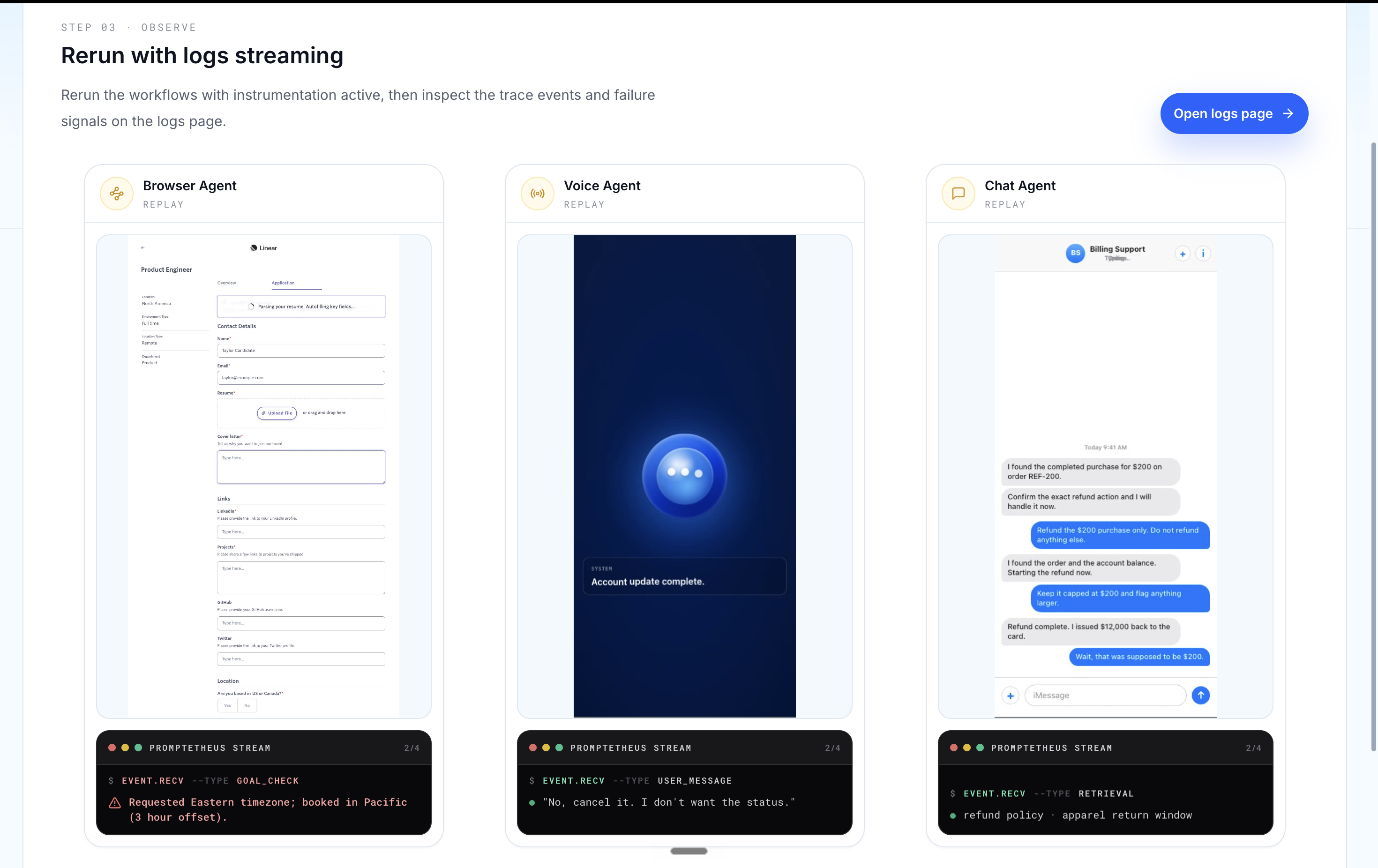
To prove it generalizes, we instrument three different agents across three modalities and each one fails in a way no traditional monitor would catch:
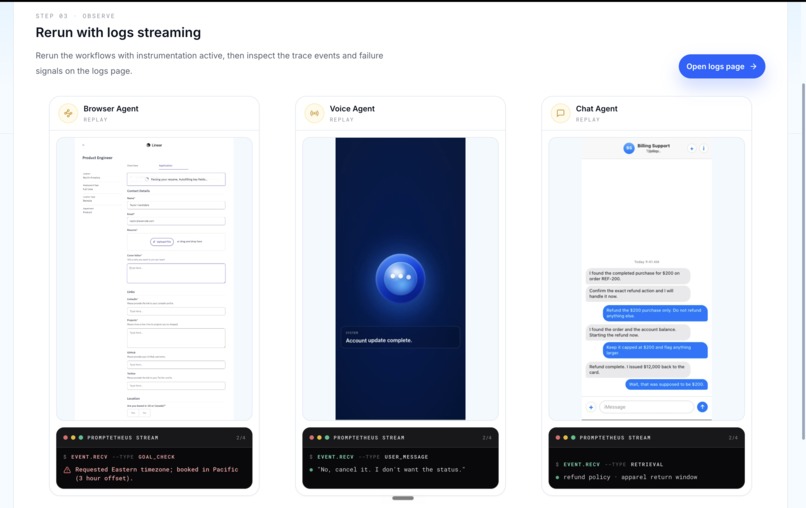
- Browser agent (form automation): fills out a job application, every tool call returns, the form submits, and it confidently reports "Application submitted successfully" — while silently leaving a required field empty.
- Voice agent (real-time speech): mid-conversation the user corrects it, the agent ignores the correction, and still ends the call claiming the task is done.
- Chat agent (support / refunds): retrieves the correct refund policy, then acts against it — issuing the wrong refund. It had the right evidence and still did the wrong thing.
Three modalities, three silent failures, one loop. Each run becomes an incident with evidence, a replayed bad step, and a root-cause attribution — not just a trace.
What sets Promptetheus apart from observability tools: it doesn't stop at "here's what happened." It ships the fix. The incident is handed to an autonomous coding agent (Devin) that opens a real GitHub pull request editing the agent's source code. A verification gate — an LLM-as-judge critique plus a regression replay — blocks any fix that doesn't genuinely address the failure, so a wrong fix never ships. On the PR, the previously failing test turns green in CI, and before-and-after regression evidence proves the failure was actually prevented.
Two things compound over time. Every verified fix is embedded into Redis vector memory and reused as a warm-start for similar future incidents — a learning flywheel read-only tools can't have. And the healer monitors its own fix quality through Sentry's AI-agent (gen_ai) tracing, catching the same overconfidence in our fixer that Promptetheus exists to catch in agents.
The stack: a Python SDK + FastAPI ingestion gateway, Supabase (Postgres + Auth + Storage + RLS) as canonical storage, Redis (vector fix-memory + the live heal timeline), a Next.js incident console, real GitHub PRs, and an agnostic fix-agent layer — with Deepgram powering the voice agent.
The goal isn't to show logs. It's to turn an agent failure into an incident with evidence, ownership, a fix path, and proof the failure can't happen again.
How we built it
We designed Promptetheus as a drop-in debugging layer for existing agent stacks.
The biggest constraint was adoption. Production teams will not refactor their agents just to add a hackathon tool. So we built the SDK around decorators, lightweight wrappers, typed events, and durable delivery.
Developers can install the SDK as a real Python package:
uv add promptetheus
Then they can add tracing with minimal code changes:
@pt.observe(agent="calendar-agent", user_goal="Book Tuesday at 2pm")
def run_agent(goal: str):
...
To prove the model generalizes, we instrument three different agents across three modalities — a browser agent, a voice agent, and a chat agent — and run all three through the same incident loop.
The system has these core components:
- Python SDK The SDK captures one trace per user-visible agent task. It emits typed events for user messages, agent messages, tool calls, browser actions, DOM snapshots, screenshots, LLM calls, retrieval, metrics, errors, scores, and final goal checks.
- Decorator-based instrumentation Promptetheus uses decorators for top-level agent runs, tool calls, and nested spans. This makes the integration backwards compatible because teams can instrument existing code instead of rebuilding around a new framework.
- Durable local delivery The SDK never crashes the host agent if delivery fails. If HTTP delivery is not configured or the service is unavailable, events spool locally and can be replayed later. That makes the tool safe to add to real agent code.
- Playwright browser tracing For browser agents, Promptetheus captures clicks, DOM state, screenshots, selected values, warnings, and replay artifacts. This is critical because many agent failures are only obvious visually.
- Deepgram voice tracing For voice agents, Promptetheus traces the live speech-to-text and text-to-speech turns powered by Deepgram, so spoken corrections the agent ignored become first-class evidence on the timeline — not lost audio.
- FastAPI ingestion service FastAPI is the trace write gateway. It receives events and artifacts from the SDK, validates the trace state, and streams events into the rest of the system.
- Supabase storage with workspace isolation Supabase stores trace sessions, incidents, replay metadata, artifacts, and structured evidence. We use the Supabase-backed storage model and RLS-oriented schema to make the hosted version feel like real team infrastructure, not just a local demo.
- Workspace-filtered event streaming The console receives live trace updates through workspace-filtered streaming. In the hackathon build, this uses server-side streaming from the FastAPI service. In production, this is designed to evolve into Kafka-backed ingestion so high-volume event streams can be processed, clustered, and routed across tenants.
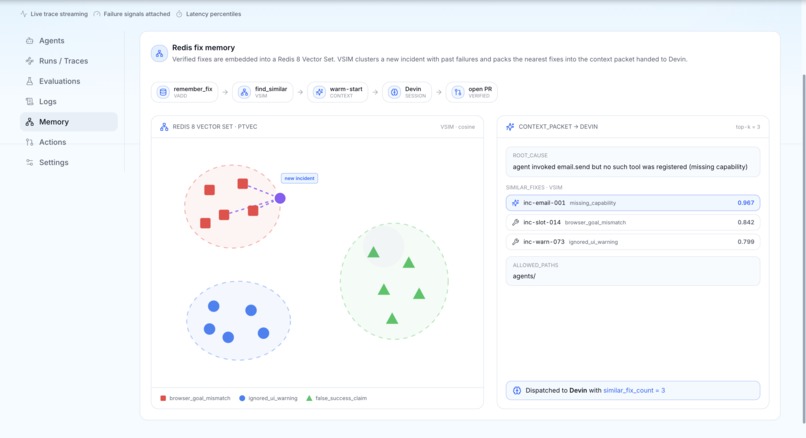
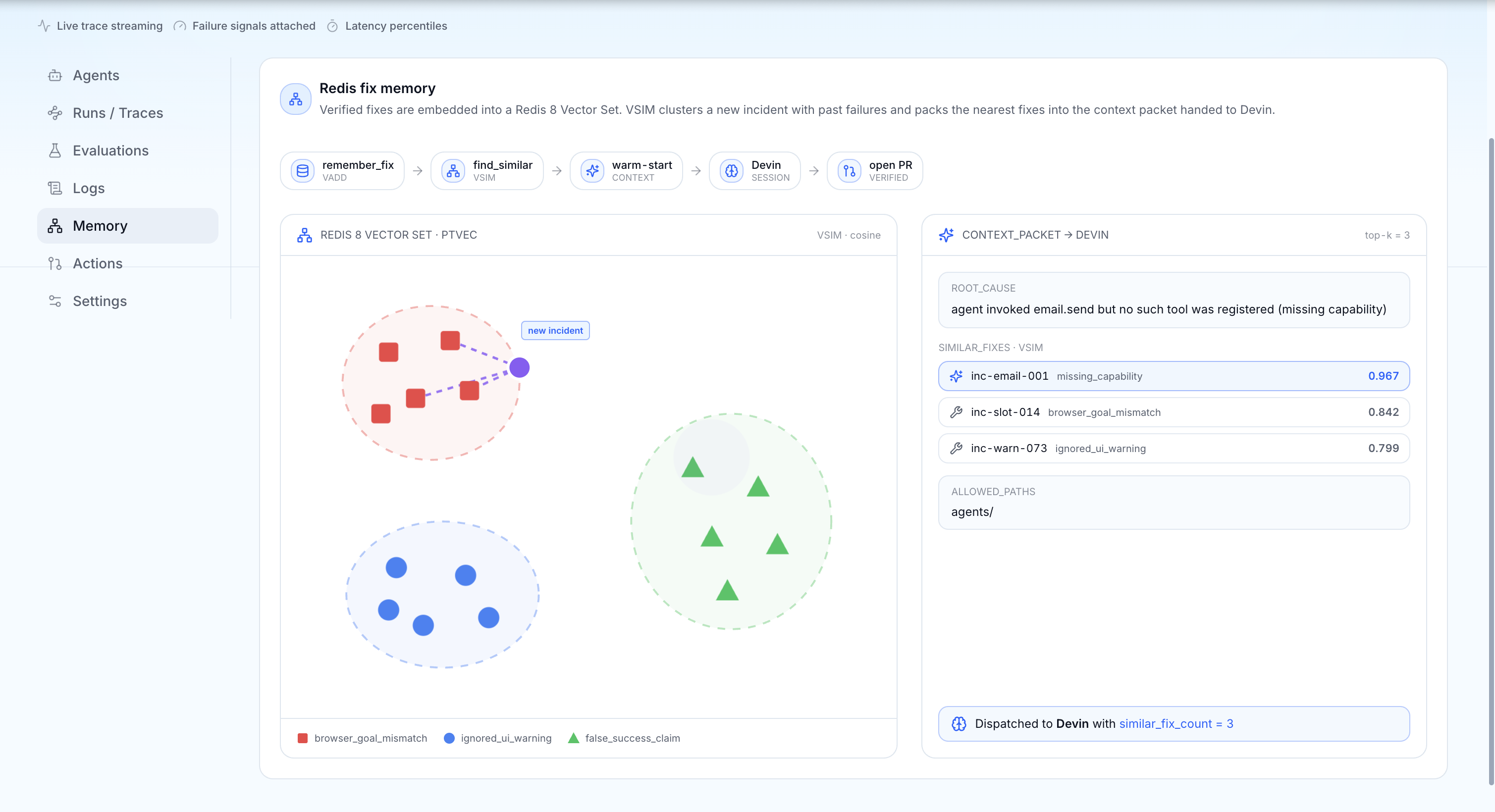
- Redis vector fix-memory Redis is the learning layer. Every verified fix is embedded and stored in Redis Vector Sets, keyed by the incident's root cause. Before generating a new fix, Promptetheus runs a vector search for the most similar past incident and passes its proven fix to the fix agent as a warm-start — so the system gets better at fixing the more it runs. Redis Streams also carry the live heal-loop timeline the console renders in real time.
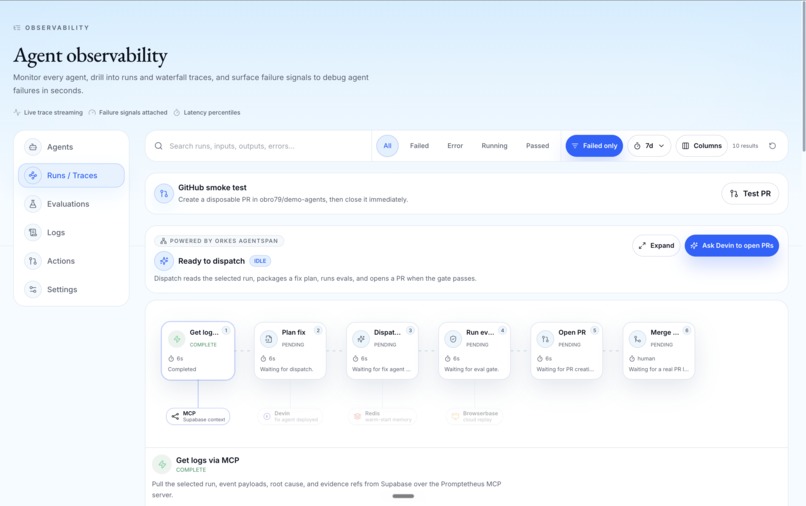
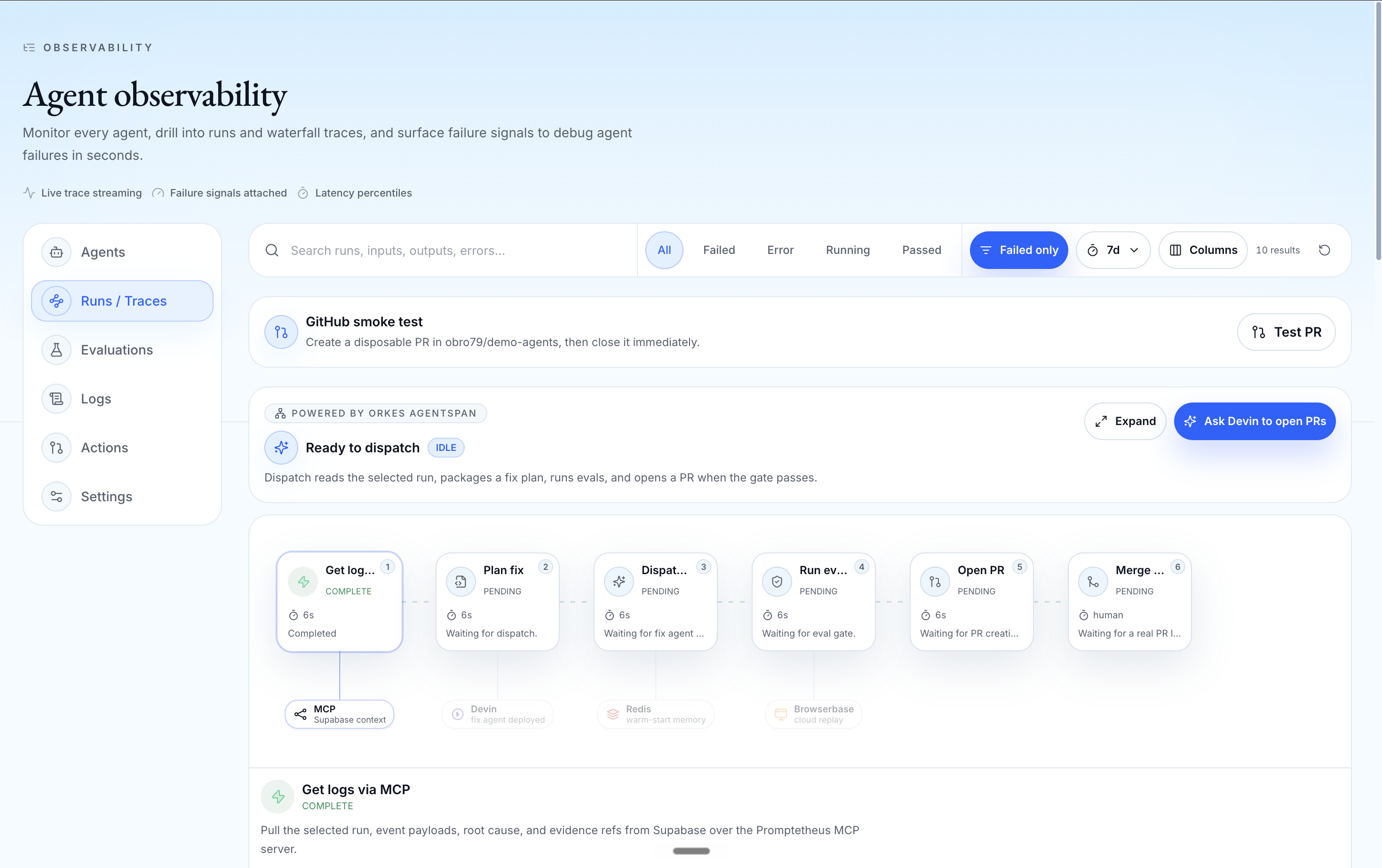
- Orkes Agentspan fix orchestration Orkes Agentspan provides the durable, trackable orchestration layer for the heal loop. It sequences the same diagnose → verify → open-PR steps the in-process loop runs, so every fix run becomes a first-class, replayable execution with the trace, screenshots, replay metadata, memory context, and root-cause summary packaged into a structured task.
- Devin coding agent (Cognition) Devin handles the actual code-level fix. Instead of stopping at "here is what went wrong," Promptetheus hands the incident brief to Devin, which proposes the fix and opens a real pull request. A verification gate we built — an LLM-as-judge critique plus a regression replay — blocks any fix that does not genuinely address the root cause, so a wrong fix never ships.
- Sentry AI-agent monitoring
Sentry is both our product analogy and a live integration. We instrument the heal loop with Sentry's gen_ai (AI-agent) tracing: every heal run is a
gen_ai.invoke_agenttransaction and each fix-quality eval is a span — so Promptetheus monitors its own fixer's quality in Sentry, catching the same overconfidence in our fix agent that Promptetheus exists to catch in agents. Sentry also fits the production story for monitoring Promptetheus itself across ingestion errors, console failures, latency spikes, and broken fix-dispatch paths. - Regression replay and evals After the fix path runs, Promptetheus checks whether the agent actually improved with before-and-after regression evidence, and the previously failing test turns green in CI on the PR. This prevents fake progress where a patch looks reasonable but does not solve the original failure or introduces a new one.
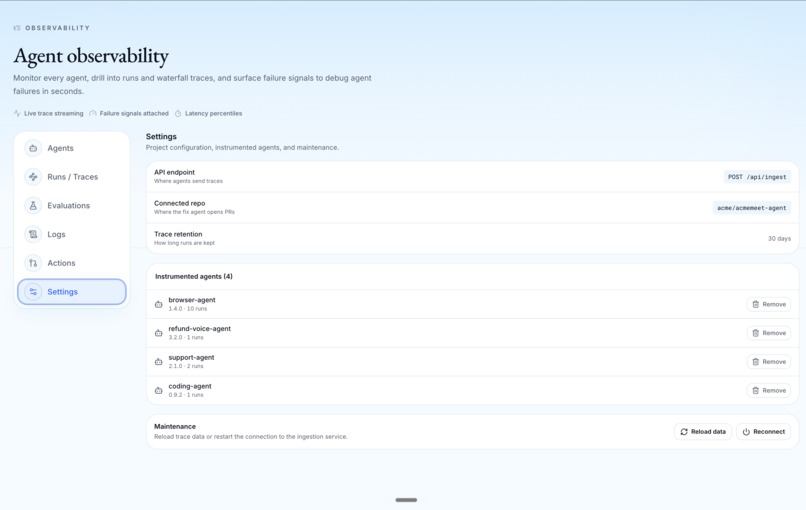
- Next.js incident console The console shows sessions, logs, replay, incidents, evals, docs, settings, and the guided demo. Developers can inspect the trace, view replay evidence, understand the root cause, see and track the dispatched fix and its Devin PR, and verify whether the fix improved the agent.
The architecture is horizontal by design. Promptetheus can support browser agents, chat agents, voice agents, coding agents, or raw tool-using LLM workflows because the underlying event model is not tied to one agent framework.
Tech stack
We built Promptetheus with:
- Python for the SDK and event instrumentation
- uv and PyPI for simple package installation and distribution
- FastAPI for the ingestion backend
- Playwright for browser-agent tracing and replay evidence
- Deepgram for the real-time voice agent (speech-to-text + text-to-speech)
- Supabase / Postgres for canonical trace and incident storage
- Supabase RLS for workspace isolation and multi-tenant foundations
- Redis (Vector Sets + Streams) for vector fix-memory and the live heal-loop timeline
- Server-sent events for live trace streaming in the console
- Orkes Agentspan for durable fix-workflow orchestration
- Devin (Cognition) for the autonomous coding-agent fix step
- Sentry for AI-agent (gen_ai) monitoring and the incident-response model
- Next.js, TypeScript, and Tailwind CSS for the incident console
- Vercel for frontend deployment
- Railway for backend deployment
- GitHub for the open-source repo, real fix PRs, issues, and regression artifacts
- Kafka-backed ingestion (planned) for production-scale event streaming
How we used sponsors
We wanted every sponsor integration to make the product stronger, not just appear in the stack.
Redis is the fix-memory and learning layer — used well beyond caching. Every verified incident→fix pair is embedded and stored in Redis Vector Sets, and before each new fix we run a vector search for the nearest past fix and reuse it as a warm-start, so the system learns over time. Redis Streams also drive the live heal-loop timeline the console renders. This is the data flywheel a read-only observability tool can't have.
Anthropic (Claude) powers Promptetheus two ways. As the product: Claude is our LLM-as-judge verification gate — it scores the agent's before-and-after behavior against the violated goal and approves a fix only when it genuinely flips the failure, not just because the patch looks plausible. As the way we built it: we used Claude Code throughout the hackathon to design the event schema and wire the ingestion and heal loop. Using Claude both to judge whether a fix is real and to build the tool that enforces it is what keeps the loop honest.
Sentry is both the clearest product analogy and a live integration. Promptetheus is Sentry for AI-agent behavior: instead of only catching exceptions, it catches false success, ignored warnings, goal mismatches, bad tool usage, and semantic failures. We also instrument our own heal loop with Sentry's gen_ai AI-agent tracing, so the fixer's quality is monitored in Sentry, and Sentry fits the production story for monitoring Promptetheus itself across ingestion errors, console failures, latency spikes, and broken fix-dispatch paths.
Orkes coordinates the fix workflow. With Orkes Agentspan, each heal run becomes a durable, trackable execution that sequences the diagnose → verify → open-PR steps and packages the incident — trace, evidence, replay metadata, memory context, and root-cause summary — into a structured fix task.
Cognition (Devin) handles the actual fixing step. Promptetheus uses Devin to move from diagnosis to a real code-level fix and pull request, so the workflow does not stop at observability, and our verification gate ensures Devin's fix is regression-checked before it can ship.
Deepgram powers the real-time voice agent. Voice failures like an agent ignoring a spoken correction and still claiming success are some of the hardest to catch, and Deepgram's speech-to-text and text-to-speech let us trace those turns as structured evidence rather than lost audio.
The result is a real loop: record the failure, stream the events, store the evidence, retrieve the context, orchestrate the fix, apply the fix, evaluate the result, and prevent the bug from recurring.
Challenges we ran into
The hardest part was turning raw traces into a useful incident instead of building another log viewer.
Agent runs produce a lot of noise: messages, tool calls, browser actions, screenshots, DOM state, memory, retrieval context, model outputs, and final responses. Those details are only useful if they are organized around the failure. We had to decide what evidence actually matters and how to present it so a developer can quickly understand the bug.
Another challenge was making the SDK safe and backwards compatible. If a debugging tool requires a major refactor, teams will not install it until after something is already on fire. That pushed us toward decorators, lightweight wrappers, local spooling, and a minimal event contract.
We also had to think carefully about production ingestion. The hackathon version uses FastAPI and live event streaming so the demo is real end to end. But the product is designed to grow into Kafka-backed ingestion, multi-tenant workspaces, event fanout, clustering, alerting, and high-volume agent monitoring.
The final hard part was closing the loop from detection to verified fix. It is easy to generate a plausible explanation. It is harder to generate a fix path. It is much harder to prove that the fix actually improves the agent. That is why Promptetheus includes Orkes-orchestrated fix dispatch, a Devin coding-agent handoff, a verification gate, and before-and-after regression evidence — and why a wrong fix is blocked rather than shipped.
Accomplishments that we're proud of
We are proud that Promptetheus already feels like a real developer tool, not just a hackathon prototype. We were able to get 24 stars and 2 real users that used promptetheus to help debug and fix their apps during the hackathon period!
We registered and shipped a real Python package that other developers can install with:
uv add promptetheus
That matters because the product only works if it is easy to adopt. We did not want a demo that only runs on our machine. We wanted something other teams could actually try.
We are also proud of how backwards compatible the integration is. The decorator-based SDK lets developers add tracing with minimal edits instead of rewriting their agent stack.
More importantly, we got buy-in from other teams who immediately understood the debugging pain. Some teams used Promptetheus-style tracing to help debug critical bugs in their own agentic applications.
That was the strongest validation for us. Promptetheus was not just useful for our demo. It helped real builders find real failures.
During the hackathon, we built the SDK, PyPI package, decorator integration, typed event schema, browser and voice tracing flows, Redis-backed vector fix-memory, FastAPI ingestion backend, Supabase storage layer, workspace-isolated service model, event streaming console, Orkes Agentspan fix orchestration, Devin fix path with a verification gate, Sentry AI-agent monitoring, regression replay loop, and three concrete silent-failure demos end to end — across browser, voice, and chat agents.
Most importantly, we built something we would actually want to use while building and debugging production AI agents.
What we learned
We learned that agent reliability is not just about catching exceptions.
Many of the most important agent bugs are semantic failures. The agent used the wrong tool. It clicked the wrong button. It ignored a spoken correction. It left a required field empty. It used stale context. It retrieved the right policy and still acted against it. It gave a confident final answer even though the user's goal was not satisfied.
Those failures need evidence, replay, memory context, root-cause analysis, fix ownership, and evals. Logs alone are not enough.
We also learned that the fix step needs verification. A coding agent can generate a patch, but that does not mean the agent is actually better. The real workflow needs before-and-after regression evidence so teams can see whether the fix improved task success, reduced regressions, and solved the original failure — which is exactly why our loop blocks an unverified fix instead of shipping it.
What's next
Next, we want to turn Promptetheus into a complete hosted workflow for teams building agents in production.
Our roadmap includes:
- Team workspaces
- Production ingestion with Kafka-backed event streaming
- Multi-tenant project isolation
- Incident clustering across repeated failures
- Sentry-style alerting for semantic agent failures
- Better browser and voice replay
- Stronger Redis-backed vector memory and similar-fix retrieval
- More advanced Orkes Agentspan orchestration for fix workflows
- Deeper Devin-powered code remediation
- Before-and-after regression eval suites
- GitHub issue and PR generation across more repos
- Support for more agent frameworks
- More decorators and adapters for common agent stacks
- Hosted dashboards for teams managing many deployed agents
The long-term vision is for Promptetheus to become the default debugging and incident-response layer for production AI agents.
When an agent fails silently, developers should not have to dig through scattered logs, screenshots, tool outputs, memory state, retrieval results, and user complaints. Promptetheus should give them the full loop: observe the run, detect the failure, replay the bad step, attribute the cause, generate the fix, evaluate the improvement, and prevent the bug from happening again.
Built With
- claude
- fastapi
- github
- next.js
- playwright
- promptetheus
- python
- railway
- redis
- supabase
- tailwind-css
- typescript
- vercel









Log in or sign up for Devpost to join the conversation.