-
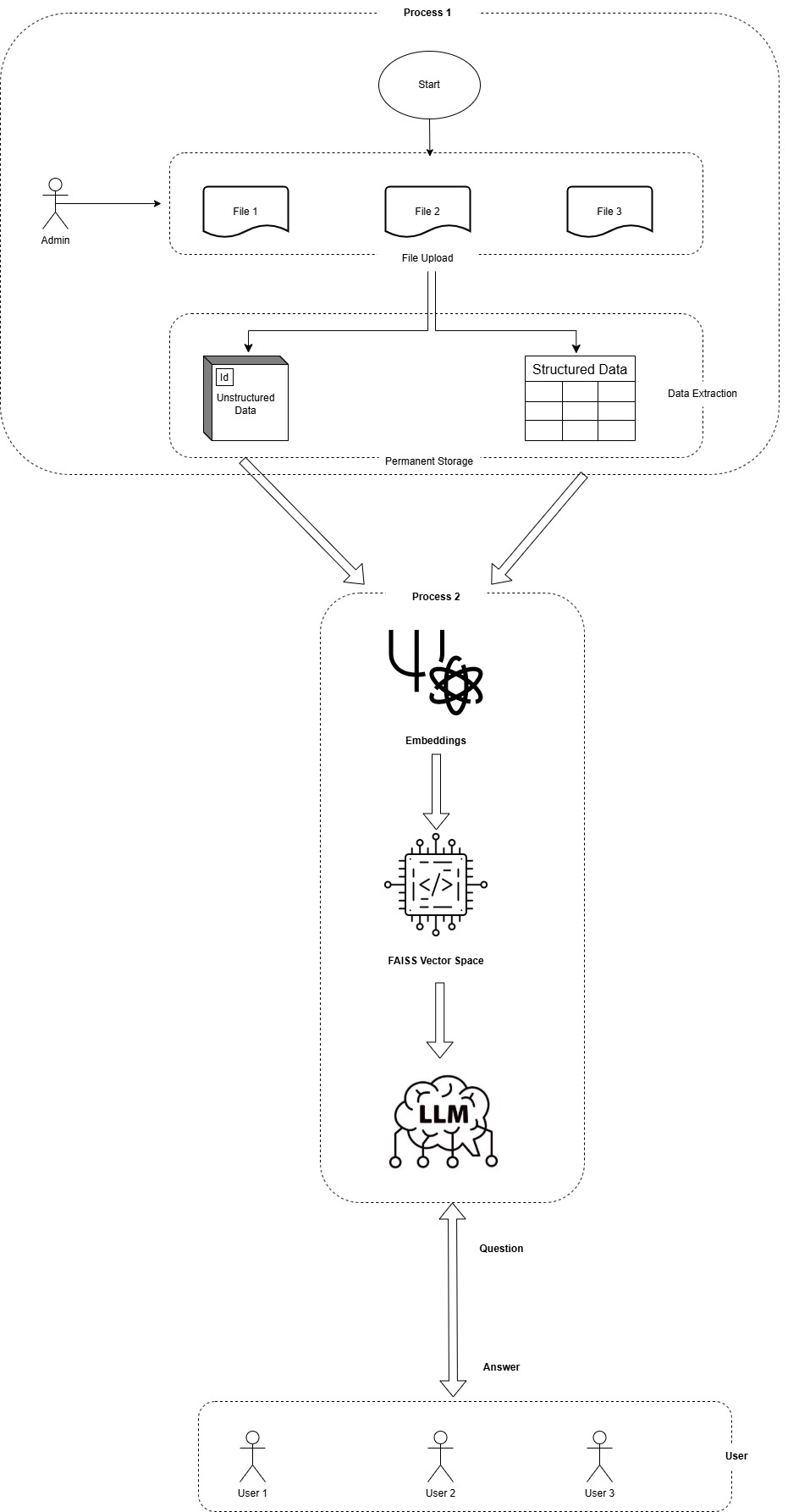
Project Flow
What Inspired Us
We were inspired by the increasing need for accessible and intelligent document understanding tools, especially for large enterprise datasets such as annual reports. Annual reports are rich in both textual and tabular data, but extracting insights from them manually is time-consuming and requires domain knowledge. With the recent advancements in large language models (LLMs) and vector search, we saw an opportunity to build a system that could make these documents more interactive, insightful, and user-friendly.
What We Learned • How to implement a Retrieval-Augmented Generation (RAG) pipeline end-to-end using open-source tools. • The practical challenges of handling unstructured vs structured data from PDFs. • How to integrate FAISS for vector indexing and Azure OpenAI for natural language responses. • Best practices for working with LLM prompts, including dynamic chart generation. • Building an interactive frontend with Streamlit and designing user-centric workflows.
How We Built the Project 1. PDF Parsing: We used PyMuPDF to extract unstructured text and tabula-py for table extraction. All parsed data is stored for reuse. 2. Preprocessing: The extracted data was chunked and embedded using sentence-transformers and indexed using FAISS for efficient semantic search. 3. Retrieval and QA: For each user question, top-k relevant chunks were retrieved from the FAISS vector space and sent along with the query to Azure OpenAI’s gpt-4o. The model was instructed to answer with source citations and optionally include ChartData in JSON format. 4. Frontend: A Streamlit app was built to serve as the user interface, allowing users to ask questions and receive both textual and visual answers.
Challenges We Faced • Data Extraction Accuracy: Extracting clean tables from PDFs using tabula-py is non-trivial. Table structures vary greatly between reports, and some were missed or distorted. • LLM Prompt Engineering: Getting consistent, clean responses that include ChartData required significant prompt tuning. • Performance: Embedding large text files and tables, and ensuring real-time interaction via Streamlit, required careful caching and optimization. • Chart Parsing: Ensuring the LLM-generated JSON was valid and rendering it reliably using matplotlib was a non-trivial integration.
Despite these challenges, we successfully built a scalable, interactive, and insightful system that transforms static PDF reports into an engaging, queryable experience.
Built With
- openai
- python
- streamlit

Log in or sign up for Devpost to join the conversation.