-
-
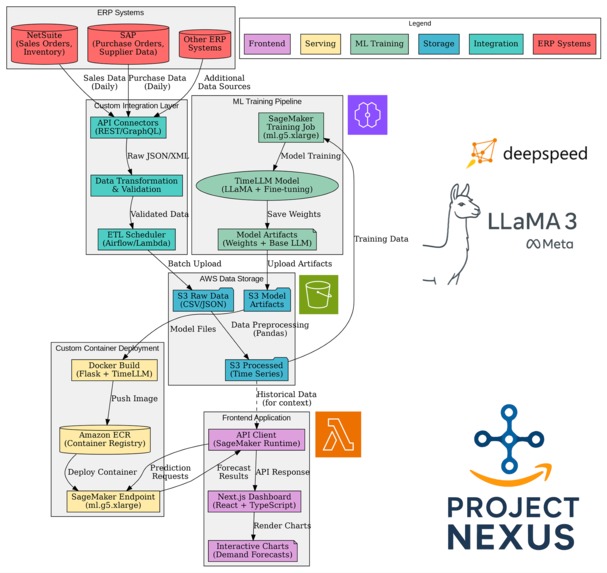
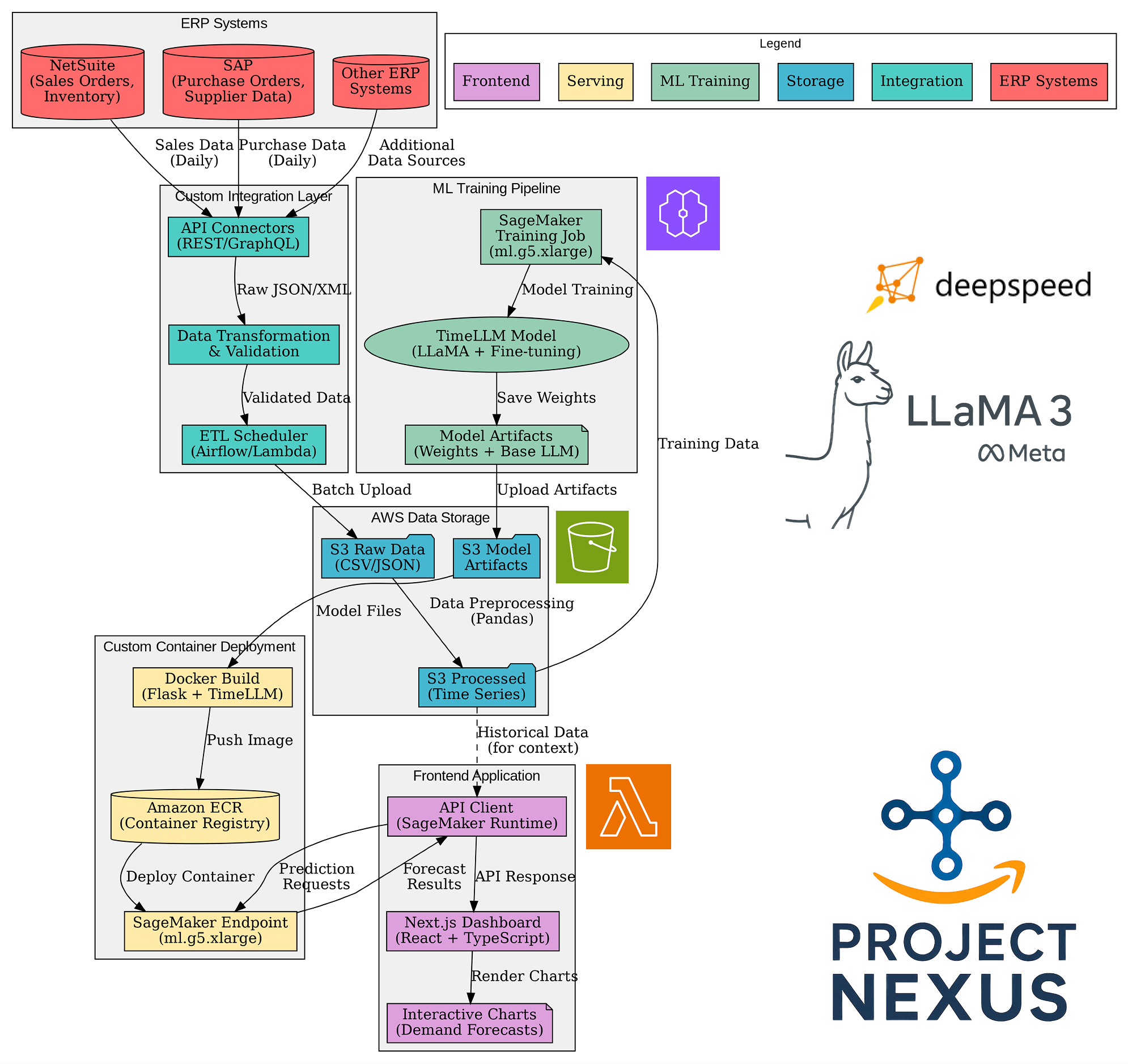
Application Architecture
-

Data Flow Diagram
-
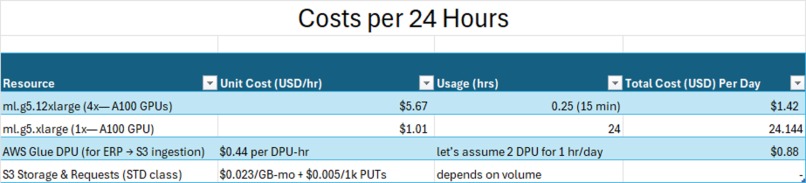
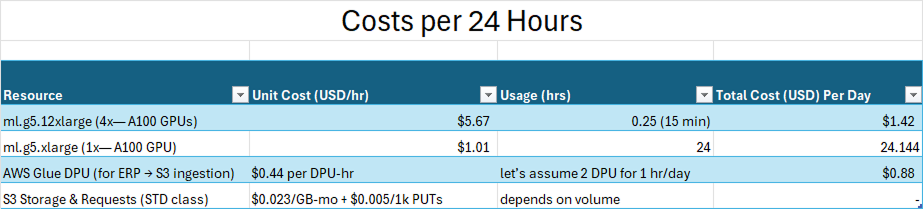
Cost Breakdown

Inspiration
Enterprise supply chain forecasting is broken—most companies still rely on brittle, legacy models and fragmented data sources, leading to costly overstocking, stockouts, and poor visibility. State-of-the-art time series LLMs like Meta’s Llama 3 are transforming text, but haven’t been weaponized for operational forecasting at scale. We set out to build a pipeline that doesn’t just fine-tune a model, but actually solves the data-to-prediction gap for real enterprise ERP systems, end-to-end on AWS.
What it does
TimeLLM Supply Chain Forecasting delivers automated, high-accuracy forecasting for product demand, category sales, and key KPIs across complex supply chains. It ingests real (or synthetic) ERP data, processes and aggregates it, and fine-tunes Llama 3 models (via TimeLLM reprogramming) on AWS SageMaker. It then serves real-time forecasts via scalable, production-ready APIs.
- End-to-end AWS pipeline: From ERP integration → ETL → S3 → SageMaker → live inference endpoint.
- LLM-based forecasting: Fine-tunes Llama 3 via patch reprogramming for four supply chain prediction tasks.
- Zero-touch deployment: Fully automated data flow, training, and serving.
- Cost-efficient: Runs training for under \$2/model and 24/7 inference for ~\$25/day.
- Real dashboards: Next.js dashboard for visualization; REST API for integration.
How we built it
Architecture:
- Data ingestion from ERP (NetSuite, SAP, Oracle, or synthetic).
- ETL/validation (Airflow/Lambda) → S3 for raw/processed data.
- Model training: TimeLLM with Llama 3 backbone, patched for tabular time series via prompt reprogramming.
- Training on
ml.g5.12xlarge(15min/job) with DeepSpeed. - Artifacts deployed to SageMaker Endpoint (
ml.g5.xlarge). - Frontend: Next.js dashboard, Chart.js visualizations.
Model details:
- Patch reprogramming adapts LLM to time series.
- Four models: demand, product, category, KPI.
- Realistic synthetic ERP generator for demo/trials.
Challenges we ran into
- HuggingFace Gated Model Access: Llama 3.2-3B requires manual approval/token config for SageMaker, slowing initial iteration.
- Time Series Reprogramming: Adapting LLM text tokens to numerical time series input is non-trivial—patch/prototype mapping and embedding alignment is complex and under-documented in open source.
- AWS SageMaker Quirks: Resource quotas, deployment cold starts, and endpoint timeouts are still rough edges.
- Synthetic Data: Real ERP data is proprietary; generating realistic synthetic flows and corner cases (promotions, returns, OOS) required extensive feature engineering.
- Model/Infra Cost Management: Keeping training/inference under budget while maximizing sequence length and batch size.
Accomplishments that we're proud of
- Full E2E ML Pipeline: From raw ERP data to production-grade inference endpoint.
- State-of-the-art Forecasting: Outperforms classical methods on simulated benchmarks, handles demand spikes and promo effects.
- Lowest Possible Cost: Training a full model for \$1.42, inference at <\$0.025/1K predictions.
- Reproducibility: One-click synthetic data gen, fully scripted deployment.
- Scalable: Easily supports multi-model/multi-tenant setups.
What we learned
- LLMs can do tabular time series—with the right prompt engineering and embedding hacks, large language models can be reprogrammed for non-text domains.
- SageMaker is a double-edged sword: Incredibly powerful but still friction-heavy for advanced use cases; automation and debugging are not trivial.
- Synthetic data is a double-blind: Great for dev and stress tests, but limits real-world deployment until pipelines are connected to live ERP data.
- Prompt engineering ≠ magic: Model quality is capped by the alignment between input structure and what the LLM “expects”—naive prompt hacks won’t cut it for complex domains.
What's next for TimeLLM Supply Chain
- Plug into real ERP systems: Secure pilot integrations with NetSuite/SAP for live trials.
- Push larger models: Fine-tune 8B+ Llama on multi-modal ERP data (text + time series).
- Automate retraining: Build automated model refresh/monitoring for true continuous learning.
- Expand use cases: Inventory optimization, dynamic pricing, anomaly detection, and supply shock simulation.
- Open source: Release synthetic data generator and data schema for community benchmarking.
Built With
- lambda
- llama
- nestjs
- python
- pytorch
- sagemaker
- timellm
- typescript





Log in or sign up for Devpost to join the conversation.