-
Logo
-
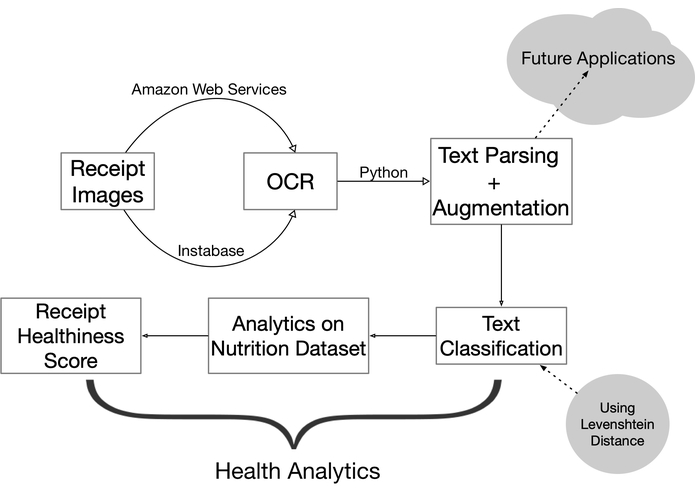
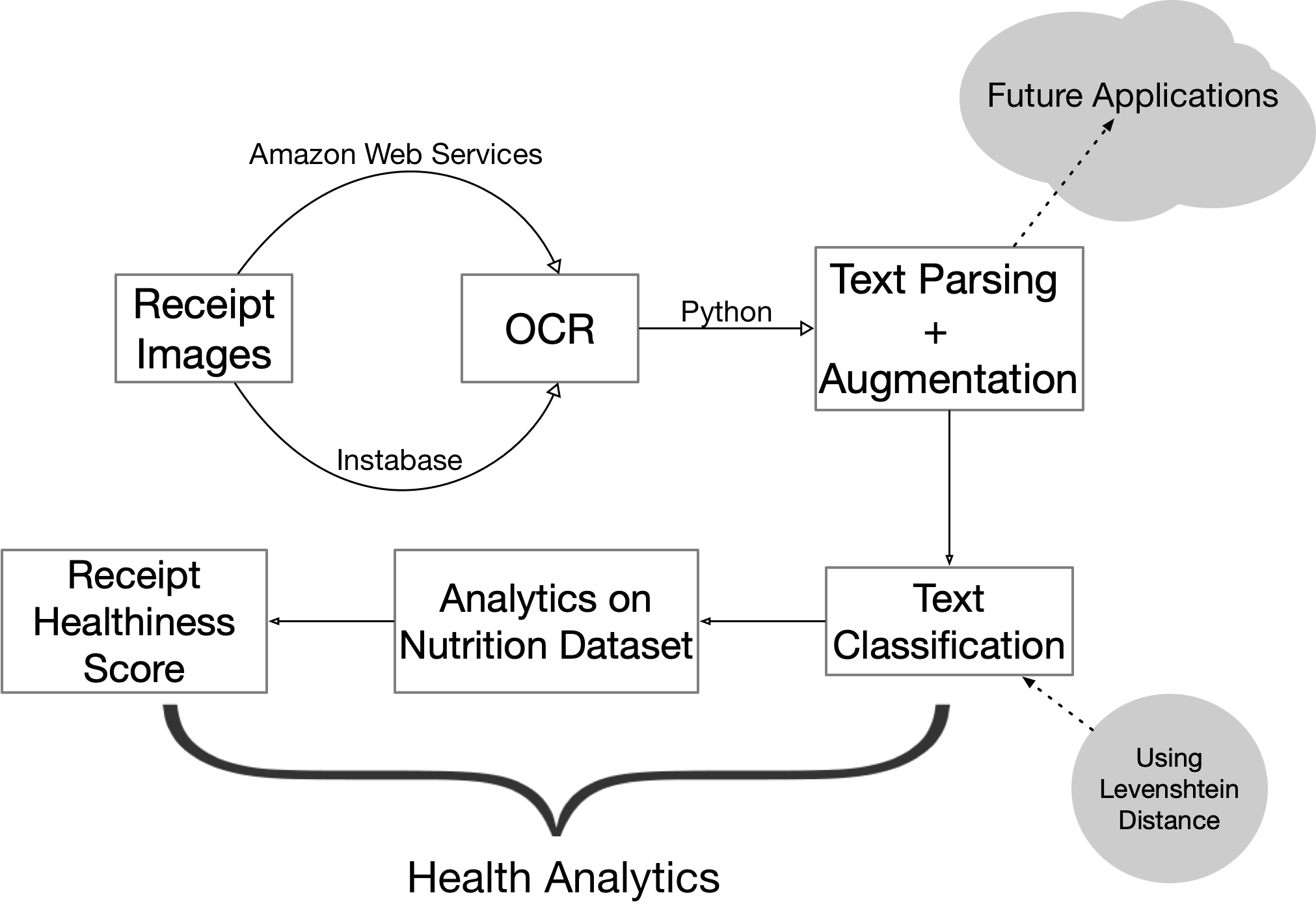
Flowchart of Project Horus' Analysis

Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification.





Log in or sign up for Devpost to join the conversation.