-
-
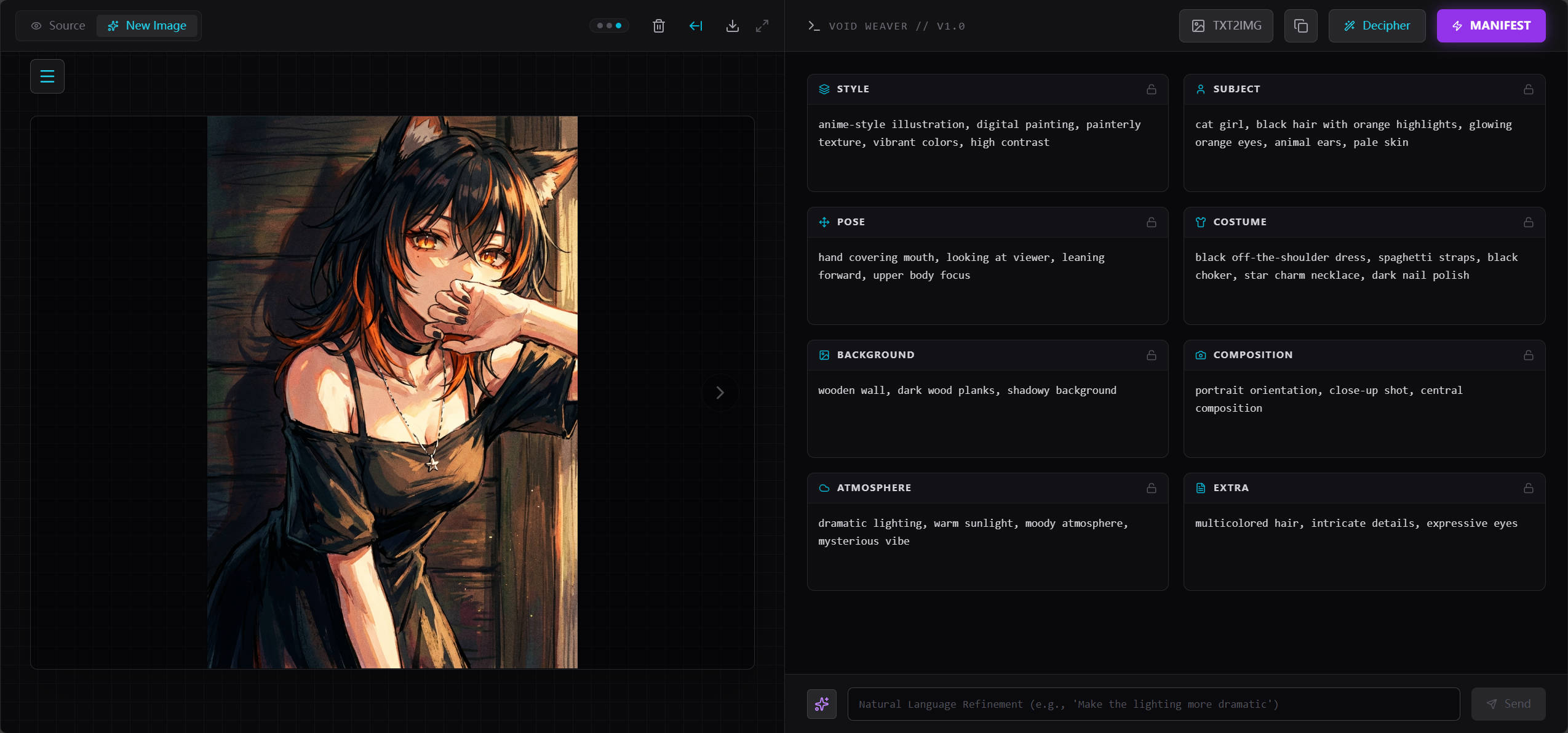
The image generation interface
Motivation
As an active AI art creator, I frequently use tools such as Nano Banana and NovelAI in daily creative work. Over time, I realized that prompt management is an underestimated bottleneck in AI image generation.
Producing a high-quality image usually requires modular consideration of multiple elements, such as clothing, facial features, pose, background, and composition. When these elements are mixed into a single monolithic prompt, later adjustments and iterations become cumbersome and inefficient.
In addition, when encountering appealing reference images, it is often easy to understand them visually but difficult to accurately describe them in language. This gap between visual perception and textual expression significantly limits prompt-based creation.
Based on these observations, this project aims to build an AI art tool that aligns more closely with human creative workflows and makes prompt construction and refinement more intuitive.
Overview
Void Weaver is an AI art prompt management and generation system built around an Agentic Workflow.
Its core engine, Deep Thinking, is inspired by the way human artists work. Instead of treating image generation as a single step, the system decomposes the process into multiple controllable stages, including:
- Initial sketch generation
- Visual structure and composition inspection
- Style and consistency alignment
- Prompt refinement and restructuring
This staged and traceable workflow significantly reduces randomness in AI-generated results and improves both stylistic and structural consistency.
The system integrates Google Gemini 3.0 Pro for general reasoning and multimodal understanding, alongside NovelAI V3 for anime-style image generation. A visualized UI exposes intermediate outputs at each stage, allowing users to understand and actively intervene in the generation process.
Development
The project adopts a modern frontend–backend separated architecture.
The backend is built with Java 17/18 and Spring Boot 3.2. OkHttp is used to manage complex multi-model and multi-stage AI invocation chains. To support long-running agent workflows, Server-Sent Events (SSE) are employed to deliver real-time streaming responses lasting several minutes.
The frontend is developed using React 18, TypeScript, and Vite 5, with Tailwind CSS for styling and Zustand for state management. This setup ensures a smooth and responsive user experience, even when handling large image data and real-time log updates.
Use of Gemini 3.0
1. Visual Reasoning
During the “visual inspection” stage of the Deep Thinking workflow, the system leverages Gemini 3.0’s multimodal capabilities to analyze generated sketches at a structural level, including human proportions, lighting direction, and perspective.
Compared to text-only models, Gemini can combine visual input with general world knowledge to identify clearly unreasonable details, such as extra fingers or incorrect joint structures. This capability stems from its native multimodal architecture.
2. Long-Context Reasoning
Throughout the multi-stage generation process, the system maintains a shared context chain across steps. Gemini 3.0 is able to consistently understand and preserve this context, allowing later stages such as style alignment and prompt refinement to inherit the original creative intent without noticeable drift.
3. Multi-step Reasoning and Intermediate Output Generation
Thanks to Gemini 3.0’s fast response time, the system can perform multiple rounds of analysis and text generation within a single workflow execution. Intermediate reasoning results are streamed to the frontend as real-time logs.
This immediate feedback mechanism improves user experience and keeps the complex agentic workflow transparent and traceable.
Challenges
Several technical challenges were addressed during development:
- Fragmentation of large SSE data streams
- Timeout handling and reconnection for long-lived connections
- Unstable JSON parsing caused by non-standard model outputs
To mitigate these issues, an additional robustness and cleaning layer was introduced to safely process incomplete or malformed responses.
Furthermore, careful negative prompt design was applied to reduce common AI-generated artifacts such as plastic-like textures and overly glossy highlights, resulting in images with a more hand-drawn appearance.
Achievements
One of the key achievements of this project is the implementation of a feedback-loop–based Critique module.
This module functions as an independent agent that evaluates generated images from both structural and visual perspectives, then feeds improvement suggestions back into subsequent generation stages, forming an iterative optimization loop.
In addition, the system successfully implements multimodal streaming, mapping backend multi-stage reasoning processes into real-time, visualized frontend logs. This significantly enhances user trust and understanding of the AI creation process.
Reflection
A key takeaway from this project is that prompt engineering itself is a form of high-performance programming.
Simple API calls tend to produce highly stochastic results. Only by carefully constructing context chains and constraints can large models be guided reliably toward a specific creative goal.
In agentic workflows, robustness is more critical than feature completeness. A timeout or parsing failure at any intermediate stage can break the entire pipeline. As a result, significantly more effort was invested in error handling and data sanitization than initially expected—an essential tradeoff for building a stable system.
Future Roadmap
- Multi-Agent Collaboration Introduce specialized agents for color, composition, and detail refinement to simulate a studio-style collaborative workflow.
- Localized Memory Enable the system to learn and retain users’ stylistic preferences and world-building settings, supporting consistent and personalized long-term creation.
- Dynamic Inpainting Allow users to trigger Deep Thinking on specific regions (such as hands or faces) instead of regenerating the entire image each time.
Built With
- gemini-3-pro-image-preview-&-gemini-3-flash-preview
- java
- maven
- react
- rest-api
- server-sent
- spring-boot
- typescript
- vite


Log in or sign up for Devpost to join the conversation.