-
-

What is Athena?
-

The idea
-

auto generating the graph - visualization
-

auto generating the graph - vertices and edges
-

how NLP to GSQL works
-

architecture
-

running the program locally for generating the graph
-

Schema of Graph
-

Statistics of Graph currently (and counting)
-

the handmade dataset for Seq2seq model - NLP to GSQL
-

training the seq2seq model
-

Graph filtered for a particular vertex (345) with its connected vertices
-

Graph filtered for a particular vertex (345) with its connected vertices
-

viewing the result of NLP querying API in browser










Inspiration
There is a huge amount of unstructured textual data that gets generated every day. Enterprises, Individuals, News Media, etc. all create volumes of unstructured data that are hard to analyze and understand in a structured way.
Business users / Individuals are left with no simpler ways to analyze unstructured data without considerable efforts of data transformation, data schema design, and curation. Moreover, Querying and searching through the data, takes additional efforts and cannot be easily done by those without the necessary skill sets and without an intermediary application.
This problem led to the creation of Project Athena (named after the Greek goddess of knowledge and wisdom). I picked a financial news dataset with close to 1 million (1,000,000) records and got it analyzed through the application.
TigerGraph is the best fit for this problem, with its high performance, elegantly designed GSQL and a rich data science library.
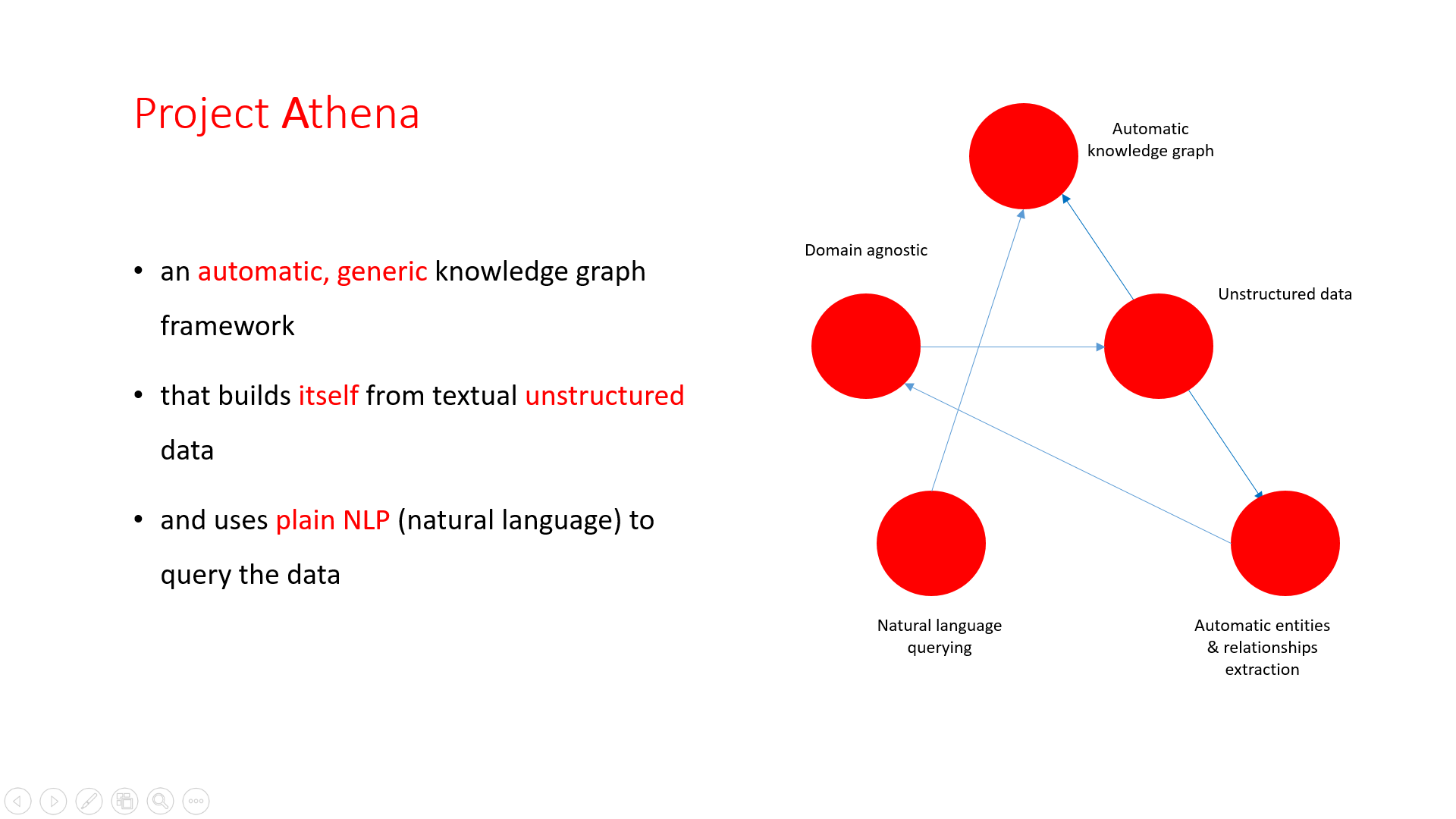
What is Athena?
- an automatic, generic knowledge graph framework
- that builds itself from textual unstructured data
- and uses plain NLP (natural language) to query the data
A knowledge graph that builds itself, speaks our language, and blends with existing tools.
What it does
- What if there was an intelligent system that automatically understands the entities, people, location, objects and the relationships among them that are found in the unstructured data and creates a big knowledge graph?
- What if there was a system that allowed us to search and query that data using natural language?
- What if the system was generically applicable regardless of the domain of the data?
Consider for example, that the intelligent system creates an automatic financial knowledge graph when executed on top of years of financial unstructured data, and it creates an automatic medical knowledge graph when executed on top of a pile of medical unstructured data.
Consider for example, that we are able to query the knowledge graph just by typing in natural language -
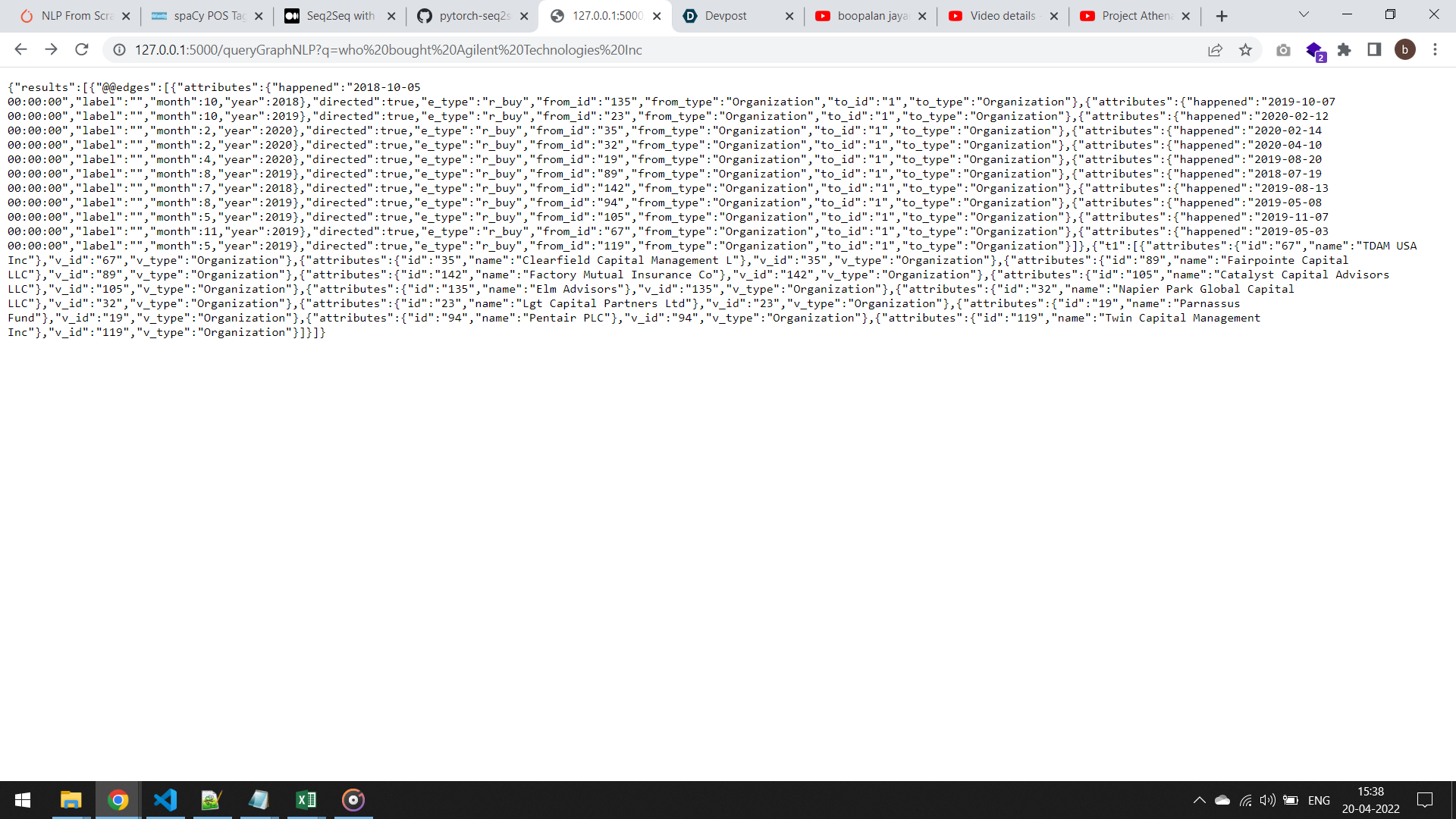
- "Who bought Agilent Technologies Inc" or
- "who all are investing in Russia" or
- "Who bought Microsoft Corp between the years 2014 and 2016" or
- "who had beaten the market in 2014" or
- even queries like "who bought the companies that bought Facebook Inc" without having to rely on additional querying tools.
What it solves
Athena aims to create the knowledge of data in two simple steps:
- Load the unstructured data, and wait for the system to understand the frequently used entities and relationships.
- Start talking to the system in your language.
Factors of design
Integration - bring the data to the applications that business users already spend their days with - such as Excel or Power BI or an existing application. This prototype is built as an API to meet those requirements.
Ease of adoption - ability to just run and create the knowledge graph on unstructured data with minimal configuration and set up.
Ease of use - ability to have a simpler mode of interaction with the system
How we built it
Automatic Graph Creation Module
I started by studying various datasets that are unstructured in nature. The below datasets helped in understanding the patterns of unstructured data. (URLs given in References section)
Stock Market News Data in Kaggle Indian financial news headlines data found in a discussion of Kite Website. Drug sentiment classification data in Kaggle competition Self-collected News data for the past 3 months.
I tried running both Google’s BERT algorithm and Spacy for Named Entity Recognition on top of the above data (each sentence). The BERT algorithm classified the entities better while Spacy could not classify the entities properly. More often, Spacy classified a single entity into multiple ones. Hence BERT was chosen to do this task.
Naturally most entities fall in one of the four categories - Organization, Person, Object, Location.
Next, I wanted to extract the verbs (actions) out of the sentence in order to find the edge or relationship that connects two entities. I tried using both Spacy and NLTK for this. Spacy was chosen because it was better at Lemmatizing and POS tagging than NLTK. (The prototypes are available as Jupyter Notebooks in the GitHub repository)
This is done for the whole dataset once initially to get the list of most frequently occurring relationships (actions / edges). Then they are created as part of the schema automatically (along with the four entity types). By default, the program covers 70% of the most occurring domain verbs. If we want to change that to 80% or 90%, this is possible through a configuration.
Then, through pattern matching, I could identify sentences that form a pattern of this kind - (Entity / Noun) → (Verb) → (Entity / Noun) which naturally is identical to how a graph database works. There are more such patterns, but for the purpose of a prototype, I limited it to a few patterns and occurrences.
The entities and relationships were then added to the database.


Statistics:
I executed this on top of the financial news dataset with having close to 1,000,000 (1 million) records, analyzed around 700,000 rows through the program and created (as of writing this)
- More than 25000 Organizations,
- More than 1800 Persons,
- More than 5400 Objects,
- More than 1500 Locations,
- More than 220 Edge Types (relationships)
- More than 130,000 relationships (edges)

NLP Language Translation to Intermediate Language - Training
NLP language translation is no simple task. To train a model that converts user’s plain natural language query into a database query (such as SQL or tigergraph’s GSQL) requires a huge input dataset (in the order of hundreds of thousands of rows) containing mappings between NLP query and output GSQL query. This is practically non-existent currently and is a research problem even today. Furthermore they also require more computing power and run for days for training.
There are datasets such as WikiSQL but they deal mostly with data that are part of a single table without any joins. Graph by its nature involves multiple entities and relationships and requires joins.
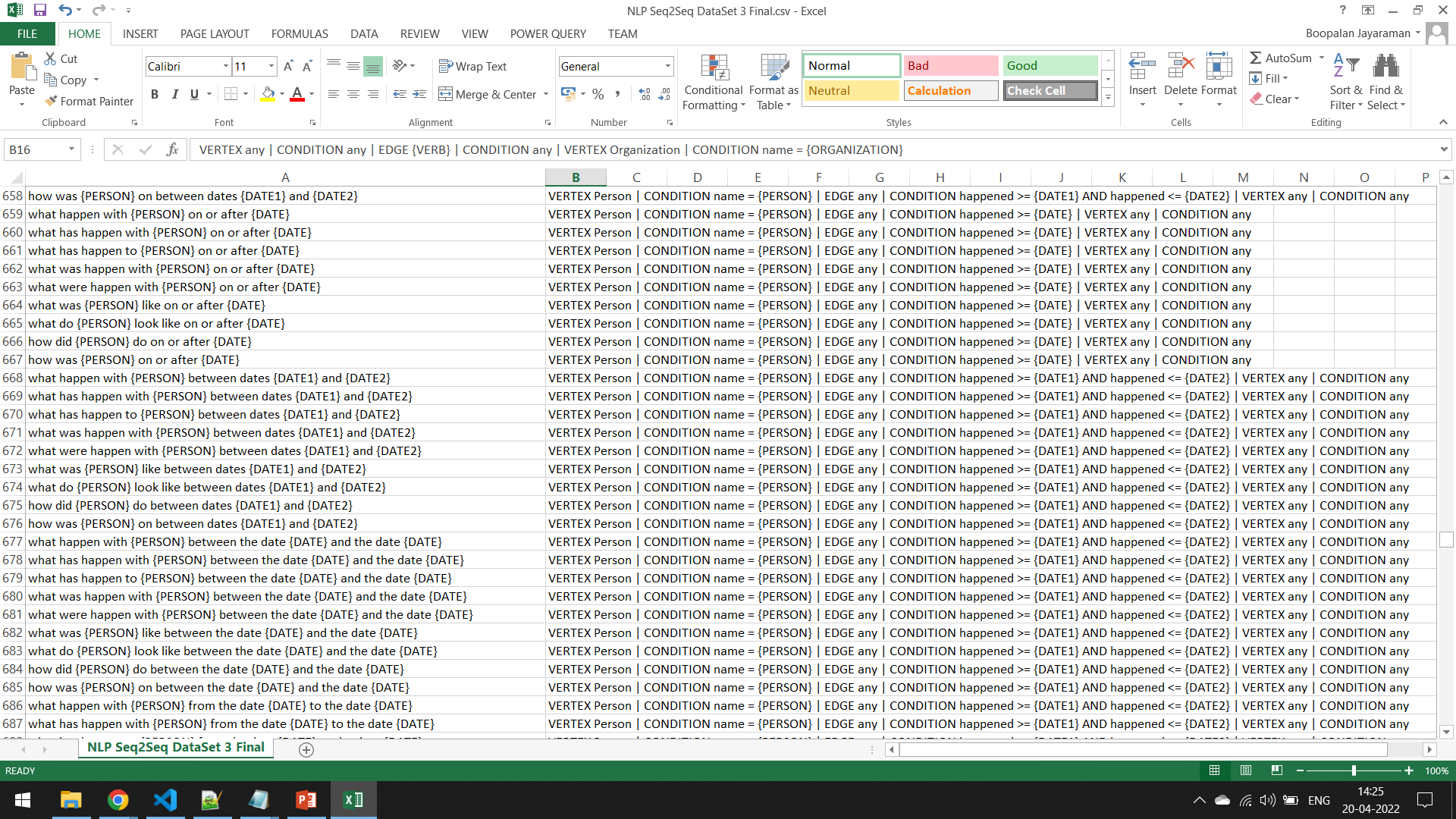
Hence, I adopted an approach in the middle. I created a dataset from scratch, containing templates of questions, rather than the actual questions. I further added the various similar forms a question would take. Then I mapped them to a hand-written “intermediate language” which will be further parsed into the actual GSQL.

I added around 1000+ questions manually mapping the natural language template to the intermediate language.
For ex., a query template and its intermediate language look like this
INPUT:
who has {VERB} {ORGANIZATION} between the dates {DATE1} and {DATE2}
OUTPUT:
VERTEX any | CONDITION any | EDGE {VERB} | CONDITION happened >= {DATE1} AND happened <= {DATE2} | VERTEX Organization | CONDITION name = {ORGANIZATION}
I built a Seq2Seq (encoder-attention decoder) recurrent neural network model on top of this dataset. Now, this model can be used to convert the user NLP query into the intermediate language.

NLP Querying Module
With the help of the model created in the previous step, I could convert a plain NLP query into the intermediate language in a parameterized way.
The verbs that are found in the natural language query are matched with the relationships or the edges, and the entities are matched with the vertices. The intermediate language is further parsed and converted into GSQL formats. After the GSQL query is executed against the TigerGraph database, results are returned to the user.
This module has been built as a Flask API service so that it could be quickly integrated with other systems.

Technology Stack
The system has been built by putting the best technology to work.
- TigerGraph
- BERT algorithm for Named Entity Recognition (huggingface transformers)
- Spacy for POS tagging (edges identification)
- PyTorch
- Seq2Seq Recurrent Neural Networks (for NLP to intermediate language translation)
- Python, Flask
- Jupyter Notebooks, Anaconda Python

How to run this
The GitHub repository contains all the three modules necessary to run the application and see it. The necessary datasets and models for NLP training are part of the repository.
- GenerateGraph
- Nlp2Gsql
- QueryGraph
I have added the required instructions and configurations as part of the GitHub repo. Please refer to them.
The actual dataset used to generate the graph is not part of the repository due to file size limitations (~350+ MB). I’ve uploaded this to google drive and shared the link here.
Full dataset for news headlines with 1M+ rows
Challenges we ran into
Creating entities and relationships depend largely on the accuracy of BERT and Spacy frameworks. BERT and Spacy both were trained on comparatively smaller datasets for Named Entity Recognition. This can be overcome if we fine tune them on a domain-based dataset in future if necessary.
Duplicates and Aliases that are immensely found in the news dataset (or any news dataset). Ex., “Agilent” and “Agilent Technologies Inc” mean the same entity. We can overcome this in future by having domain-based master data if necessary.
Case (upper vs. lower) of text made a big difference in classifying the entities or verbs. For ex., ‘Buys’ is classified into a noun whereas ‘buys’ is classified into a verb.
Accomplishments that we're proud of
- We created a generic framework that is functional and is a very good prototype for the idea.
- This will really help many businesses and users by enabling them look at their data in a different perspective.
- Attempted a research problem (converting NLP questions into an intermediate language for querying)
What we learned
- Working with TigerGraph is a very good learning experience and taught me to look at the data in a wholly different way.
- Learning to apply the concepts of Seq2Seq RNN on a real use case was a very good experience.
What's next for Project Athena
- Improving accuracies for BERT NER and Spacy POS tagging by fine tuning further
- Handling special cases in the NLP parameterization and creating a larger dataset for NLP to Intermediate language training
- Handling GSQL data science algorithms through natural language
References
https://www.kaggle.com/datasets/miguelaenlle/massive-stock-news-analysis-db-for-nlpbacktests
https://www.kaggle.com/datasets/jessicali9530/kuc-hackathon-winter-2018
https://github.com/TigerGraph-DevLabs/TigerGraph_Northwinds
https://huggingface.co/dslim/bert-base-NER/tree/main
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html




Log in or sign up for Devpost to join the conversation.