-
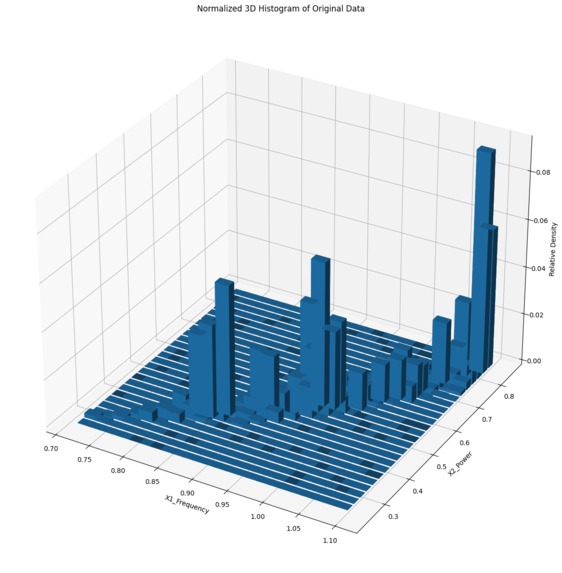
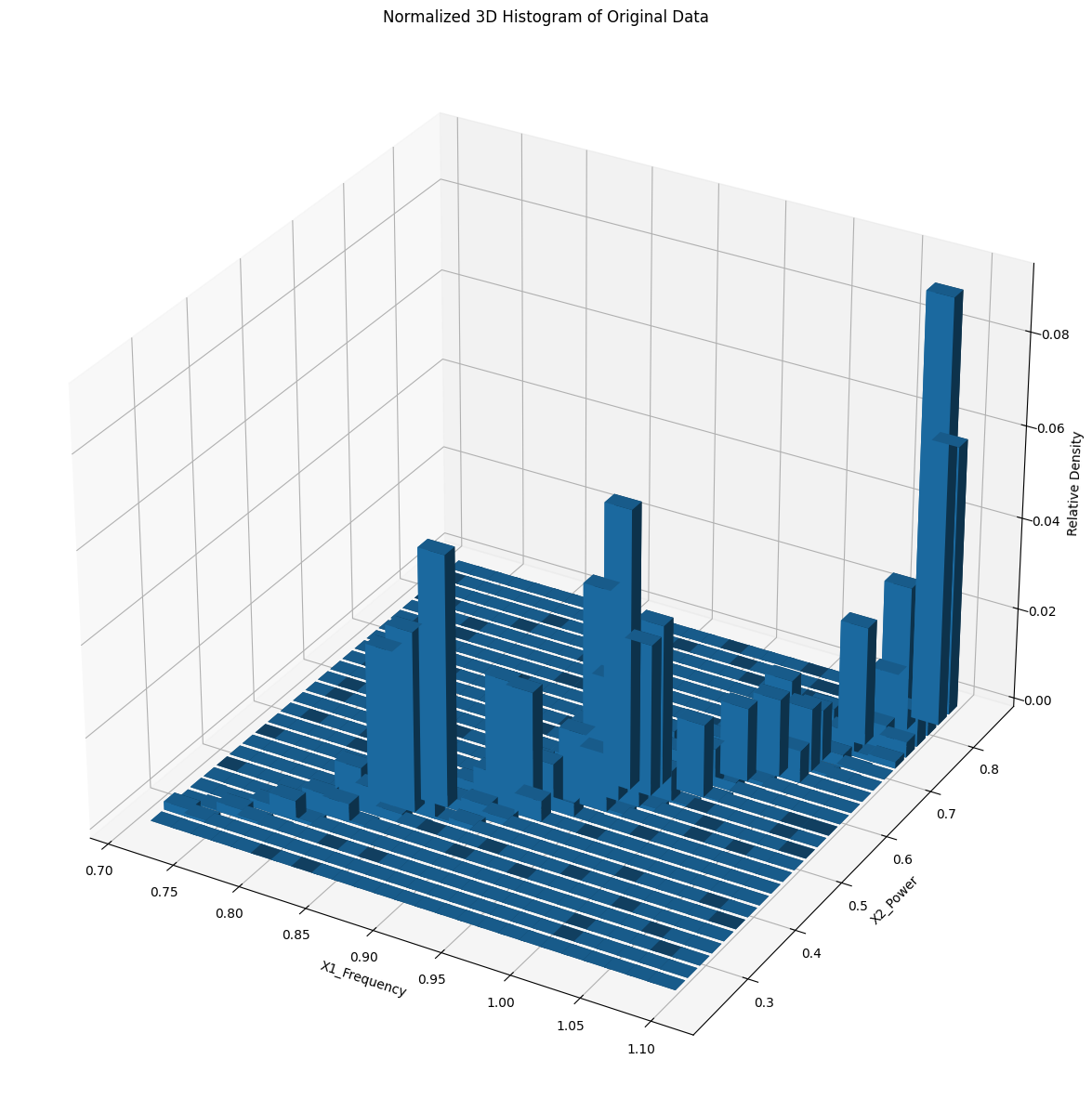
Original Data Distribution (Dataset 1)
-
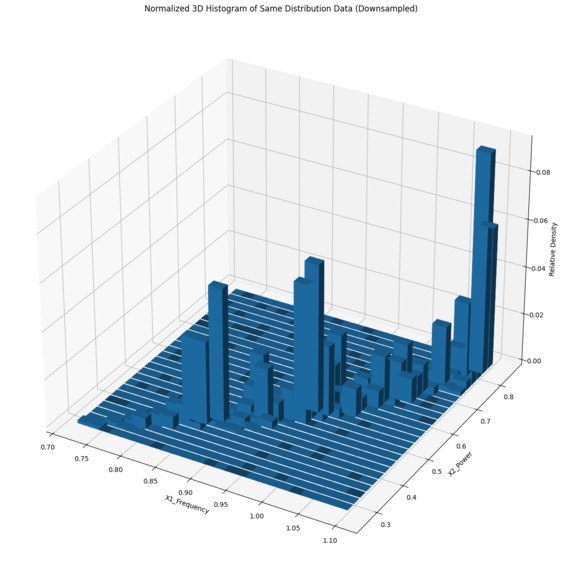
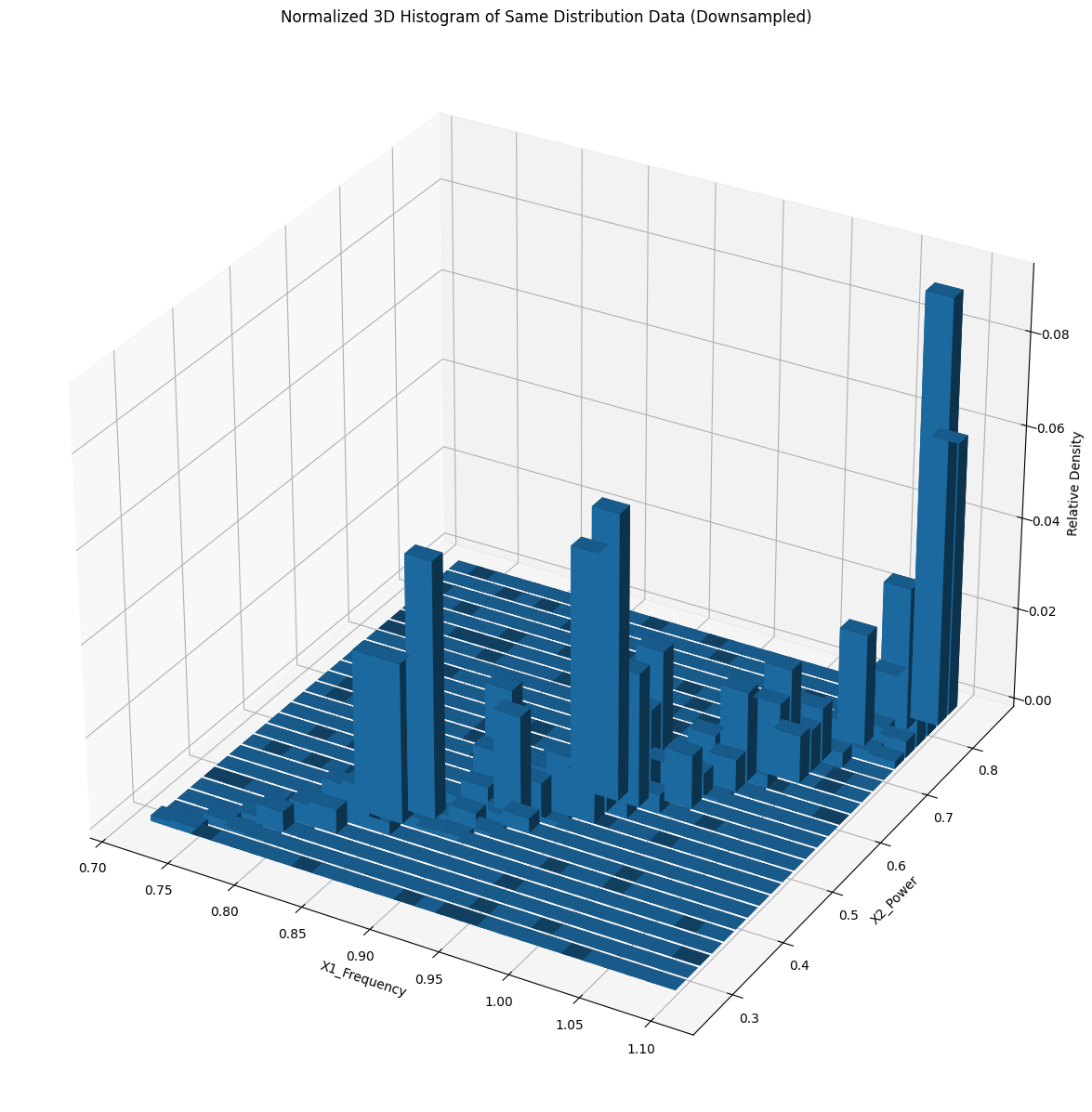
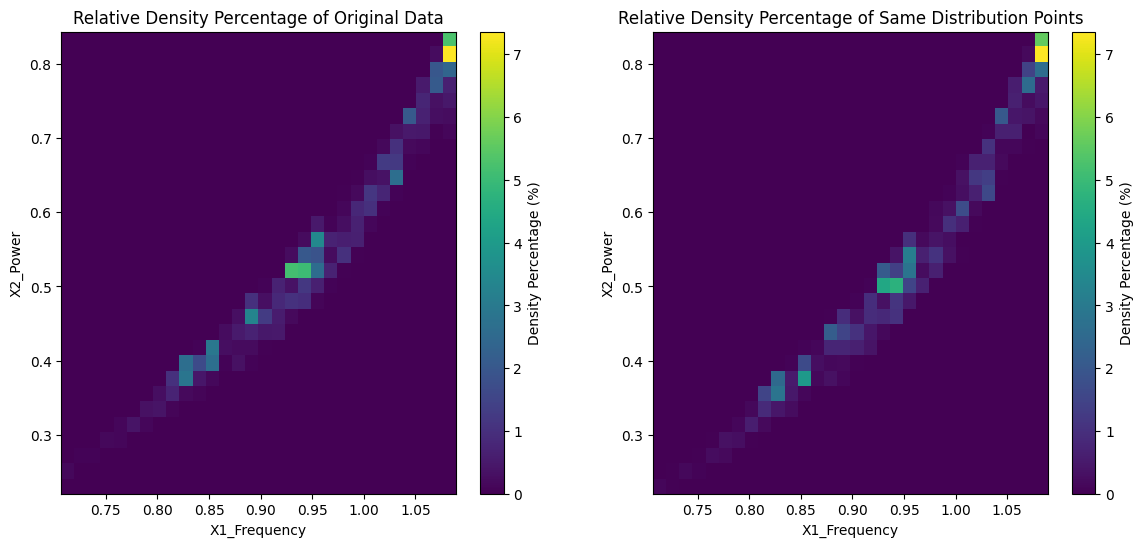
Downsampled Similar Distribution (Dataset 1)
-
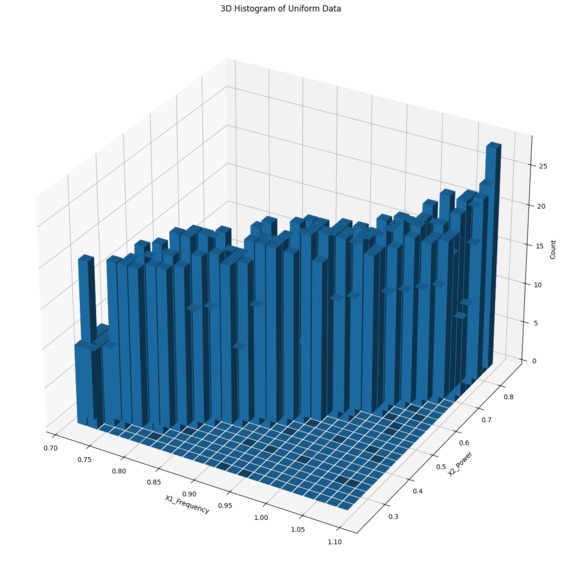
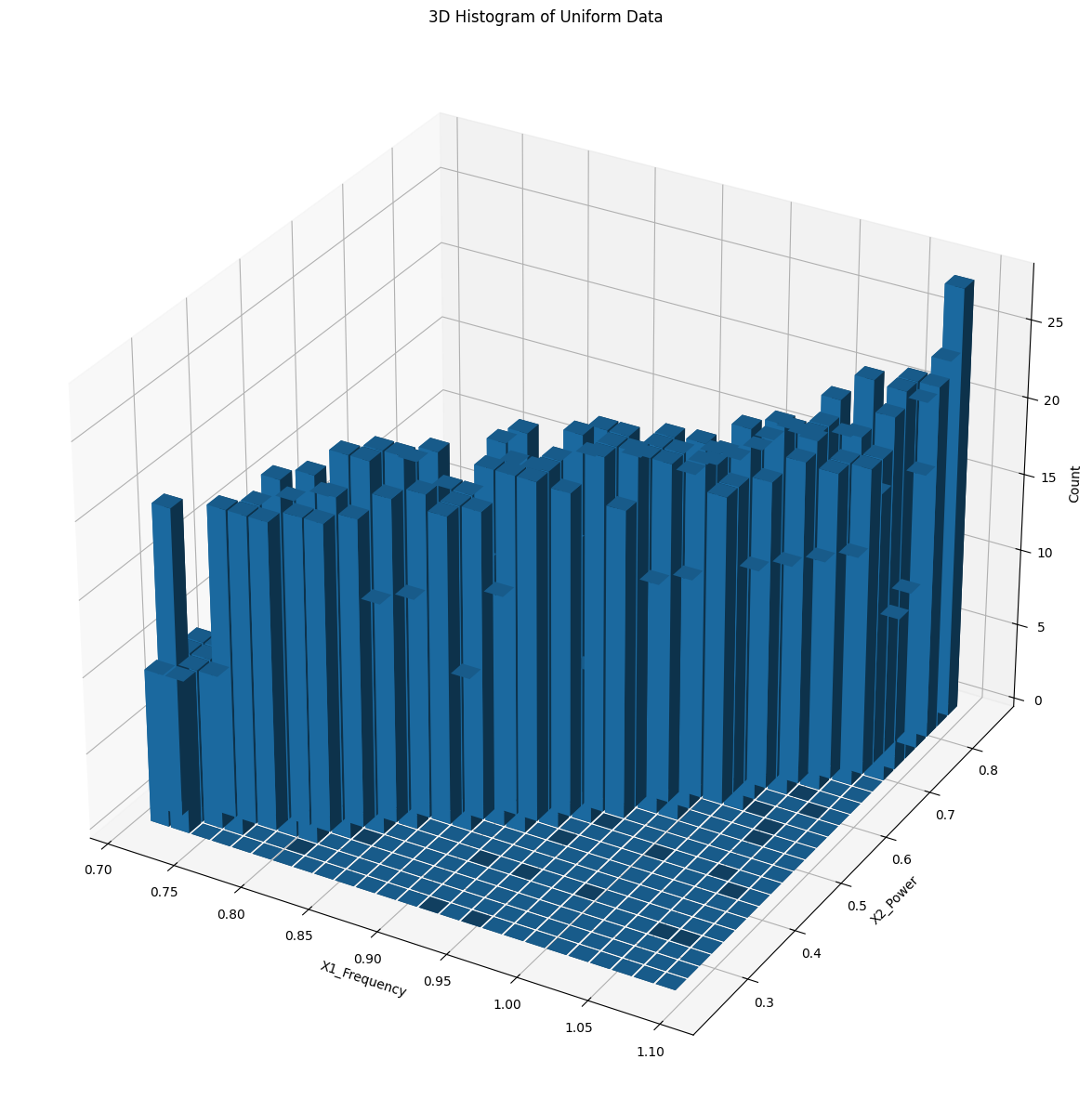
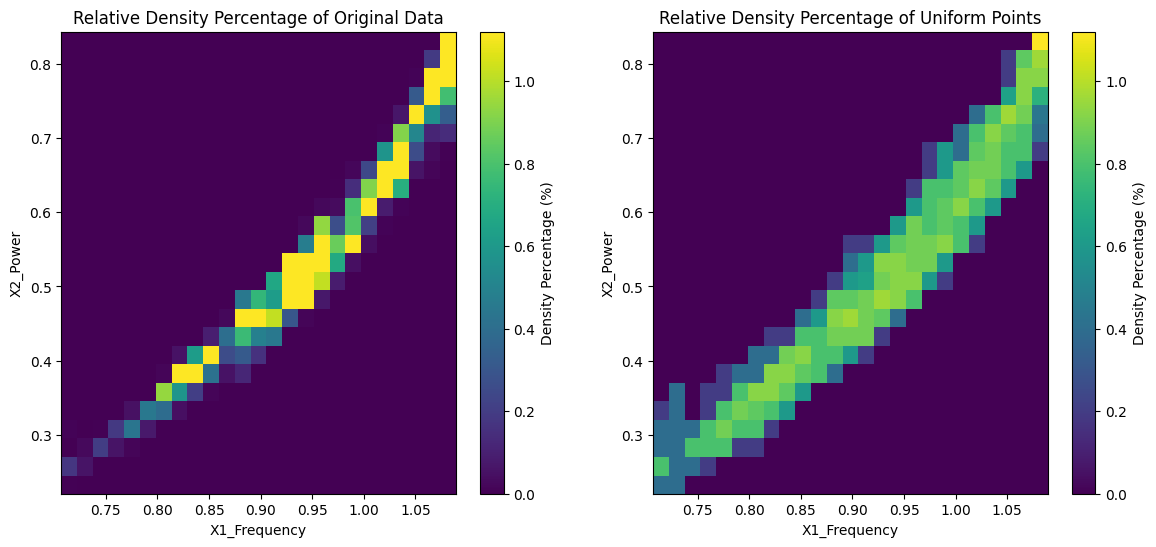
Downsampled Uniform Distribution (Dataset 1)
-
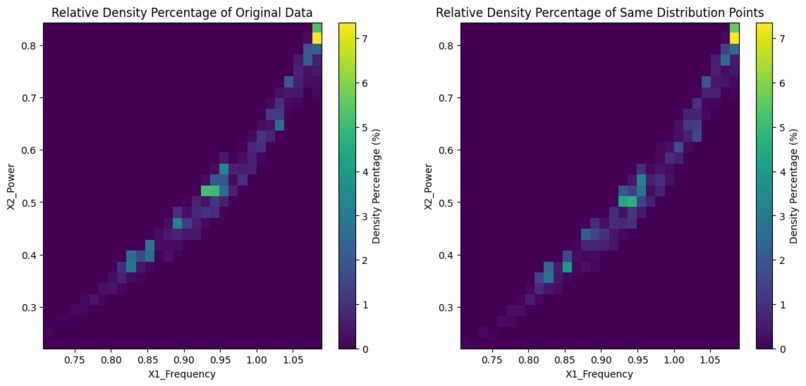
Original Distribution vs Same Shape Distribution Density Plots
-
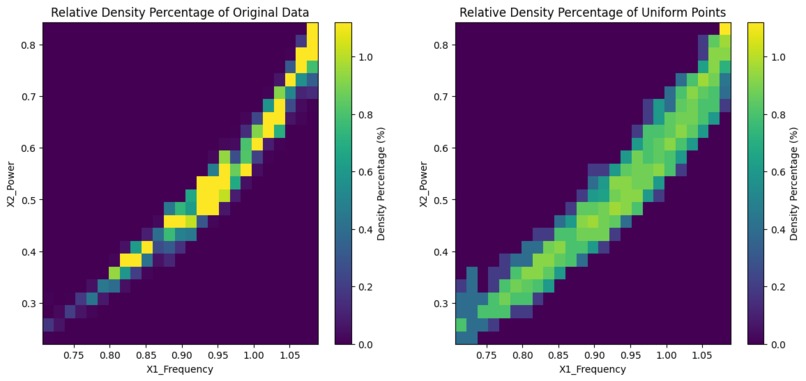
Original Distribution vs Uniform Distribution Density Plots
-
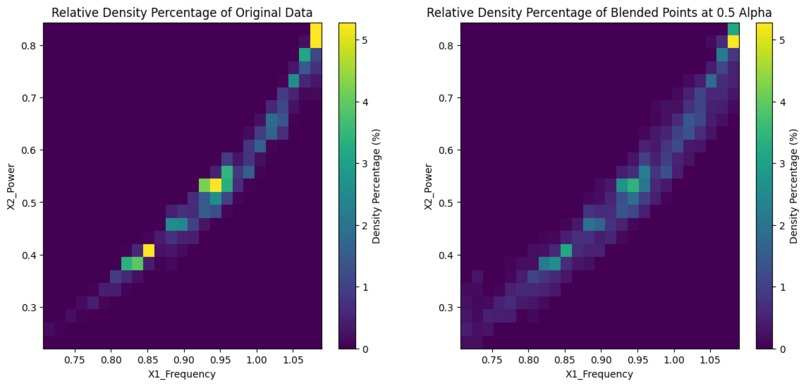
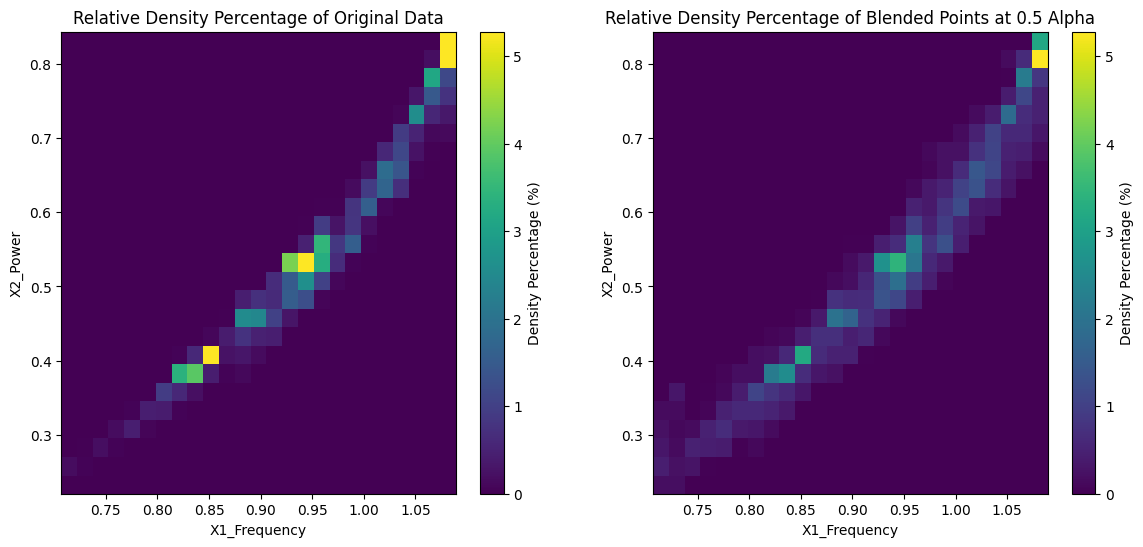
Original Distribution vs Blended Distribution (Alpha: 0.5) Density Plots
Inspiration
The need for smarter and more efficient monitoring of electric motors is what inspired this project. We saw an opportunity to apply data science, machine learning, and statistical analysis to improve predictive maintenance, and transform electric motor health and load proactively.
What it does
Our model uses data from sensors that track frequency and power to predict health degradation in electric motors by selecting 2500 key data to represent the entire dataset. These selected data points help represent the original dataset, and enable the precise and efficient operation of the condition monitoring system.
How we built it
We used the sensor data to create an output the original distribution as a comparable baseline. Next, we utilized a data selection algorithm to reduce the dataset size while persevering crucial information from the data. Finally, we plotted the sampled data in 2D scatter plots and 3D histograms to visualize and compare the distributions and density percentages of the original and sampled data.
Challenges we ran into
The greatest challenge we faced was trying to efficiently reduce the dataset from 500,000 points to 2,500 without losing any valuable information. We had to make sure that we captured a uniform distribution while also collected points from high density areas which impacted our algorithm approach and testing. Furthermore, deciding on a metric to decide which datapoints to use represent a cluster added complexity to our approach and testing processes.
Accomplishments that we're proud of
We're proud that we created models that compress a massive dataset into manageable representative subset while retaining high accuracy. Additionally, as a group we were able to identify many different algorithms that selected key data points, and select the best approach based on group discussions.
What we learned
We were able to gain experience with downsampling and various clustering techniques to uniformly balance the selected data in a real-world application. Aiming to balance high density areas with a uniform distribution required us to explore various methods of effective point selection such as utilizing bins, assessing coefficient of variation, and redistribution of excess points.
What's next for ---
We would like to refine our model to explore more advanced sampling techniques to integrate datapoints that show better accuracy in comparison to the dataset. Furthermore, observing how our approach would execute in the industrial setting would allow us to identify how well our models perform.


Log in or sign up for Devpost to join the conversation.