-
-
VISTA - Architecture Diagram
-

Team - Cortex
-

VISTA - Logo
-

Title



VISTA — Video Intelligence with Spatio-Temporal Augmented Retrieval for Egocentric Understanding
"A 6-month-old baby has better spatial memory than the most advanced vision-language models in the world. We built VISTA to change that."
Inspiration
Ironsite captures hours of first-person construction footage every single day. Supervisors watching those feeds face a deceptively hard problem: the footage remembers everything, but the AI remembers nothing.
We noticed that most spatial and temporal tasks are tricky for frontier models, not because they lack perception, but because they lack persistent memory of the physical world. Ask Gemini "Where's the ladder the worker walked past two minutes ago?" and it struggles. Not because it can't recognize a ladder, but because the moment that ladder left the camera's view, it ceased to exist for the model. The context of the physical world - where things are, where they were, how they changed , simply isn't there. Every frame is a blank slate.
That's when it clicked for us. RAG transformed what LLMs could do by giving them structured, retrievable memory over documents. We wanted to do the same thing for video - turn raw footage into structured, queryable spatial-temporal memory that any VLM can retrieve from. The same way RAG enabled LLMs to answer questions over knowledge they were never trained on, our Spatio-Temporal RAG enables VLMs to answer questions over physical spaces they can no longer see.
Construction supervisors don't need a fancier object detector. They need an AI that remembers the physical world the way humans do - that knows the scaffold is still behind you even though you turned away thirty seconds ago, that knows when exactly the worker started laying bricks, and that can tell you whether a tool was ever returned to where it was dropped. That's what inspired VISTA.
What It Does
VISTA wraps a lightweight Spatio-Temporal RAG layer around existing frontier VLMs, giving them persistent memory of the physical world from a single monocular egocentric camera - no GPS, no SLAM, no IMU, no depth sensors required.
It enables five capabilities that no standalone VLM can achieve today:
- Temporal Retrieval - "At what point does the worker lay the first brick?" VISTA pinpoints the exact timestamp from entity state changes.
- Productivity Analysis - "How long was the worker idle?" VISTA diffs entity states across the full timeline to compute idle vs. active durations.
- Object Permanence - "Where is the ladder right now?" Entities persist in world-fixed coordinates even after leaving the camera's view entirely.
- Directional Reasoning - "What's behind me?" VISTA knows the answer because it maintains allocentric heading at all times.
- Temporal Reasoning - "Does the worker return to where they dropped the tool?" VISTA checks the entity's observation timeline against the full video duration.
Supervisors no longer scrub through hours of footage. They just ask.
How We Built It
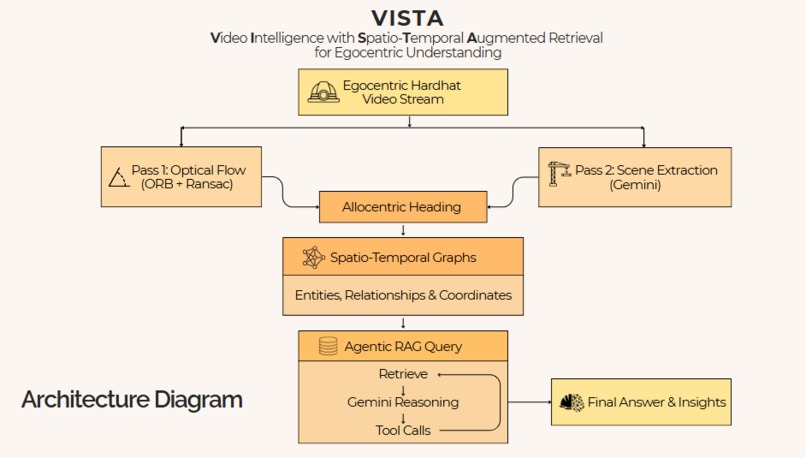
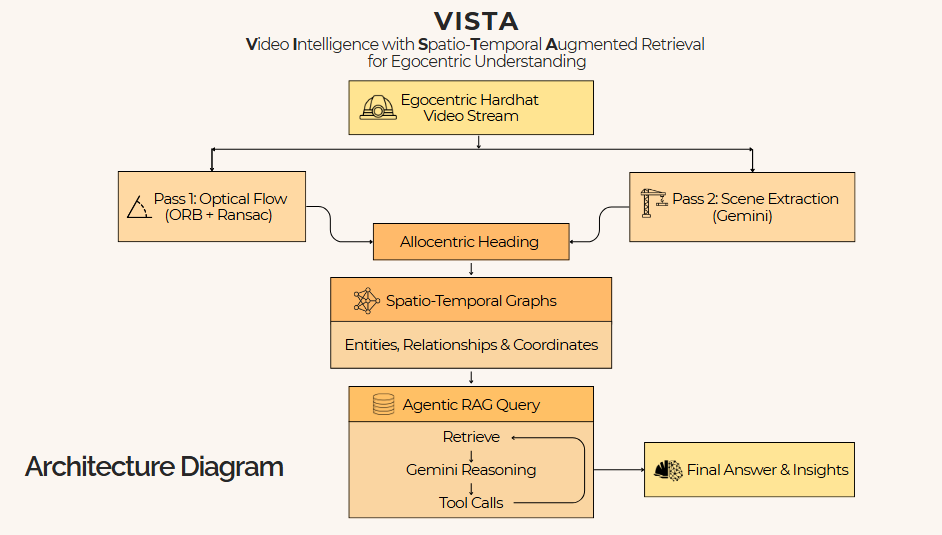
VISTA's pipeline runs in three stages:
Stage 1 — Parallel Video Processing
Two passes run simultaneously on the incoming egocentric video stream:
Pass 1 — Optical Flow (every frame):
We use ORB feature detection with 500 keypoints per frame, matched via BFMatcher with Hamming distance and filtered through Lowe's ratio test at 0.75. Surviving matches feed into an affine decomposition via OpenCV's estimateAffinePartial2D with RANSAC, extracting per-frame camera rotation (d_theta) and translation (dx, dy).
The key insight: we accumulate the per-frame rotation continuously across the entire video. This running total gives us an allocentric heading — a world-fixed compass direction that tells us exactly which way the camera is pointing at any moment. Rotational drift stays below 2 degrees over 60 seconds of typical construction footage, making it reliable without GPS, IMU, or any external positioning system. This is effectively a free vestibular system — built from nothing but pixel math.
Pass 2 — Scene Extraction (every 30th keyframe): Keyframes are sent to Gemini 2.5 Flash (temperature 0.1, structured JSON output) with a prompt that extracts entities — workers, tools, equipment, structures — with bounding boxes, confidence scores, visual descriptions, current states, and spatial relationships. Up to 10 concurrent API calls run in a thread pool, so Gemini latency is fully hidden behind optical flow computation.
Stage 2 — The Spatio-Temporal Scene Graph
Both passes converge into a persistent scene graph — the core data structure that makes everything possible.
Each detected entity is transformed from pixel coordinates into world-fixed polar coordinates: the entity's horizontal position in the frame becomes an egocentric angle (based on the camera's field of view), then the camera's accumulated heading is added to produce an allocentric angle — one that stays fixed in world space regardless of where the camera looks next. Distance is estimated from the entity's vertical position in the frame.
Entity merging provides object permanence: new observations are matched against existing entities by label (fuzzy substring matching), category, and spatial proximity — within 20 degrees and 0.25 distance units for people, doubled to 40 degrees and 0.5 for structures and equipment. Matched observations merge with an exponentially weighted position update (alpha = 0.3). Unmatched observations create new entities.
Confidence decays at 0.015 per second for unobserved entities, pruning below 0.2. Briefly glimpsed objects fade naturally while consistently observed entities remain persistent.
The result: a queryable spatio-temporal map of reality — entities with world-fixed coordinates, full observation chains over time, tracked states, and spatial relationships — persisting even when completely off-camera.
Stage 3 — Agentic RAG at Query Time
Natural language queries are resolved through an agentic RAG loop using Gemini's function-calling API with nine graph query tools:
get_entities_in_direction— spatial lookups by compass directionget_spatial_relation— geometric angle and distance between two entitiesget_entity_timeline— how an entity's state changed over timeget_entities_at_time— what was visible at a specific timestampget_entity_info— full observation history, relationships, and attributesget_relationships— filtered relationship traversal across the graphget_direction_at_time— camera heading at a past momentget_changes— state transitions and diffs over a time windowget_all_entities— summary statistics and category counts
Gemini decides which tools to call and in what order, iterating through up to 5 tool-calling rounds before synthesizing a final natural language answer. The system prompt injects live scene graph statistics — entity count, category breakdown, heading, time range — so Gemini knows what data is available.
The entire pipeline processes a 10-minute video in 30–40 seconds end to end, and answers queries in 2–5 seconds.
Challenges We Ran Into
Coordinate system hell. Translating pixel-space bounding boxes into stable world-fixed coordinates across a constantly moving, rotating camera required careful math. The allocentric heading accumulation had to stay numerically stable — and not drift into nonsense — across hundreds of frames. Getting the ego-to-allo coordinate transform correct so that "behind-left at -129 degrees" actually means behind-left took significant iteration.
Entity merging ambiguity. When does "worker near scaffolding" at frame 60 and "worker near scaffolding" at frame 120 refer to the same worker? Fuzzy label matching combined with spatial proximity thresholds had to be tuned carefully — too tight and we'd create ghost duplicates, too loose and we'd merge distinct entities. We ended up using wider thresholds for structures and equipment (which don't move) than for people (who do).
Hiding API latency. Gemini Flash calls take roughly 5 seconds per keyframe — orders of magnitude slower than optical flow. Designing the thread pool with 10 concurrent workers to fully parallelize keyframe extraction so it never becomes the bottleneck was non-trivial, but it means a 10-minute video processes in roughly the time it takes to process just a handful of sequential Gemini calls.
No existing benchmarks. There is no standard benchmark for "object permanence in egocentric video" or "spatial reasoning across temporal occlusions." We designed our own evaluation suite — 15 queries across multiple real Ironsite construction videos, spanning spatial, temporal, directional, and change-detection categories — and scored VISTA at 93.3% accuracy (14/15 correct).
Accomplishments That We're Proud Of
- Beat Gemini 3 Flash and Molmo 2 8B on spatial and temporal reasoning over real construction footage, not by replacing frontier models, but by giving them a memory layer they never had.
- Built a free vestibular system from pure optical flow: no GPS, no IMU, no SLAM, no depth sensors — just a monocular camera and math.
- Achieved genuine object permanence in a VLM pipeline for the first time, with entities persisting confidently across occlusions and off-screen intervals.
- End-to-end pipeline that turns raw egocentric video into structured operational intelligence in under a minute.
What We Learned
- Spatial memory isn't about better object detection: it's about architecture. Frame-level models are fundamentally incapable of answering where-and-when questions, no matter how accurate they are per frame. The bottleneck is persistence, not perception.
- Optical flow is massively underutilized in the VLM era. Cheap classical computer vision running at full frame rate provides the spatial scaffolding that expensive foundation models can't: and it costs essentially nothing.
- RAG doesn't have to mean documents and embeddings. Spatio-temporal retrieval: filtering by location, direction, and time rather than semantic similarity is a powerful and underexplored paradigm. The scene graph is the new vector store.
- Agentic tool-calling is the right interface for spatial queries. Letting the model decide which graph tools to call, in what order, across multiple rounds, produces far richer answers than any single retrieval step. A question like "how long was the worker idle?" requires chaining temporal retrieval, state diffing, and duration computation — the agent handles that naturally.
What's Next for VISTA
- Multi-camera fusion — combining overlapping egocentric streams from multiple workers into a shared world model, enabling site-wide spatial awareness from distributed hardhat cameras
- Metric scale estimation — moving from relative distance units to real-world meters using known object sizes as scale references
- Automated progress tracking — detecting work completion percentages, comparing current site state against construction plans, and flagging deviations automatically
- Persistent cross-session memory — a world model that accumulates across multiple days of footage, building a longitudinal understanding of how a construction site evolves over weeks
- Real-time streaming mode — live query support so supervisors can ask questions about what's happening right now, not just in post-processing
Built by Team Cortex at UMD



Log in or sign up for Devpost to join the conversation.