Inspiration
As students and developers, we've repeatedly encountered the most time-consuming part of any machine learning project which is preparing the dataset. From searching across countless sites like Kaggle, data.gov, or obscure CSV files online, to cleaning the data, aligning schemas, handling nulls, and engineering features. All of it takes significant effort before we even get to model building.
We asked ourselves: what if this entire process could be automated using intelligent agents?
That question became the foundation of Data2Prompt, a fully autonomous data pipeline that converts a natural language prompt into a clean, structured, ML-ready dataset.
This would save time for students, researchers, data scientists, and developers alike, while lowering the barrier for anyone looking to work with machine learning.
What It Does
Intent2Dataset is a multi-agent AI system that transforms a user's prompt into a usable dataset by automating the entire data preparation pipeline:
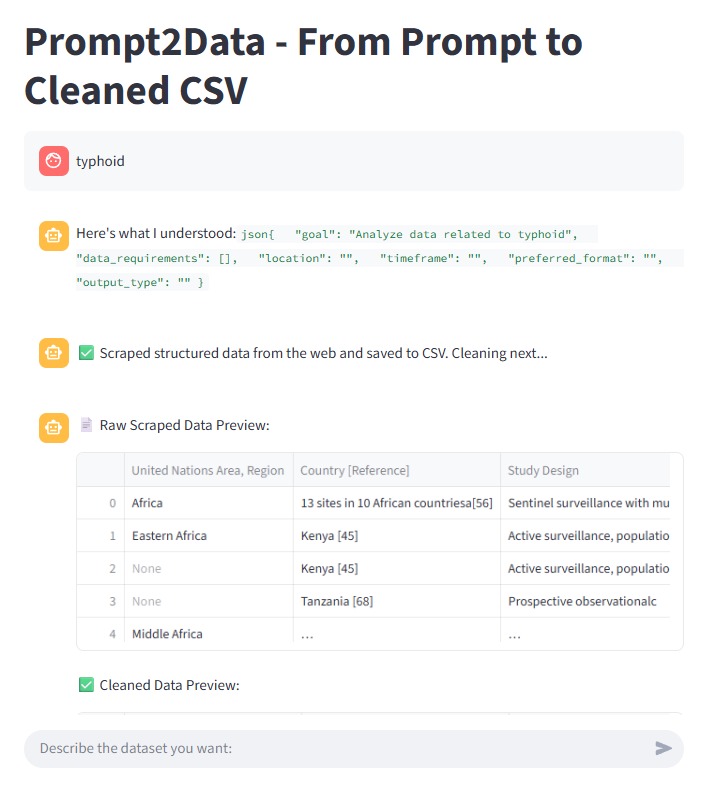
- Parses the prompt using an Intent Agent to extract the user's goal and schema requirements.
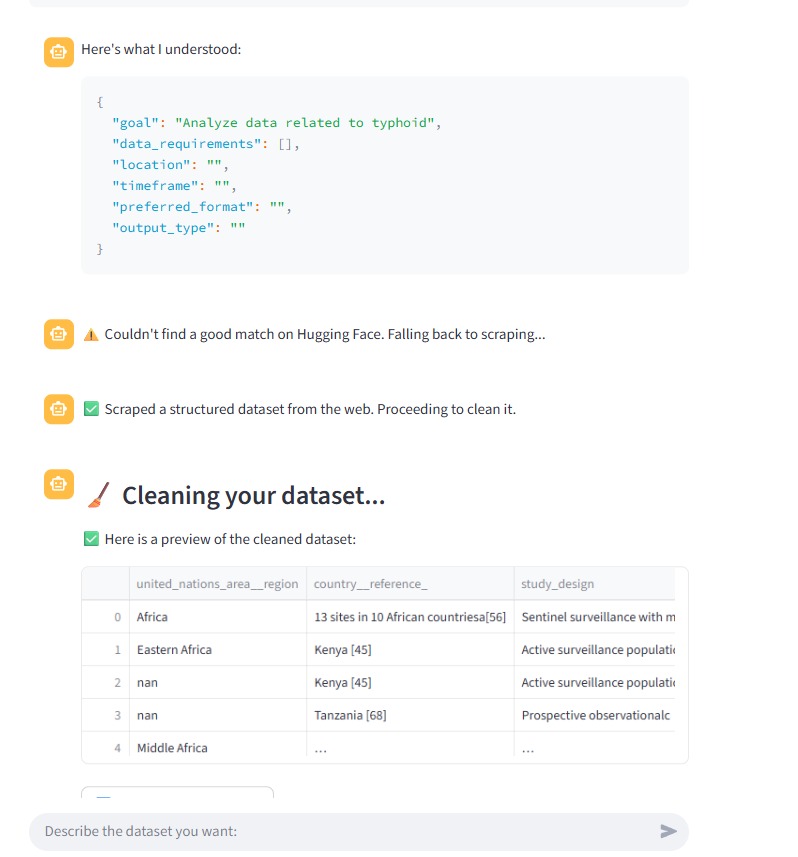
- Searches existing repositories using a Dataset Search Agent (Hugging Face and others).
- If no relevant dataset is found, activates a Smart Web Scraper Agent to find and extract tables from public websites using DuckDuckGo.
- Applies a Data Cleaning Agent to standardize the final dataset.
- Produces a single, downloadable CSV file that is schema-ready for ML applications.
How We Built It
We built Intent2Dataset as a modular, multi-agent system using:
- Streamlit for a user-friendly interface
- Claude and rule-based parsing for the Intent Agent
- Hugging Face API and DuckDuckGo search for dataset sourcing
- BeautifulSoup and pandas for scraping and table extraction
- Heuristic scoring and merging logic to prioritize and consolidate tables
- A Python-based cleaning agent to clean, deduplicate, and transform the final dataset
What We Learned
- Scraping isn't just about accessing the page, it's about identifying what data is useful and structured.
- Automating schema alignment and merging requires smart heuristics and fallback rules.
- Claude/LLMs help reduce ambiguity in prompt interpretation, but still need support from domain-specific logic.
- Even the smallest formatting inconsistencies (like duplicate columns) can break downstream pipelines.
Challenges We Faced
- Finding reliable, structured tables across a wide range of topics using search APIs
- Merging multiple scraped tables into one unified dataset for further processing
- Preventing crashes from duplicate or malformed HTML tables
- Balancing flexibility with precision across diverse domains (health, transport, crime, etc.)
- Ensuring the final output is ML-ready, not just raw scraped data
Impact
Intent2Dataset empowers anyone from students to professionals to quickly and reliably generate datasets tailored to their ML project.
By automating the most painful part of the pipeline, it allows users to spend less time cleaning data and more time building models and generating insights.
It’s not just a tool. It’s a time-saver, a workflow accelerator, and a step toward democratizing machine learning.
Built With
- claude
- duckduckgo
- duckduckgo-search
- huggingface
- python
- streamlit

Log in or sign up for Devpost to join the conversation.