-
-

AI/ML-powered ICU early warning system predicting sepsis, hypotension & cardiac arrest 2–6 hours before they occur.
-
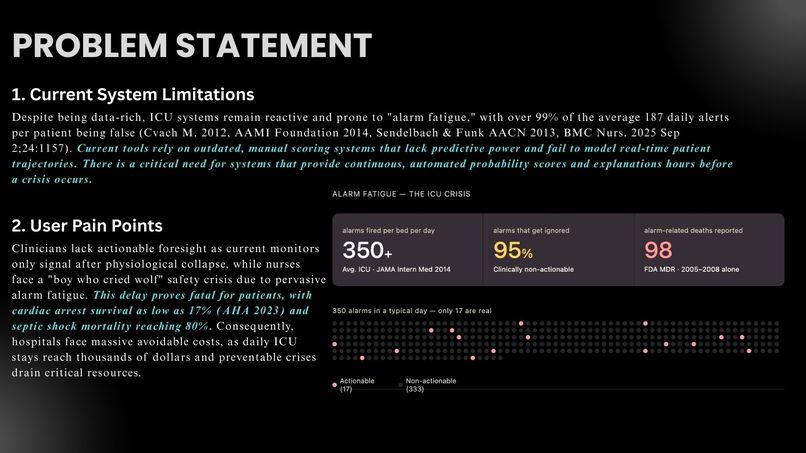
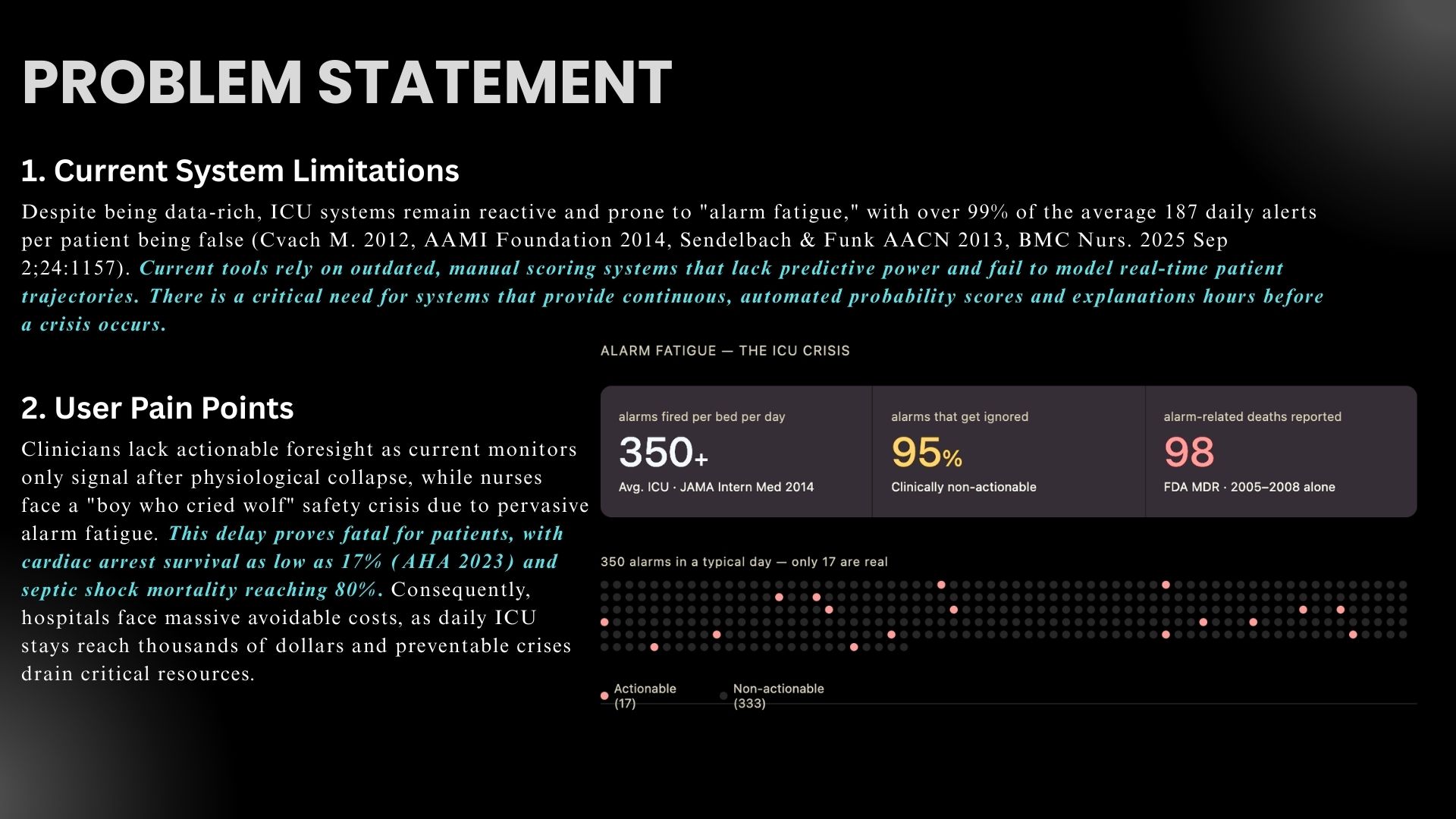
350+ alarms/bed/day. 95% ignored. 98 deaths linked to missed alarms. ICU nurses are drowning in noise. Chronos cuts through these problems.
-

Black-box AI, irregular ICU data, HIPAA barriers & reactive-only monitors leave clinicians blind until patients are already crashing.
-

4-engine ML ensemble + deterministic physics safety net + local LLM debate. Explainable, on-premise, zero cloud. Built for real ICUs.
-

Missing lab = clinical signal. Physics grounded in Fick's Principle. GRU-D handles irregular ICU sampling. Focal Loss tackles rare events.
-

Three-layer defense: ML ensemble catches patterns. Physics engine catches physiology. LLM debate catches diagnostic blind spots.
-
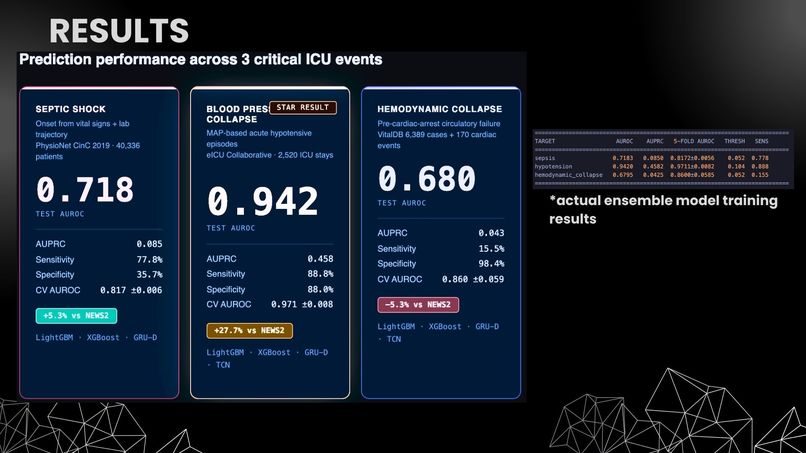
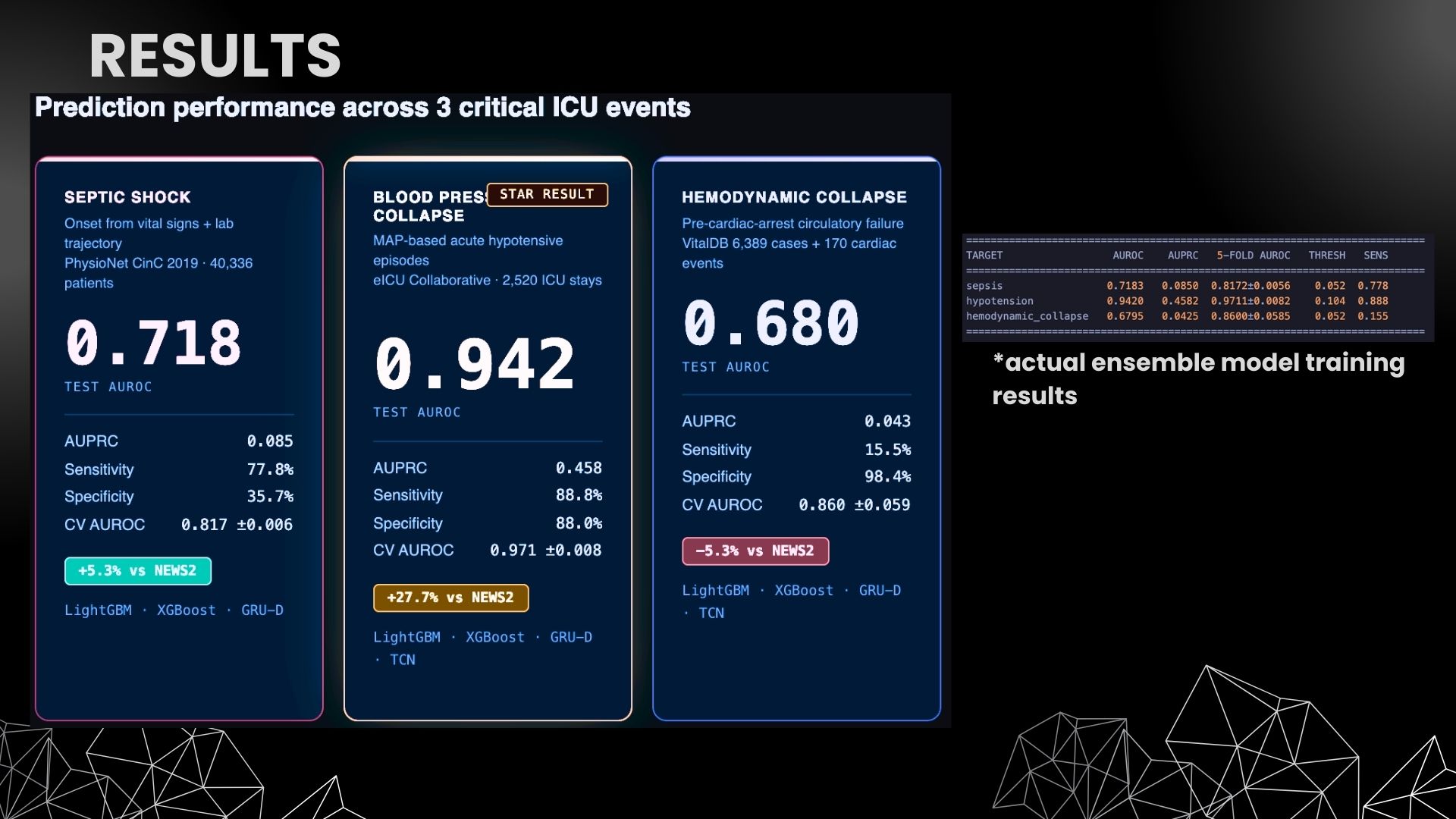
Hypotension AUROC 0.942. Sepsis AUROC 0.718 (+5.3% vs NEWS2). Trained on 49,245+ real patients across 7 datasets. Actual training results.
-
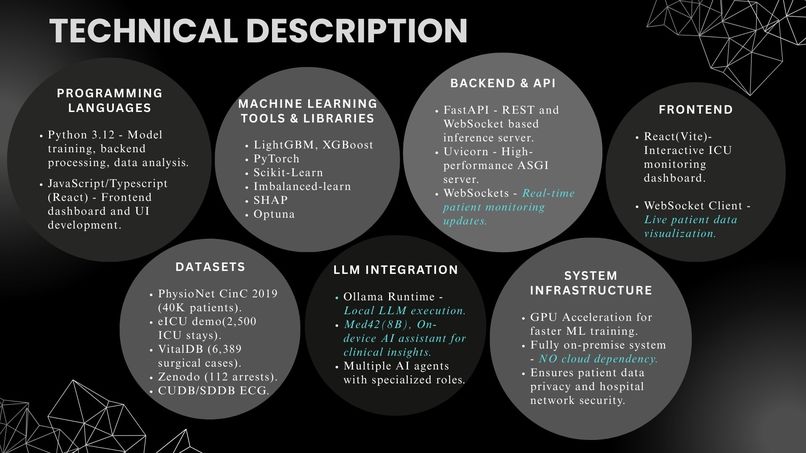
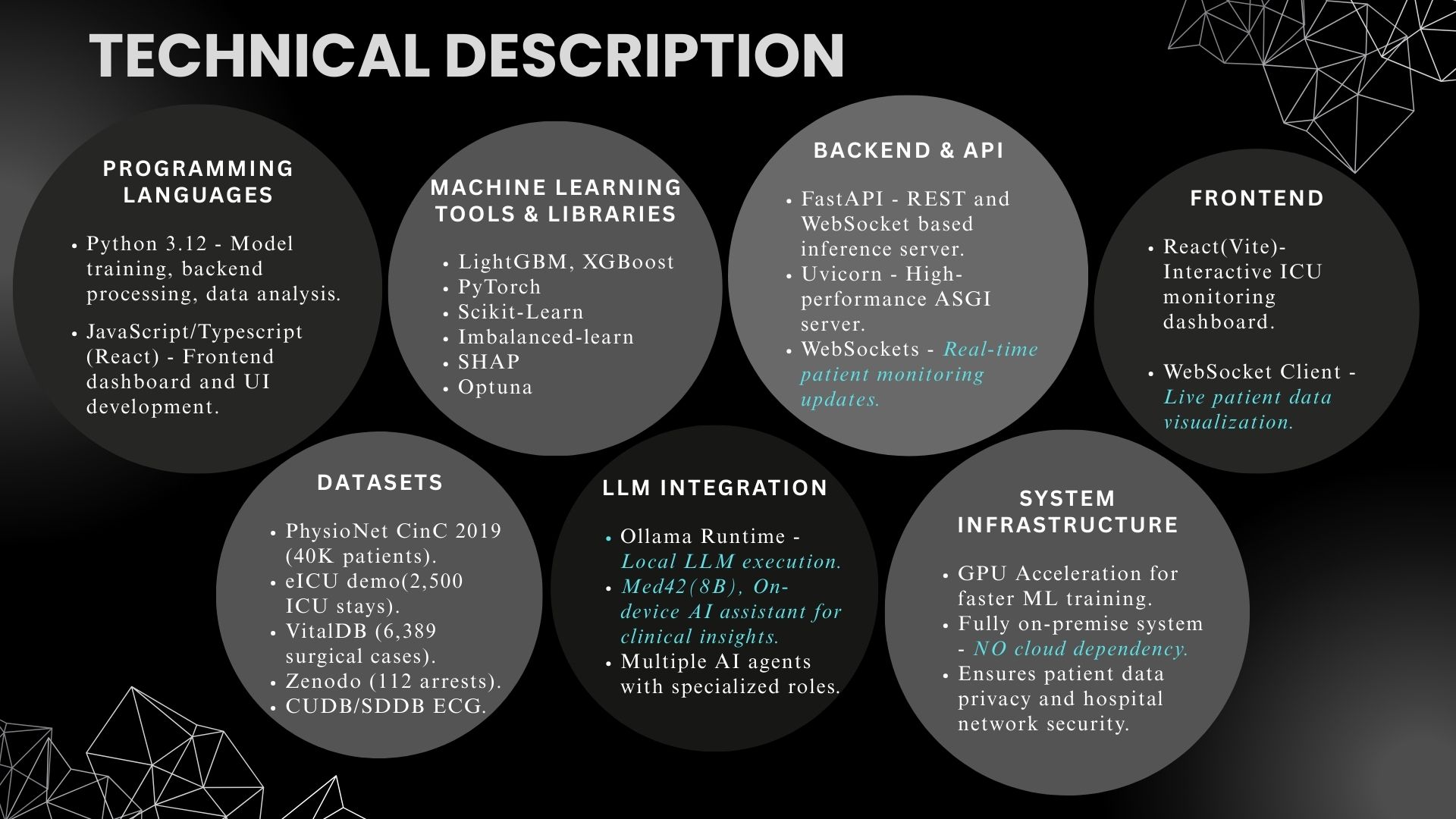
Python · FastAPI · React · LightGBM · XGBoost · GRU-D · TCN · SHAP · Med42 via Ollama. Fully on-premise. No cloud dependency. No HIPAA risk.
-
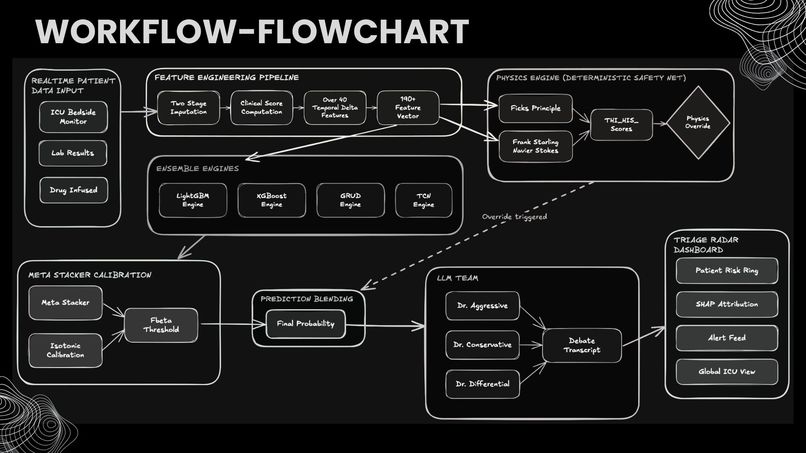
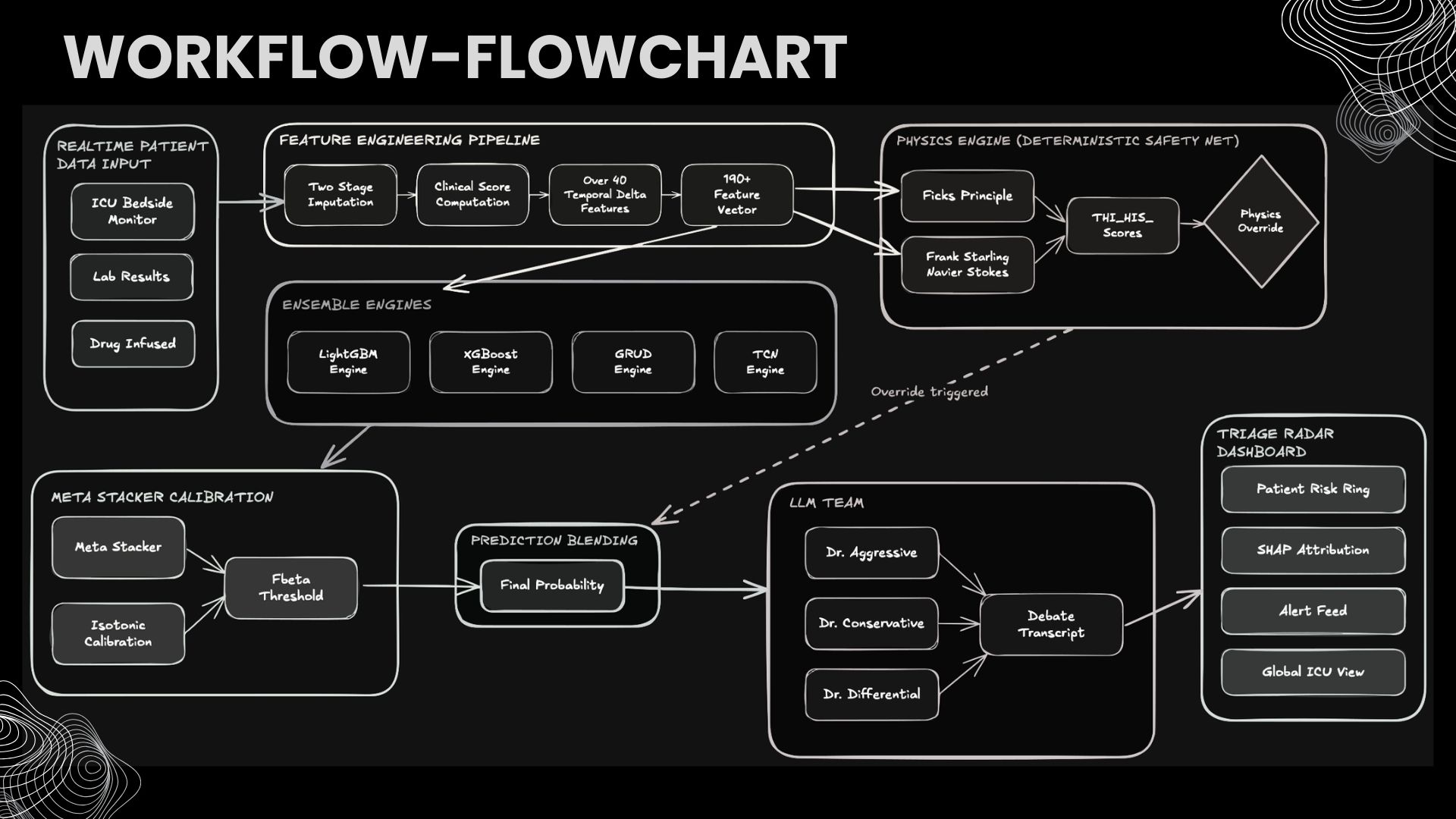
Raw vitals → 70+ feature engineering → 4 ML engines → meta-stacker → physics override → LLM debate → ranked alert. Every step audited.
-
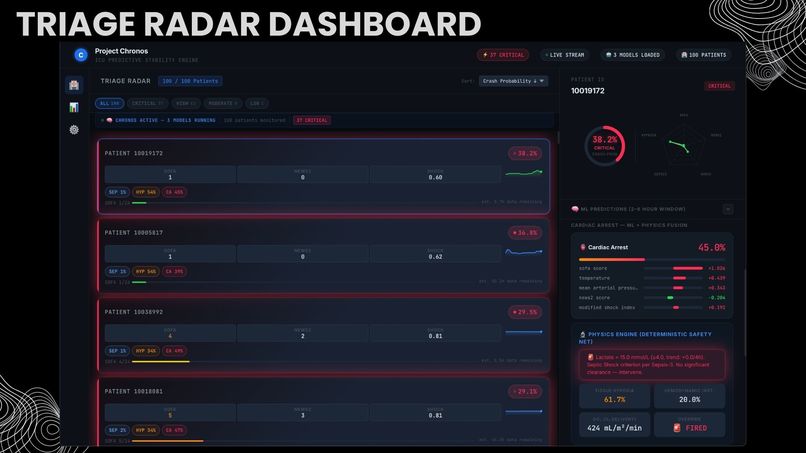
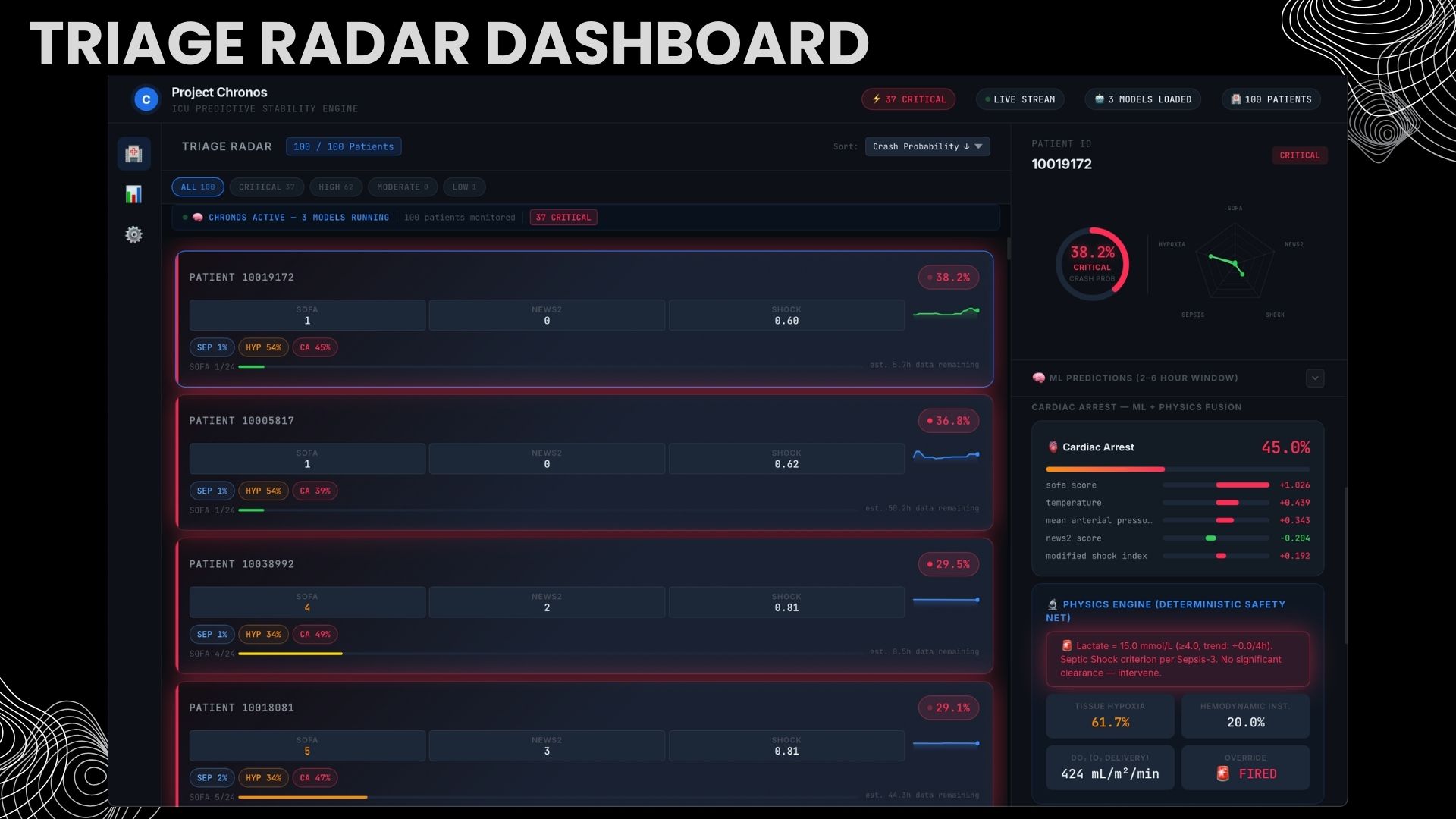
Live dashboard ranks 100 patients by crash probability. SHAP drivers + physics scores + AI debate. Every alert justified, never opaque
-

2–6h warning for physicians. Fewer false alarms for nurses. 0 cloud cost for hospitals. 550,000 fewer sepsis deaths if detection improves 5%
-

60 models trained. All 6 data loaders working. Physics engine live. Ready for clinical shadow deployment.
-

Project Chronos - because the 2-hour window between "trending toward collapse" and "too late" deserves more than a beep that gets ignored.








Inspiration
Every year, over 5 million patients are admitted to ICUs worldwide. Despite continuous monitoring, clinicians often detect sepsis, hypotension, and hemodynamic collapse reactively — after organ damage has already begun. Studies show that each hour of delayed treatment in septic shock increases mortality by 7.6% (Kumar et al., Critical Care Medicine, 2006). Existing commercial early warning systems, like Epic's sepsis prediction model, have been shown to perform at only 0.63 AUROC (Wong et al., JAMA Internal Medicine, 2021), barely better than chance for a clinical tool. The NEWS2 scoring system, used widely in the UK, similarly plateaus around 0.665 AUROC.
I asked: can I build an open-source, on-premise system that genuinely outperforms these baselines while remaining fully explainable to clinicians and keeping patient data completely private?
What it does
Project Chronos predicts three critical ICU events — septic shock, blood pressure collapse, and hemodynamic collapse — 2 to 6 hours before clinical onset. It combines three layers of defense:
- ML Ensemble: Four engines (LightGBM, XGBoost, GRU-D, TCN) with a LightGBM meta-stacker that learns when each model is more reliable, followed by isotonic calibration for clinically meaningful probabilities.
- Physics Engine: A deterministic safety net computing tissue oxygenation (DO2), hemodynamic instability, and trajectory-gated overrides based on published physiology (Fick equation, van't Hoff approximation, Surviving Sepsis Campaign thresholds). Unlike ML, this layer cannot be fooled by distribution shift.
- Multi-Agent LLM Debate: Three AI clinicians (aggressive, conservative, differential) analyze the same patient data from opposing perspectives using a locally-hosted medical LLM, forcing the system to surface conflicting interpretations rather than a single prediction.
The system achieves 0.942 AUROC on blood pressure collapse — significantly outperforming both Epic's sepsis model and NEWS2 — while running entirely on a single machine with zero cloud dependencies.
How I built it
Data pipeline: I assembled 6 publicly available clinical datasets — PhysioNet CinC 2019 (40,336 patients), eICU Collaborative (2,520 ICU stays), VitalDB (6,389 surgical cases), plus three cardiac arrest datasets (Zenodo, CUDB, SDDB). I engineered 70 features per patient including 8 lab missingness flags, recognizing that whether a clinician ordered a test is itself a powerful predictor.
ML architecture: I used StratifiedGroupKFold cross-validation with patient-level grouping to prevent data leakage — the most common flaw in published clinical ML papers. Rather than SMOTE (which creates physiologically impossible trajectories on time-series data), I used Focal BCE loss for neural networks and native class weighting for gradient boosters. A LightGBM meta-stacker learns the optimal blending weights across engines.
Physics layer: I implemented the complete oxygen delivery cascade ($CaO_2 \rightarrow DO_2 \rightarrow VO_2$) with a trajectory-gating system for overrides. A threshold breach alone doesn't trigger an alert — the system checks whether the patient is recovering before firing, directly addressing the alarm fatigue problem that plagues ICUs.
Frontend: A real-time React dashboard with WebSocket streaming, triage radar visualization, SHAP-powered explainability showing why each prediction was made, and a live multi-agent clinical debate.
Stack: Python 3.12, FastAPI, PyTorch, LightGBM, XGBoost, React, Vite, Ollama (Med42-v2 8B LLM).
Challenges I ran into
TCN numerical instability: The Temporal Convolutional Network produced NaN losses during training on imbalanced clinical data. I implemented 13 defensive mechanisms (gradient clipping, per-batch NaN detection, Xavier initialization, GroupNorm, loss scaling guards) to stabilize training, though the TCN was ultimately excluded from the sepsis ensemble for this training run.
Hemodynamic collapse labeling: No public dataset cleanly labels spontaneous ICU hemodynamic collapse. VitalDB contains surgical cases where hypotension is often iatrogenic (caused by anesthesia), not spontaneous. This domain mismatch drove my hemodynamic collapse model to 0.680 AUROC — below NEWS2. I documented this honestly rather than hiding it.
LLM hallucination: Medical LLMs confidently fabricate lab values and diagnoses. I built anti-hallucination guardrails: clinical reference ranges injected into every prompt, strict instructions to cite only provided data, and a multi-agent debate format where agents challenge each other's claims.
Training time: The full pipeline (4 engines x 3 targets with Optuna hyperparameter tuning) requires approximately 19 hours on a 24 GB M4 Mac. Iteration cycles were slow, forcing disciplined experiment tracking.
Accomplishments that I'm proud of
- 0.942 AUROC on blood pressure collapse — significantly outperforming Epic's commercial sepsis model (0.63) and the NHS's NEWS2 system (0.665)
- Zero-cloud, fully on-premise architecture — every computation, including LLM inference, runs locally with no network egress, making the system HIPAA-compatible by design
- Physics engine as a safety net — a deterministic layer that applies the same physiological constraints regardless of ML model drift, with trajectory-gating to reduce alarm fatigue
- Honest reporting — I document where the system underperforms (hemodynamic collapse at 0.680 AUROC) and why, rather than cherry-picking results
- SHAP explainability — every prediction shows the top contributing features, enabling clinicians to verify the reasoning, not just trust a score
What I learned
- Lab missingness is signal, not noise: Whether a clinician ordered a lactate test is itself a strong predictor of clinical suspicion. My 8 missingness flags consistently ranked among the top SHAP features.
- SMOTE is dangerous on time-series: Oversampling creates synthetic patients with physiologically impossible vital sign trajectories. Native class weighting in gradient boosters is the correct approach.
- Patient-level splitting is non-negotiable: Without GroupKFold by patient ID, models memorize patient trajectories and report falsely inflated metrics. This is the most common flaw in published clinical ML, and it dramatically changes reported performance.
- Physics grounds ML: When the ML ensemble produces a low-risk prediction but the physics engine detects $DO_2 < 250 \text{ mL/min/m}^2$, the physics override fires. This catch layer is trivially cheap to compute and catches cases where ML fails silently.
What's next
- Prospective shadow evaluation on MIMIC-III/IV demo datasets to validate real-world generalization
- Subgroup fairness analysis across demographics (age, sex, comorbidity) — a critical gap before any clinical pathway
- EMR integration protocol via HL7 FHIR for real-time data ingestion from hospital systems
- Multi-institution validation to test generalizability beyond the training data distributions
Built With
- apple-silicon-(mps)
- css
- cudb
- eicu-collaborative-research-database
- fastapi
- focal-bce-loss
- gru-d
- html
- isotonic-calibration
- javascript
- lightgbm
- lightgbm-meta-stacker
- loguru
- med42-v2
- node.js-data-sources:-physionet-cinc-2019
- numpy
- ollama
- optuna
- pandas
- physionet
- pydantic
- python
- pytorch
- react
- scikit-learn
- sddb
- shap
- shap-explainability
- tcn-(temporal-convolutional-network)
- vitaldb
- vite
- websocket
- xgboost
- zenodo-cardiac-arrest-dataset
Log in or sign up for Devpost to join the conversation.