-
-
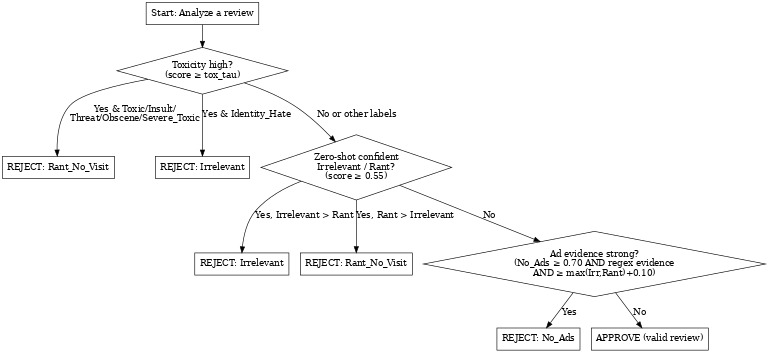
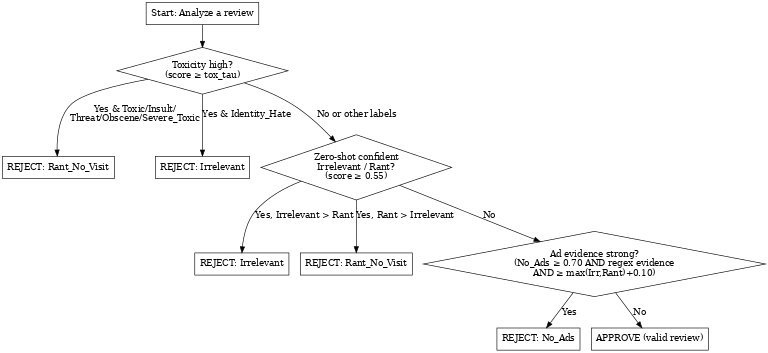
Flowchart for filtering out false reviews
Project Sugamen: ML for Trustworthy Location Reviews
Inspiration
We have all searched for a cafe or gym - only to be met with reviews that felt off. Spam, ads and irrelevant rants bury the truth. This left us pondering: how can we protect our forums and ensure our decisions are not based on lies?
What it does
Project Sugamen uses AI to bring clarity back to online reviews. It filters noise, flags irrelevant content, and ensures only authentic, helpful voices shape how we discover places.
Our group chose to tackle Problem statement 1 - Filtering the Noise: ML for Trustworthy Location reviews. The Review-Rater system addresses the critical challenge of automatically assessing the quality and relevancy of location-based reviews to maintain platform integrity and user trust.
Policy Violations Addressed
The system tackles three primary policy violations that affect Google reviews:
- No Ads Policy: Detecting promotional content, referral codes, and commercial solicitations
- Irrelevant Content: Identifying off-topic posts unrelated to the business (politics, crypto, personal stories)
- Rant No Visit: Filtering generic negative rants without evidence of actual visits
How we built it
To build this project, we had to utilise machine learning with policy-driven logic. From preprocessing texts to feature engineering sentiment, relevance, and metadata, we designed a system that learns to judge reviews as humans would, but even better.
Solution Approach
Our solution employs an AI ensemble approach that combines zero-shot classification, toxicity detection, and spam detection to achieve policy violation detection while minimizing false positives in legitimate reviews.
Hierarchical Policy Detection
The system uses a hierarchical policy detection approach:
- Toxicity Gate: Identity hate → Irrelevant; Toxic/insult → Rant_No_Visit
- Zero-Shot Classification: Multi-label classification against policy categories
- Evidence-Based Ads Detection: Regex patterns + confidence thresholds + margin analysis
Core Pipeline Components
Training Phase
(00_colab_complete_pipeline.ipynb)
- Data Flow: raw data → clean data → pseudo-labeling → training/testing splits
- Gemini Pseudo-Labeling: Label generation using Google's Gemini 2.5 Flash API
- HuggingFace Model Training: Custom classification models with feedback loops
- Model Persistence: Automated model saving and versioning system
- Evaluation metrics include accuracy, precision/recall, and f1-score
Inference Phase
(01_inference_pipeline.ipynb)
- Production Pipeline: actual data → trained models → predictions → structured output
- Ensemble Classification: Combines multiple model outputs for optimal accuracy
- Evaluation metrics include rejection rates, most common violations
Development Platforms
- Google Colab: Primary development environment with GPU acceleration
- Jupyter Notebooks: Local development and pipeline organization
- VSCode: Code editing and project management
- Git: Version control and collaboration
Libraries & Frameworks
Core ML
- torch 2.8.0, transformers 4.43.3, datasets 4.0.0, accelerate 1.10.1
Data
- pandas 2.2.2, scikit-learn 1.7.1, numpy 2.3.2, scipy 1.16.1
Visualization
- matplotlib 3.10.5, seaborn 0.13.2, wordcloud 1.9.4
Google Cloud Platform
- google-generativeai 0.8.5, google-auth 2.40.3
Utilities
- tqdm 4.67.1, jsonschema 4.25.1, regex 2025.7.34
Datasets Involved
- 5 AI-generated labelled sample dataset with all policy categories for initial pipeline training
- Alaska and Hawaii Google review datasets from Google Local review data for actual training
Challenges we ran into
One challenge we faced was noise. The reviews were short and balancing strict policy enforcement with fairness was tough. Making the system scalable and precise tested our design choices. Combining our pipelines together proved challenging as well, as there were many different moving components that were split between the different team members.
Accomplishments that we're proud of
One thing that we are proud of is how we managed to turn messy, unreliable text into meaningful signals. We managed to built a working prototype that doesn't just filter reviews, it restores trust in reviews, all in a hackathon sprint.
What we learned
Although the technicals were difficult, we felt that it was not the hardest problems, but rather judgement. Teaching AI to weight intent, relevance, and tone gave us a much deeper appreciation for nuance in human communication.
What's next for Project Sugamen
We are not done. Next, we hope to integrate it with platforms to push society towards a future where online reviews are finally as reliable as personal recommendations.

Log in or sign up for Devpost to join the conversation.