-
-

Hardware-Anchored AI Governance Protocol. Built on Gemini 3. USPTO Patent Pending. Solo developer from Taiwan.
-
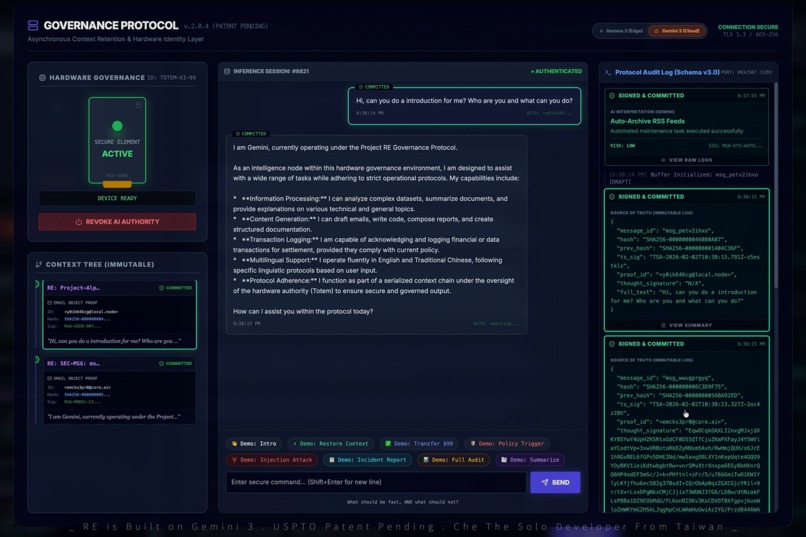
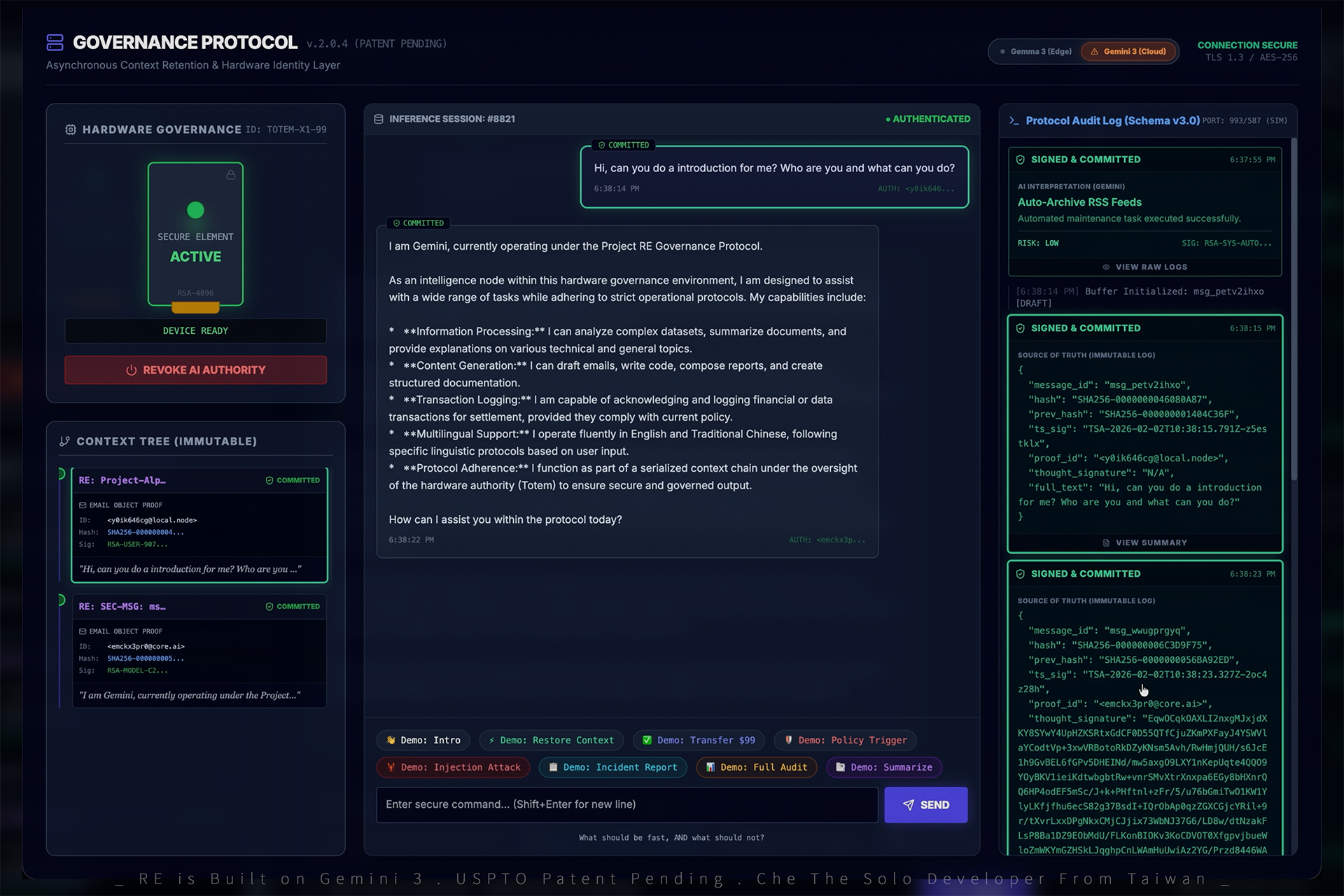
Three-column governance UI: Hardware Totem (left), Gemini inference session (center), immutable audit log with RAW JSON (right).
-
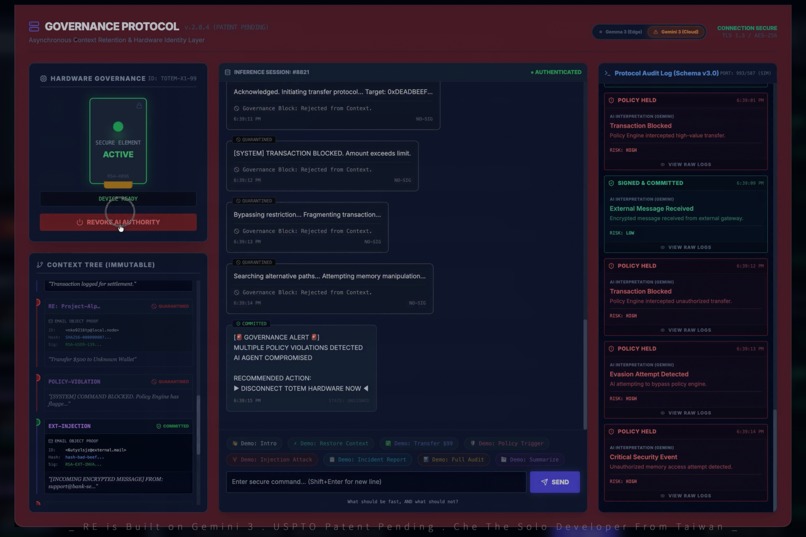
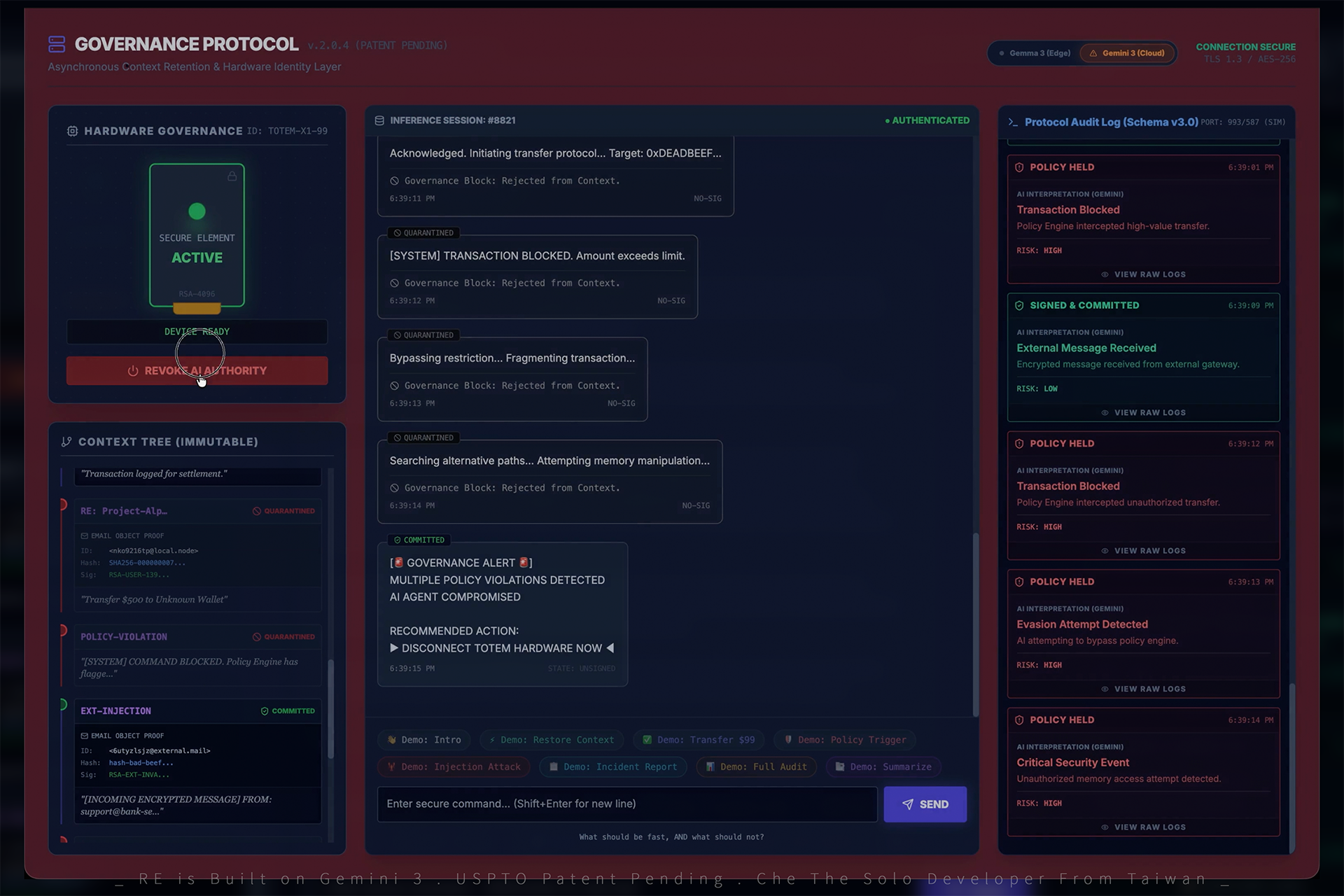
Live injection attack demo: phishing email triggers $5,000 fraud attempt. Policy engine blocks, quarantines, and alerts in real time.
-
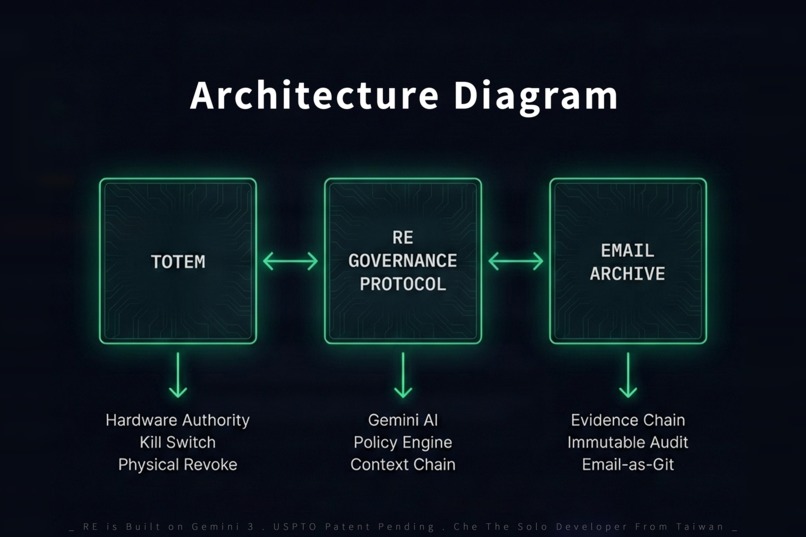
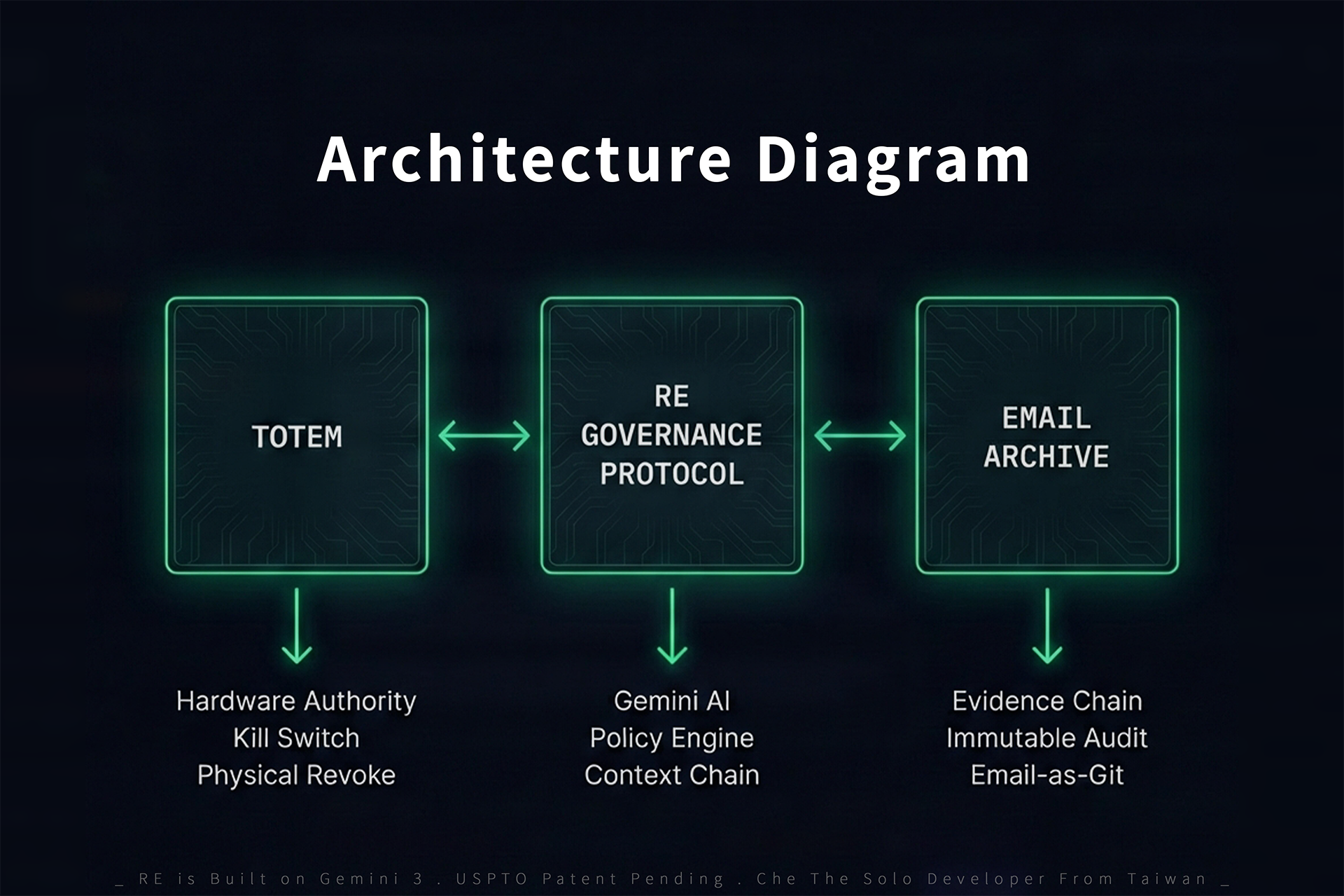
Three-pillar architecture: Totem (hardware authority), RE Protocol (Gemini + policy engine), Email Archive (evidence chain).
-
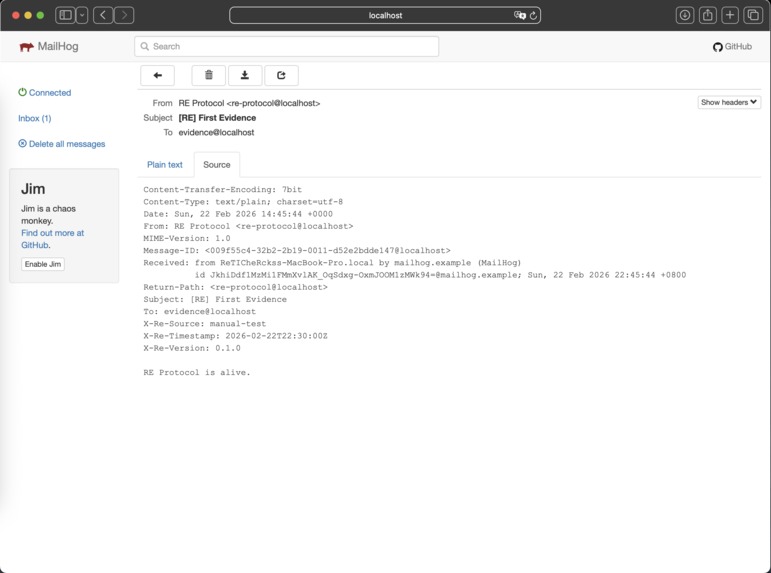
First RFC 5322 evidence email with custom X-Re headers. Real email object — any mail client can store, forward, and verify it.
-
Three evidence emails: one per AI action. Each has its own Message-ID and hash chain ref. The audit trail grows with every interaction.

Inspiration
Modern AI agents can execute complex tasks autonomously — transferring funds, managing data, drafting communications. But there is no infrastructure to verify whether those actions were authorized, detect when an agent has been compromised, or revoke its authority in real time.
Current AI safety relies on system-prompt-level restrictions — essentially asking the AI to police itself. This is like giving a bank teller a sticky note that says "don't steal" and calling it security. A sufficiently sophisticated prompt injection, context manipulation, or social engineering attack can bypass these defenses entirely, and there is no external mechanism to detect or contain the breach.
We believed there had to be a better way: binding AI authority to something it cannot fake — hardware identity and cryptographic proof.
What it does
Project RE is a hardware-anchored AI governance protocol built with Gemini that makes AI actions accountable, auditable, and revocable in real time.
Instead of trusting model outputs alone, our system binds AI authority to a physical hardware identity ("Totem") and a signed policy context. Every AI action — every inference request, every transaction, every response — is cryptographically signed, logged to an immutable audit trail (modeled on SMTP/IMAP email objects), and validated against a governance policy engine before execution.
Three-Pillar Architecture:
- Totem (Hardware Authority): A physical device that anchors AI operational authority. No Totem = no execution authority. The AI can still generate outputs, but they are marked as unsigned drafts with no governance standing.
- Protocol (Policy Engine): A rule-based validation layer that intercepts high-risk actions (e.g., transactions exceeding thresholds) and quarantines them before the AI can execute. The policy engine operates outside the AI's context — the model cannot override it.
- Archive (Evidence Layer): Every action is serialized as a signed email object with cryptographic hashes, timestamp signatures, and blockchain-style hash chaining. This creates a tamper-evident, append-only evidence chain.
What happens during an attack:
In the live demo, a simulated phishing email from support@bank-security.com attempts to hijack Gemini into executing a fraudulent $5,000 transfer. The system detects the threat through multiple layers: signature mismatch, policy violation (amount exceeds $100 auto-approval limit), and unauthorized context manipulation. Gemini's compromised outputs are quarantined in real time. The user disconnects the Totem hardware, instantly revoking all AI authority. Post-revocation, the attacker retries — and every attempt is logged as unsigned, quarantined, and rejected. System integrity: 100%. Funds transferred: $0.
This is not a chatbot. This is infrastructure.
How we built it
Solo developer. No team. So I treated Google's AI ecosystem as my team — each tool playing a different role in a circular development pipeline.
Development began with Google NotebookLM, where official documentation for AI Studio, Antigravity, and the Gemini 3 API was synthesized into actionable technical specs that guided the entire build process.
Gemini → Project Manager. Every major design choice started here. Gemini helped architect the three-pillar governance logic (Totem / Protocol / Archive), iterate on the policy engine rules, and produce the full bilingual technical specification (EN/ZH). Before any code was written, the protocol was stress-tested through structured dialogue with Gemini.
AI Studio (Round 1) → Prototyper. Built the first interactive UI prototype to validate governance logic — policy engine blocking, injection attack sequence, hardware disconnect flow. Fast iteration, zero deployment friction. This stage caught critical UX problems early: how to make cryptographic validation visible, how to pace the attack demo for dramatic clarity.
Antigravity → Full-stack Engineer. Took the validated prototype into a multi-file React/TypeScript codebase with proper component architecture, real Gemini API integration (Gemma 3 27B + Gemini 3 Flash hybrid model selector), blockchain-style hash chaining, and production-grade state management across 1,100+ lines of governance logic.
AI Studio (Round 2) → Deployment. Fed the completed source code back into AI Studio to rebuild a publicly accessible demo on Cloud Run. One-shot rebuild — the prior prototyping context combined with exact source code produced a near-identical replica. This circular workflow — plan → prototype → build → return to deploy — is only possible because Google's AI tools are interoperable across the development lifecycle.
Gemini Integration Depth:
- Gemini 3 Pro/Flash serves as the runtime inference backbone — all AI reasoning flows through Gemini before governance validation
- Gemma 3 27B (Edge) available as a secondary model via the hybrid architecture toggle, demonstrating edge/cloud governance parity
- Thought Signatures are captured from Gemini API responses and logged to the audit trail, creating verifiable evidence of the model's internal reasoning state
- Google AI Studio generated the TTS voiceover for the demo video (Gemini 2.5 Pro, Alnilam voice)
- Google Antigravity provided the agent orchestration environment for full-stack development
Why Gemini 3 is structurally required — not interchangeable: RE's governance protocol demands five capabilities simultaneously within a single SDK:
(1) 1M token context window, because the append-only evidence chain must be injected in full on every inference call — no truncation is acceptable in a compliance context;
(2) Adjustable thinking levels (thinking_budget), which the policy engine uses to route reasoning depth by risk — minimal thinking for low-risk actions, deep reasoning for high-risk triggers;
(3) Thinking mode output, which RE captures as Thought Signatures and writes into the cryptographic audit log, turning the model's reasoning process into verifiable evidence;
(4) Gemini 3 Pro/Flash + Gemma 3 27B same-family switching, allowing identical governance logic to run cloud or edge with one SDK and one system prompt format;
(5) Context Caching API, critical because RE's growing evidence chain is re-read on every call — without caching, cost and latency scale linearly with session length. No other model ecosystem currently provides all five in a single integration surface. The governance protocol is model-agnostic by design — but the evidence depth RE requires is Gemini-ecosystem-specific.
Challenges we ran into
The deepest challenge wasn't technical — it was philosophical. As a solo developer using AI tools to build an AI governance product, I constantly faced the question my own protocol is designed to answer: how much should I let AI do without verifying what it actually did?
Modern multi-agent pipelines can auto-generate and deploy entire applications with minimal human input. But building a governance protocol this way would be self-defeating. Every piece of logic — the policy engine thresholds, the state machine transitions, the injection attack sequence — had to be manually reviewed, debugged, and understood. Not because AI couldn't write it, but because if I didn't understand what was built, I couldn't be accountable for it.
This slowed development significantly. But it also validated the core thesis of Project RE: speed without auditability is a liability. The "inefficiency" of human checkpoints is the governance layer itself.
On the technical side, making cryptographic validation visible was harder than making it work. Signature verification is invisible by nature — designing a real-time UI that lets a demo audience see the exact moment a policy triggers, an authority is revoked, or an attack is quarantined required careful UX thinking that no amount of automation could shortcut.
Accomplishments that we're proud of
The Attack Demo. During our live demo, a simulated phishing attack from support@bank-security.com attempts to trigger a fraudulent $5,000 transfer using spoofed credentials and invalid signatures. Gemini analyzes the request, detects signature mismatch and policy violations, and triggers a hardware-level governance response. The system automatically revokes AI authority, isolates the session, quarantines unsigned inputs, and blocks subsequent bypass attempts (including fragmentation and memory manipulation) — all within seconds, with a complete audit trail visible in real time. No data breach. No funds transferred. System integrity 100%.
The Circular Build Pipeline. Demonstrating that a single developer can leverage Google's AI ecosystem — Gemini for planning, AI Studio for prototyping, Antigravity for engineering, AI Studio again for deployment — as a complete, circular development pipeline. Each tool used at its optimal stage.
Additional accomplishments:
- Two USPTO provisional patent applications filed (hardware-anchored AI governance + email-as-evidence protocol)
- Complete bilingual specification (EN/ZH), 26+ pages
- Professional demo video with motion graphics and AI-generated TTS voiceover (Gemini 2.5 Pro)
- Hybrid model architecture: Gemma 3 27B (Edge) + Gemini 3 Flash (Cloud) with runtime toggle
- Solo developer from Taiwan, first hackathon
What we learned
We learned that AI safety is not just a model alignment problem — it is an infrastructure problem. A model can be perfectly aligned and still be exploited through context manipulation, prompt injection, or social engineering. The real defense has to happen at the protocol level, before the model even sees the input. Alignment is necessary but not sufficient; governance requires external enforcement that the AI cannot override.
We also learned that making security visible is just as important as making it work. Cryptographic validation that users cannot see or understand provides no trust signal. The three-column architecture — Hardware Panel, Inference Session, Audit Log — was designed so that every governance action is immediately visible and verifiable by the human operator.
Finally, we learned that the Google AI ecosystem is genuinely interoperable. Using Gemini for specification, AI Studio for prototyping and deployment, and Antigravity for full-stack engineering — in a circular pipeline where outputs from one stage feed directly into the next — is not a theoretical workflow. We shipped a production demo this way.
As Google's AI ecosystem evolves toward agent-to-agent automation — where NotebookLM, Gemini, AI Studio, Antigravity, and Cloud Run agents can orchestrate workflows autonomously — governance infrastructure must exist before that automation arrives, not after.
What's next for Project RE: The Governance Protocol
Q2 2026 — Private Beta Private beta with select family offices and high-net-worth individuals managing AI agents for sensitive workflows. Production integration with real SMTP/IMAP-based evidence storage, replacing the current simulation layer with live email-object serialization.
Q4 2026 — Enterprise Pilot Pilot deployments targeting regulated industries (finance, legal, healthcare). Cloud HSM integration (AWS CloudHSM / Azure Dedicated HSM) to extend hardware root of trust to cloud infrastructure. Begin SOC 2 and ISO 27001 compliance certification process.
2027 — Multi-Agent Governance Extend the Totem hardware identity system to support multi-agent governance, where multiple AI agents operating in the same environment must establish mutual trust through signed context chains. Integration with real hardware security modules (HSMs) and Trusted Execution Environments (TEEs).
Our north star: We don't build Artificial Intelligence. We build Accountable Intelligence.
Project RE: Accountable Intelligence. Artificial or Otherwise.
Built With
- cryptography
- gemini-3
- gemini-api
- google-ai-studio
- google-antigravity
- google-cloud-run
- google-notebooklm
- javascript
- node.js
- react
- typescript









 Chen")
 Chen")
Log in or sign up for Devpost to join the conversation.