-
-
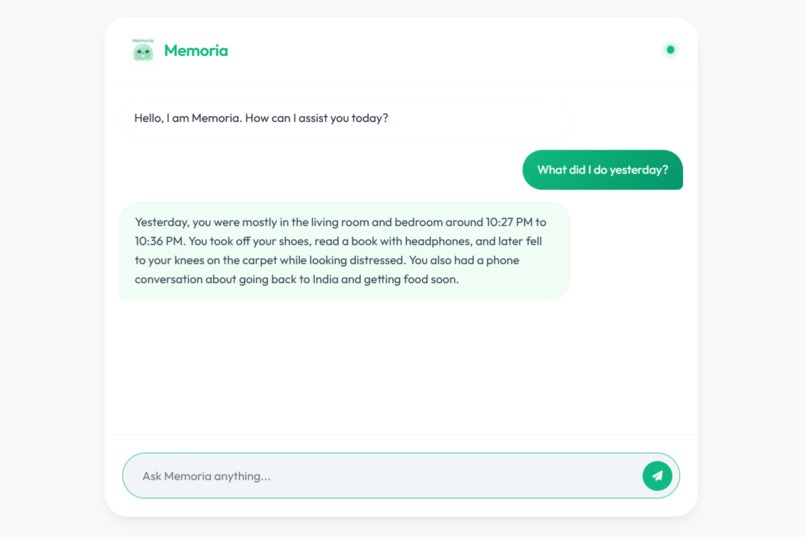
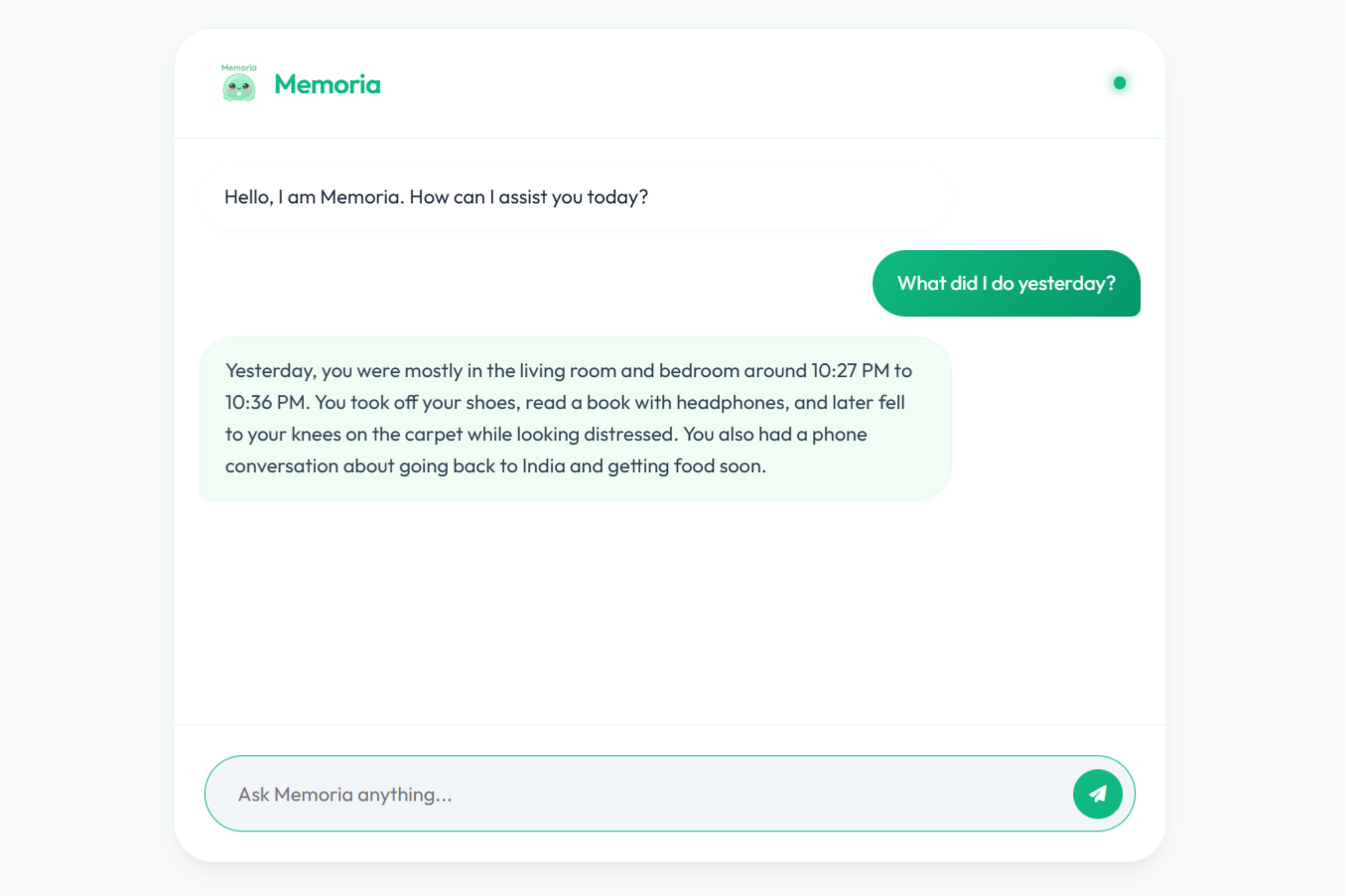
Time Based Queries
-
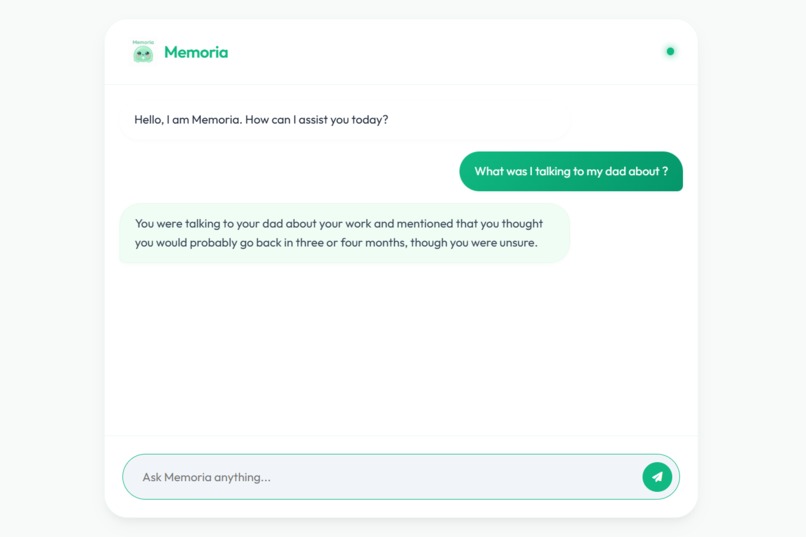
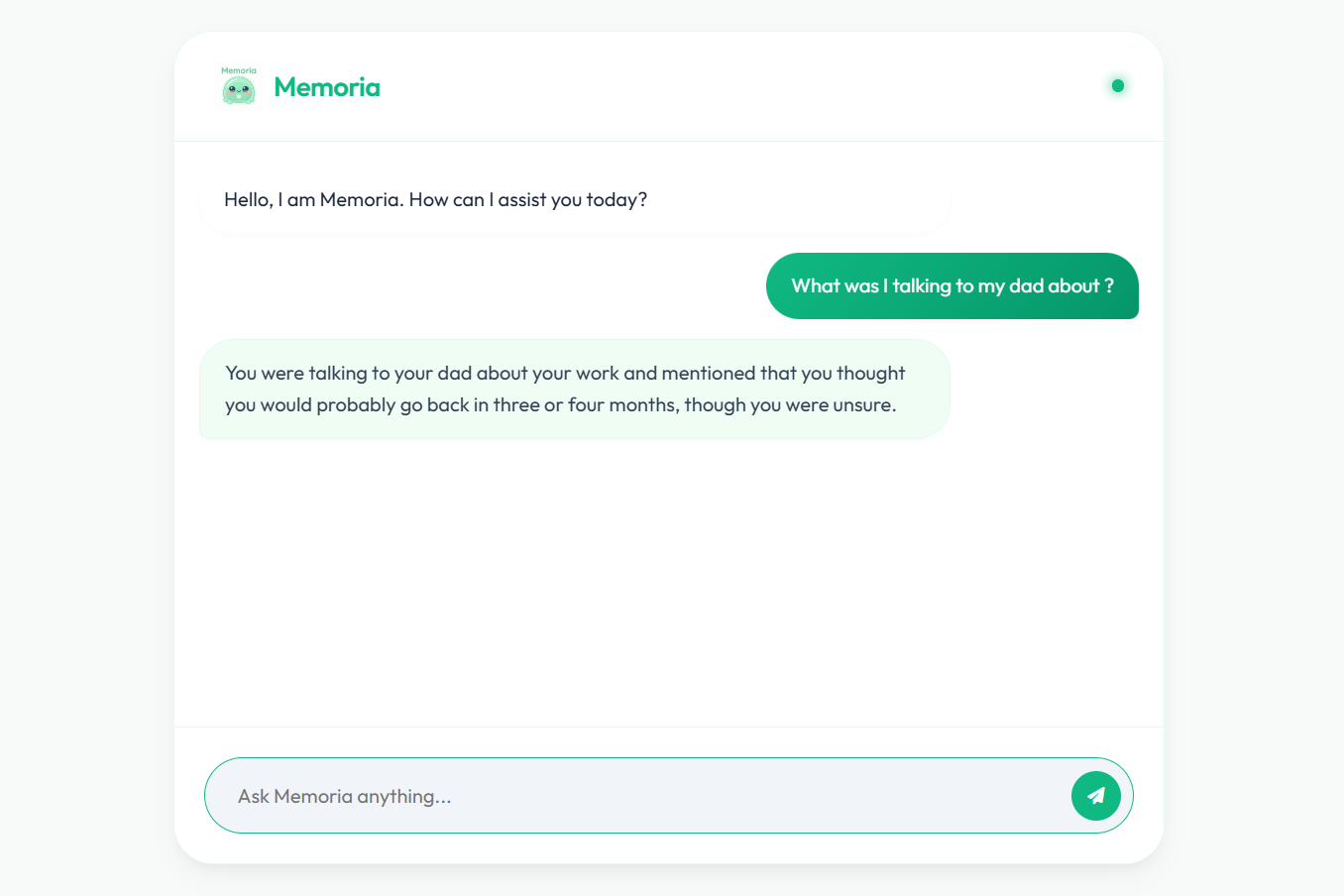
Semantic Based queries
-
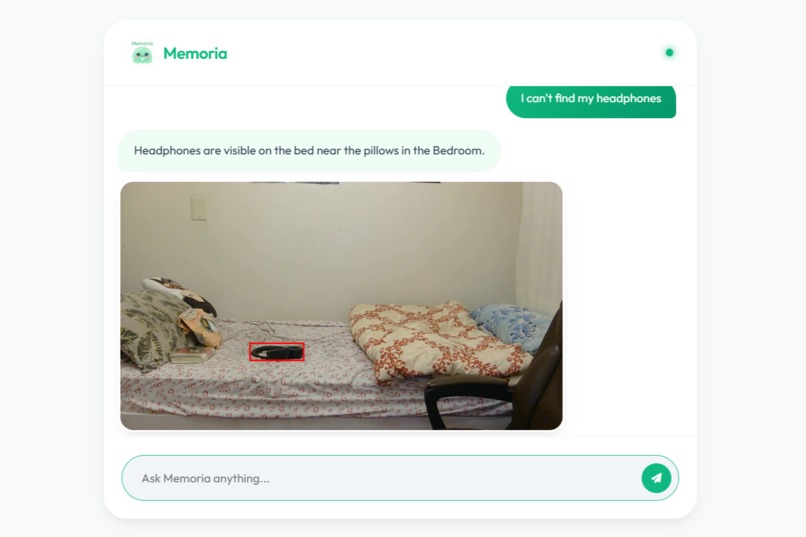
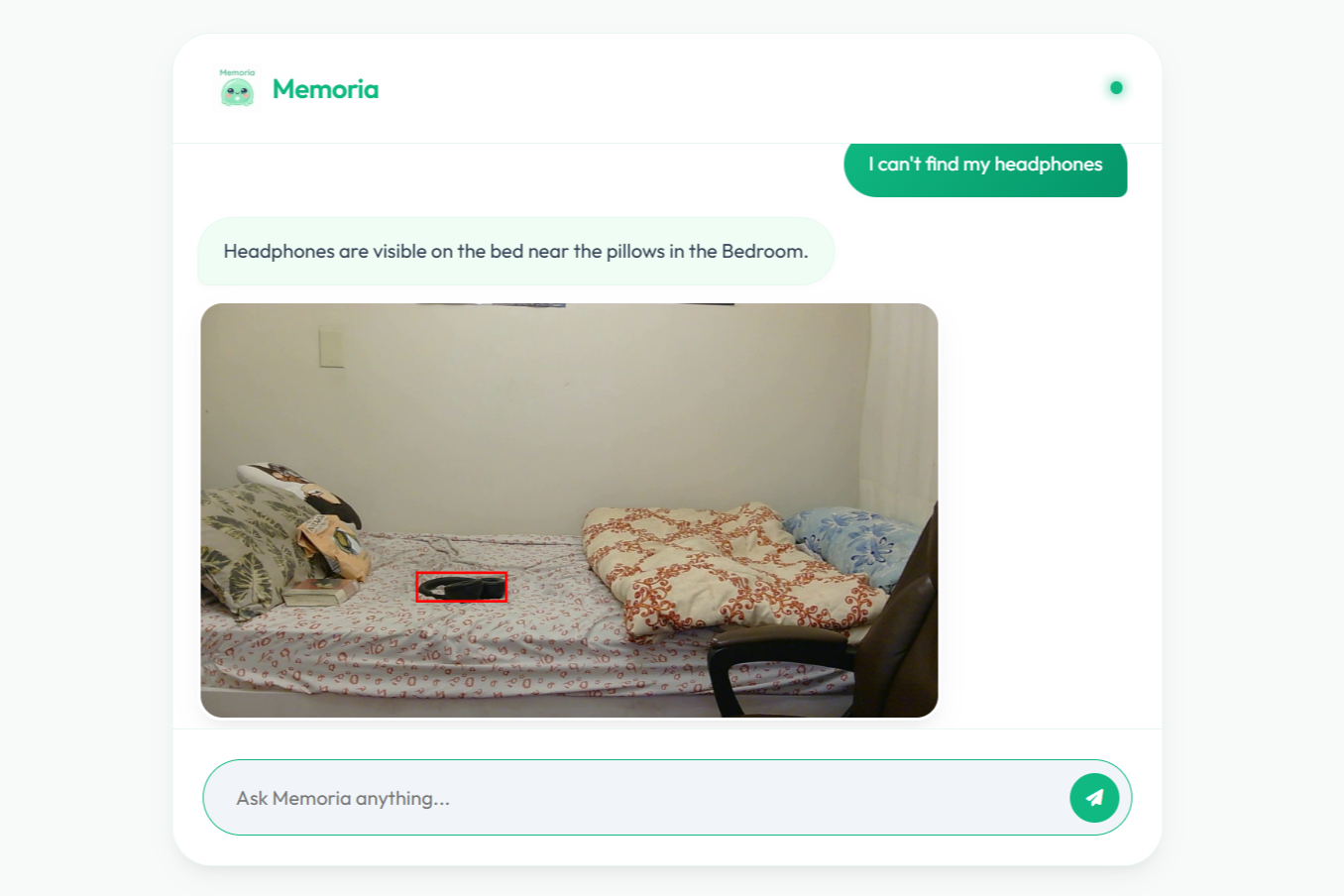
Object Recall and Object Highlighitng
-
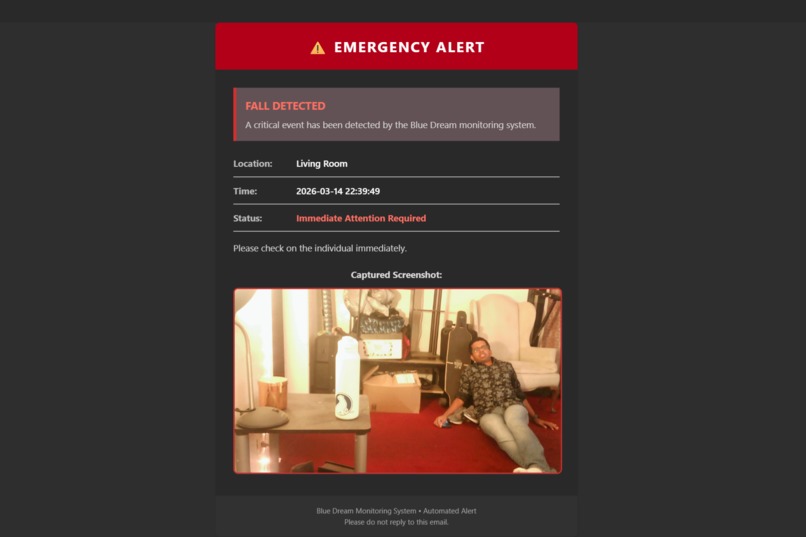
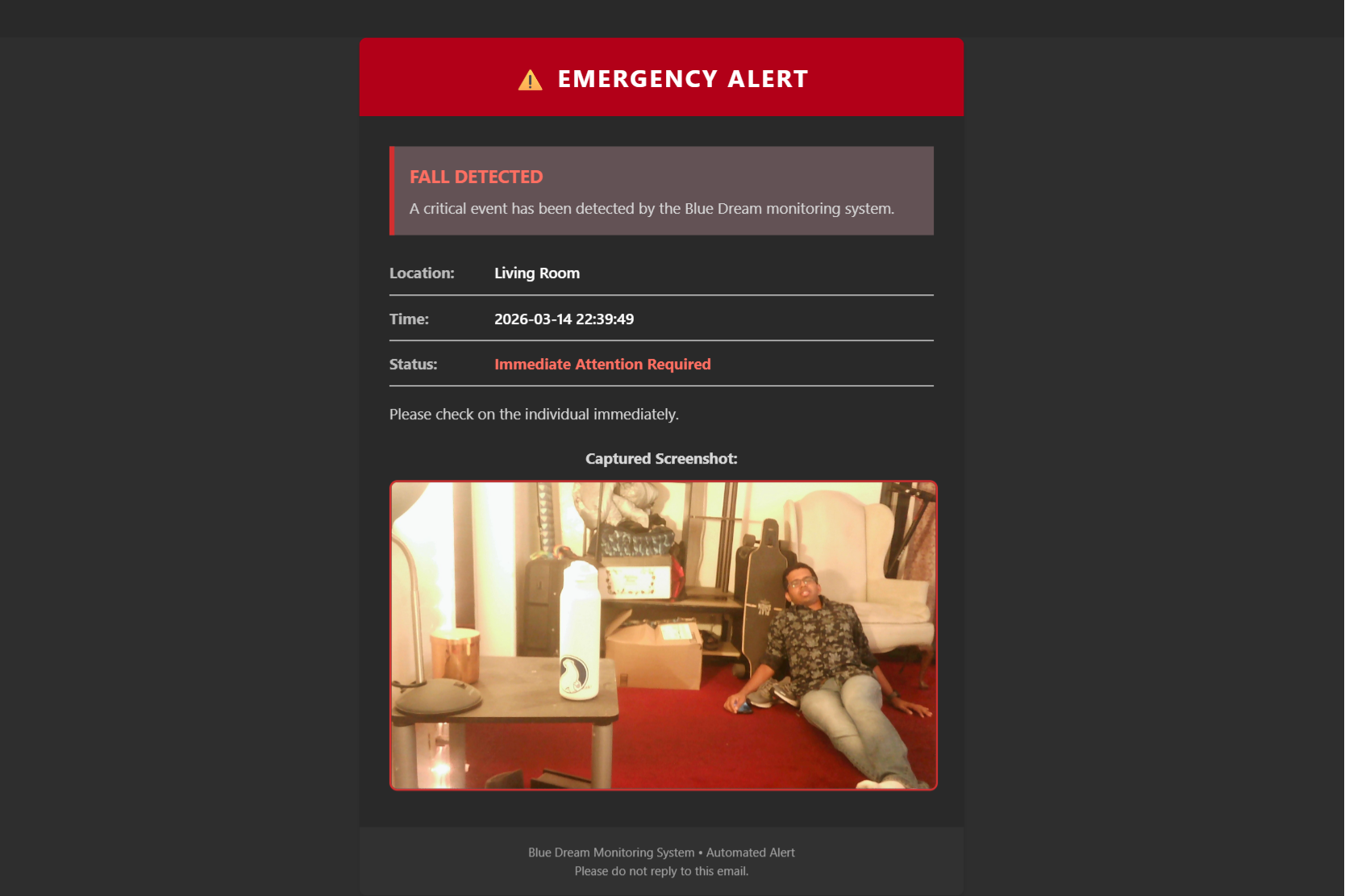
Emergency Email after Fall Detection
-

Our Mascot!

Project Memoria
Project Memoria was inspired by a simple problem with serious consequences: when someone with dementia forgets where they placed an object, what they were doing, or what they were talking about earlier, that confusion can quickly become stressful for both the patient and the caregiver. At its core, Memoria is powered by Amazon Nova 2 Lite as the reasoning and query-routing layer, and Amazon Nova multimodal embeddings to semantically index and retrieve memory events, enabling efficient, context-aware recall without loading unnecessary history.
Features
- Fall detection and caregiver alerts
- Time Based Memory Recall (e.g., What was I doing in my bedroom yesterday night?)
- Object location assistance (e.g., I can't find my water bottle in any room)
- Semantic memory questioning (e.g., What was I talking to my son about?)
How I Built It
I had built an earlier version of this idea with fall detection, emergency alerts, memory recall, and image highlighting, but it was too resource-intensive and inefficient. Time-based queries often pulled in large windows of events even when the user only needed one specific action or conversation, which wasted context and reduced reliability.
For this hackathon version, I rebuilt the assistant around Amazon Nova as the core reasoning layer. I used Amazon Nova 2 Lite in a Strands-style agent architecture so the model can route queries, judge retrieval quality, synthesize responses, and decide when semantic memory needs additional time-based grounding. I also used Amazon Nova multimodal embeddings to index memory events in a vector database.
I kept MongoDB as the source of truth for full event history, used ChromaDB as the vector index, and exposed the system through a FastAPI-based web app. Instead of always loading a broad time range, Memoria first retrieves the most semantically relevant events, then pulls nearby timeline context only when that improves grounding and answer quality. For object highlighting, I replaced the older SAM 3 approach with a lighter image-localization workflow, which reduced the cost and complexity of that pipeline.
Challenges
The biggest challenge was balancing accuracy with efficiency. In assistive AI, a system should not confidently invent details just because it retrieved something vaguely related. I learned that retrieval quality matters as much as model quality: the hard part is not only generating an answer, but deciding what evidence to trust, when to widen the search, and when to admit uncertainty. That was the most important shift from the earlier version of Project Memoria to this hackathon rewrite.
Built With
- chromadb
- fastapi
- gemini
- javascript
- mongodb
- nova
- opencv
- pillow
- pyaudio
- python
- strands
- yolo











Log in or sign up for Devpost to join the conversation.