-
-
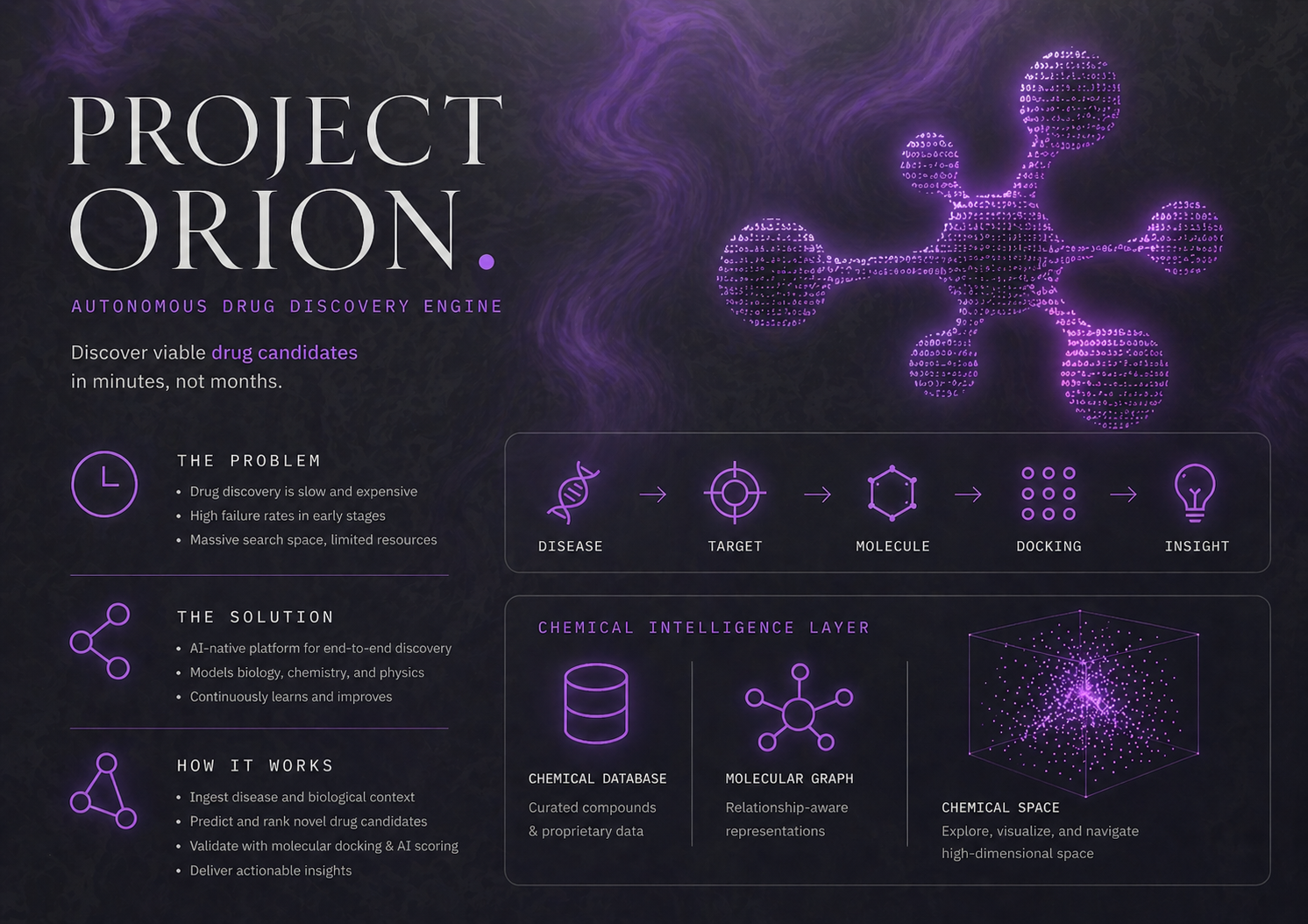
Infographic
-

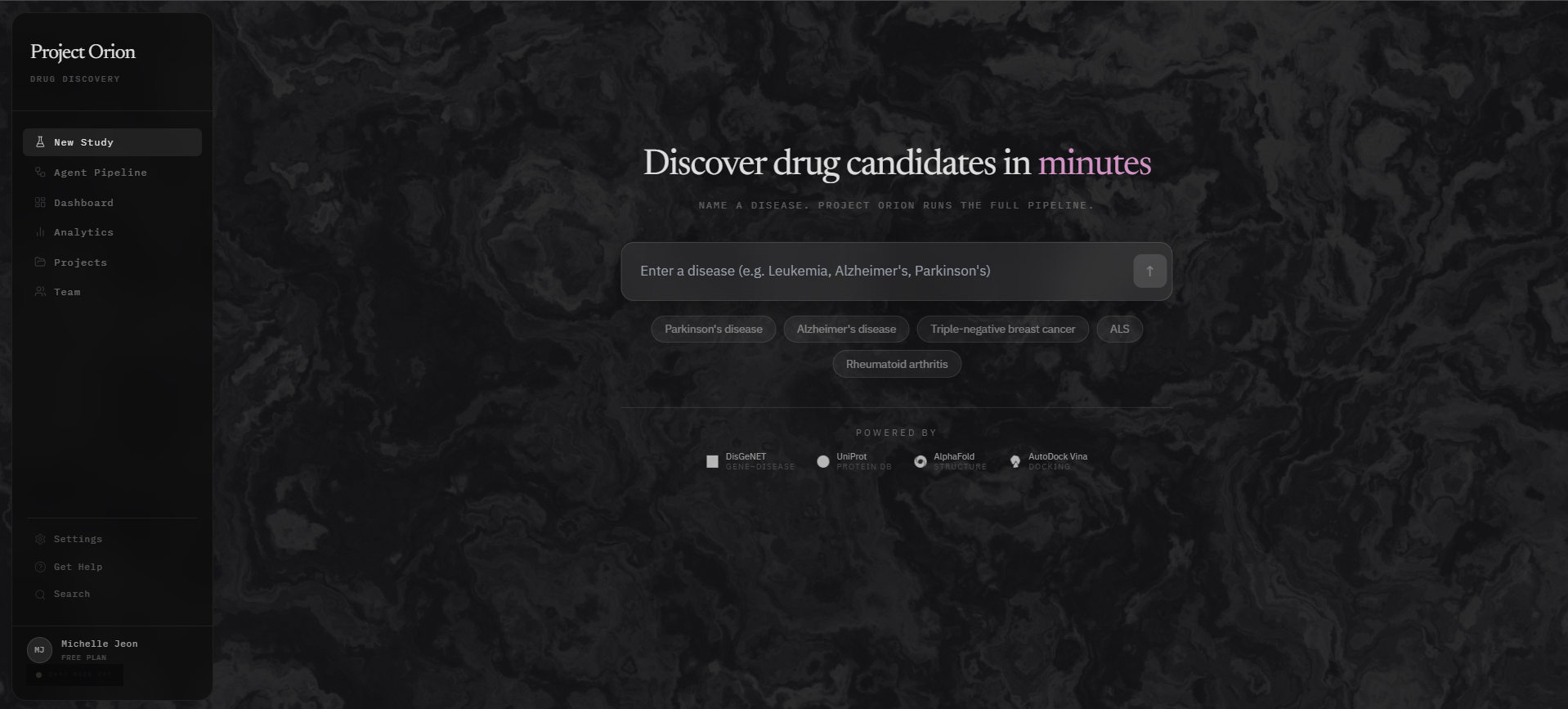
Landing Page
-
Home Page
-

Disease Intelligence
-
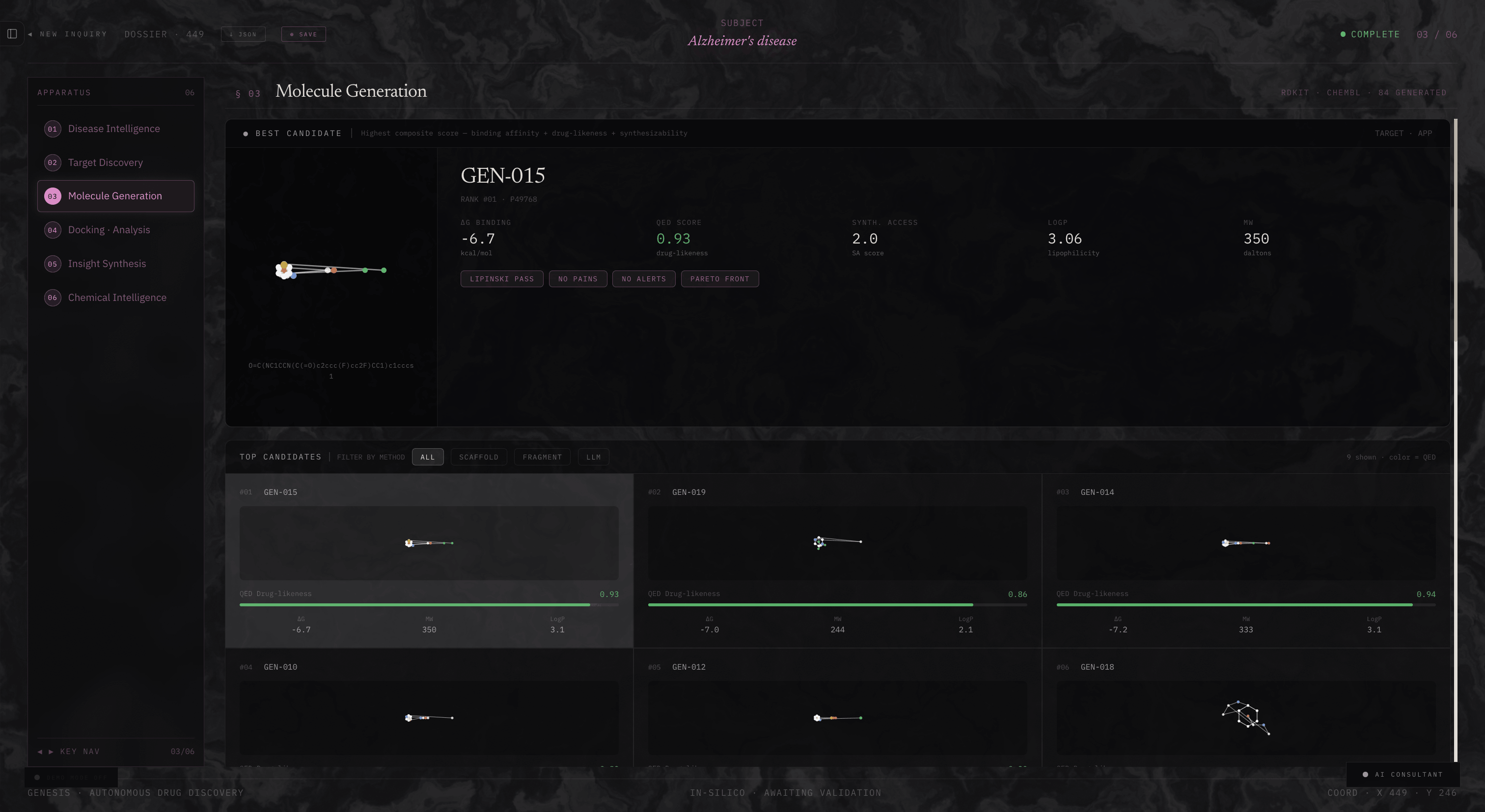
Molecule Generation
-
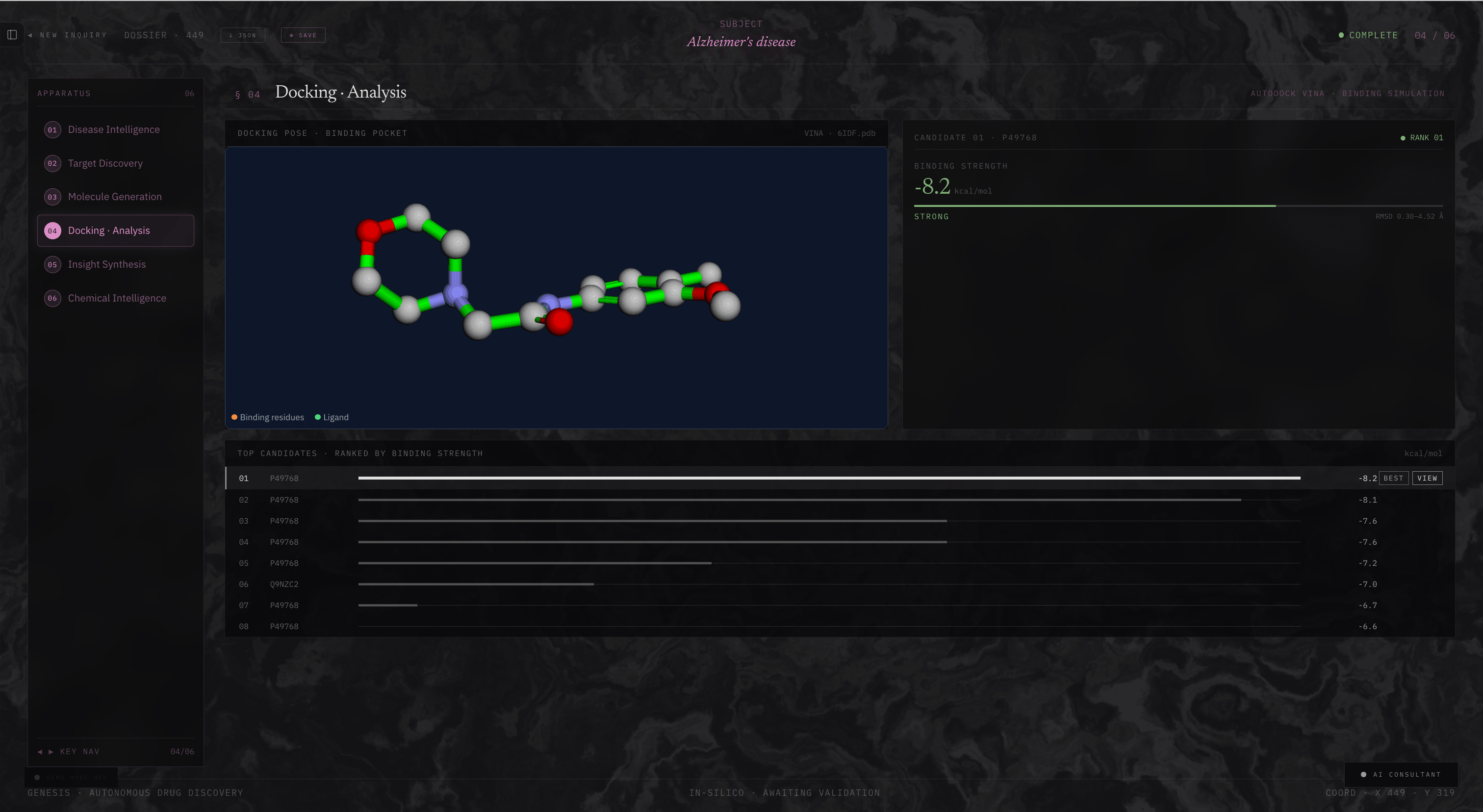
Docking Analysis
-
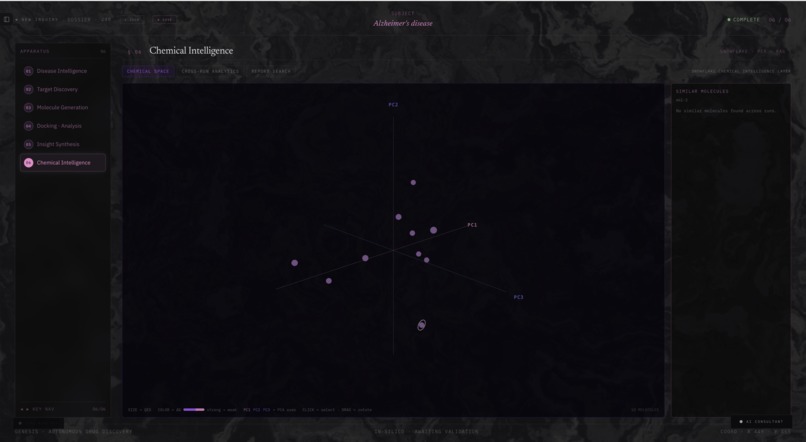
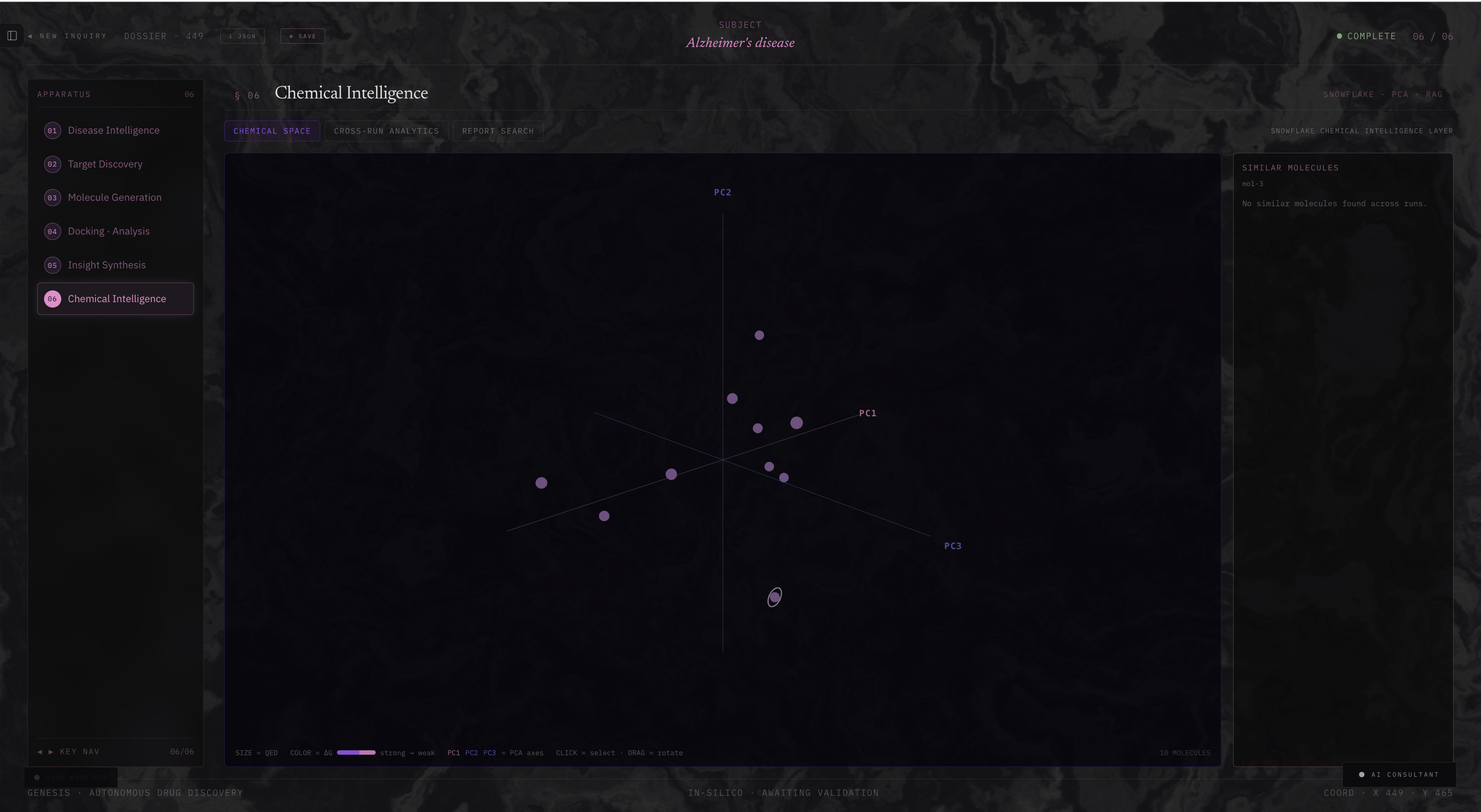
Chemical Intelligence
-
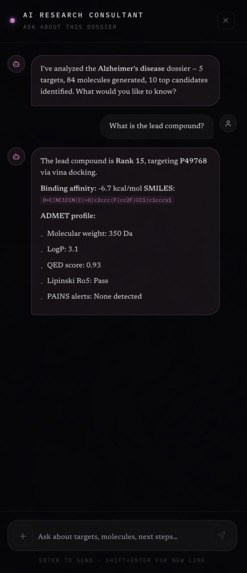
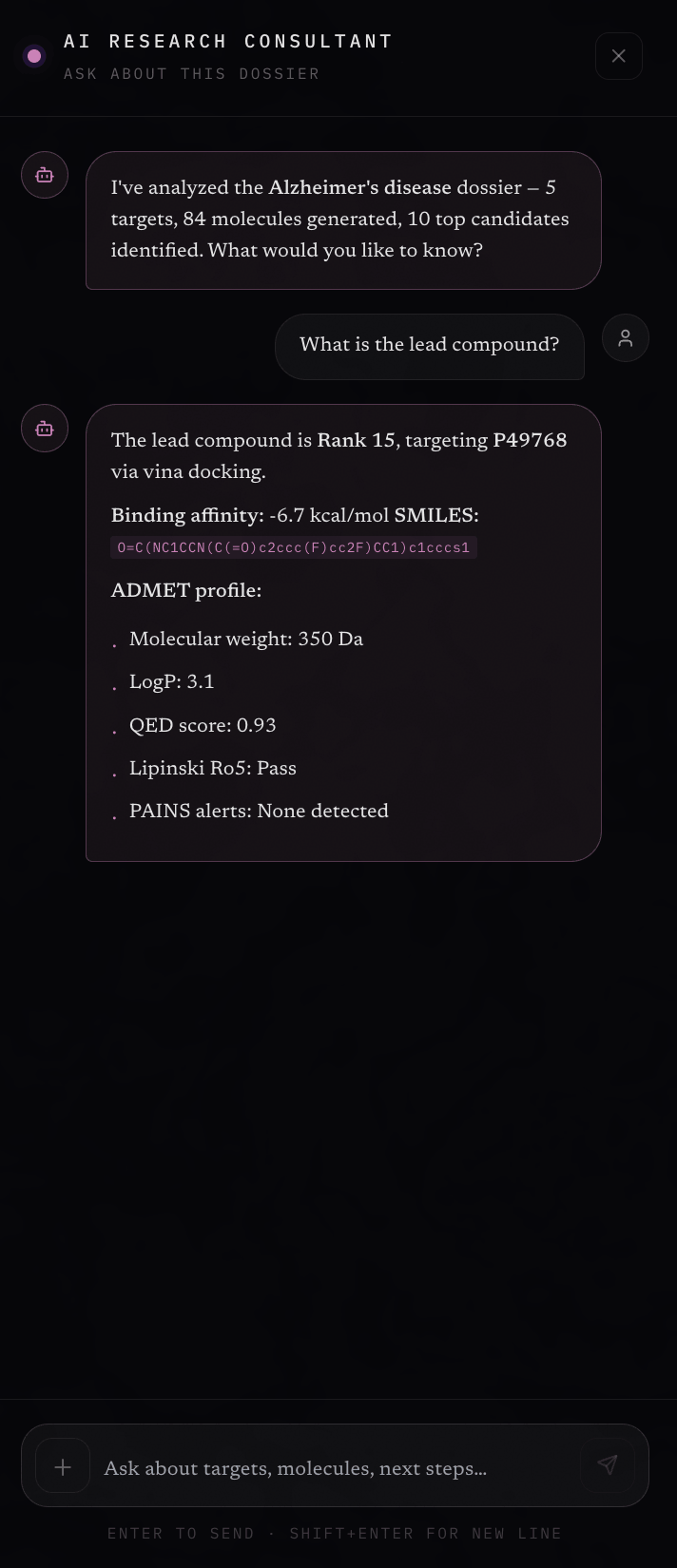
AI Consultant


Inspiration
A potential treatment for pancreatic cancer existed for 50 years before anyone realized it.
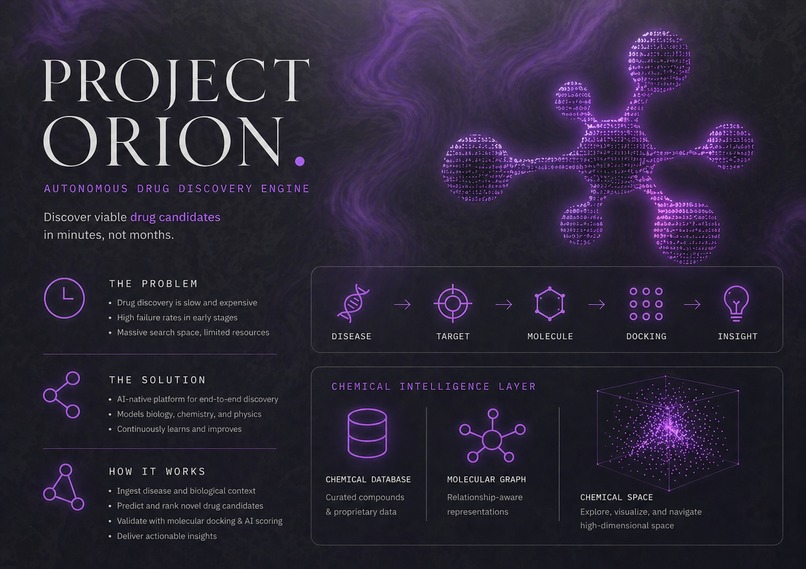
The problem isn’t a lack of drugs, it’s a lack of time, scale, and coordination in exploring them. Drug discovery today is a fragmented, slow and costly process.
- 10–15 years
- $1B+ cost
- Millions of potential compounds never explored
Our goal was to build a platform that leverages agentic AI to innovate in the biotech space by accelerating drug discovery.
What It Does
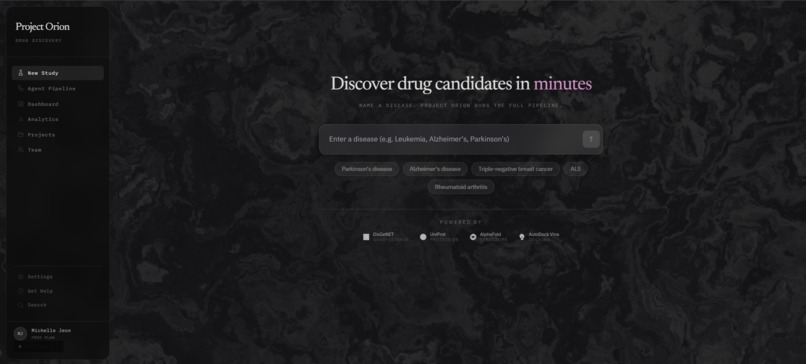
Project Orion is an autonomous AI research assistant built for the primary drug discovery phase. When a user inputs a disease such as Alzheimer’s or pancreatic cancer, our system launches a four-agent pipeline that leverages real biological evidence to identify precise protein targets, generate candidate drug molecules, and simulate molecular binding — all in one end-to-end workflow.
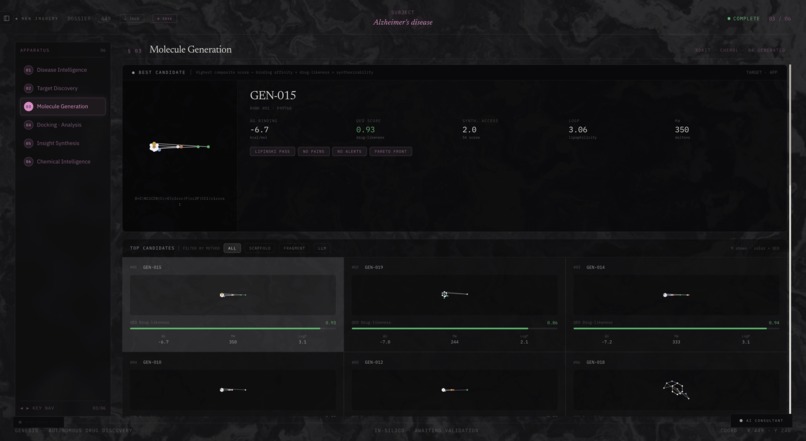
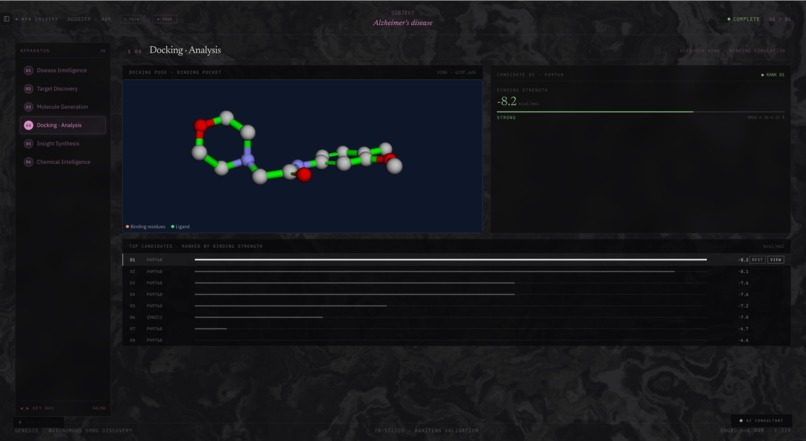
Rather than requiring weeks or months of manual research, Orion completes this process in minutes. The platform outputs ranked drug-like molecular candidates, predicted binding affinity scores (ΔG), and key ADMET properties such as QED, LogP, and TPSA. It also generates a fully synthesized scientific research report that users can interact with through a chat interface.
This allows researchers not only to inspect a single pipeline run, but also compare results across previous experiments, identify recurring molecular patterns, and accelerate cross-disease insights.
How It Works
At its core, Project Orion compresses early-stage drug discovery into a fully automated multi-agent workflow.
The pipeline begins with disease intelligence, where the user’s disease input is normalized and mapped to relevant biological targets. Using databases such as DisGeNET and UniProt, the system identifies associated proteins and retrieves structural information from sources like PDB and AlphaFold. It also builds pathway graphs using KEGG and Reactome to understand the disease at a systems-biology level.
Next, the molecular generation layer produces candidate compounds using RDKit alongside ChEMBL-derived seed molecules. Each generated compound is filtered through drug-likeness and safety checks, including Lipinski rules, PAINS filtering, and synthetic accessibility scoring. This stage can produce up to 50 viable candidates per target.
The third stage focuses on docking and simulation. Candidate molecules are converted into PDBQT structures and passed through AutoDock Vina and DiffDock (MIT’s ML model) to simulate binding behaviour. Orion then computes predicted binding affinities and interaction maps, allowing researchers to evaluate how strongly each molecule interacts with the target protein.
After each docking run, key molecular features — including binding affinity, ADMET properties, and vectorized chemical descriptors — are persisted into Snowflake’s native VECTOR storage layer. This transforms each experiment into a searchable scientific memory system, enabling downstream similarity search, cross-run analytics, and chemical space visualization.
Finally, the insight synthesis layer uses an LLM to generate a complete scientific research dossier, including an executive summary, target-level biological analysis, ranked candidates, and safety flags. These reports are also embedded and stored in Snowflake using Cortex, enabling semantic retrieval and chat-based comparison across previous pipeline runs.
How We Built It
The backend was built using Python, FastAPI, SQLAlchemy, and PostgreSQL, with modular orchestration to manage the full multi-agent pipeline.
We developed a custom MCP server to expose specialized scientific tools and services directly to our agents, allowing modular access to molecular processing, database retrieval, and downstream analytics.
The agent workflow itself is orchestrated through LangFlow, which also enables researchers without coding experience to visually inspect, modify, and reconfigure agents when needed.
For molecular modelling, we integrated RDKit, AutoDock Vina, Meeko, Open Babel, and DiffDock for candidate generation and docking simulation.
On the frontend, we used React, TypeScript, Vite, and Three.js to create an interactive interface with 3D molecule and protein visualization.
For analytics and scientific memory, we used Snowflake as a vector-native storage and retrieval layer, powering similarity search, semantic retrieval, and cross-run analytics.
Key Features (Snowflake ❄️😉)
Project Orion uses Snowflake as a vector-native scientific memory and analytics layer, persisting molecular features and research reports into a continuously queryable knowledge base rather than treating each pipeline run in isolation.
Molecular Similarity Search
Each molecule is stored as a feature-rich record containing ADMET metrics, binding affinity, and a 9-dimensional vector representation. Using Snowflake's native VECTOR type and VECTOR_L2_DISTANCE, researchers can run pure SQL similarity search across all historical runs — no external vector databases needed.
Chemical Space Explorer
Orion retrieves feature matrices from Snowflake and projects them into 3D chemical space via PCA, where each point is a molecule coloured by binding affinity and sized by drug-likeness. This makes clusters, outliers, and high-performing regions immediately visible.
Cross-Run Analytics
With every pipeline output persisted in Snowflake, researchers can query across all experiments — identifying which protein targets, generation strategies, or disease areas consistently yield the strongest candidates.
Research Reports (RAG + Cortex)
Reports are embedded using Snowflake Cortex and retrieved semantically via VECTOR_COSINE_SIMILARITY, creating a RAG-powered scientific memory over all historical experiments.
Challenges We Ran Into
We encountered significant issues in molecular preprocessing. Converting generated SMILES strings into valid 3D molecular structures introduced numerous edge cases, including malformed outputs, failed conformer generation, and incompatible formats for downstream docking tools.
Another major challenge was multi-agent orchestration. Because Orion’s workflow spans several tightly connected stages — from target identification to report synthesis — ensuring reliable, structured outputs between agents required strict schema validation, error handling, and controlled data flow.
Beyond the technical challenges, we also had to consider scientific responsibility. From the beginning, we intentionally designed Orion as a research assistant for early-stage drug discovery rather than a clinical decision-making system.
Accomplishments We’re Proud Of
We built a system that autonomously performs:
target discovery → molecule generation → docking → report synthesis
This reduces a multi-week research workflow into minutes.
We are especially proud of successfully integrating:
- AI agents
- molecular simulation
- vector-native scientific analytics and memory layer
- interactive visualization
- no-code agent configurability through LangFlow
Most importantly, we designed a platform that is both scientifically grounded and user-accessible.
What We Learned
In biotech, correct framing matters as much as accuracy. We learned that AI agents need strict structure and validation to avoid hallucinations.
What’s Next
We plan on making the pipeline more realistic, more reliable, and more product-ready. The highest-priority upgrade is adding an ADMET and synthetic accessibility agent after docking to evaluate toxicity, solubility, metabolic stability, and how practical each molecule is to synthesize. This will allow Orion to rank not just strong binders, but truly actionable lead candidates.
Built With
- autodockvina
- diffdock
- docker
- fastapi
- langflow
- node.js
- postgresql
- pytest
- python
- rdkit
- snowflake
- three.js
- typescript









Log in or sign up for Devpost to join the conversation.