-
-
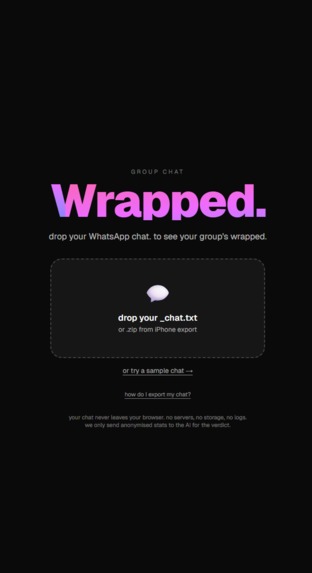
Landing Page
-
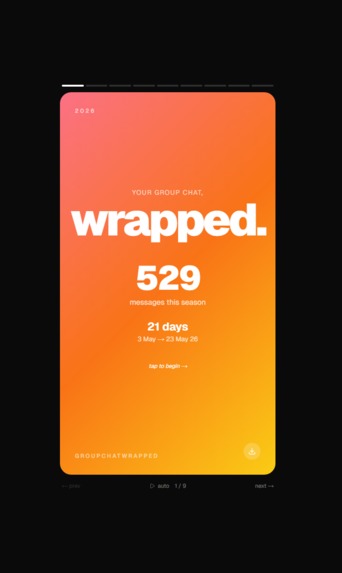
Example page #1
-
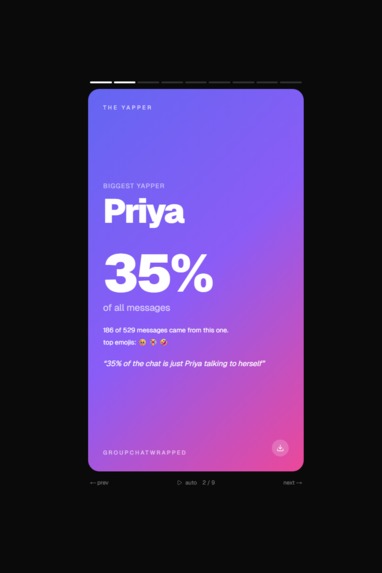
Example page #2
-
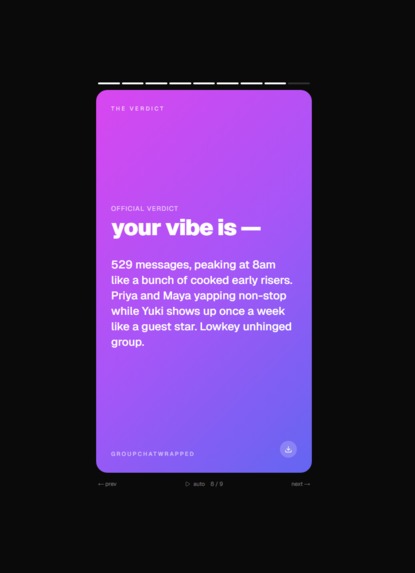
AI summary
-
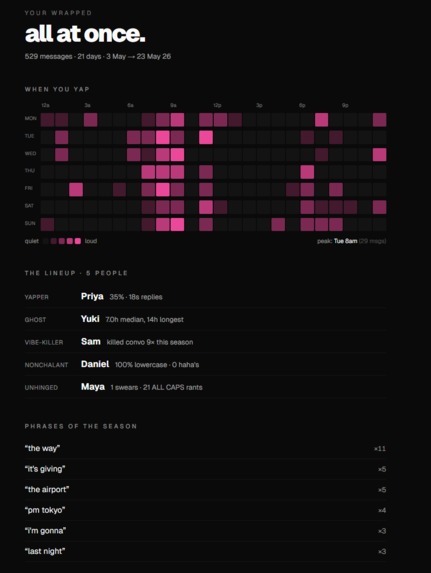
Detailed stats
Inspiration
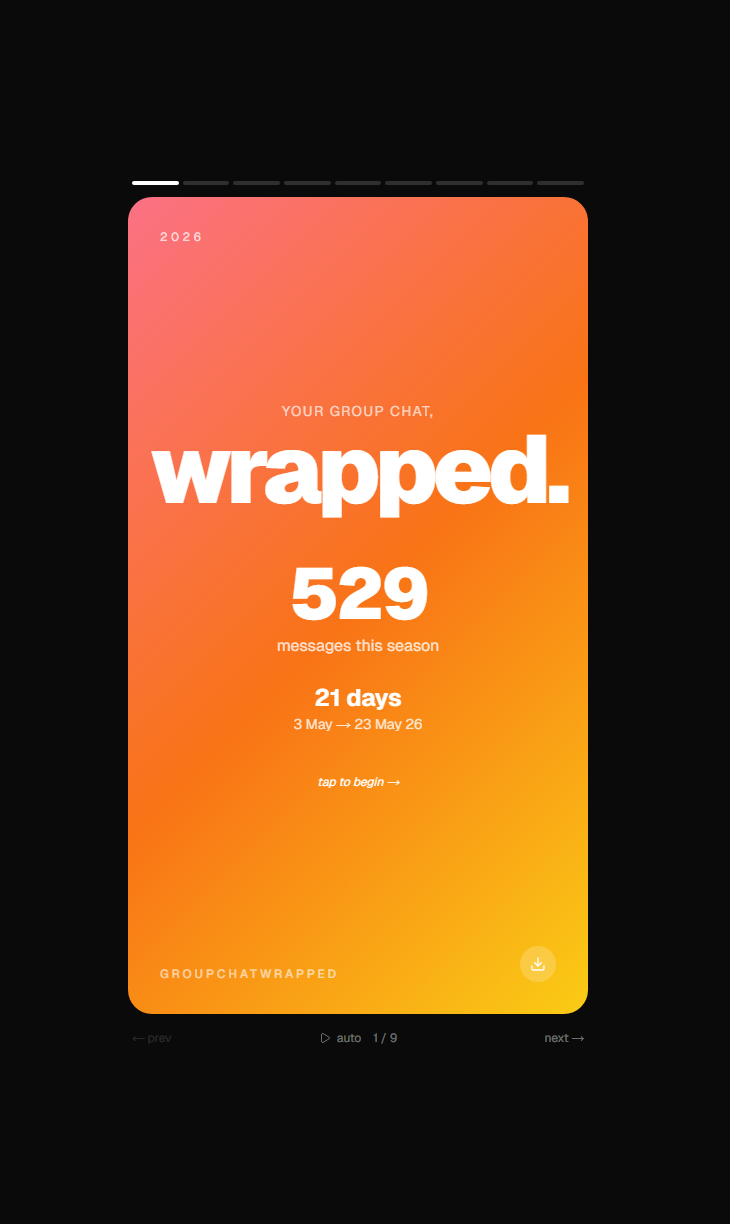
We started with one question: who in our group chat actually sends the most messages? Then we kept going. Who never replies? Who kills the vibe right before everyone goes quiet? Who's typing in ALL CAPS at 3am? We wanted Spotify Wrapped but for our group chat, and we wanted it funny enough that we'd actually forward it back to the chat instead of pretending it never happened.
The hackathon theme was "social trends" so we figured the smallest, most personal social trend is the one inside your own group chat. Everyone's got the yapper, the ghost, the one person who only sends "lol" and dips. Nobody's ever quantified it.
What it does
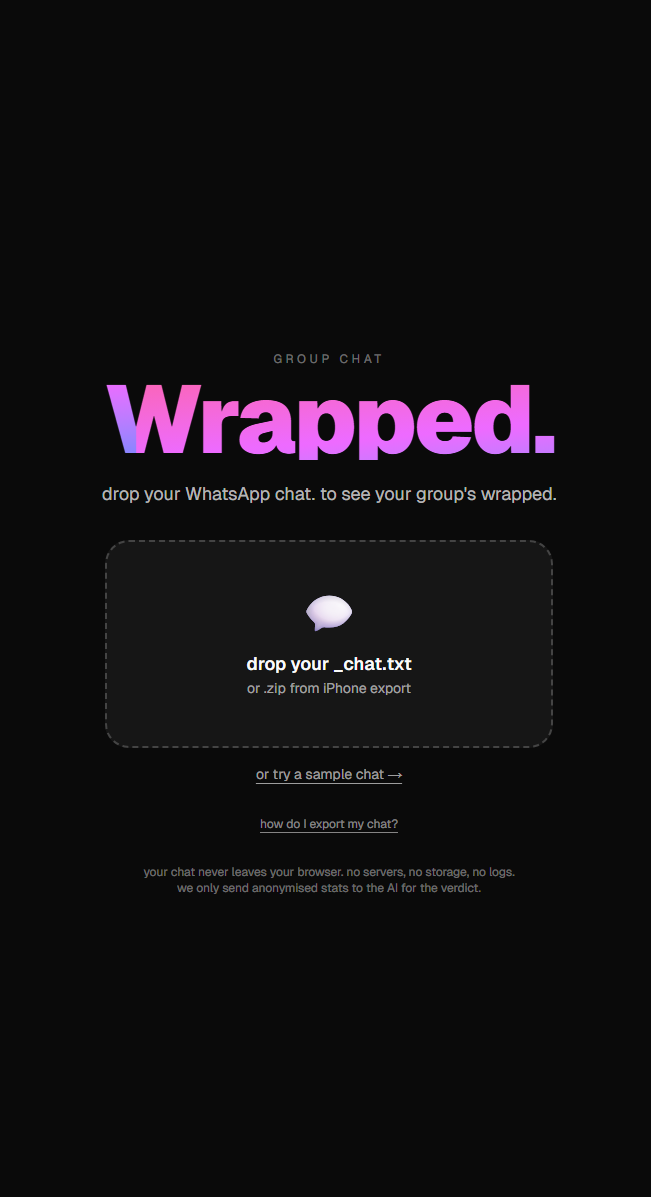
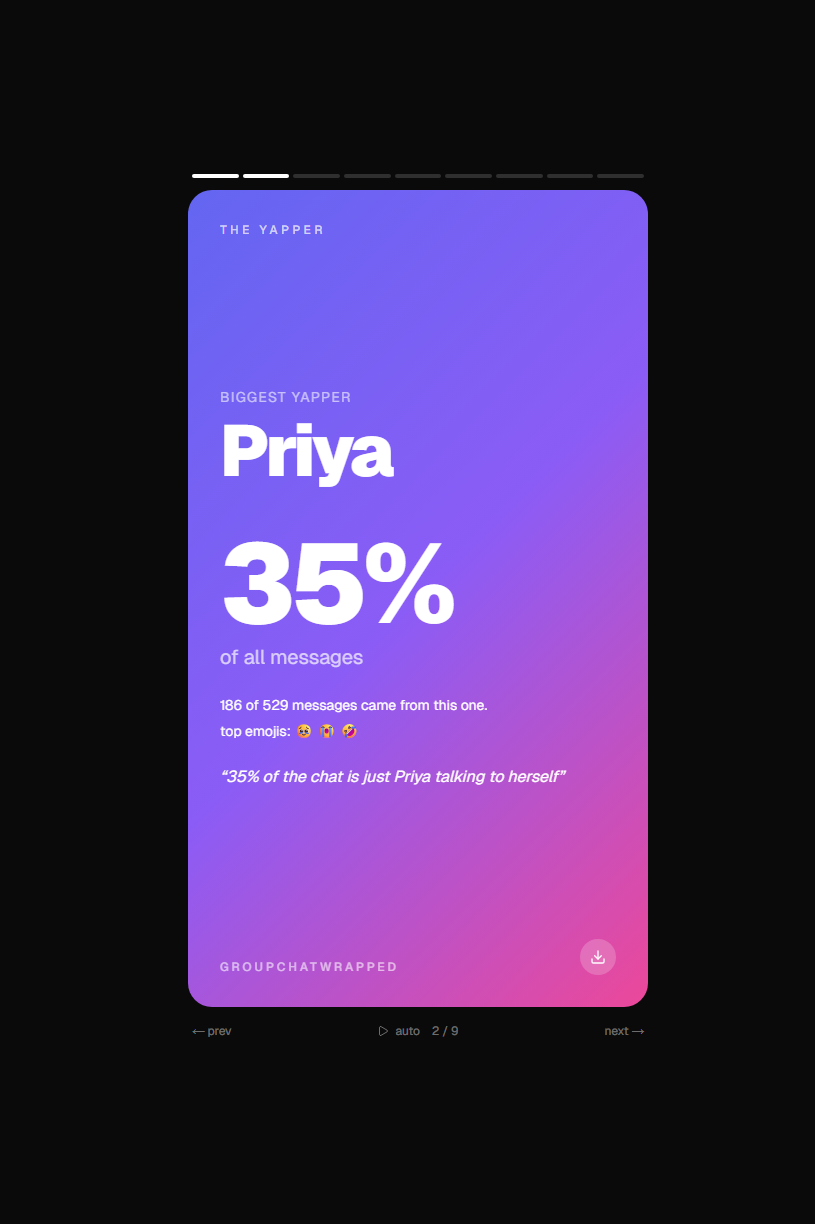
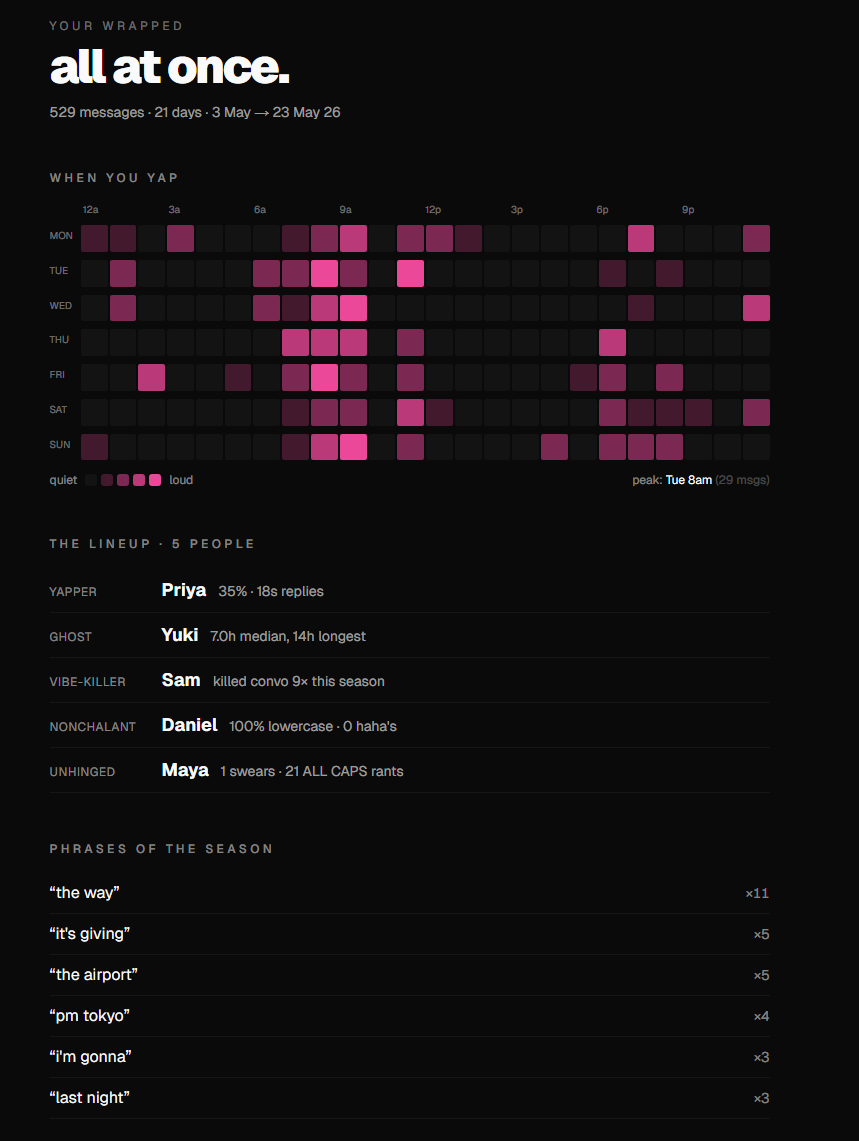
You drop your WhatsApp _chat.txt (or .zip if you're on iPhone) into the site and it gives you a 9-card swipe-through that roasts every personality in the chat. The Yapper is whoever sends the most messages. The Ghost has the slowest median reply. The Vibe Killer is whoever sends the message right before the chat goes quiet for 6+ hours, which is funnier than it sounds when you actually see who keeps doing it. The Nonchalant person uses no emojis, replies in all lowercase, and is somehow always right. The Most Unhinged tab counts swears and ALL CAPS rants. Phrase of the Season finds the running joke that the chat says way too much.
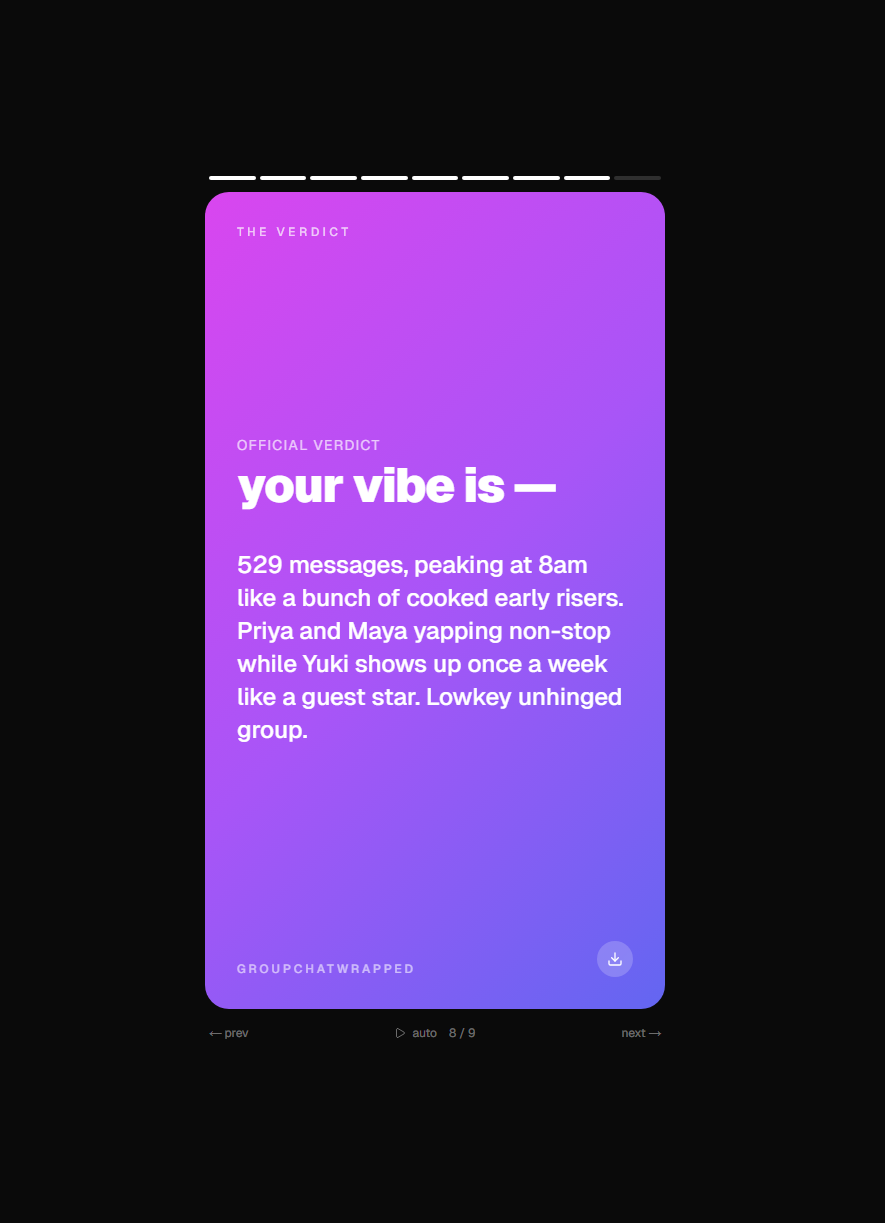
The last card is The Verdict, an AI roast written specifically about your stats. The first time we saw it spit out "3 messages in 21 days, you're not in the group you're a rumour" we knew the product was real. After that there's a final share card that generates a permalink anyone you forward it to will see identically.
We also built a scrollable summary page with a 24x7 activity heatmap that shows when your chat is actually awake. Every card screenshots cleanly so you can paste them back into the group chat and start the drama.
How we built it
The parser runs entirely in your browser. We didn't want anyone's chat logs sitting on a server we control, and being able to truthfully say "your chat never leaves your device" was the foundation we built everything on. Only anonymised stats (counts, latencies, percentages, never message content) get sent to our API for the AI to write the verdict text.
WhatsApp's export format is messier than you'd expect. iPhone and Android use different line structures, AU and US locales swap day/month order, multi-line messages need reconstruction, and system messages like "Messages and calls are end-to-end encrypted" have to be filtered out before they pollute the stats. We built a defensive parser that handles all of it.
For the AI verdicts we use the Anthropic API with a role-aware prompt. The same person can get two different roasts when they win two roles (someone might be both the yapper AND the most unhinged) without sounding repetitive. Getting the model to write in actual Gen Z register instead of essay-tone took an allowed-slang list and a banned-phrase list. No "fascinating", no "in conclusion", no "according to the data".
Permalinks use Vercel KV. The deck UX is Instagram-style: tap right to advance, tap left to go back, hold to pause autoplay. Each card screenshots to PNG via html-to-image. The whole thing is mobile-first because that's where group chats actually live.
Challenges we ran into
The biggest one was platform restrictions. We initially looked at iMessage, Discord, and Messenger but most don't let you export raw chat history without jumping through hoops. WhatsApp was the only one that worked cleanly on both iPhone and Android, so we narrowed our scope hard.
The parser was way more annoying than expected. There's no public spec for the WhatsApp export format, and it changes subtly depending on phone, OS version, and locale. We had to handle continuation lines (multi-line messages don't repeat the timestamp), random system messages mid-stream, and the fact that some chats use 12-hour time and some use 24-hour. The parser took longer than the actual UI to get right.
Prompt engineering for the AI verdicts was its own challenge. Default LLM output reads like a corporate analyst, which is exactly the opposite of what we wanted. We ended up writing a register guide into the prompt with allowed slang, banned phrases, and example tone, and re-rolling until the output sounded like a friend ribbing a friend.
We also hit a stable-permalinks bug late in the build. Shared links were re-generating new AI text on every visit, so the URL you sent your mate would show them a completely different verdict than the one you saw. We fixed it by caching the verdict alongside the stats in KV so the link is byte-identical for everyone.
Accomplishments that we're proud of
Zero raw messages ever leave the user's device. We didn't compromise on this even though it would have been easier to send the chat to a server and parse it there. The privacy claim is real and we can defend it.
The roasts are specific. They reference actual numbers from the chat (message counts, percentages, ghost durations) instead of generic filler. When we tested with our own real group chats the verdicts hit hard enough that we forwarded them back to the chats, which was kind of the whole point.
The activity heatmap surfaces moments you don't notice in a normal chat. Stuff like "your chat peaks at 3am every Saturday" or "Tuesday afternoons are completely dead" shows up in a single image and gets people calling each other out.
We shipped 9 cards, a summary page, permalink sharing, the WhatsApp export guide modal, and the live AI integration in 36 hours. Mobile-first, deployed to a real domain, tested on actual chats.
What we learned
Designing for the screenshot is different from designing for the user. Every gradient, font weight, and corner radius decision came back to one question: would someone screenshot this and forward it. A card that looks fine in your hand but bad in a forwarded image is a failed card.
Prompt tone is harder than prompt accuracy. Telling an LLM "write a roast" is easy. Telling it "write a roast that doesn't sound like a corporate analyst" is much harder and needed a banned-phrase list, register examples, and several re-rolls before it actually landed.
Building the privacy moat client-side gave us a side benefit: infrastructure costs don't scale with chat size. We can handle a 50,000-message chat the same way we handle a 200-message one because all the heavy work happens in the browser.
What's next for Group Chat Wrapped
We want to support more platforms. Messenger, Instagram DMs, Discord, iMessage, Telegram. Each has its own export format we'd need to handle, but the rest of the pipeline transfers.
A Web Worker version of the parser for huge chats (more than 50K messages). Right now we run on the main thread and it's fine for normal chats but starts to feel laggy on extreme cases.
A custom Open Graph image per shared link, so when someone pastes the URL into a chat the preview shows their group's actual yapper. Bigger viral hook than the generic preview we have now.
Auto-generated narrated video reels per chat. Basically a TikTok of your wrapped that you can post directly. We've got the data, we've got the AI roasts, we just need the video pipeline.
And eventually a year-on-year comparison ("Mia was 32% of the chat last year, now she's 45%, concerning trend") because Wrapped works best when there's a story over time.
Built With
- motion
- next.js
- react
- tailwind
- typescript
- upstash
- vercel



Log in or sign up for Devpost to join the conversation.