



Inspiration
During natural disasters, governments and first-response organizations such as the Red Cross often struggle to predict which areas will be hit the hardest. We used historical storm and census data alongside the IBM Watson Machine Learning to model impacts on a region based on socioeconomic and geographic factors.
What it does
Our predictions can then be utilized by first responders, government organizations, and the Red Cross to better prioritize and allocate resources immediately following a disaster. We hope to eventually implement this on a more granular scale so that natural disaster relief can be given in a priority-order of need.
How we built it
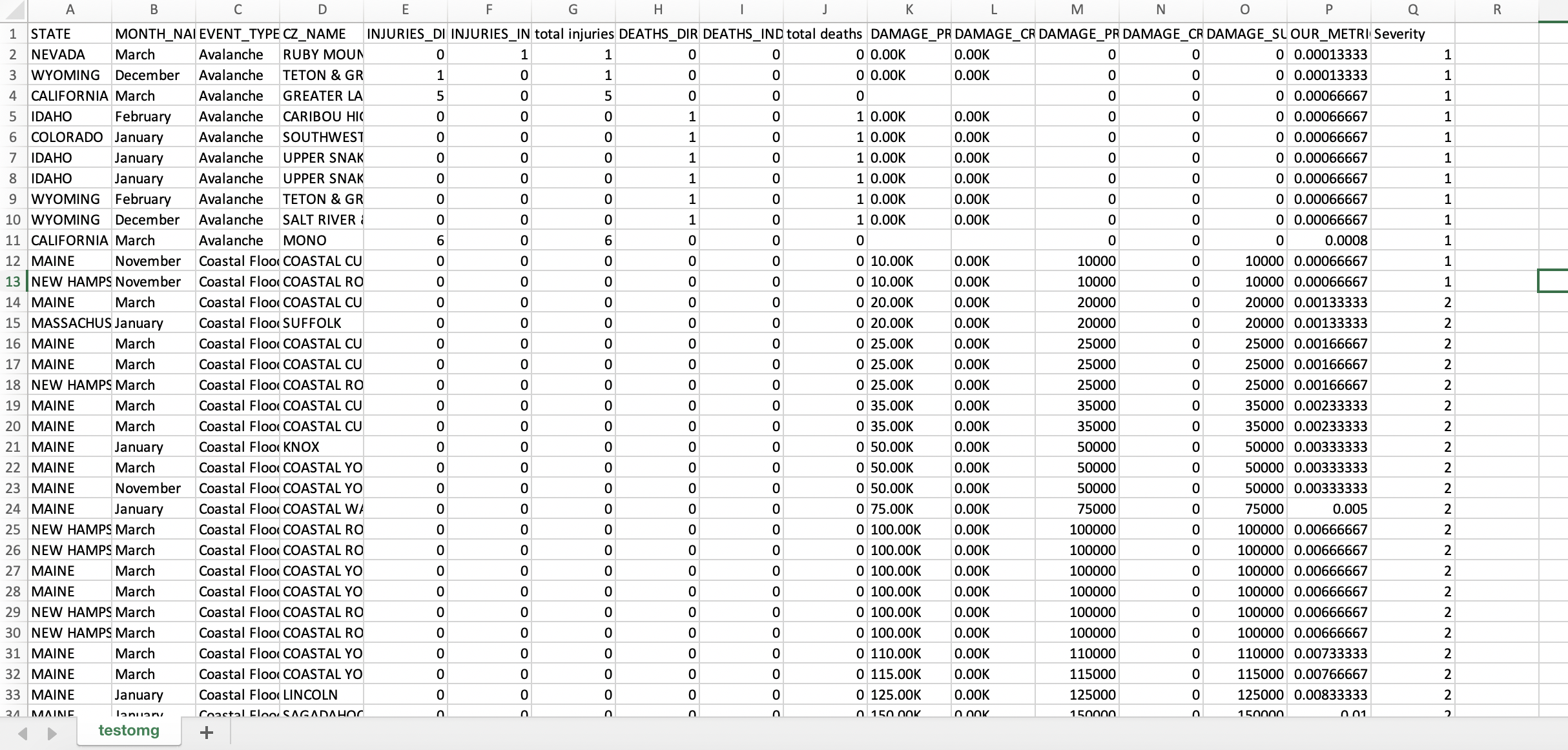
We used historical data (60,000+ data entries) of natural disasters from the NWS that resulted in deaths, injuries, property damage, and/or crop damage. We combined this historical data into a weighted average using a formula that weights deaths, injuries, and monetary damages appropriately. We then used the Python Pandas library to map these weighted averages into a severity scale of 1-10, with 1 being minor damage and 10 being maximum damage. All of this data was broken up by county to allow for granular analysis. Once we had our data in the appropriate format, we used the IBM Watson Machine Learning to create a predictive model that would allow users to estimate the severity of a natural disaster in a US state of their choice during a specified month of the year. Our program is hosted on a JavaScript platform with data analysis and plots based in Python. What you see is a heat map of the state you chose that is color coded by county based on each county’s computed severity level based on our predictive model.
Challenges we ran into
We couldn't upload two separate datasets to AutoAI, so we couldn't fully implement our census socioeconomic data alongside our historical damage data. We also spent a lot of time coming up with a metric formula that accurately described damage from disasters. Finally, we had difficulties connecting our JavaScript to AutoAI.
Accomplishments that we're proud of
We are proud of coming up with our metric formula, learning to clean data, training our predictive AI model successfully, being flexible with the technologies we used, learning new technical skills like Watson AutoAI, shapefiles, and Pandas.
What we learned
We learned more about how IBM Watson AutoAI works with datasets to predict future data, better communication and collaboration skills, and how to integrate all of our technologies like Python, JS, IBM AutoAI, and our frontend website.
What's next for project hurricAIne
Next, we want to integrate historic median income data per county to find correlations between income and damage costs, due to factors like residents being unable to evacuate or having too few resources to rebuild. We also want to make more granular heat maps, and use more years of data in our predictive model. On a large scale, this could be expanded to include more types of disasters or weather events, and could be used by hospitals and grocery stores to better prepare their areas for certain disasters.



Log in or sign up for Devpost to join the conversation.