Inspiration
- Observing how non-technical users struggle to get high-quality outputs from LLMs due to a lack of "prompt engineering" knowledge.
- The goal of creating a "middleman" that optimizes cost and time by reducing the need for repetitive "try-again" prompting cycles.
What it does
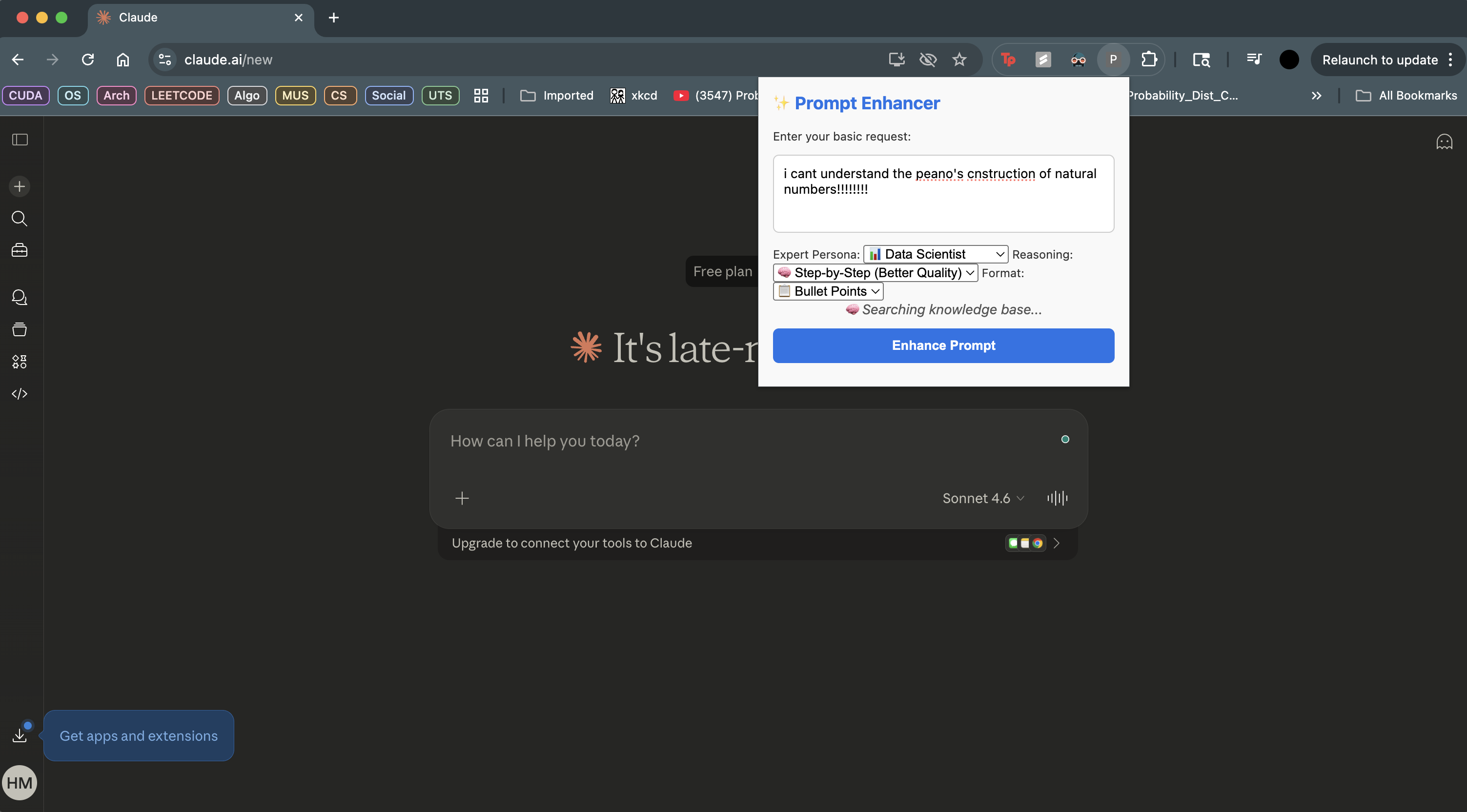
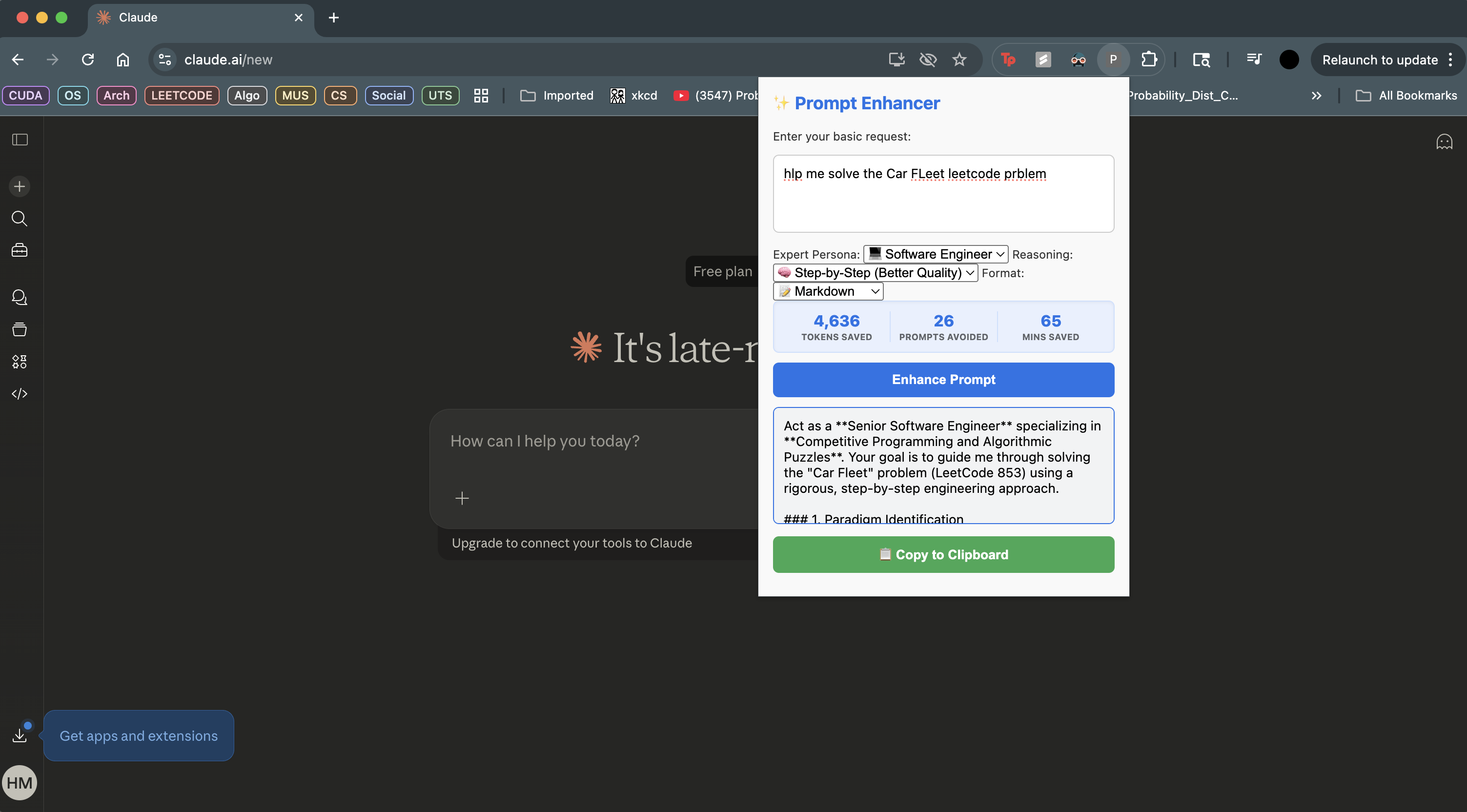
- Injects expert-level prompt engineering techniques into basic requests using a Retrieval-Augmented Generation (RAG) architecture.
- Allows users to select specific personas and reasoning modes through a Chrome Extension UI that talks to a FastAPI backend.
- Calculates and displays real-time metrics, such as estimated tokens and minutes saved.
How I built it
- Developed a FastAPI backend that utilizes ChromaDB as a vectorDB to retrieve prompt engineering research on the fly.
- Integrated the Gemini model via LangChain to synthesize the retrieved context into a final, optimized prompt. Built the frontend as a Chrome Extension using vanilla JavaScript and CSS for a lightweight, responsive user experience.
Challenges we ran into
- Fine-tuning the RAG retrieval window to ensure the context was helpful without exceeding the LLM's prompt length or distracting the model.
Accomplishments that we're proud of
- Successfully implementing a full RAG pipeline that runs locally.
- Developing a persistent metrics dashboard that tracks user impact across sessions using browser local storage.
- Creating a "copy-to-clipboard" workflow that fits naturally into a user's existing AI-assistant habits
What we learned
Too Much!
What's next for Prompt Enhance
- Porting the backend to a serverless architecture to provide a truly "always-on" global service for a wider user base
- Allow the user to personalize the choice of the RAG documents.
Built With
- chromedb
- css3
- fastapi
- html5
- huggingface
- javascript
- langchain



Log in or sign up for Devpost to join the conversation.