-
-
Merged Data
-

"Fair" Water Quality Prediction
-
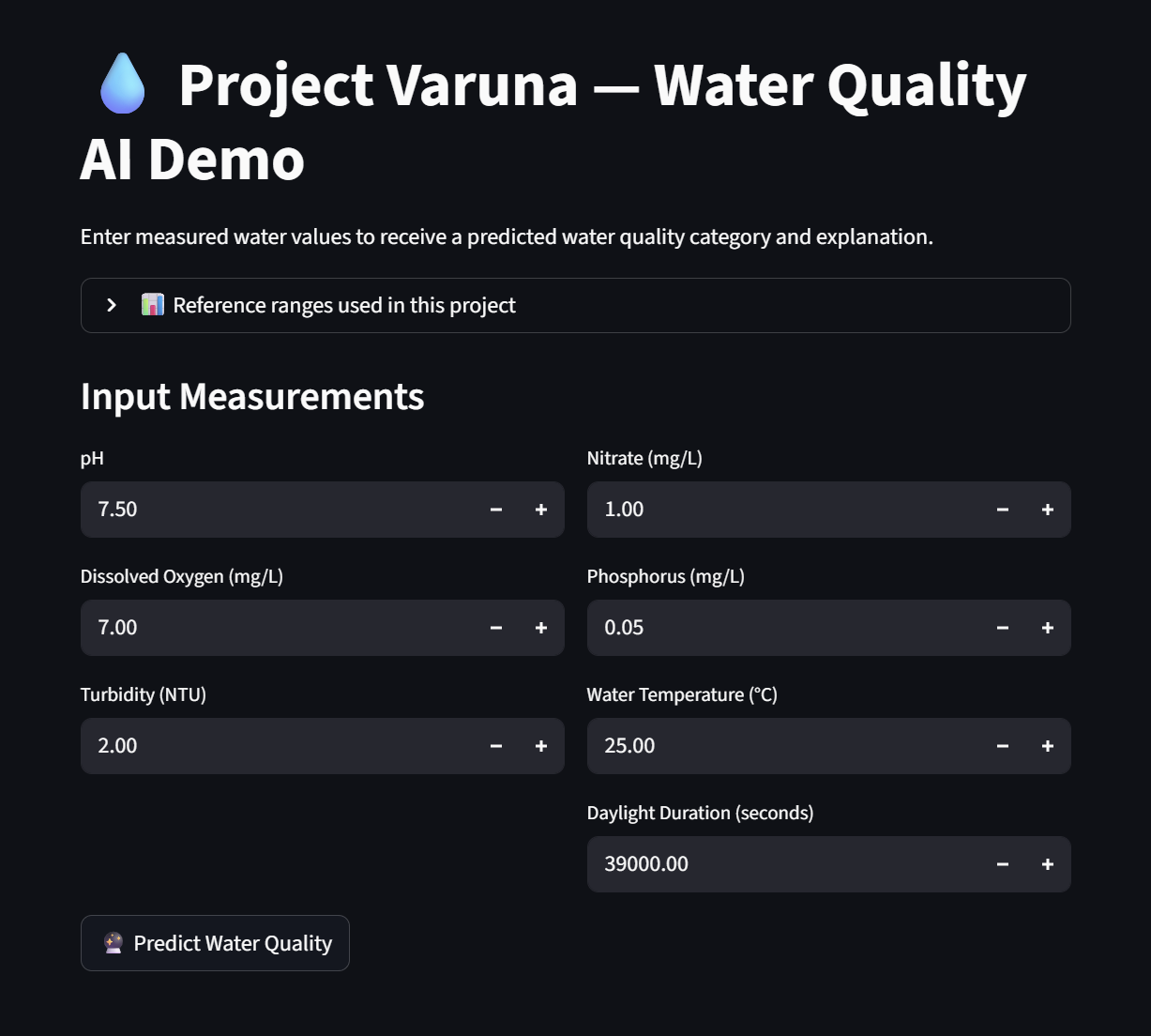
Demo Screenshot
-

"Poor" Water Quality Prediction
-

"Good" Water Quality Prediction
-

Page 1
-
Page 2




Inspiration
Water consumption is one of the most imperative necessities for human health and survival. Fresh, clean water ensures the betterment of the environment and the human population. Ensuring the purity of water makes our lives easier and allows us to focus on innovation and creation in other fields because we are able to live without any impurities in the water we drink everyday contaminating our well-being. However the process of figuring out whether our everyday water is good or not is a very time-consuming process, as scientists have to go through thousands and thousands of variables to try and figure out water quality. This leaves a large room for error, as they have to sort through multiple datasets, and if an error is made, then it takes months to retrace that data. When we were researching the effects that commercialization had on underserved populations, we found that access to reliable information about water quality was often limited. This made water safety not just a global issue, but a local problem that directly affects communities around us. Seeing how difficult and time-consuming it can be to determine whether water is safe inspired us to focus on creating a solution that could simplify the process and make water quality analysis more accessible and efficient.
What it does
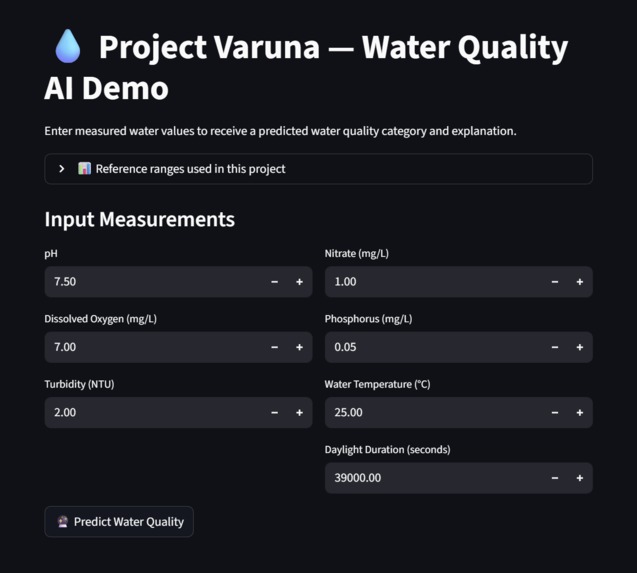
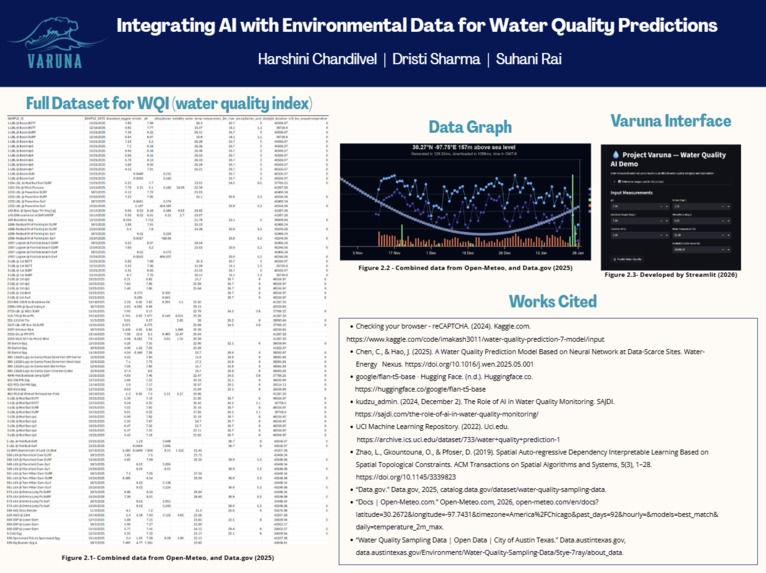
The understanding of probable issues or hazardous changes to water quality helps people identify risk areas and mitigate the possibility of impure water. Varuna: Integrating AI with Environmental Data for Water Quality Predictions will be accessible to all and will update frequently, minding climate change, and other unpredictable factors. Especially in Austin, Texas we have a wider breadth for data as our state is not usually prepared for drastically changing winter weather. AI can transform water quality monitoring by analyzing real time data, identifying patterns, and making predictions that enable more proactive water management. Varuna predicts water quality for Austin by getting weather data from the Austin area and the water quality variables- dissolved oxygen, nitrate, phosphorus, turbidity, water temperature, precipitation sum, daylight duration and evapotranspiration. These key factors helped drive the ai model we made to find and analyze patterns found in the data set involving these variables to predict whether or not the water quality is good, fair, or bad.
How we built it
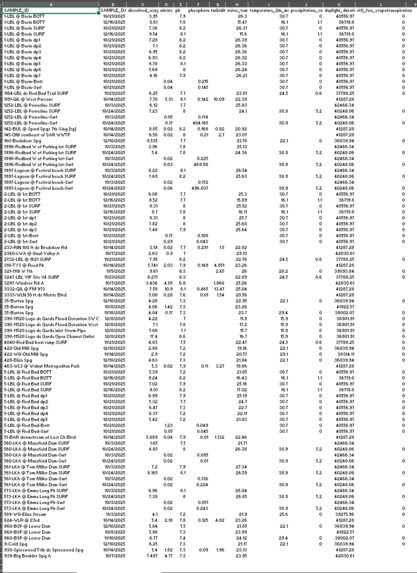
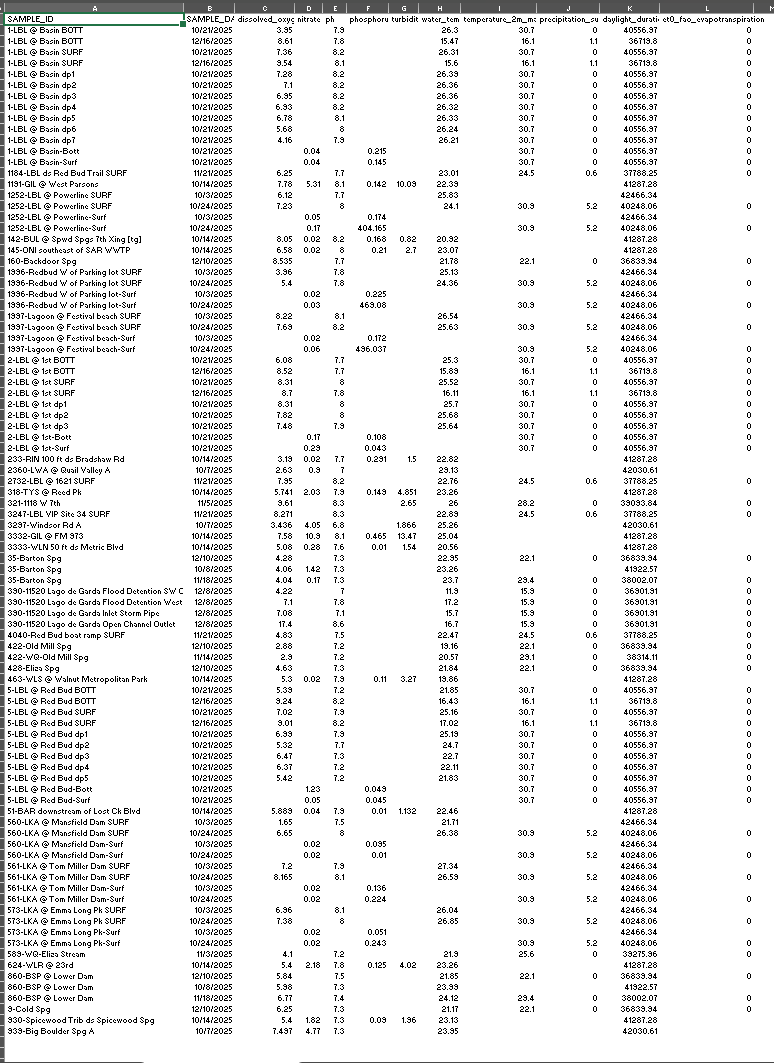
Procedure Data Collection Data used in this study was collected from publicly accessible water quality sampling datasets, OpenMeteo for weather and City of Austin for water quality.. The datasets included physicochemical parameters such as pH, dissolved oxygen, turbidity, nitrate, phosphorus, and water temperature. Environmental data was collected from publicly accessible weather data sources. Environmental data included daily environmental parameters such as daylight duration and temperature. No physical samples, chemicals, or biological materials were used. Data Cleaning and Preprocessing The data cleaning of the water quality dataset involved the removal of invalid data, standardization of the columns, and filtering of the data based on parameters that are of interest in the assessment of water quality. The data was also transformed from a long format to wide format so that each sample of water corresponds to a single row with multiple columns. The data cleaning of the environmental dataset involved the removal of metadata, standardizing column names,converting dates into a consistent format, and eliminating duplicate entries. When new environmental data was obtained, the old and new data was combined programmatically. Dataset Integration The cleaned water quality and environmental datasets were integrated based on their common key, which was the sampling dates. This led to the creation of a single dataset that contained both water quality and environmental data. The data was made consistent by keeping only those records that had overlapping dates. Water Quality Index (WQI) Labeling A Water Quality Index-based system of categorization was also implemented using scientific thresholds for important parameters like pH, dissolved oxygen, turbidity, and nitrate concentration. A sub-score was assigned to each parameter depending on the range within which it fell—optimal, moderate, and poor ranges. A water quality category was assigned by summing up the sub-scores for each parameter. This process of labeling the water samples with categories was used for machine-learning training. Baseline Machine Learning Model A Random Forest classifier was used to train a model on the labeled dataset, predicting water quality categories based on numerical input data. The data was split into a training set and a test set, with accuracy, precision, recall, and feature importance used to test the model's performance. The feature importance values helped identify significant water quality drivers, such as dissolved oxygen, nutrient concentration, and pH. Explainability Layer The results obtained from the feature importance of the baseline model were utilized to generate rule-based natural language explanations for each sample. These explanations described the reason for the sample’s classification into a particular category based on scientifically relevant factors, such as low levels of dissolved oxygen and high levels of nitrates. AI Model Fine-Tuning (FLAN-T5) The data was transformed into instruction-response form, which is applicable for large language models. In this case, the instructions were related to numeric water quality and environmental measurements, while the responses included water quality categories and explanations. A FLAN-T5 transformer-based model was used for fine-tuning to jointly classify water quality and generate human-readable explanations from numeric data. Model Testing and Demonstration The trained FLAN-T5 model was subjected to testing using new or simulated realistic values for the input variables. The goal of the testing was to assess the model’s ability to generalize the predictions. The AI model’s predictions were compared with the baseline model predictions for the purpose of testing the interpretability of the model. A local interactive web-based demo was developed.
Challenges we ran into
One limitation of this study is the limited geographic scope, as the model was initially trained using water quality data primarily from the Austin area. Because environmental conditions, pollution sources, and seasonal patterns vary across regions, the model’s performance may change when applied to new locations without additional training data. In addition, the water quality categories were derived from predefined thresholds, which may simplify complex environmental interactions.
Because the dataset currently spans only four months and does not include severe storm conditions, the model’s ability to predict nitrate fluctuations related to heavy rainfall is limited. Ongoing data collection will strengthen predictive accuracy and generalizability over time.
Accomplishments that we're proud of
We used this AI Model to participate in our Regional Science Fair and were able to place 3rd for our event. We are also expanding our project to multiple areas in Texas rather than only Austin.
What we learned
We were able to meet with an Environmental Specialist from City of Austin who helped us so much in our understanding about what truly affects water quality, like turbidity being how dirty the water is, and then dissolved oxygen which affects the insects and animals that reside in water. We learned a lot also about the extremely laborious process and how helpful our tool can be instead of them having to go through so many variables to try and figure out the water quality.
What's next for Project Varuna
In the future, we hope to expand this project beyond the Austin area by first implementing the system in additional regions across Texas, such as Dallas and Houston. After validating the model’s performance across multiple cities, we plan to further expand the system to other states in order to evaluate its scalability and adaptability to different environmental conditions.
Built With
- city-of-austin-environmental-data
- flan-t5
- numpy
- open-meteo-forecast
- pandas
- python
- random-forest-classifier

Log in or sign up for Devpost to join the conversation.