
Inspiration
Have you ever watched Messi and wondered what the game looks like from his point of view?
Project Horizon explores identity through perspective. In sports, a player’s identity is shaped not only by their actions, but by how they perceive the game: positioning, timing, awareness, and decision-making.
Reconstructing a first-person POV from third-person footage using novel machine learning techniques, we let viewers momentarily inhabit another identity.
What It Does
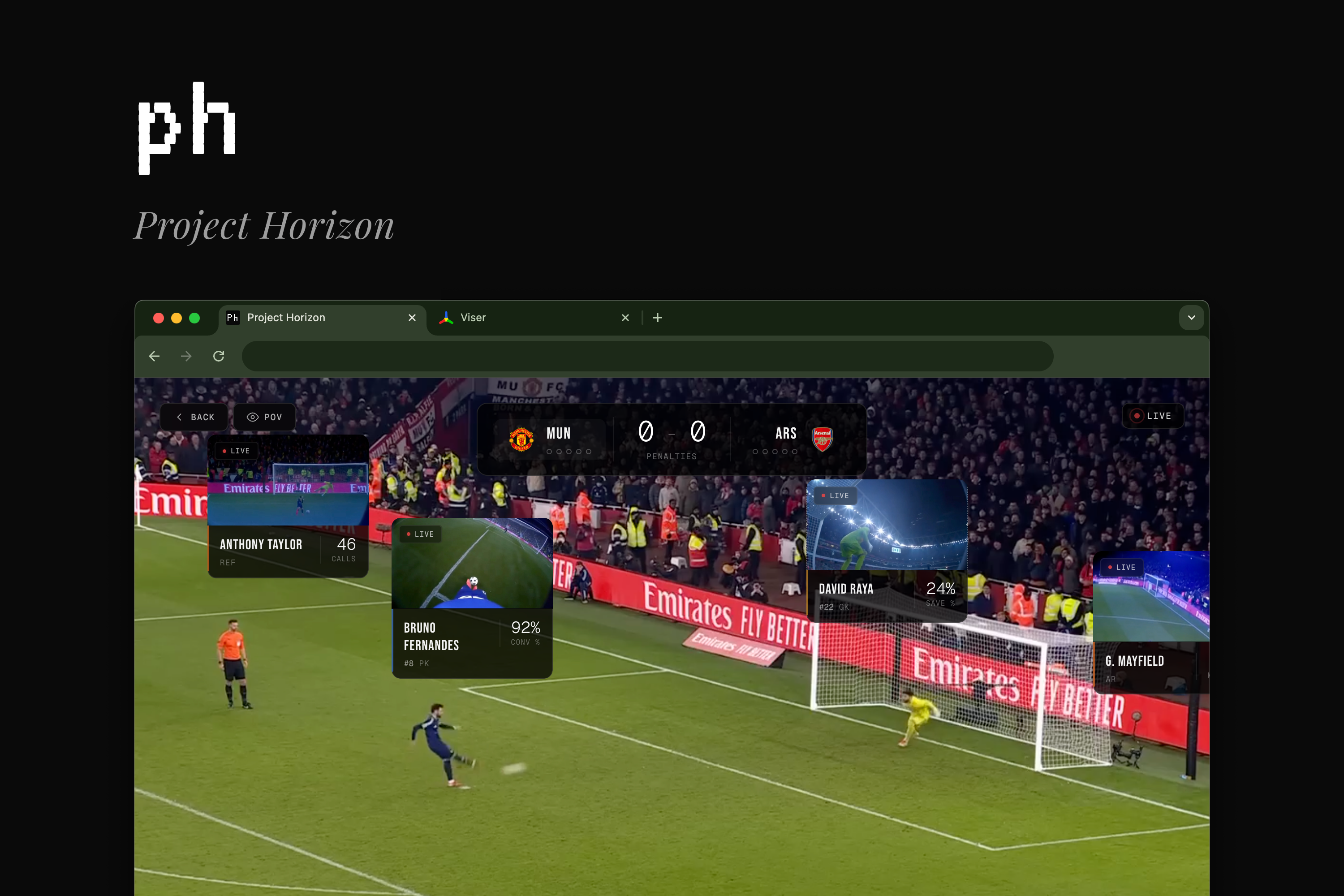
Project Horizon is an AI system that converts third-person videos into realistic first-person POV footage.
Users can select any player in a soccer video and experience the game exactly as that player would see it.
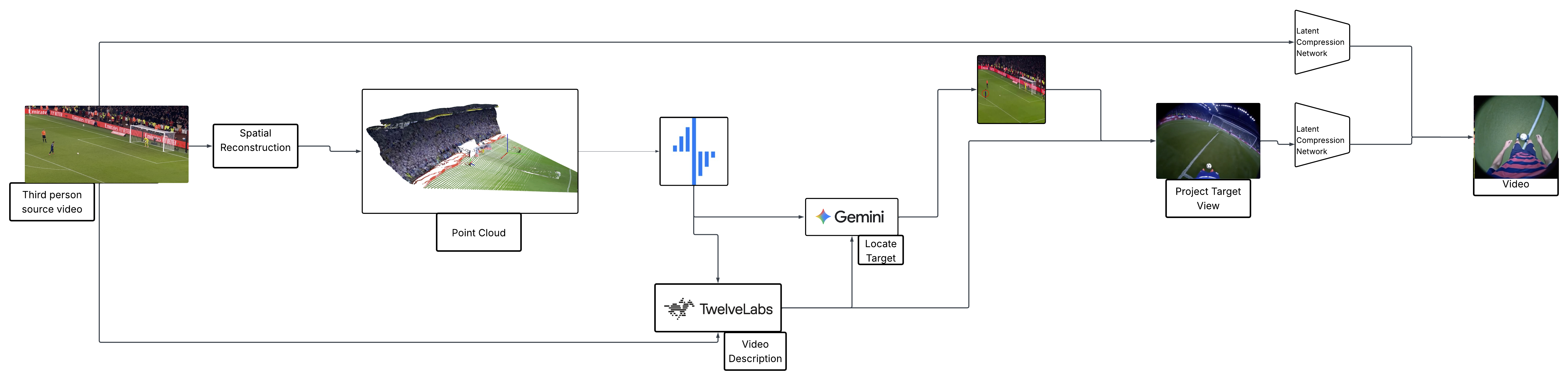
How We Built It
Input Video (Third-Person View)
We start with short third-person videos capturing target actions across diverse scenes.Scene Understanding (backboard.io)
Video frames are sent to backboard.io, which routes them to Gemini and TwelveLabs to generate structured scene descriptions and identify the target subject and intended first-person viewpoint.Depth-Based Prior Rendering
Each video is converted into depth maps using a monocular depth estimation model, producing a coarse 3D scene representation.
Using the detected subject location and camera geometry, we render a first person rough sketch video that encodes camera motion, spatial layout, and scene constraints.Model Training
This model was trained by fine-tuning the Wan 2.1 Image-to-Video (14B) diffusion model using LoRA on a curated dataset of paired third-person and first-person videos.
This training explicitly teaches the model to learn the transformation from third-person inputs to realistic first-person camera trajectories and visuals.Inference on H100 (Modal)
At inference time, the model is conditioned on the third-person video, the depth-based first-person prior, and the generated text prompt.
Inference runs on NVIDIA H100 GPUs via Modal, with cached base weights and LoRA adapters.
Challenges We Ran Into
- Securing access to H100 GPUs for both training and inference
- Extremely high compute costs and long-running jobs during experimentation
Accomplishments We’re Proud Of
- Successfully trained and ran inference on large-scale video diffusion models for the first time
- Built an end-to-end pipeline combining vision models, depth estimation, and generative video
What We Learned
- How to be resourceful under constraints
- After AWS rejected our compute requests, we discovered and leveraged Modal as a practical way to access H100 GPUs and unblock our project
What’s Next for Project Horizon
- Further fine-tuning for additional domains such as robotics and embodied AI
- Generating high-quality synthetic first-person video data for AI research labs
- Exploring partnerships and commercialization opportunities, including applications in data generation for humanoid robotics companies like Figure AI and Neo
Built With
- backboard
- gemini
- openai
- python
- react
- typescript







Log in or sign up for Devpost to join the conversation.