-
-
-
-

-
-
-
-
-
-
-
-

-
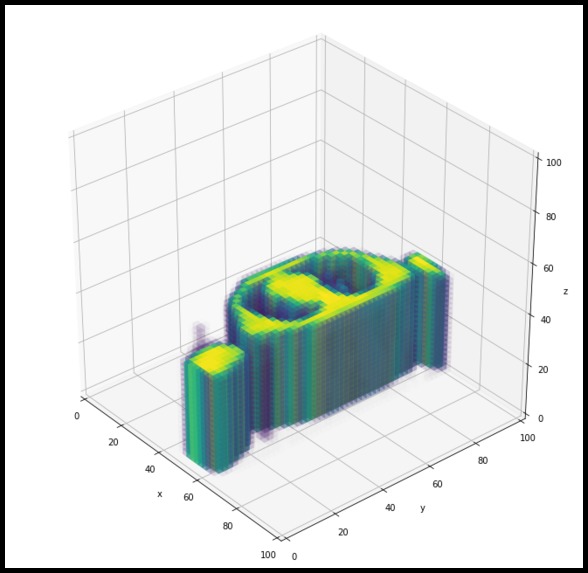
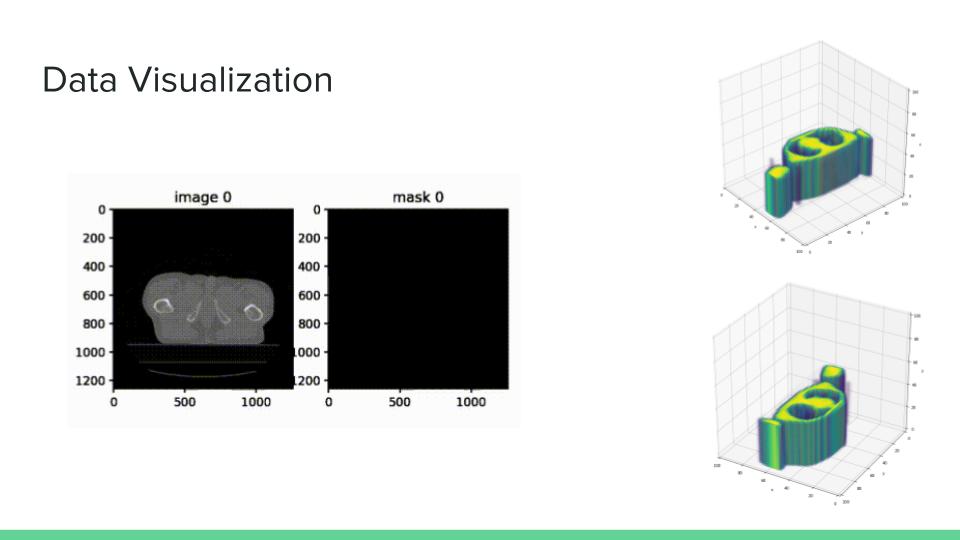
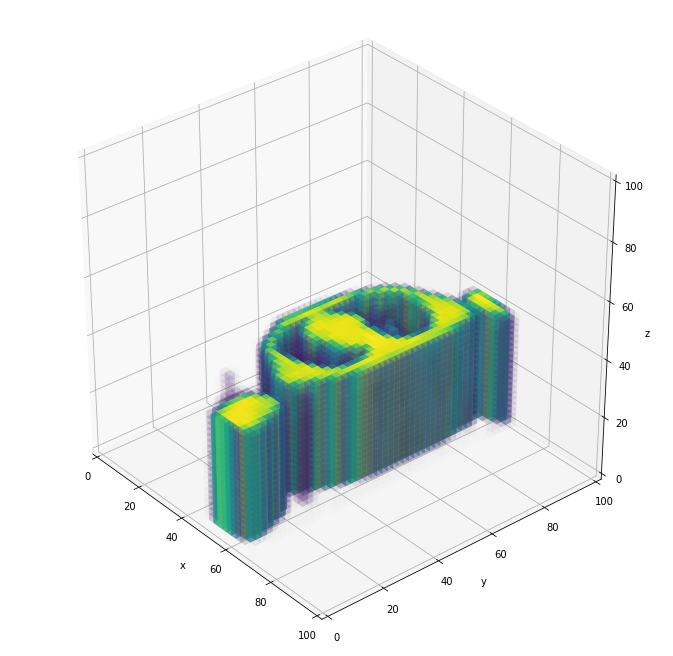
3D demonstration of train data 001
-
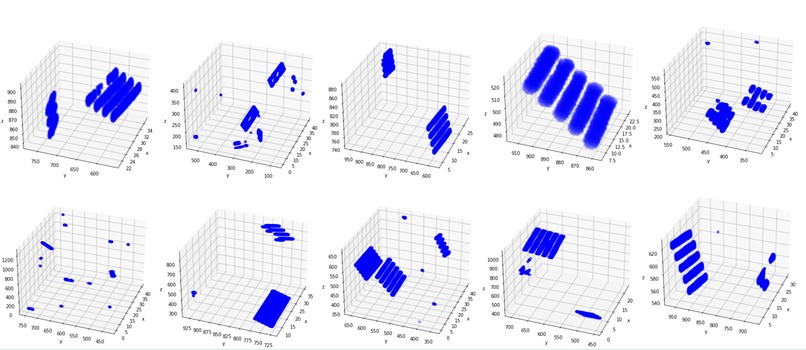
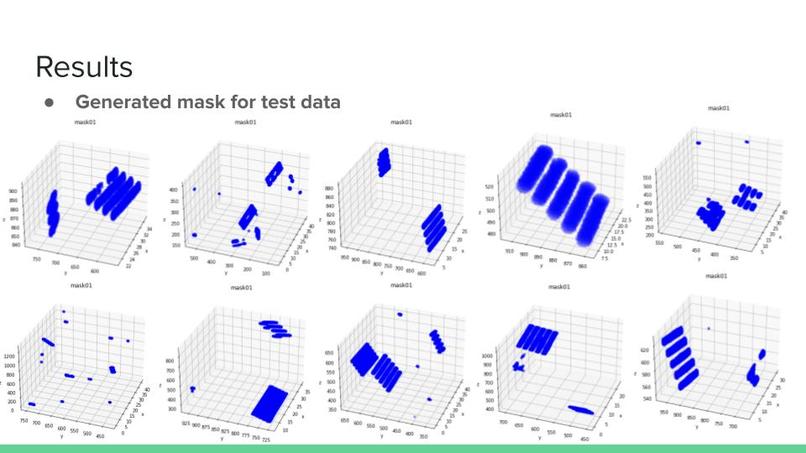
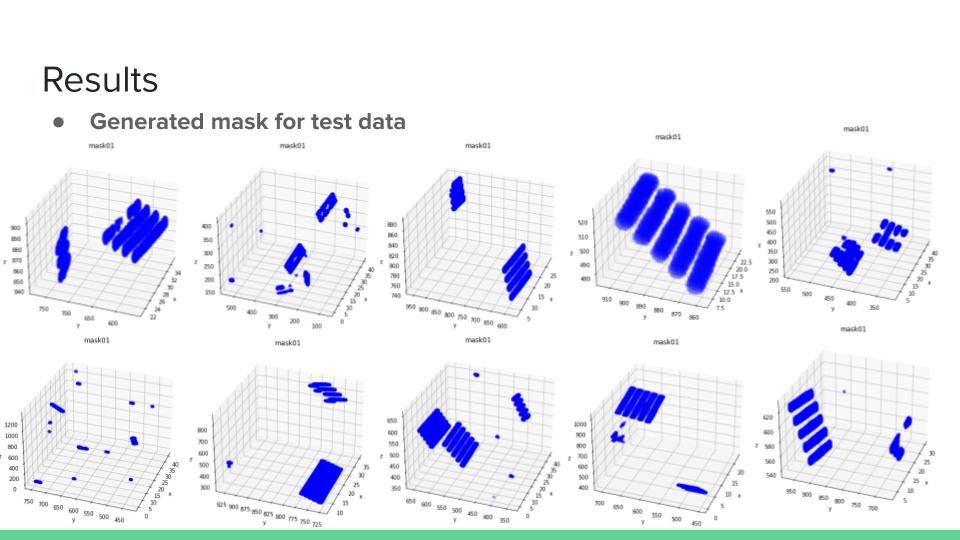
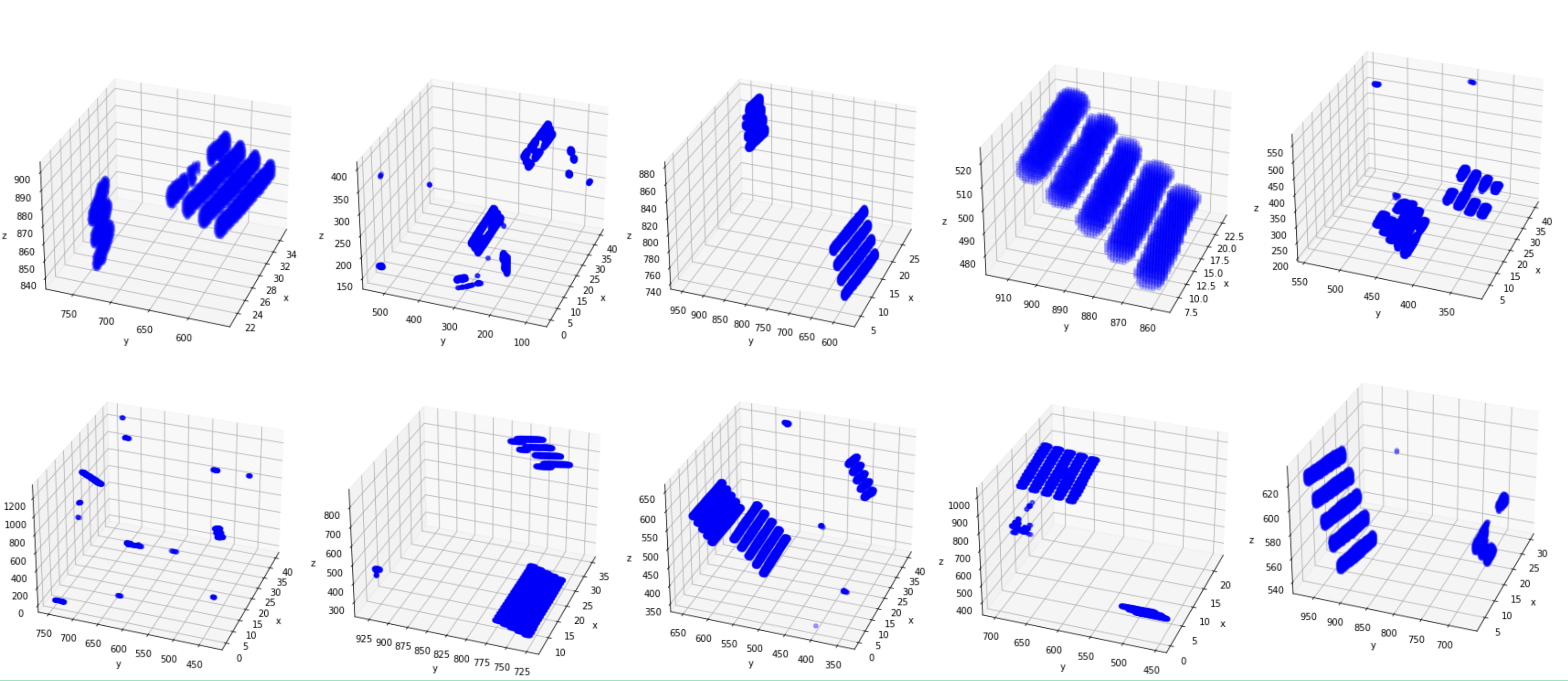
Generated mask for test data
-
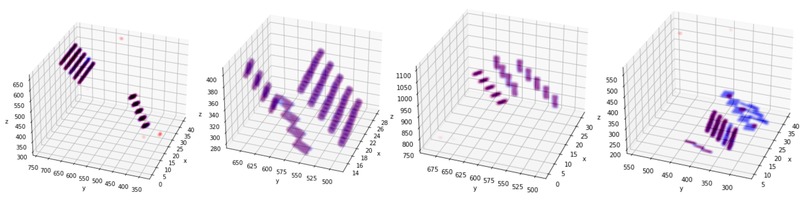
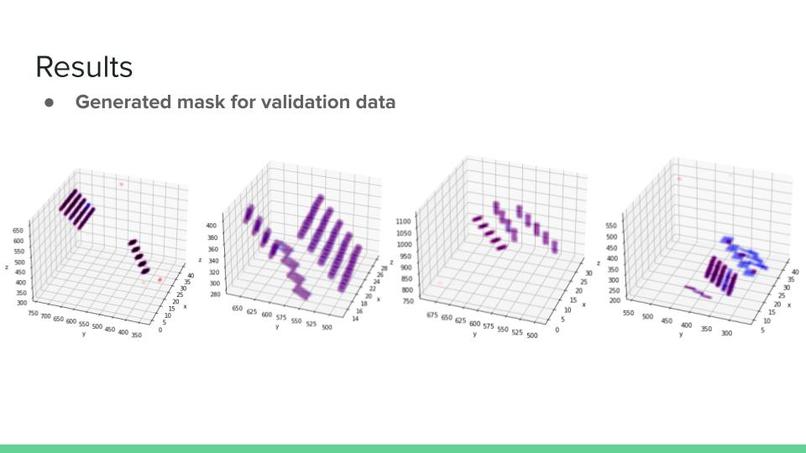
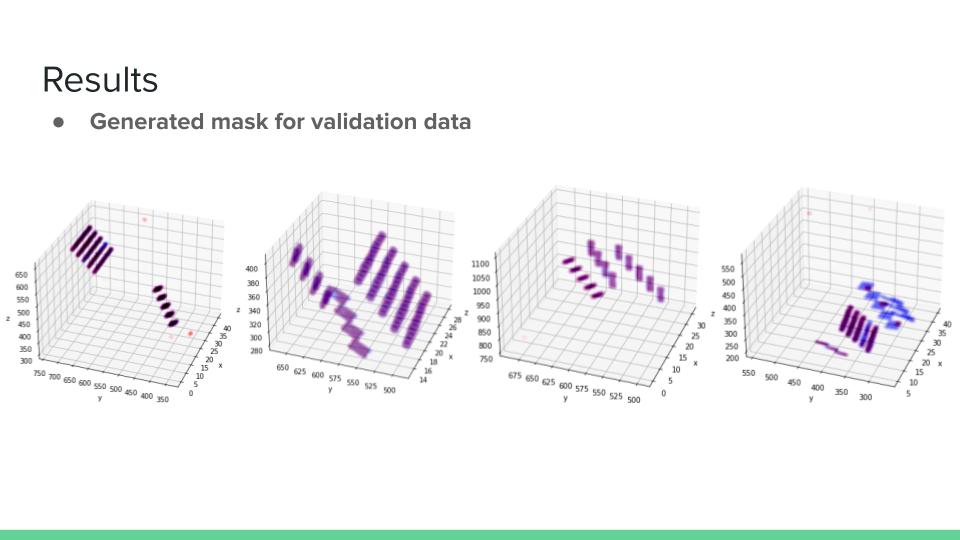
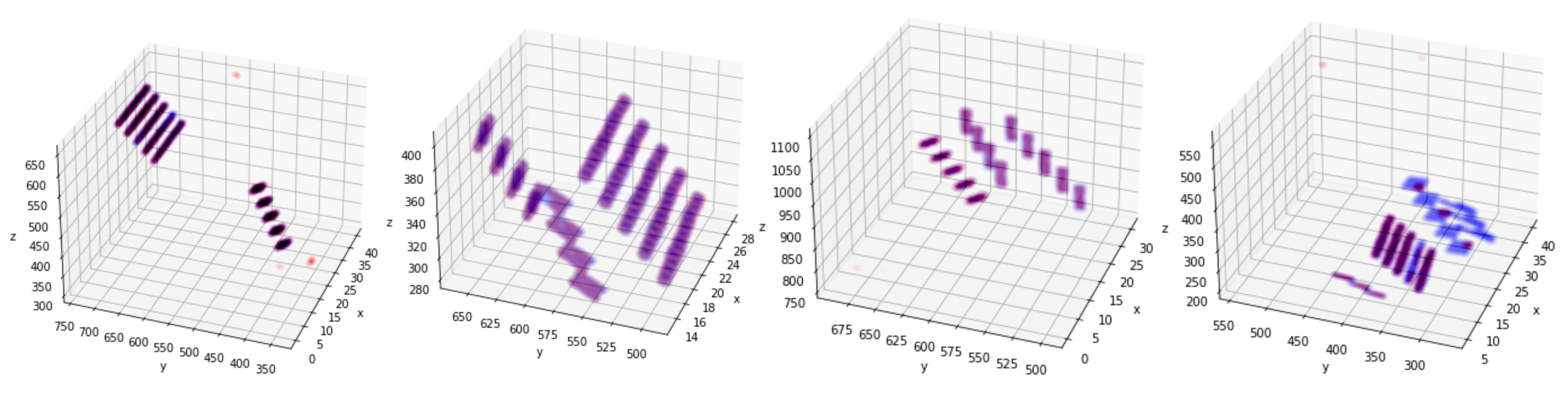
Generated mask for Validation (blue for ground-truth, red for generated))
-
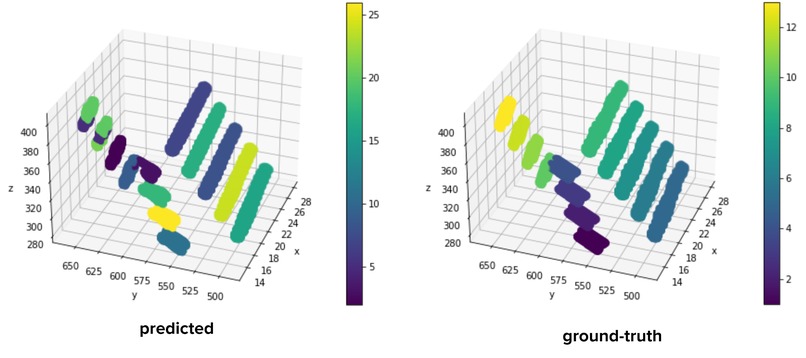
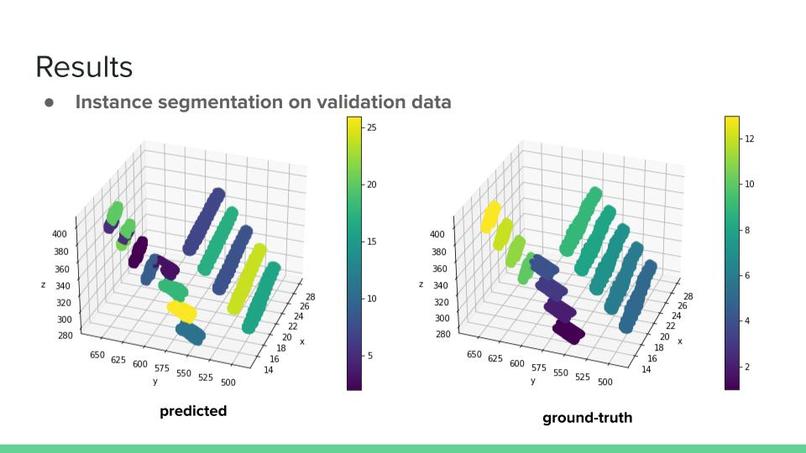
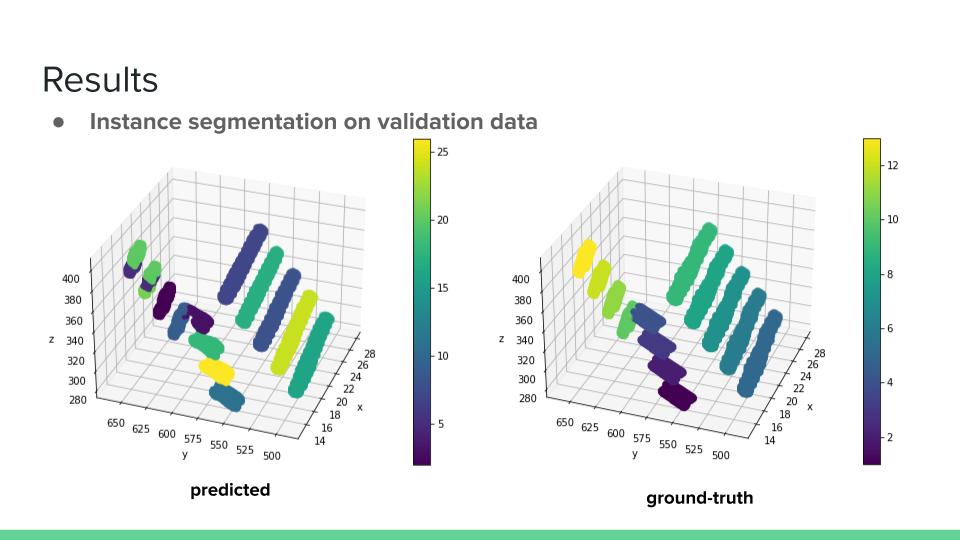
Instance segmentation on validation data
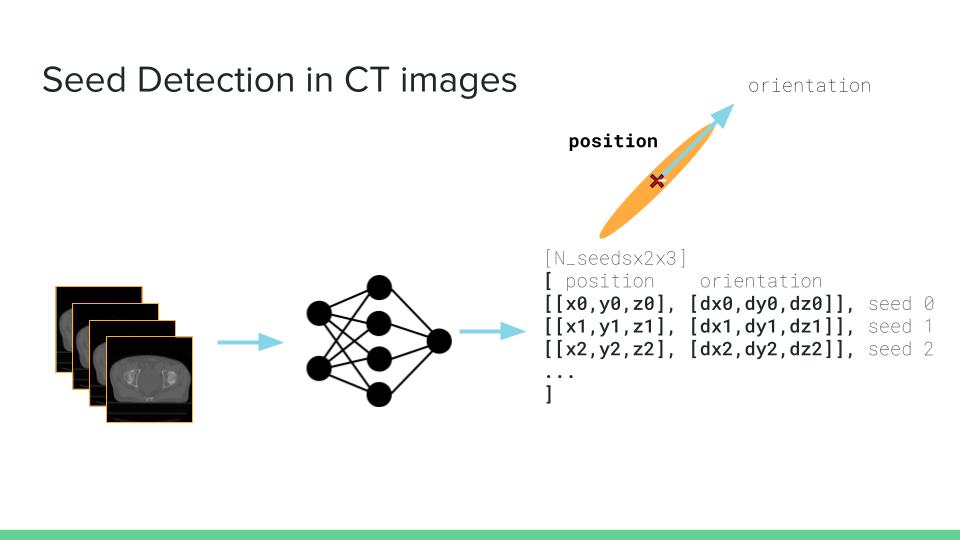


Inspiration
Inspired by some successful approaches in Statistical Machine Learning, Deep learning and Computer Vision, we designed a multi-stage pipeline to solve the problem of Seed detection in CT images.
What it does
Our approach involves multiple stages, each solving a subproblem which all contribute to solving the bigger problem.
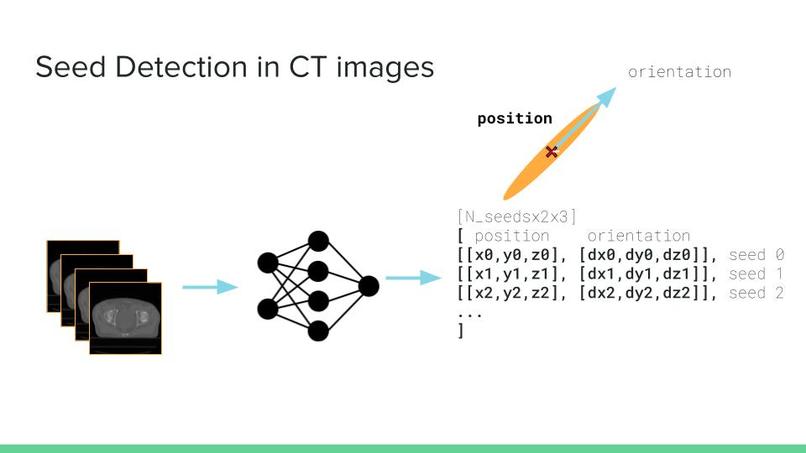
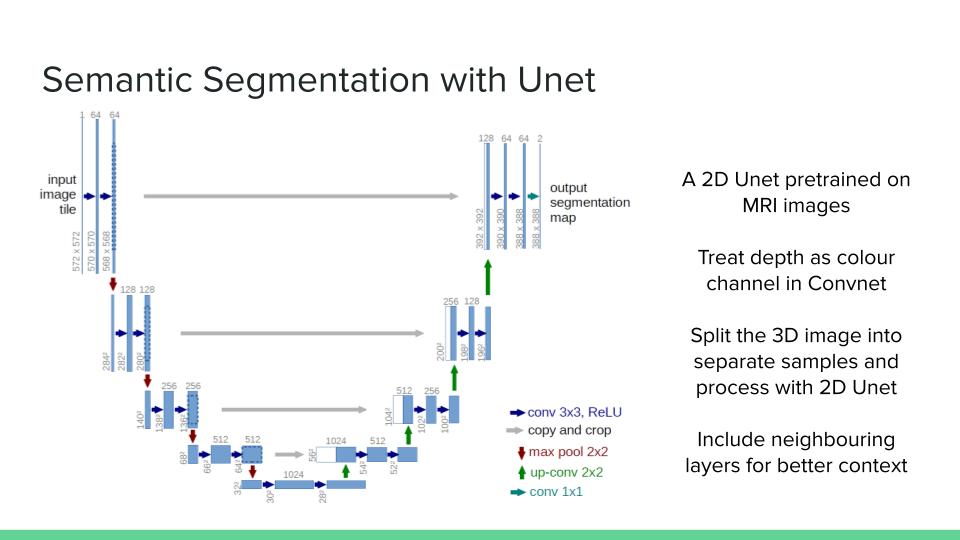
1) Semantic segmentation: At this stage we have trained a model which outputs a 3D matrix containing ones and zeros where ones indicate that at that location a seed exists. This is the same as the mask matrix but it does not indicate which seed each point belongs to.
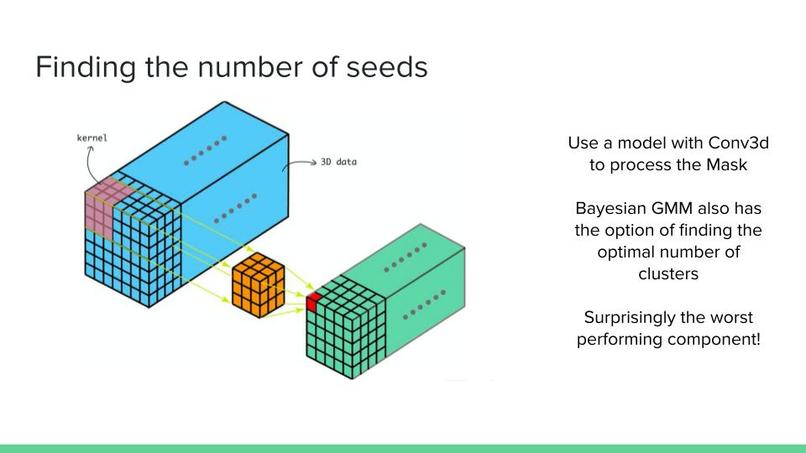
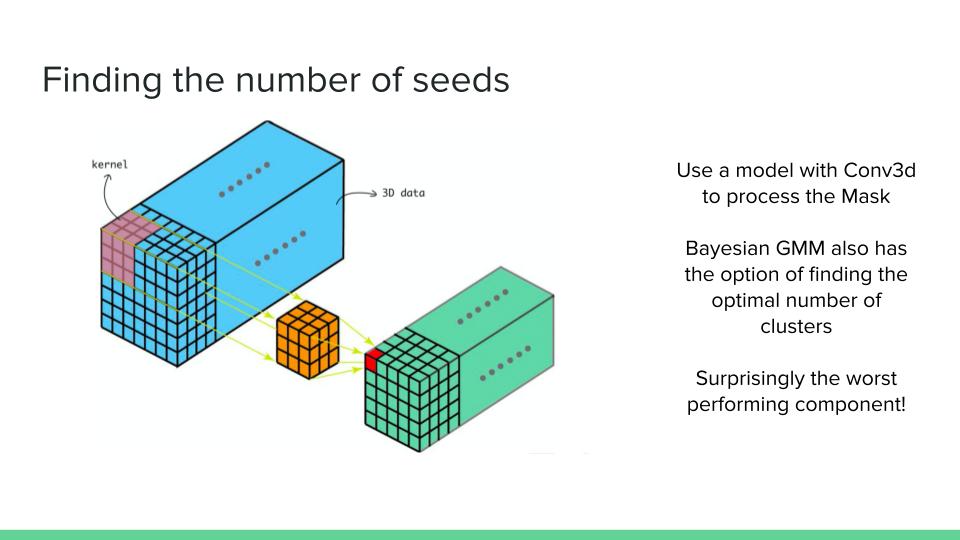
2) Seed Counter: At this stage, we use a variety of different approaches to count the number of seeds in the 3D matrix which is the output of the previous step.
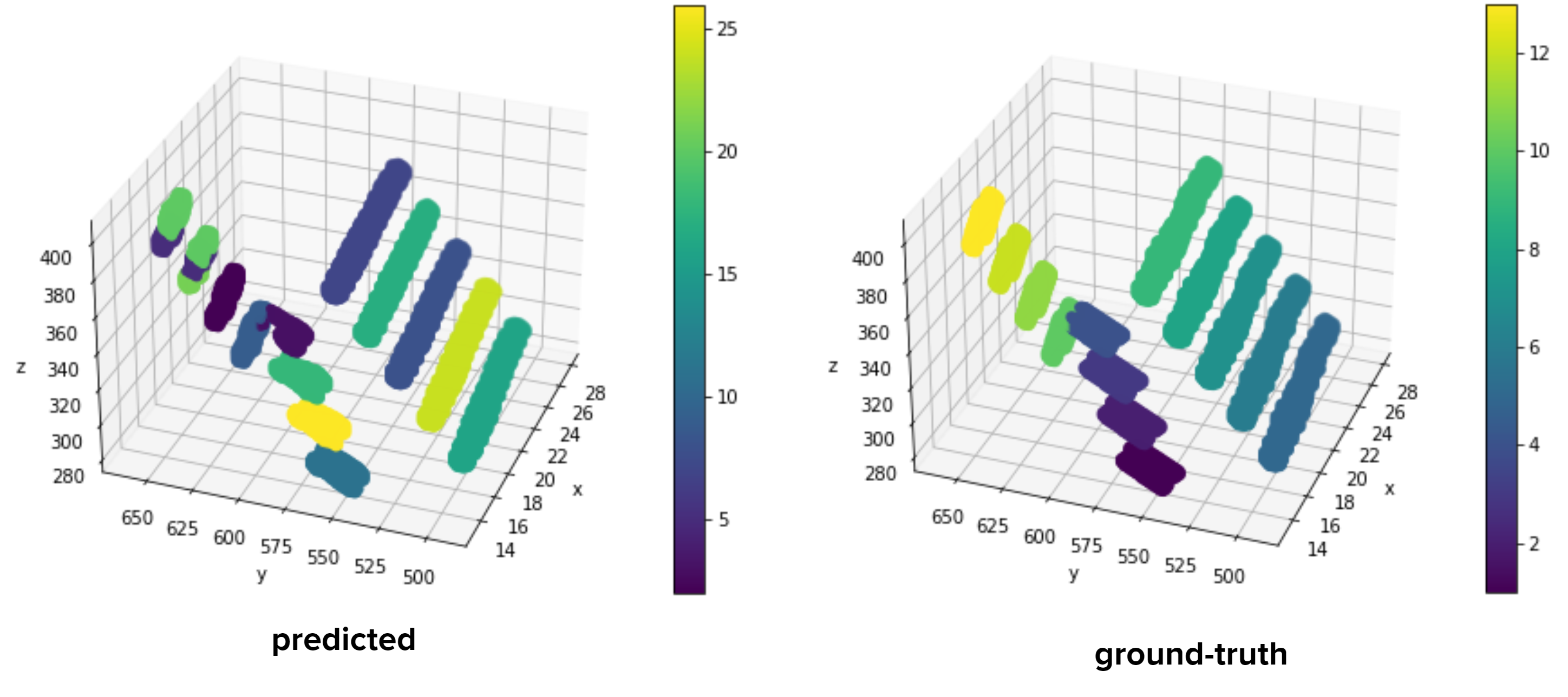
3) Instance segmentation: Given the output of stage 1, this stage is basically a clustering problem. We want to group the points found at stage 1 into k different clusters. The number of clusters was found at the previous step.
4) Finding the seed arguments: At the final step, we plan to find the seed position and orientation using all the information that we have acquired.
How we built it
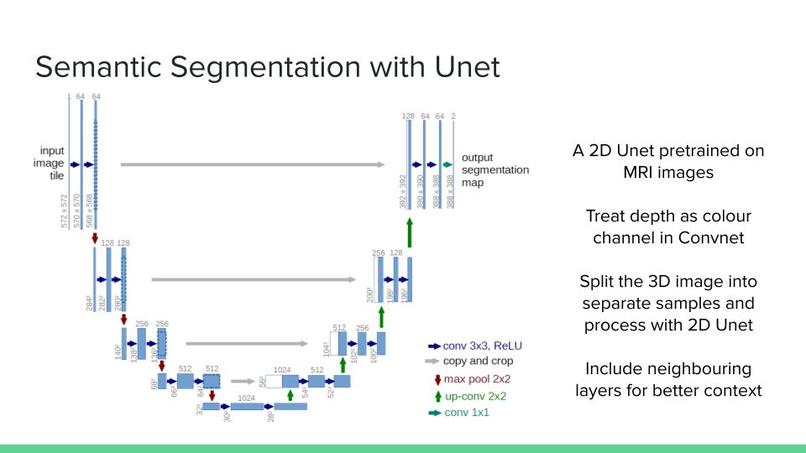
1) This step involves using a 2D U-Net pre-trained for semantic segmentation an MRI dataset. Since our data is 3d, the model cannot be used in a naive way. For each layer of the output matrix, a seperate U-net is called with the correspoding layer in input and its sorrounding two layers used as inputs. We use each as seperate channels in the 2D U-Net. This basically turns each data sample into several (usually 41) new data samples which are all used to fine-tune the U-Net.
2) This step involves counting the number of seeds given the Mask matrix. This mask matrix only has ones and zeros as its elements. Our first approach for solving this step involves using a Multi-layer neural network composed of 3D Convolution layers, 3D Batch Normalization layers, Relu activation function and Linear layers. This neural network is trained to correctly predict the number of seeds. Due to some complications, this component does not work as planned. Another approach was used which is discussed in the next section.
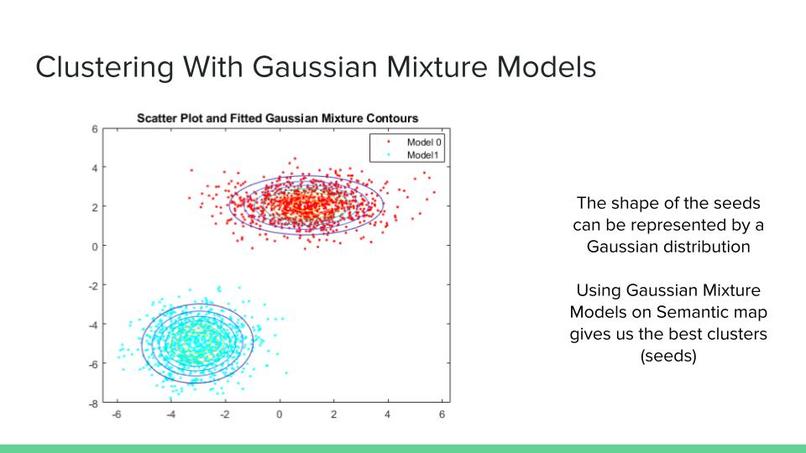
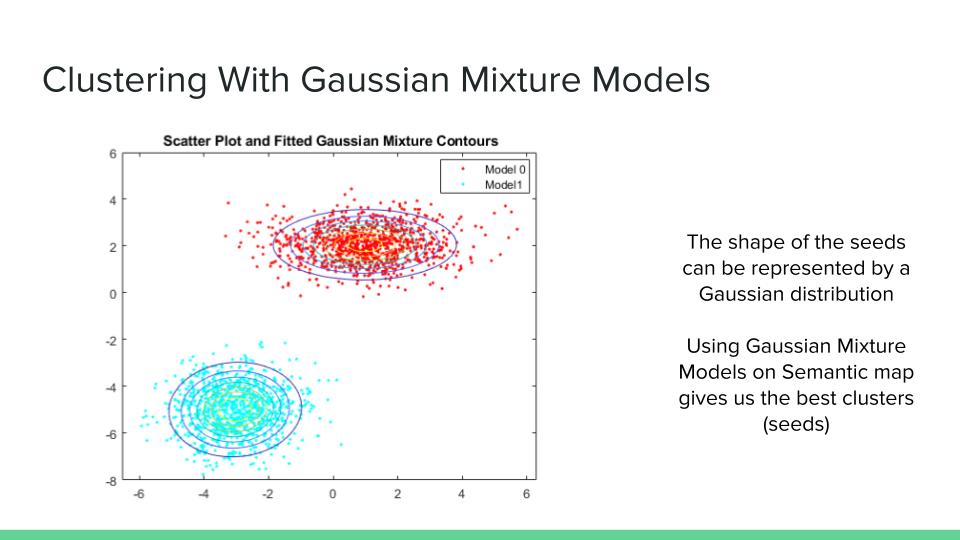
3) At this step, it is assumed we have 3D mask matrix and the number of seeds. Using this data we can use clustering methods to find the seeds. Gaussian Mixture Models are used to cluster the ones in the 3D mask matrix. It was mentioned that the Neural Network used at the previous step might not be as accurate for finding the number of seeds. Another clustering method is Bayesian Gaussian Mixture models which involves using Bayesian optimization to find the best Mixture of Gaussians. An advantage of this method is that it also finds the number of clusters that is most optimal.
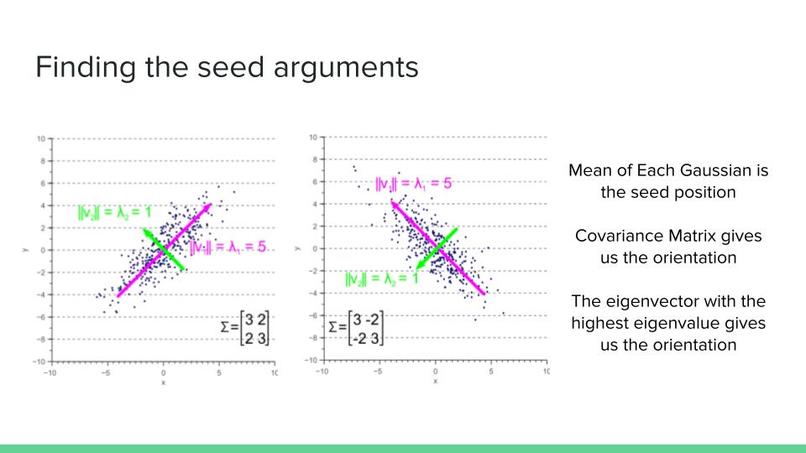
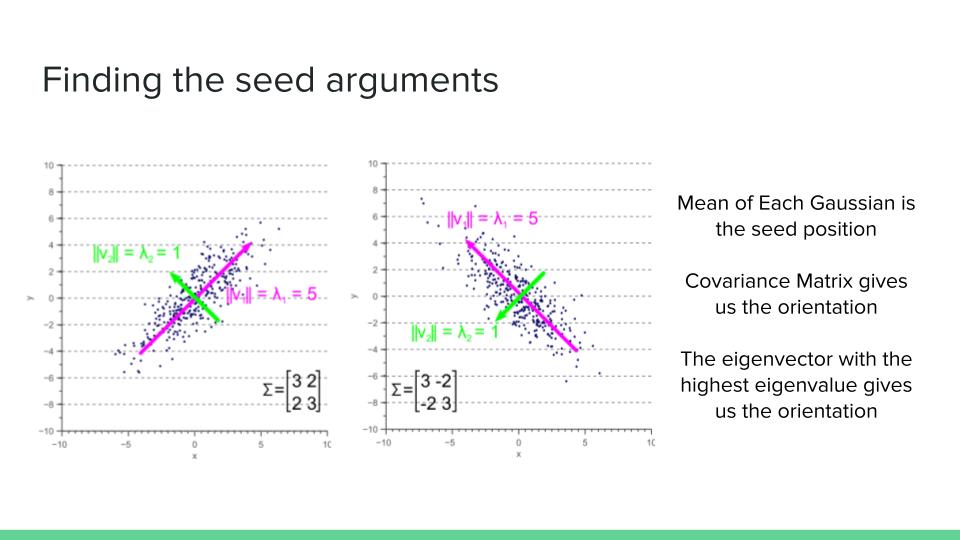
4) The final step involves finding the seed location and orientation. We find these attributes by taking a look at the mixture of Gaussian we made at the previous step. The mean of each Gaussian distribution is used as the Seed location. We use the Covariance matrix of each Gaussian distribution to find the orientation of each seed. We know that the eigenvector with the largest eigenvalue shows the direction with the largest variance in Gaussian distribution. We use these eigenvectors to find the orientation of each seed.
Challenges we ran into
It was the first time any of the group members had to solve segmentation tasks and this challenge involved a huge amount of learning for all of us. As expected we ran into plenty of challenges along the way. Some of which are listed:
1) Using 3d Unets for semantic segmentation requires a ton of GPU memory. Something we did not have. Therefore some innovations had to be made to make segmentation network fit in a GPU.
2) Lack of pretrained networks on 3D data. We had to work with 2D networks with some tricks.
3) The large size of dataset made it difficult to use compute resources other than Compute-Canada. We had to capitalize on the sparcity of the data and turn it into something more compact.
4) Comparing our clustering results with the ground truth is difficult. You do not know which computed seed corresponds to which true seed.
Accomplishments that we're proud of
We are notably proud of the following:
1) Using Masked RCNN for Instance Segmentation seemed difficult. (Lack of pre-trained models on 3D medical images) We came up with an alternative approach which involves a number of simpler subproblems which are all significantly easier to deal with.
2) Using some tricks, we used a 2D U-net pre-trained on MRI images and fine-tuned it on our 3D images. The way we use the 2D method is that we treat the depth dimension as image channels and the model has to seperately find each layer of the mask matrix. In order to make the output more accurate, we use the neighbouring layers alongside the corresponding layer from the input image. This essentially turns each sample into a number of subsamples which are independently used to train the model. The model is significantly faster and we have more samples to train our model on.
3) The idea of clustering methods was brought up during our brainstorming sessions and we found out later that using GMMs on the Mask data can find the individual seeds with very good accuracy.
4) Due to some problems with finding the number of seeds, the idea of using Bayesian GMMs was brought up and we found out that the Bayesian GMM approach was able to find the number of seeds and cluster the mask data at the same time with good accuracy. This essentially merges the second and third steps of our approach and simplifies it.
What we learned
We have gained a great deal of valuable experience with Semantic Segmentation, Instance segmentation and Medical Imaging.
What's next for our Project
Even though the individual pieces of our approach work well, we still have difficulty in using them all together to fully solve the larger problem.
We plan to include different architecture to improve our results on semantic segmentation. Also, our seed counter model still does not work well and requires further improvements. One notable improvement is treating the seed counting problem as a classification problem rather than a regression problem. This approach is used in some notable research papers before and could be the key to solve the seed counting part of our approach which is currently the main bottleneck of our method.








Log in or sign up for Devpost to join the conversation.