-
-

Project Iris
-

The Project Iris landing page, highlighting its core pillars: browser-native edge AI, zero proprietary hardware, and patient privacy.
-
 GIF
GIF
The Iris eye graphic dynamically follows the cursor, previewing the platform's core gaze-tracking capabilities.
-

5-point eye-tracking calibration mapping raw pupil coordinates via WebAssembly MediaPipe to specific screen bounds for precision.
-
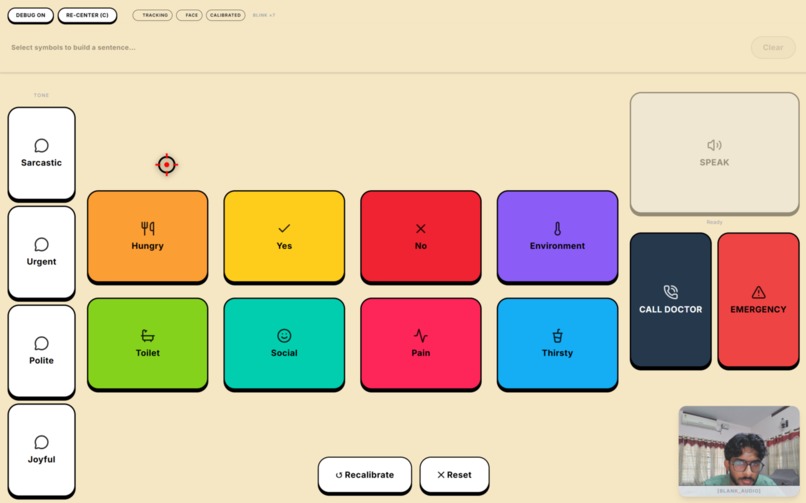
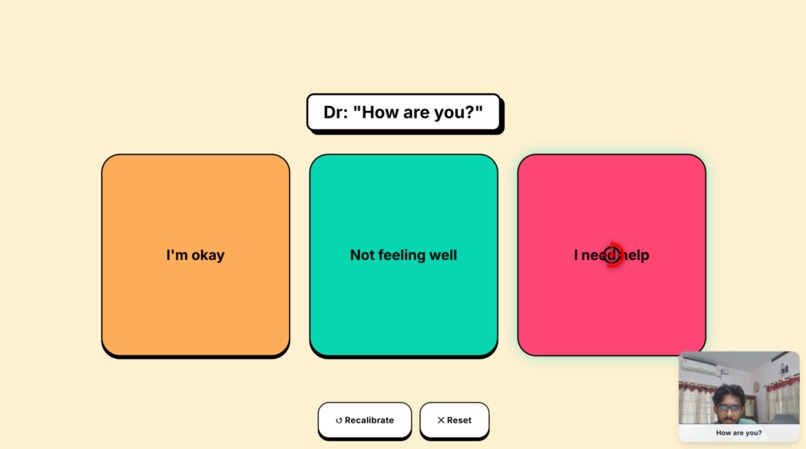
The main high-contrast grid engineered via Fitts's Law. The red crosshair is the real-time, Kalman-filtered gaze cursor navigating tiles.
-
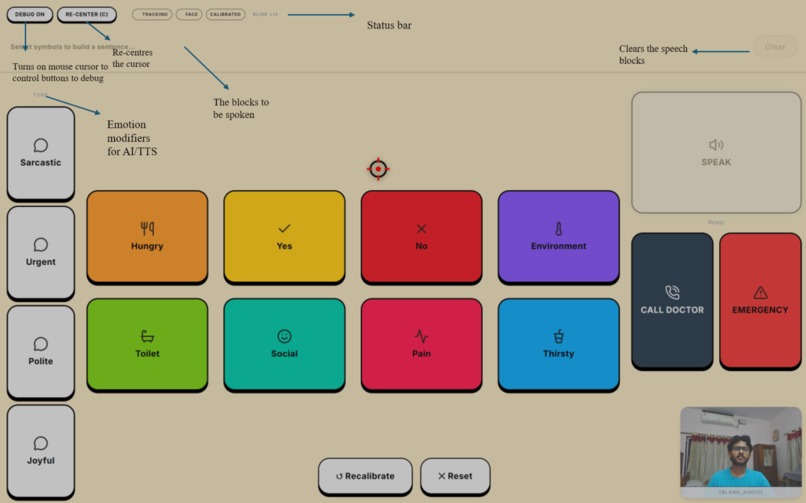
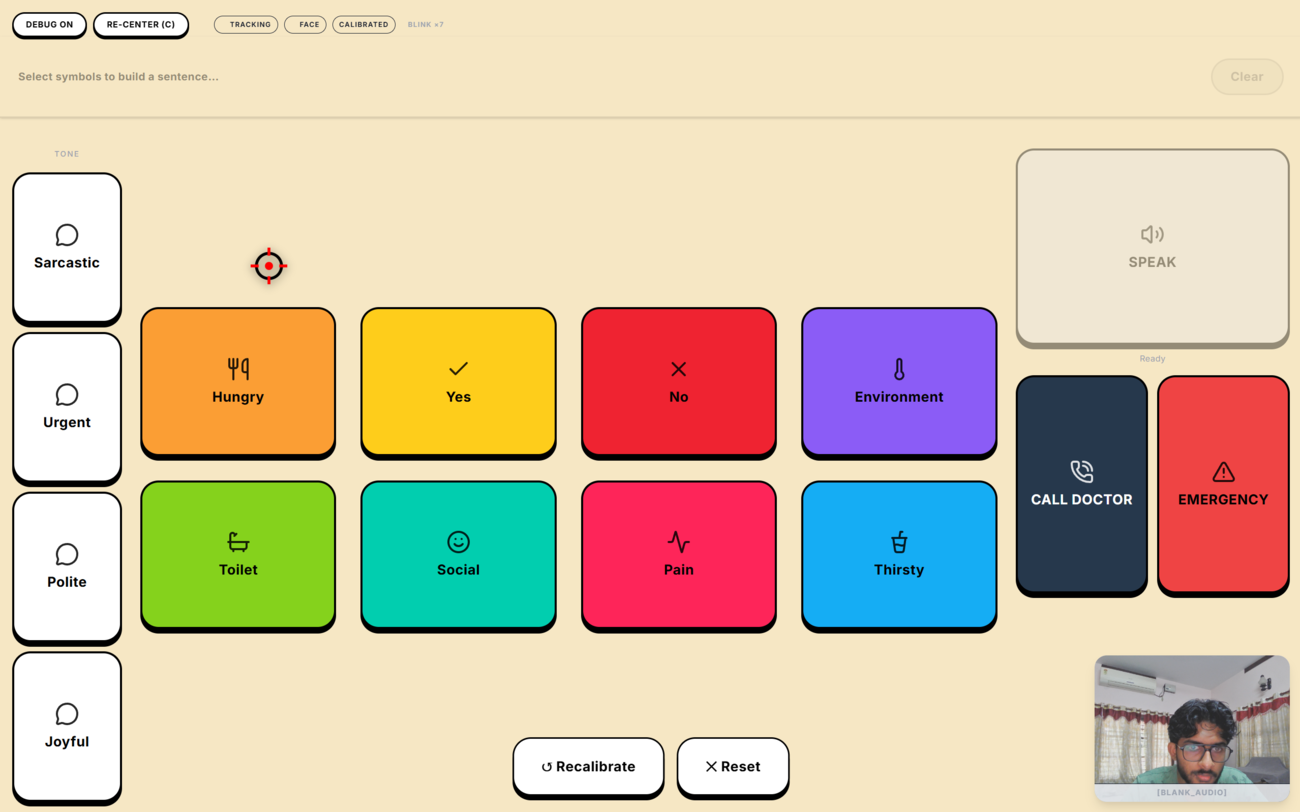
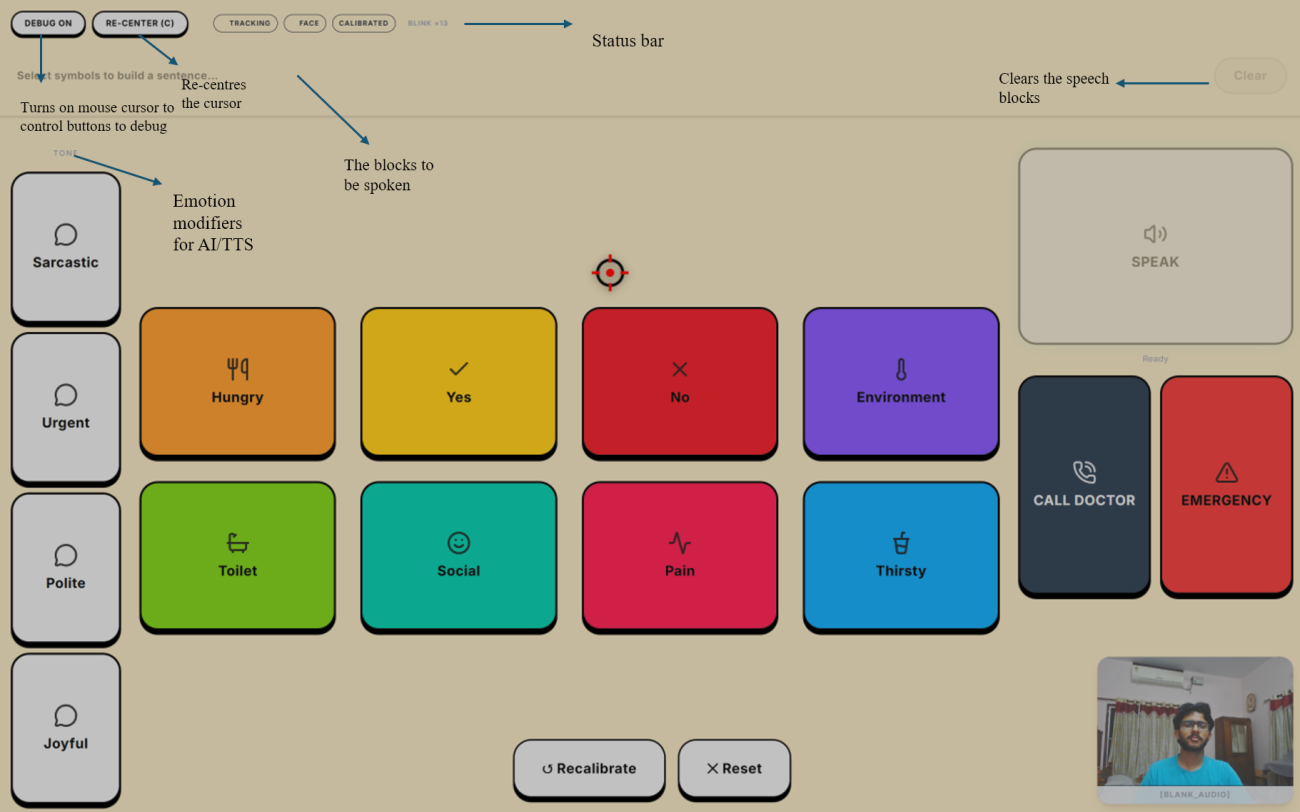
Annotated breakdown of the Iris interface, highlighting the AI tone modifiers, system controls, and speech assembly blocks.
-
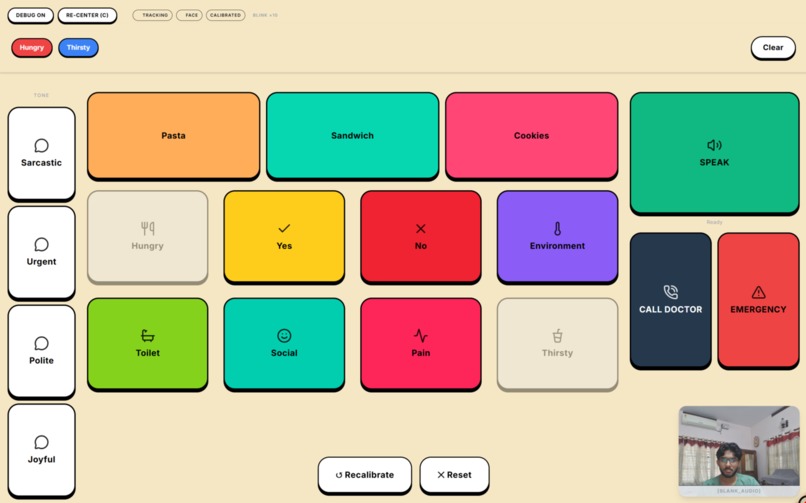
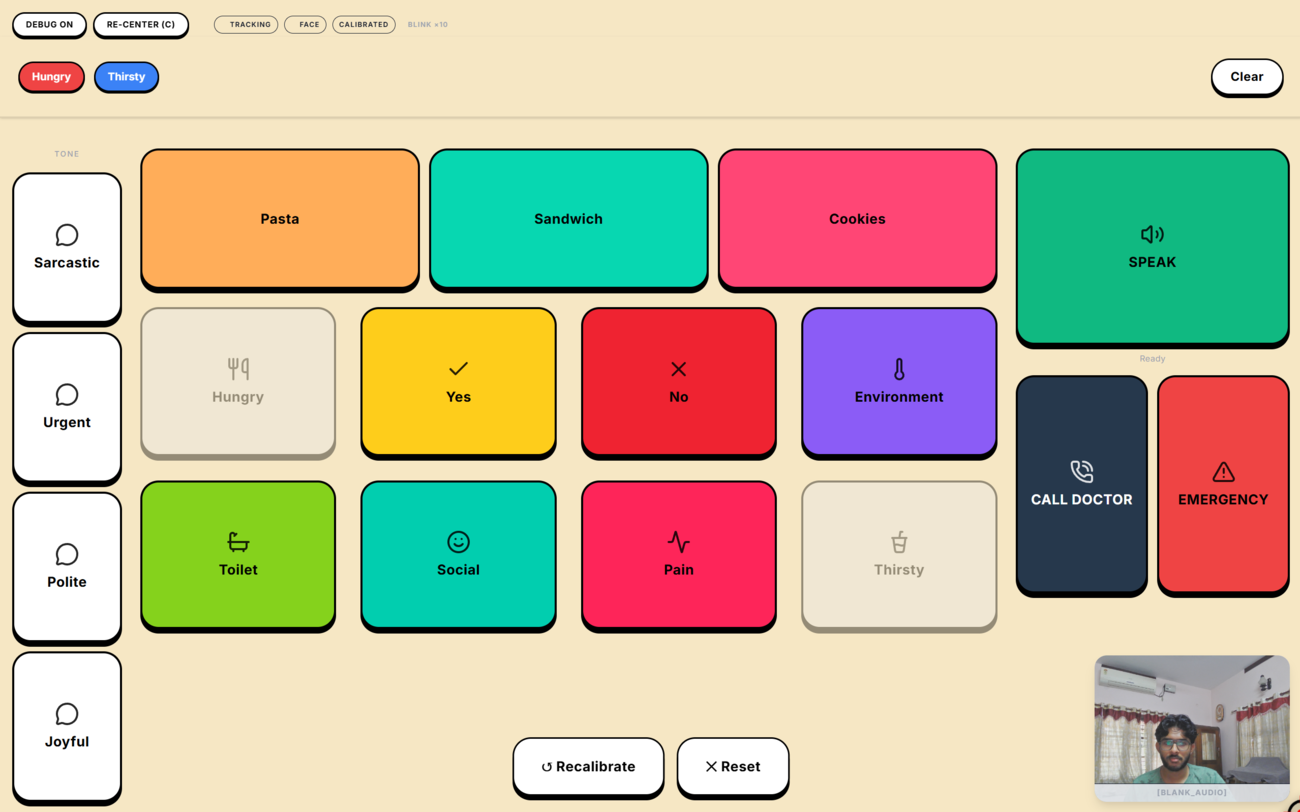
The main Fitts's Law AAC interface. The local AI predicts context-aware options based on the patient's selected "Hungry" keyword.
-
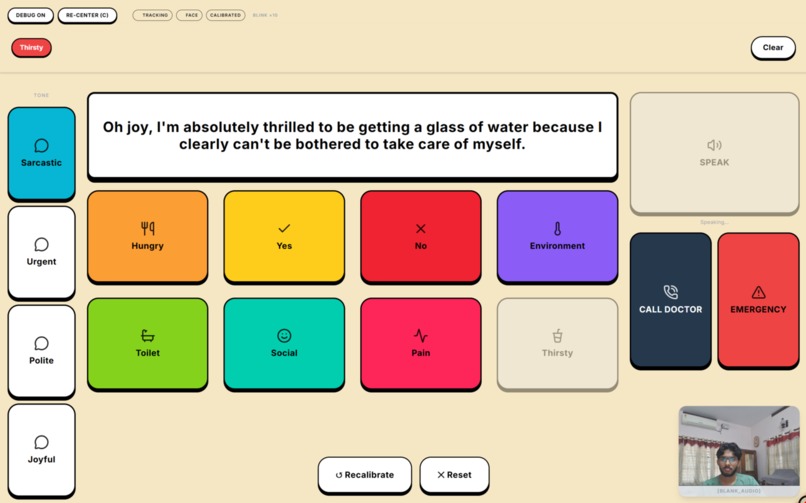
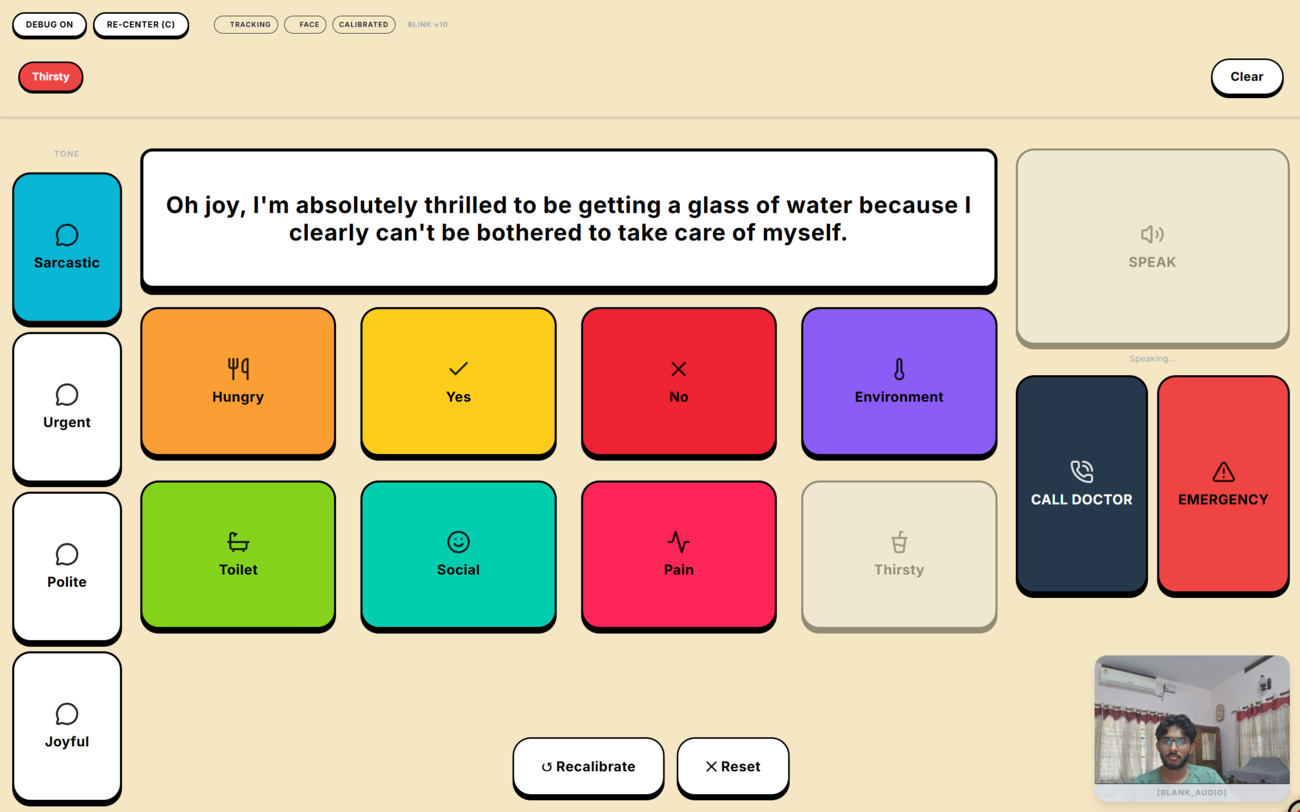
Local WebGPU LLM inference: the 1B model dynamically generates a tone-specific sentence from a keyword, routed to the ONNX TTS worker.
-

The lightweight browser portal for doctors or relatives to monitor session states and initiate secure telemedicine calls to their patients.
-

The patient-side telemedicine interface initiating a secure, peer-to-peer video session using the LiveKit WebRTC infrastructure.
-

The incoming WebRTC telemedicine call modal, allowing seamless and secure connection negotiation with medical professionals.
-
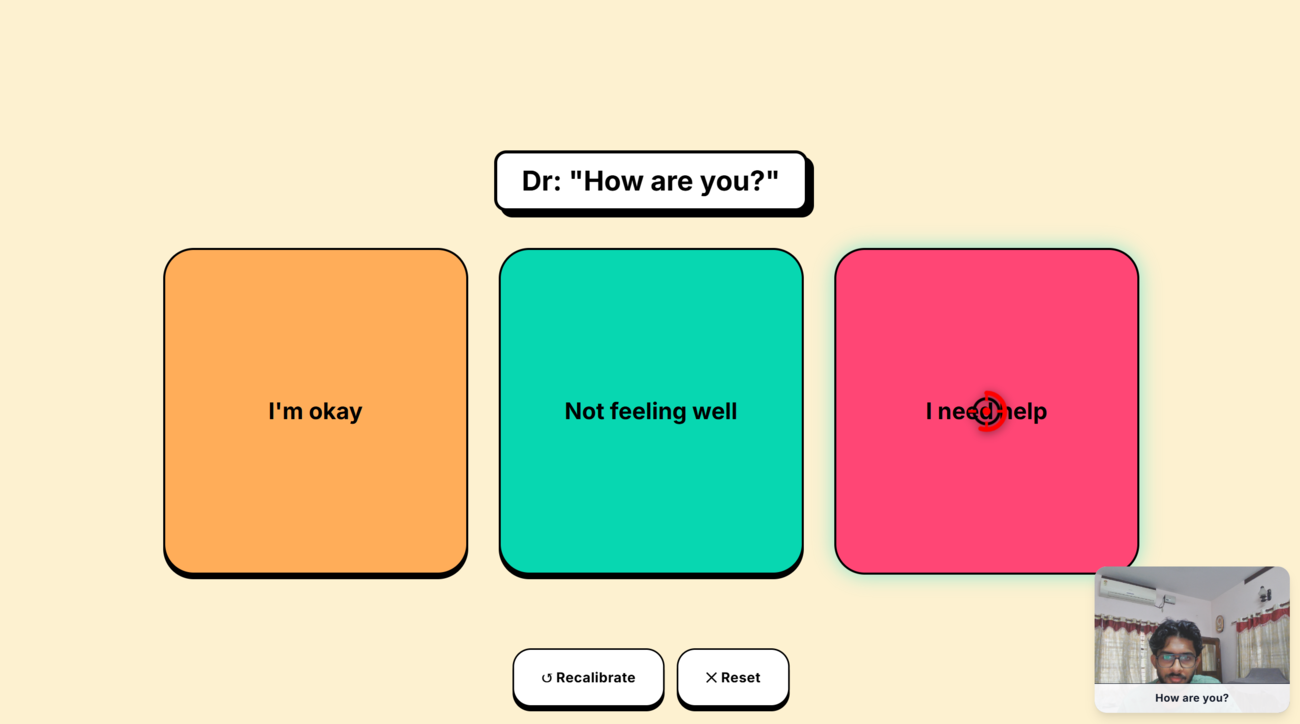
Predictive AI overlay: a Python agent transcribes live speech, while the local LLM instantly generates contextual response targets.
-
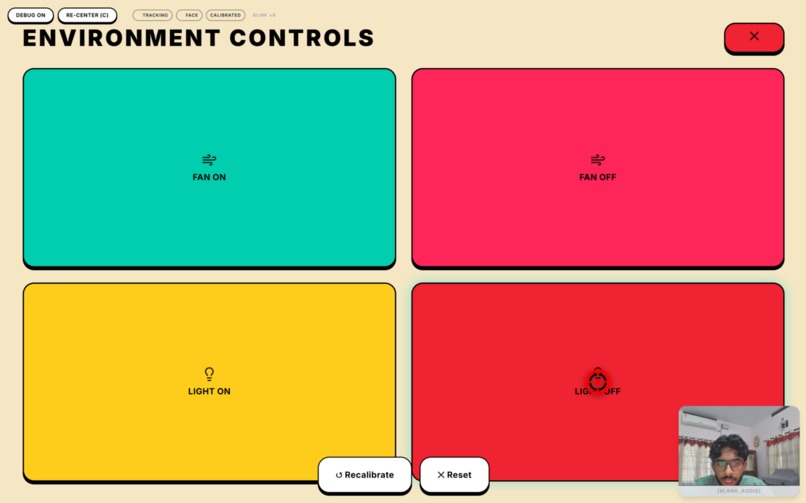
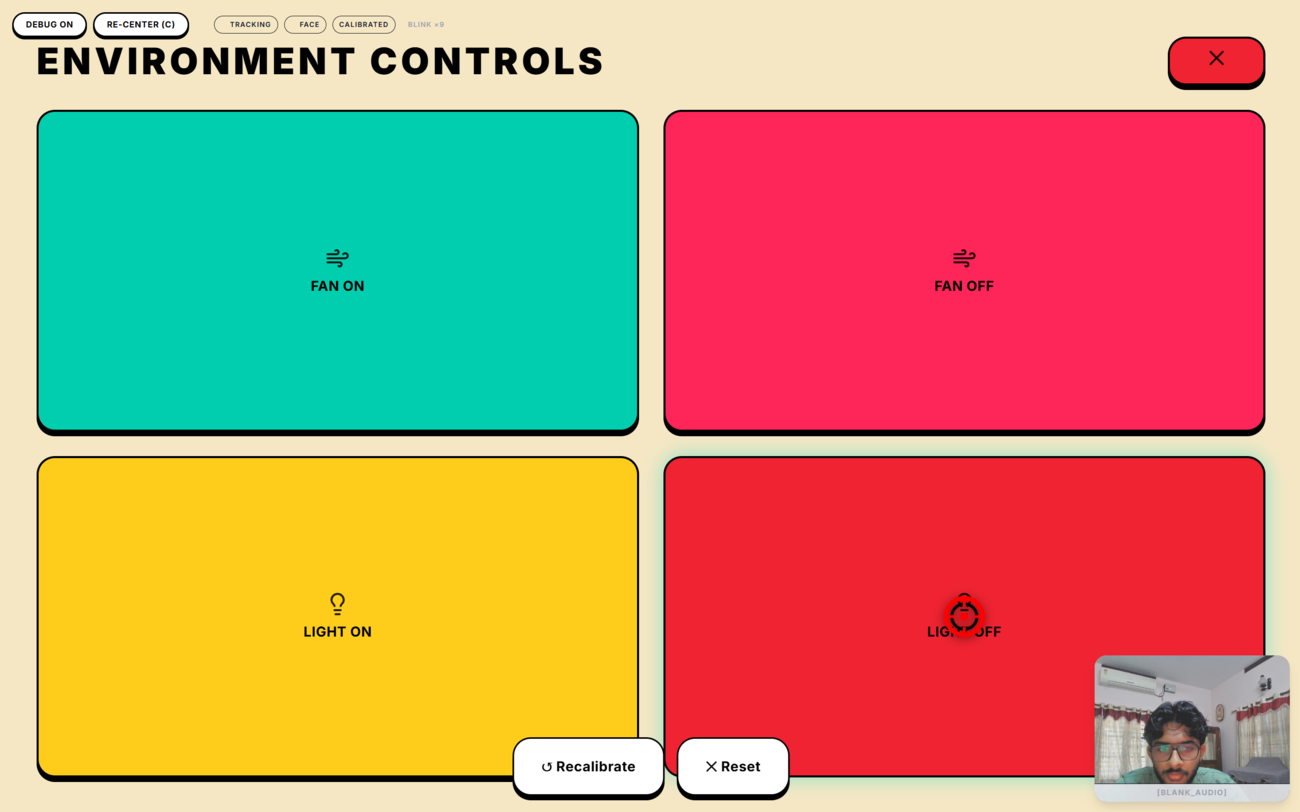
IoT Control dashboard. Gaze selections publish instant MQTT payloads to a Mosquitto broker to toggle physical relays like fans and lights.
-

Project Iris IoT hardware: The Seeed Wio Terminal successfully receives the local MQTT payload to activate the fan display.
-
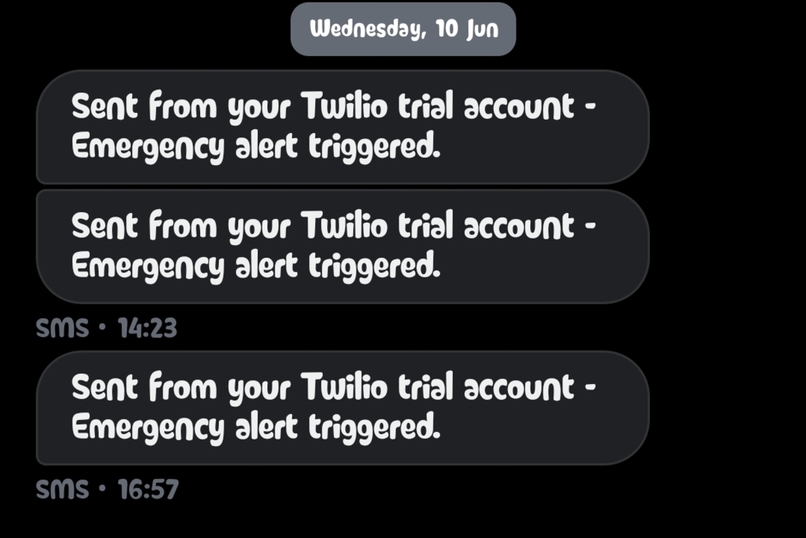
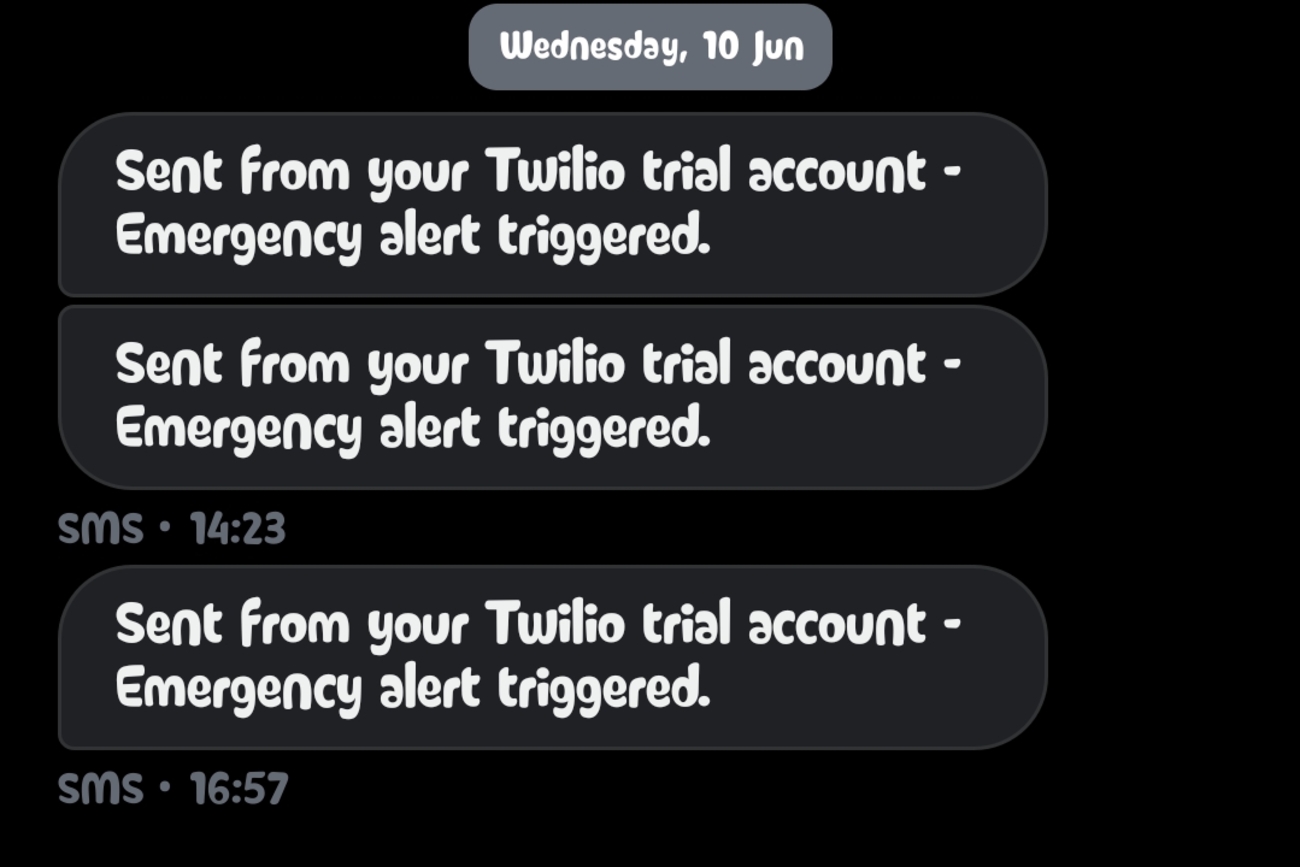
Real-world SMS delivery via Twilio, triggered instantly to a caregiver's phone when the patient gazes at the "EMERGENCY" node.








Inspiration
My great grandmother spent the final years of her life paralyzed, trapped in a body that could no longer execute the commands of her mind. Her only remaining avenues of communication were the subtle movements of her eyes and infinitesimal gestures of her head. When her grandchildren and great grandchildren walked into the room, you could see a profound, radiant happiness swimming in her eyes, yet expressing that joy---or even basic physical needs like "I am cold"---was an agonizingly slow and frustrating process for her. She ultimately passed away in this condition, locked in silence, because coming from a middle-class family in Kerala, India, we simply did not have access to advanced Augmentative and Alternative Communication (AAC) technology.
Witnessing that isolation fundamentally changed how I view technology. AAC technology is designed to replace or supplement lost speech using residual body movements or brain signals. However, the current market is prohibitively expensive and largely inaccessible to families like mine. I wanted to build a system that could give people like my grandmother their voice back instantly, privately, and at absolutely zero cost. Project Iris was born from the conviction that the basic human right to communicate should never be gated by wealth or geographic location.
The Market Landscape & The Zero-Cost Advantage
AAC solutions are highly personalized depending on the user's specific motor capabilities and residual muscle control. However, looking at the current market competitors reveals a massive financial barrier for everyday families:
- Eye-Tracking Systems: Devices from companies like Tobii Dynavox provide dedicated speech-generating devices (SGDs) and eye-gaze software, which are best for individuals who retain control of their eye muscles. However, these are incredibly expensive, with even pre-owned models routinely selling for thousands of dollars on secondary markets.
- Head-Tracking and Switch Access: For individuals who rely on subtle head movements or facial twitches, platforms from manufacturers like PRC-Saltillo allow users to navigate keyboards and generate synthetic speech. Their dedicated communication tablets carry a massive premium, with devices like the Accent 800 priced at $7,975 and the Accent 1000 at $8,290.
- Facial Recognition and Voice Banking: Software like Grid 3 by Smartbox merges multiple access methods into one interface for users retaining limited facial gestures. Yet, the software license alone typically costs between $600 and $900.
- Brain-Computer Interfaces (BCIs): For patients with severe locked-in paralysis, pioneers like Synchron are introducing implanted stents that translate neural activity into device control. While revolutionary, this relies on highly invasive procedures and is currently limited to clinical trials.
Project Iris disrupts this landscape by offering a zero-cost, entirely software-based alternative. It requires no specialized hardware, no $8,000 dedicated tablets, and no expensive software licenses---only a standard webcam and a web browser.
What it does
Project Iris: Edge AI AAC Platform is a fully accessible, zero-latency eye-tracking communication suite built specifically for patients with severe neurodegenerative diseases, locked-in syndrome, and late-stage ALS.
At its core, it translates a patient's eye gaze into a precise cursor, allowing them to navigate a custom UI to speak, control their physical room, and communicate with doctors. It does all of this by running a complete, state-of-the-art AI inference stack entirely client-side in the browser.
- Predictive AAC: Generates contextual, natural-sounding sentences based on the patient's selected keywords and the ambient conversation in the room.
- Conversational IoT Control: Allows the patient to physically alter their environment. If a patient uses their eyes to select "I am sweating," Iris instantly triggers physical hardware to turn on the room's fan.
- Secure Telemedicine: Integrates a WebRTC video portal for remote doctor consultations, complete with live dual-path Speech-to-Text (STT) transcription.
- Solving the "Midas Touch": We implemented an exclusive "Blink-to-Select" mechanism combined with intelligent cursor snapping and visual dwell rings. By monitoring the probability channels for left and right eye blinks, we distinguish between involuntary physiological blinks and deliberate commands, ensuring actions are only triggered intentionally.
- Adaptive UI Personalization: The communication grid uses a frequency-reranking system that tracks word usage and persists it to local storage. This powers a "Re-Optimize Layout" feature that automatically shifts the patient's most frequently used words to the optimal Fitts's Law positions (center and corners).
How I built it
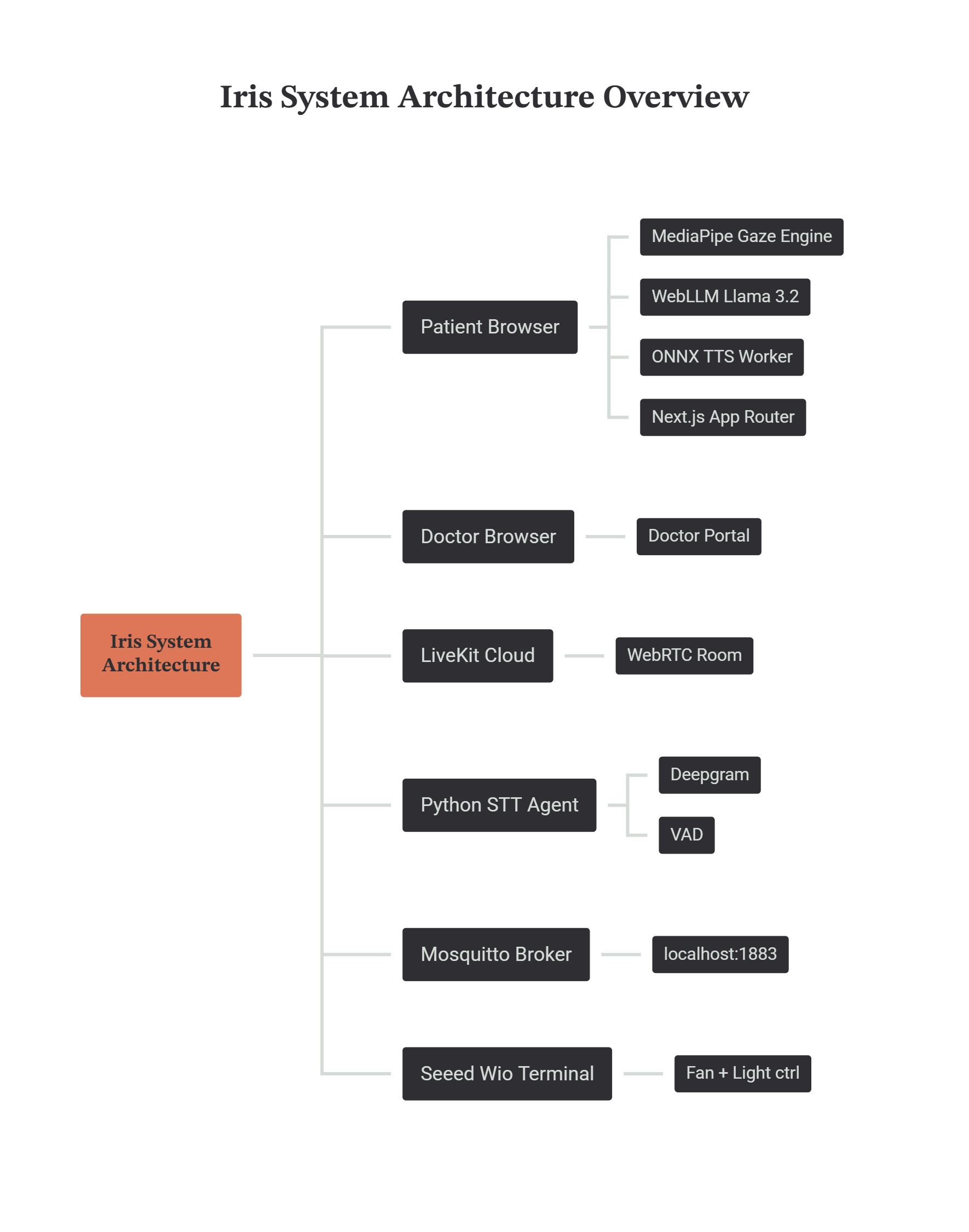 Iris is a deeply integrated distributed system that bridges the gap between browser-based Edge AI and physical IoT hardware. We built this with a fanatical dedication to keeping the processing strictly local.
Iris is a deeply integrated distributed system that bridges the gap between browser-based Edge AI and physical IoT hardware. We built this with a fanatical dedication to keeping the processing strictly local.
- The Vision Engine & Head Decoupling (CPU-Bound): We utilize MediaPipe FaceLandmarker compiled to WebAssembly. On every frame, it computes a 478-point 3D facial mesh. To allow patients to move their heads freely without displacing the cursor, we calculate the iris position relative to the eye socket bounds. We measure the total width of the eye socket (X_outer to X_inner) and calculate the iris's relative horizontal position as a ratio between 0.0 and 1.0. This guarantees the cursor only moves when the eyes rotate, completely ignoring physical head translation. We deliberately pinned this workload to the CPU to reserve all available GPU VRAM for the language model.
- Polynomial Regression Calibration: To map these raw 0-to-1 facial ratios to the patient's actual screen resolution, we run a calibration phase utilizing a Linear Least-Squares Regression (Affine Transform). As the patient looks at calibration targets, the system calculates the optimal coordinate coefficients using the Normal Equations to solve a 3x3 matrix via Gaussian Elimination. This bends the raw data to perfectly match the physical curvature of the patient's eyeball and their specific monitor placement.
- The Local Brain (WebGPU): The predictive text engine is powered by MLC AI WebLLM running a local 1.24-billion parameter Llama 3.2 model. Quantized to 4-bit weights with float16 activations, its VRAM footprint is reduced to roughly 700MB. It runs locally via WebGPU without ever sending a byte of patient thought data to the cloud.
- Dual-Path Speech-To-Text (STT) Architecture: We engineered two distinct STT pipelines. During idle use, the
useWhisperMichook captures room audio via anAudioContextand processes it through a dedicated Web Worker using a WASM-compiled Whisper Tiny model (Transformers.js). This feeds directly intopredictFromAmbientContext, generating context-aware UI buttons based on the room's physical conversations even without an active call. Conversely, during active telemedicine calls, a Python agent utilizes Deepgram to process the doctor's audio with extreme accuracy, seamlessly routing transcripts to the local LLM. - Local Text-to-Speech (TTS) Processing: To maintain strict privacy and zero-latency feedback, patient responses are synthesized entirely locally using an ONNX-based Kokoro Web Worker for TTS, ensuring no voice data leaves the browser.
- The IoT Hardware Layer (Local MQTT): We set up a local Eclipse Mosquitto broker. The frontend Next.js API pushes JSON payloads to this broker. A Seeed Wio Terminal microcontroller running custom C++ firmware intercepts these MQTT packets over the local Wi-Fi and triggers physical GPIO relays to control the room's lighting and fans.
- State Management & Concurrency Safety: Bridging asynchronous events from WebRTC, WebGPU, and Web Workers required a robust global state solution. We utilized Zustand to manage state outside the React render cycle, preventing catastrophic re-renders. To protect the WebGPU inference engine, we also implemented a
requestLockpromise chain that serializes LLM calls, wrapped in an 8-second timeout to prevent queue blocking.
The Two Necessary Exceptions: We architected Iris to be an offline-first, local fortress. However, two specific features structurally required external routing, for which we had no local alternative:
- LiveKit (Telemedicine): To allow remote doctors to connect with patients securely, we had to use LiveKit's WebRTC infrastructure. Peer-to-peer video streaming across different networks and firewalls mathematically requires a cloud-based STUN/TURN traversal server to negotiate the connection.
- Twilio (Emergency Alerts): To allow a paralyzed patient to send an emergency SMS to a caregiver's phone, we utilized the Twilio API. Establishing a direct SMS cellular handshake from a local browser is fundamentally impossible without plugging in a dedicated hardware GSM gateway.
Challenges we ran into
1. Micro-Saccades and "Downward Spike" Blinking
Raw pupil coordinates suffer from micro-saccades (rapid, involuntary eye tremors) and "downward spikes" caused by the eyelid pushing the iris during a blink. This made selecting UI buttons impossible. To fix the jitter, we implemented an Exponential Moving Average (EMA) Filter (α = 0.12). This acts as a mathematical shock-absorber, where the smoothed cursor is 12% the new raw data and 88% its previous position, producing a buttery smooth glide. To fix the blink spikes, we continuously monitor six eyelid points to calculate the Eye Aspect Ratio (EAR):
$$\text{EAR} = \frac{|P_2 - P_6| + |P_3 - P_5|}{2 \cdot |P_1 - P_4|}$$
If the EAR drops below our threshold, the system recognizes a blink and instantly freezes the cursor's X/Y coordinates until the eye reopens, entirely eliminating downward drag.
2. Hardware Memory Allocation Crashes (SAM-BA Errors)
While programming the Wio Terminal's IoT UI, we initially requested a large memory canvas to animate a spinning fan for visual feedback. Because the Wi-Fi library consumes almost all of the board's 192KB of RAM, this caused a fatal panic and froze the microcontroller. We had to rewrite the rendering logic into a non-blocking state machine that draws and erases trigonometric triangles directly to the physical screen, bypassing RAM entirely.
3. LLM Hallucinations in Hardware Control
Relying on a 1B parameter LLM to format strict JSON for hardware control proved unstable. We solved this by implementing a two-stage hybrid pipeline: a lightning-fast deterministic layer scans incoming transcripts for actionable environmental vocabulary (e.g., "hot", "dark") and routes the intent before allowing the LLM to generate the creative conversational response.
Accomplishments that we're proud of
- Zero-Latency Independence: We successfully achieved a sub-200ms end-to-end response loop completely within the browser. The patient blinks, the local LLM evaluates the context, and the physical fan turns on almost instantly.
- Fitts's Law UI: We engineered a Neobrutalist UI strictly adhering to Fitts's Law, calculating the index of difficulty for gaze targeting:
$$ID = \log_2 \left( \frac{D}{W} + 1 \right)$$
By maximizing target width W and minimizing distance D with massive 80px dead-zones, we guaranteed that gaze tremor never results in an accidental misclick.
- Edge Compute Prowess: We managed to concurrently run computer vision, Large Language Models, and audio synthesis in a single web browser without crashing the hardware.
- Solving the "Midas Touch" Problem: We successfully distinguished between involuntary physiological blinking and deliberate commands by monitoring
eyeBlinkLeftandeyeBlinkRightprobabilities. Coupling this with intelligent cursor snapping guarantees zero accidental misclicks. - Progressive Interface Personalization: Implementing a localized frequency-reranking system that dynamically re-optimizes the AAC grid layout based on the patient's unique vocabulary over time.
What we learned
We learned that the modern web browser has effectively become its own operating system. Technologies like WebGPU and WebAssembly have completely democratized high-performance computing, proving that you no longer need a massive cloud computing budget to build life-changing AI tools.
We also learned a profound lesson in empathetic design. When building for users with severe motor degradation, flashy animations and complex menus are active barriers. High contrast, massive targets, and deterministic reliability are what actually restore dignity and independence.
What's next for Project Iris: Edge AI AAC Platform
Ultimately, Project Iris is an initial proof of concept with immense room to grow. While we are proud of the zero-latency foundation we have built, here is our roadmap for fully realizing its potential:
- Achieving True 100% Offline Autonomy: Our goal was an API-free ecosystem, but WebRTC telemedicine and Twilio SMS required cloud fallbacks. We plan to sever these final dependencies by integrating physical GSM hardware for texting and exploring localized mesh networking to achieve a genuinely sovereign, offline-first architecture.
- Universal Smart Home Integration: We will transition from our Wio Terminal demo to bridging our local MQTT broker directly with consumer ecosystems like Home Assistant and Matter. This will allow patients to control off-the-shelf smart plugs out-of-the-box, saving caregivers from wiring custom microcontrollers.
- Domain-Specific AAC LLMs: We plan to fine-tune a heavily quantized LLM trained exclusively on patient-caregiver dialogue. Narrowing the focus will drastically reduce the VRAM footprint, allowing Iris to run on older, entry-level bedside tablets.
- Multilingual Accessibility: To ensure global accessibility, we will integrate regional languages into our local STT and TTS pipelines so patients can communicate naturally in their native tongues without language barriers.


Log in or sign up for Devpost to join the conversation.