-
-
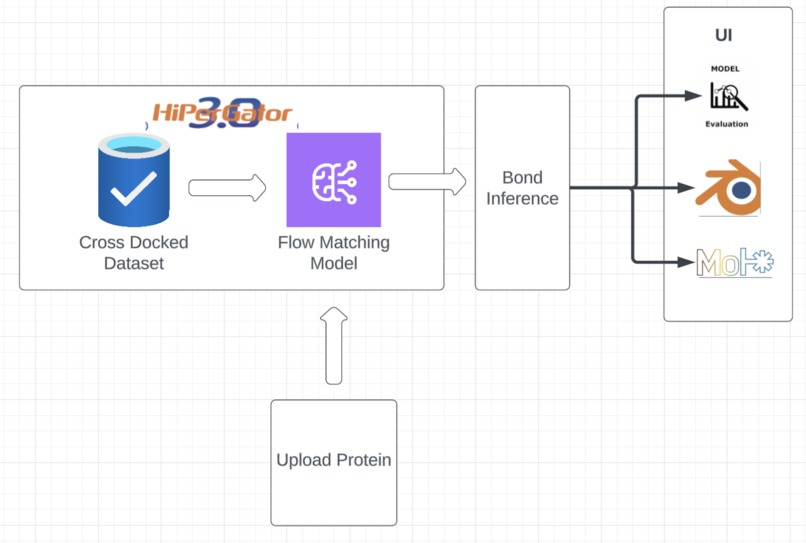
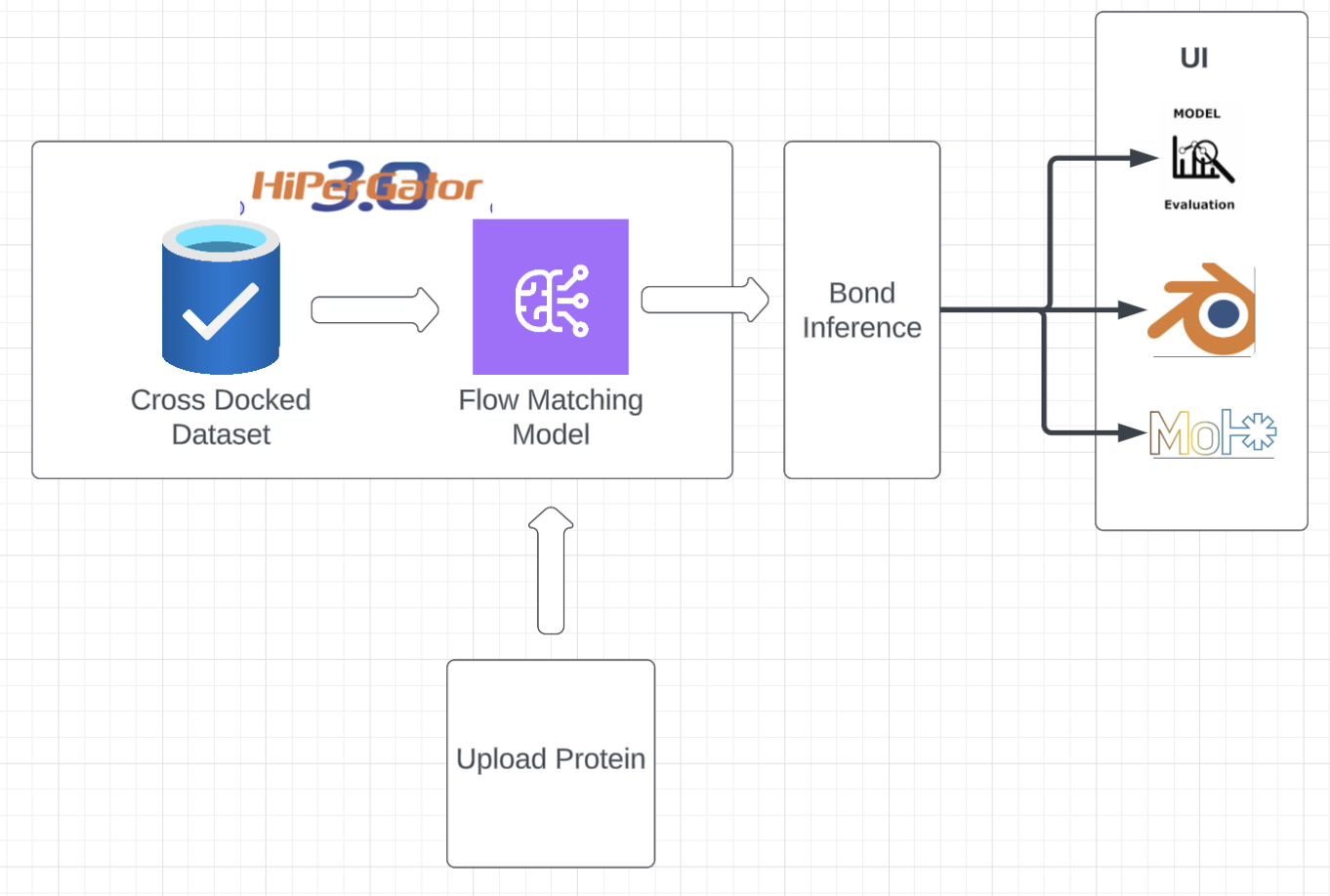
Overall System Design
-
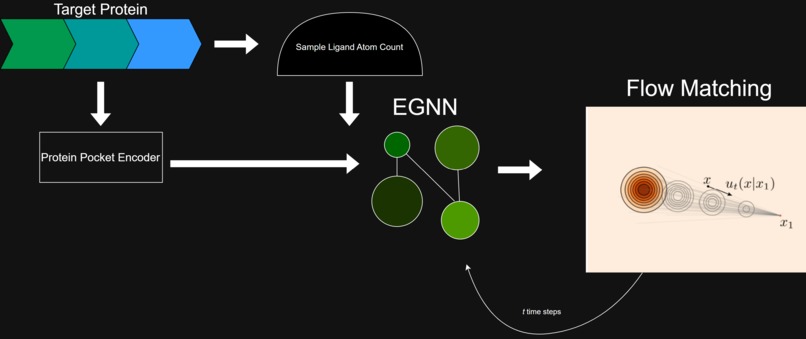
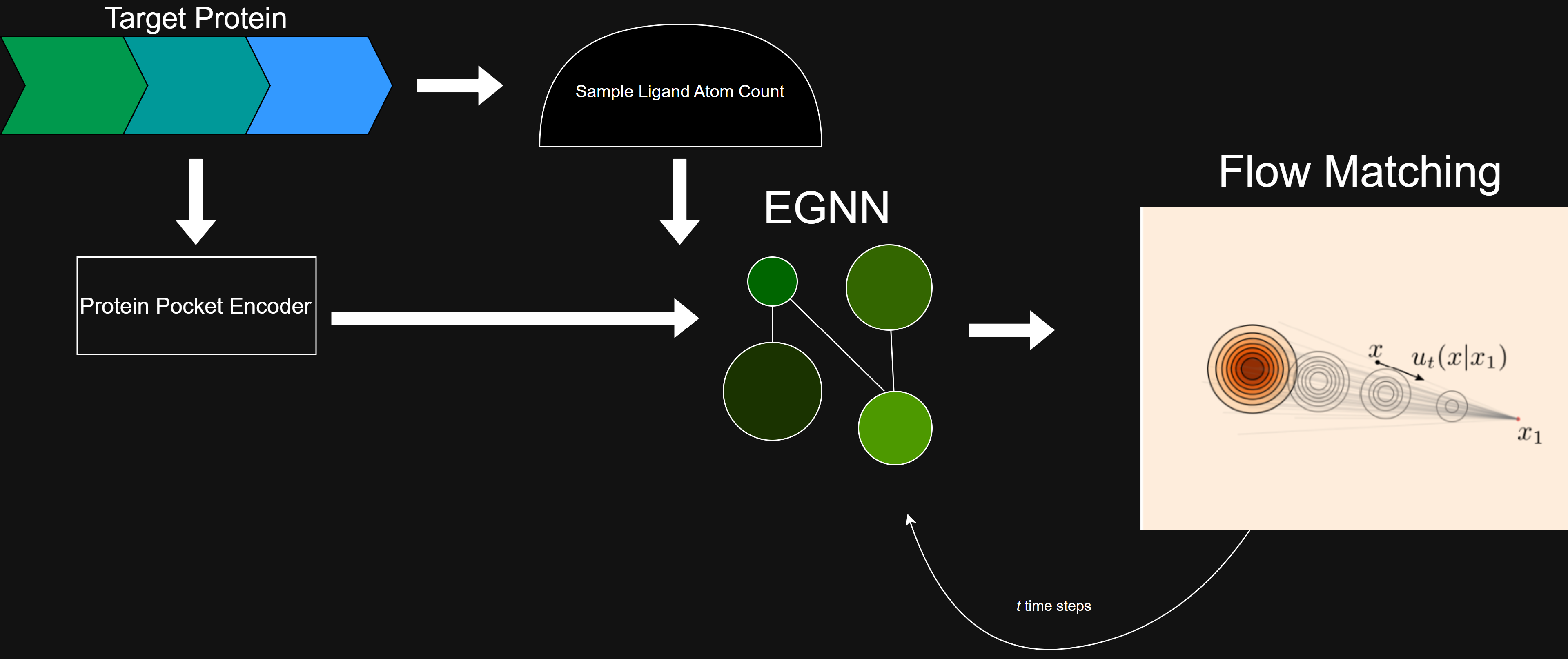
Model Architecture Overview
Inspiration
Proteins are molecular machines that perform various functions in the body. A protein's function is dictated by its structure. In some cases, it is useful to inhibit a protein's function in a patient's body. One way to inhibit a protein is to take a small-molecule drug that fits perfectly in the protein's pocket. However, many target proteins do not yet have a known drug inhibitor. There is existing research (https://arxiv.org/pdf/2303.03543) on advanced ML methods for generating drugs from scratch to bind specifically to the target protein. However, they are still seen as ineffective, partially due to sample-inefficient learning.
What it does
We designed and trained a Flow-Matching Model to generate small-molecule drugs that fit perfectly in the target protein pocket. We also created a website where researchers can upload a target protein of their choice, generate dozens of candidate molecules, visualize them, and analyze them across several evaluation metrics compared to a baseline.
How We Built It
We heavily relied on AI-use to speed up development. We first designed the neural network to improve upon recent research. We trained it and ran inference on a few test-set proteins, and set up the data pipeline for the frontend to read from, then implemented the frontend.
Challenges We Ran Into
Our GPU resource, Hipergator, faced an outage mid-hackathon, hindering our thorough evaluation on the entire test set. Luckily we were able to get just enough final predictions.
Accomplishments We’re Proud Of
We are proud of implementing Flow-Matching to create a faster, more sample-efficient model than recent popular models such as TargetDiff (2023). We are also very proud of our intuitive UI, the beautiful rendering of the molecular complex, the flow animation, and the metrics comparison.
What We Learned
We learned just how more efficient flow-matching is than diffusion, and we refined our AI-use software development workflow to be more efficient.
What’s Next for 蛋白质结合
Our current model’s training objective is to generate ligands that look like the ones in the training set; a natural next step is to formulate a Reinforcement Learning reward function to finetune our pretrained model on. This will allow us to optimize our model to specifically generate the strongest binders possible, while maintaining realistic chemistry.
Built With
- fastapi
- flowmatching
- hipergator
- machine-learning
- molstar
- python
- react




Log in or sign up for Devpost to join the conversation.