-
-
Vision is Our Bridge. Meet Project Signbridge: a sleek, real-time AI translating fluid ASL motion into instant meaning.
-
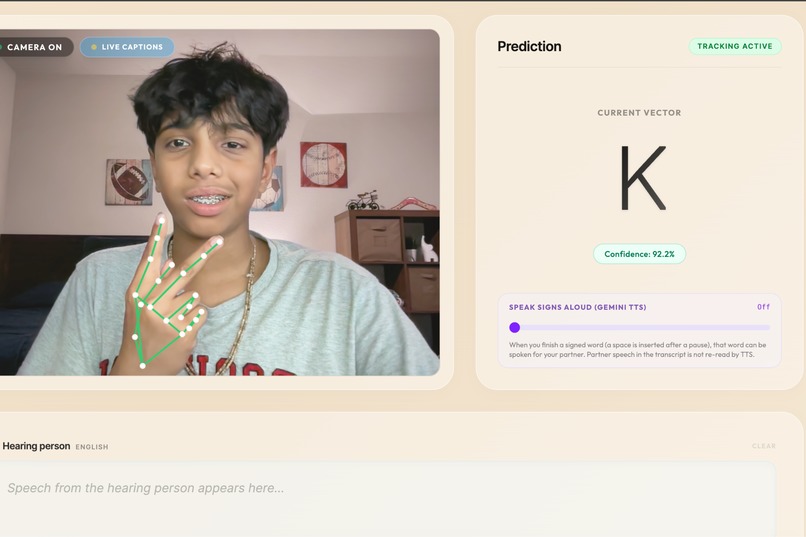
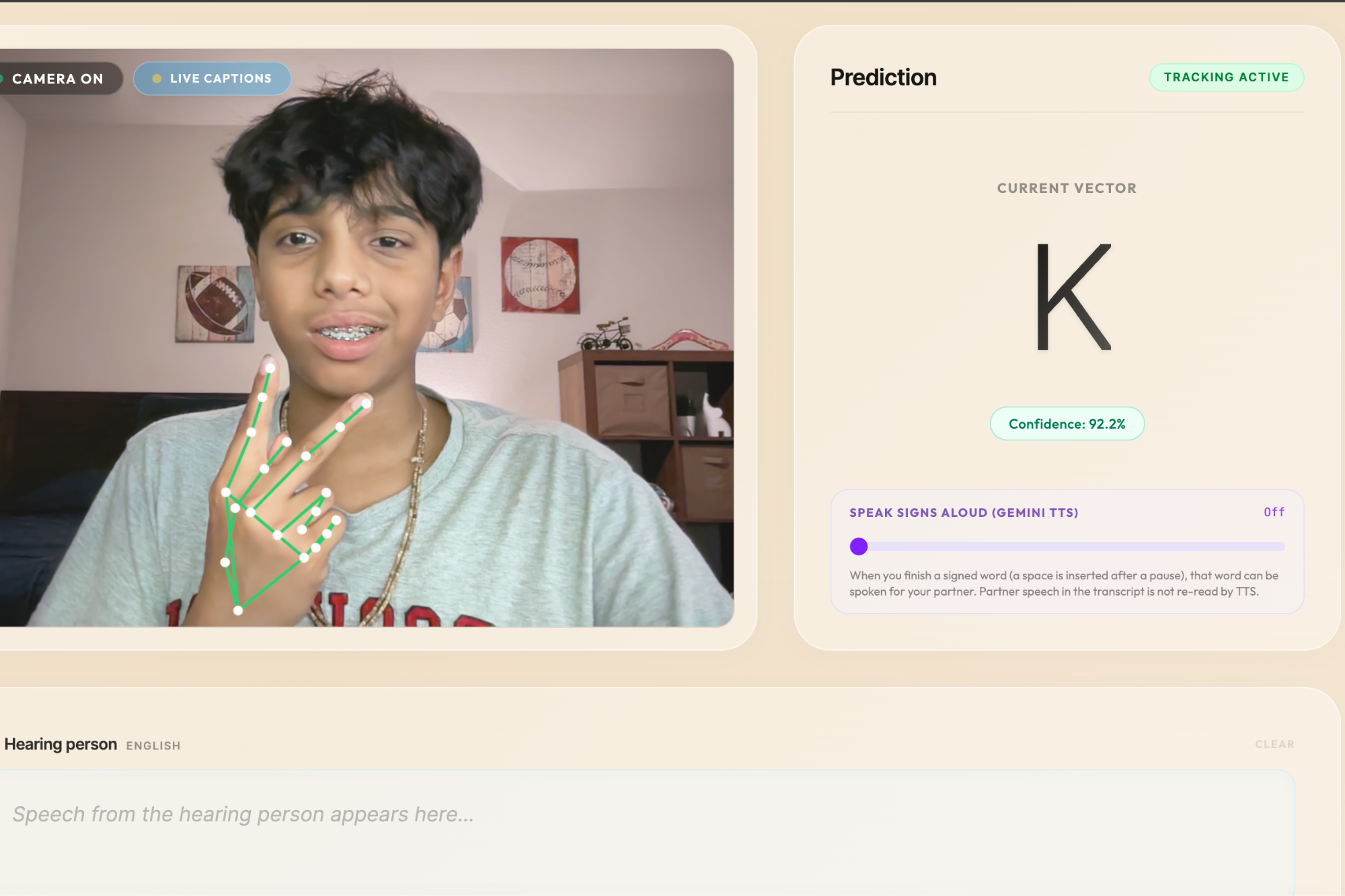
The baseline works flawlessly. Real-time ASL fingerspelling translation tracking spatial vectors with 92.2% confidence.
Inspiration
The core inspiration for Project SignBridge stemmed from the massive and often frustrating communication gap that exists between the Deaf community and individuals who do not know American Sign Language. This barrier impacts daily interactions, from simple retail transactions to essential services, limiting accessibility and inclusion. We were motivated to create a truly zero-friction solution that uses ubiquitous technology — a standard webcam and a web browser — to instantly bridge this gap without the need for specialized hardware or app downloads, making communication seamless and universally accessible.
What it does
Project SignBridge is a web application that uses artificial intelligence to translate American Sign Language (ASL) into English text in real time. It captures the user's hand movements via a standard web camera, processes the spatial coordinates using Google's MediaPipe framework, and sends this normalized data to a Python backend. This backend uses a custom-trained neural network to identify the signed letters and common words. The application then displays the translated text on the screen. Additionally, we integrate the Gemini API for advanced post-processing, which not only predicts the user's intended next words but also synthesizes the on-screen text into natural-sounding spoken audio, providing a complete and comprehensive communication solution.
How we built it
The project was built in three chronological phases: Phase 1 — We implemented the front-end to utilize the browser's WebRTC API to access the webcam and the Google MediaPipe Hand Landmarker model to detect and extract 21 coordinate points from the user's hands in real time. Phase 2 — We focused on the backend, converting raw 3D landmarks into normalized, relative coordinates to build our custom training dataset. We then trained a lightweight deep neural network using PyTorch on an ASL fingerspelling dataset to recognize static letters, and trained an additional model using the WLASL dataset to interpret common words. Phase 3 — We integrated the complete application using WebSockets to send normalized hand coordinates from the browser to the Python ML backend, rendered predictions onto the UI, and integrated the Gemini API for intelligent word prediction and text-to-speech output.
Example: Normalized landmark data sent via WebSocket
landmarks = extract_landmarks(frame) # MediaPipe hand detection normalized = normalize_coordinates(landmarks) # Convert to relative coords prediction = model.predict(normalized) # Neural network inference
Challenges we ran into
One of the primary challenges was ensuring low latency for real-time conversation. The computational demands of the ML model on a standard server posed a significant hurdle. We addressed this by strictly sending only the mathematical coordinate data — not raw video frames — and optimizing our deep learning model for edge performance. Another challenge was achieving high, consistent accuracy for fingerspelling across different users and varying lighting conditions, which required extensive data normalization and careful model tuning.
Accomplishments that we're proud of
We are most proud of successfully launching a complete, end-to-end web application within the hackathon timeframe that seamlessly integrates real-time hand-tracking, a custom-trained Python machine learning backend, and the Gemini API. A significant accomplishment was adhering to our "Zero-Friction Accessibility" principle — delivering a solution that requires zero downloads, zero specialized hardware, and zero accounts. Finally, achieving an end-to-end latency of approximately 300 milliseconds is a major technical achievement that ensures the tool is viable for natural, unscripted conversations.
What we learned
We learned the critical importance of data processing and normalization in machine learning for computer vision. Converting pixel data into relative coordinates was essential for creating a model that generalizes well across different devices and viewing distances. The key normalization insight was: ( \text{normalized}i = \frac{x_i - x{\min}}{x_{\max} - x_{\min}} ) Furthermore, we gained valuable experience in optimizing deep learning models for low-latency, real-time performance and utilizing efficient WebSocket communication to bridge the gap between a browser-based frontend and a Python ML backend.
What's next for Project SignBridge
The next steps for Project SignBridge focus on scaling and improving accuracy. We plan to integrate the WLASL word recognition capability more prominently into the UI, moving beyond just the static ASL alphabet. We will also focus on model compression and hardware acceleration techniques to drive our median latency below the 200-millisecond threshold: $$\text{Target Latency} < 200\text{ms}$$ Long-term goals include translating fluent, dynamic ASL sentences, which will require transitioning from our current models to more complex sequence models like LSTMs or Transformers.
Built With
- css
- fastapi
- gemini
- javascript
- mediapipe
- numpy
- opencv
- pydantic
- python
- pytorch
- react
- tailwind
- tensorflow
- typescript
- uvicorn
- vite
- web-audio-git
- websockets


Log in or sign up for Devpost to join the conversation.