-
-
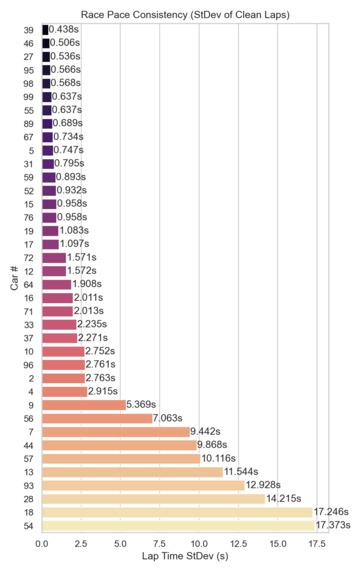
Average Race Pace by car
-
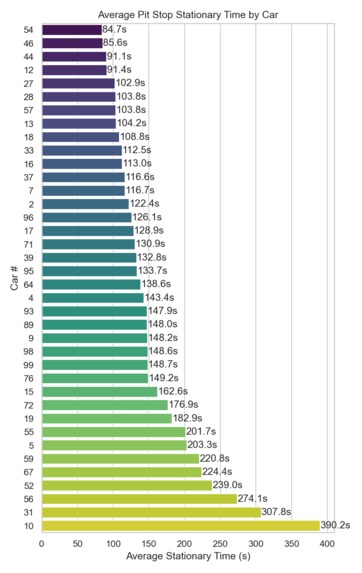
Average Pit Stops across cars
-

Generated social media content
-
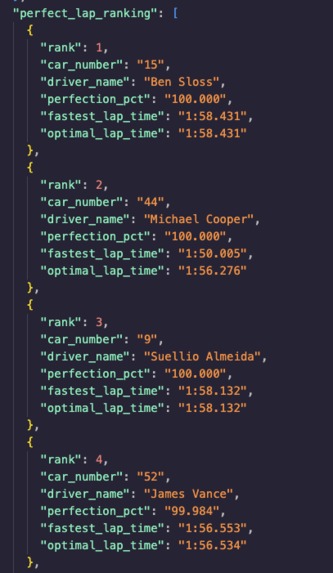
Finding drivers hitting their optimal lap times
-
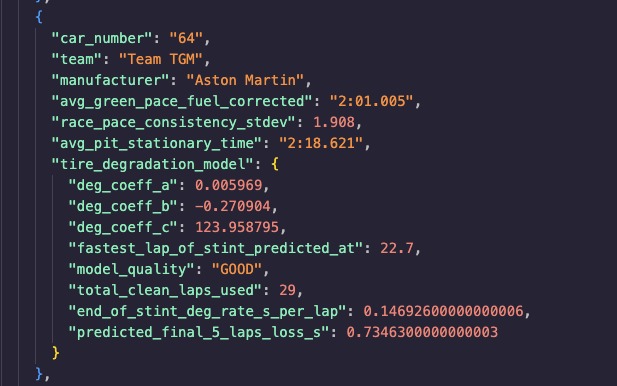
Per car race strategy, pace
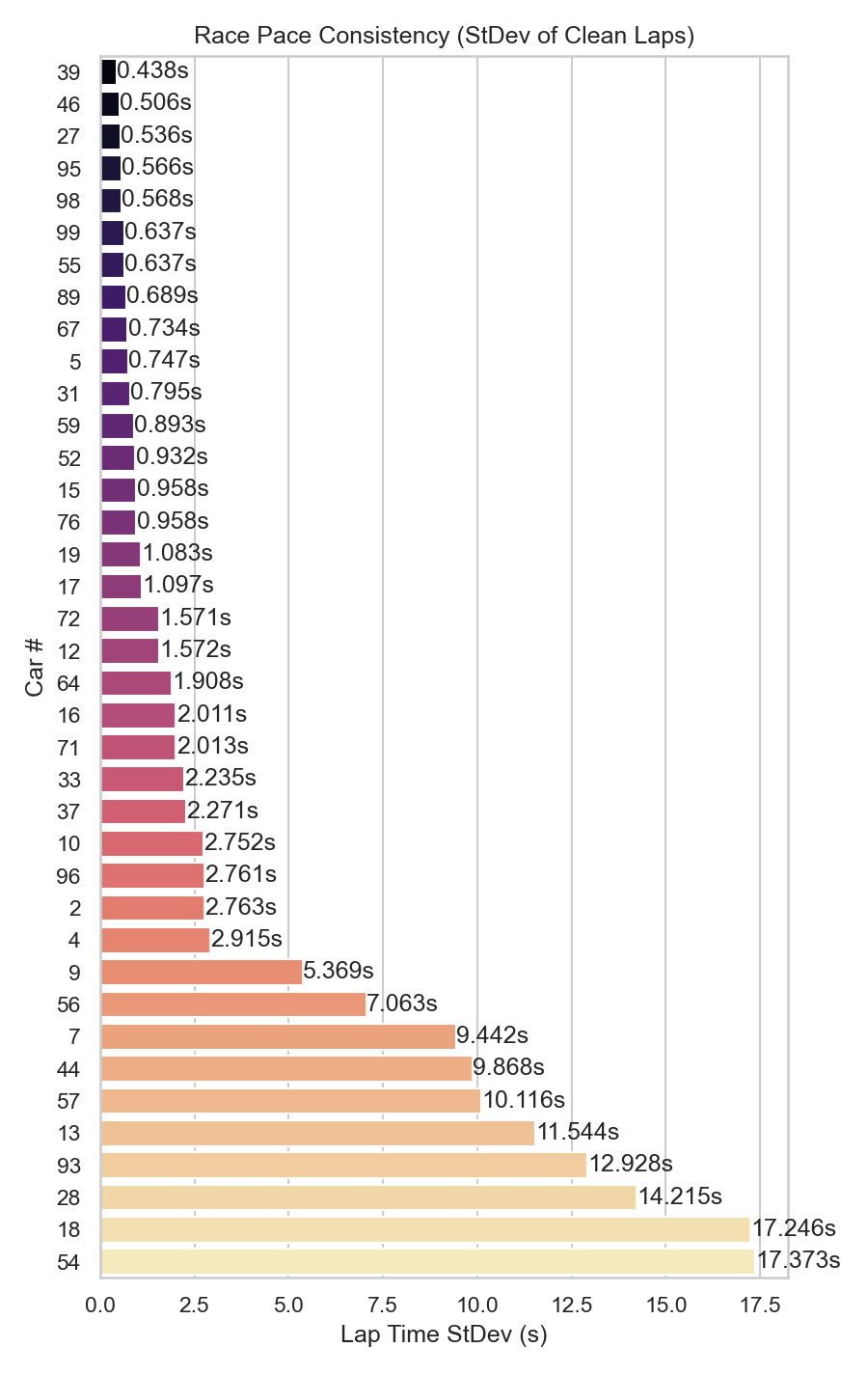
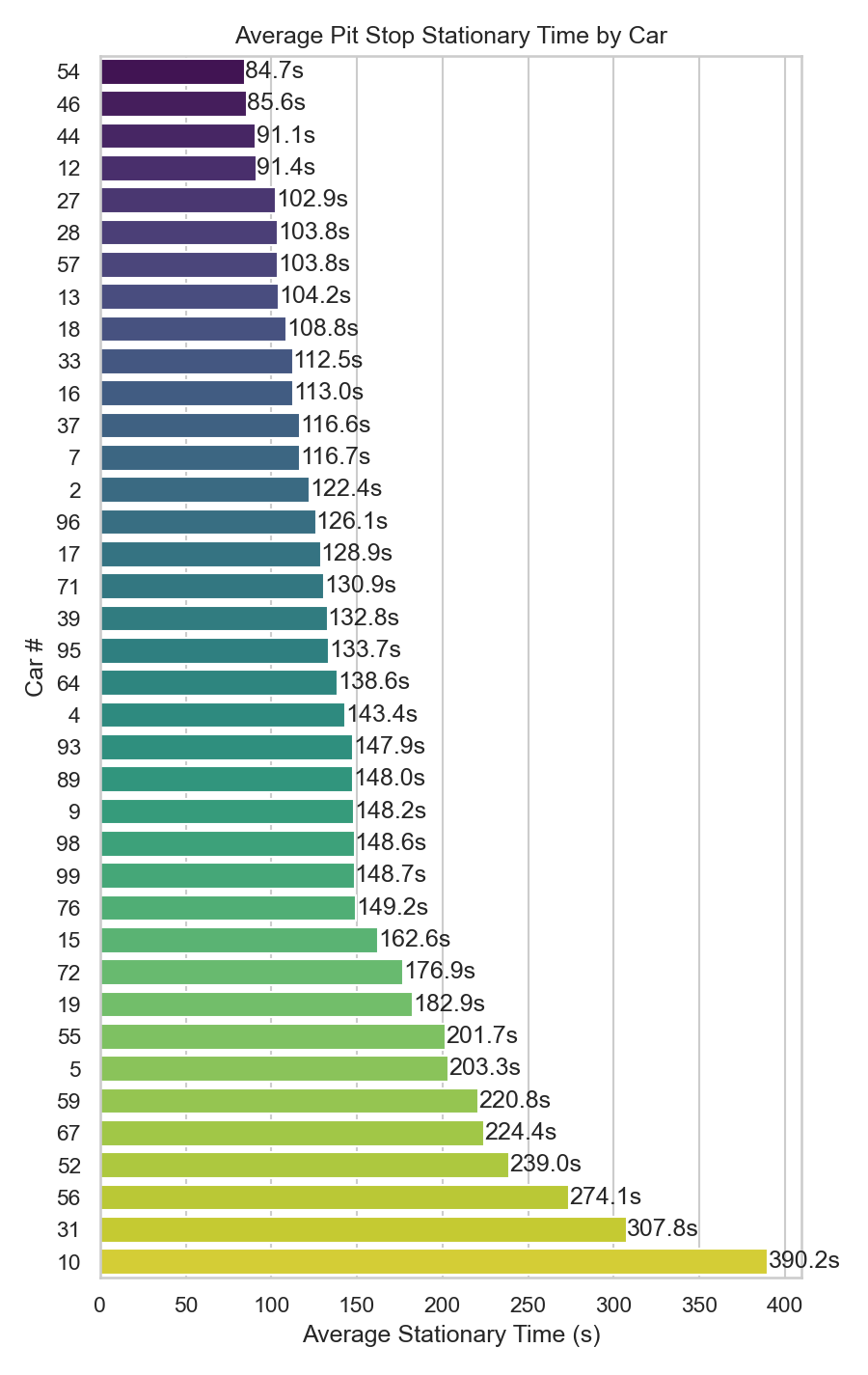

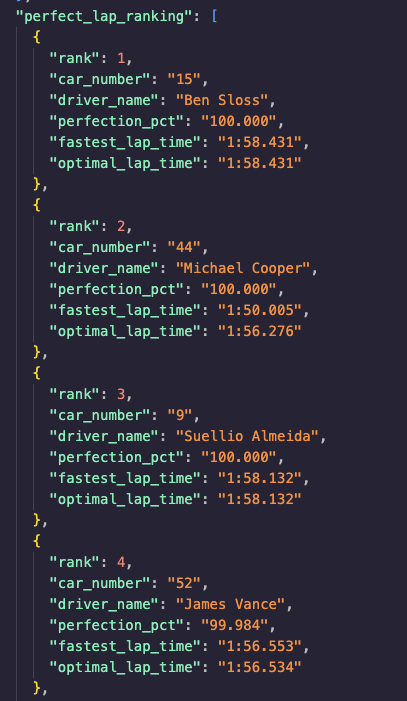
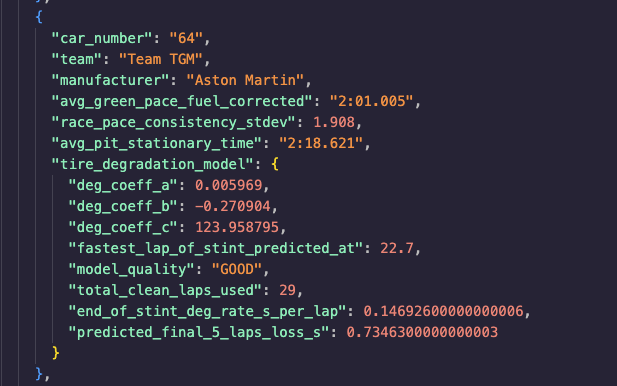
Inspiration
In the high-stakes world of endurance racing, teams are inundated with thousands of data points every minute—lap times, sector splits, pit stops, and fuel consumption. This raw data is dense and difficult to interpret under pressure. While competing in IMSA Michelin Pilot Challenge at Daytona and Mid-Ohio, we saw a critical gap between the raw telemetry streaming from the track and the actionable intelligence needed by two key personas:
- The Race Strategist on the pit wall needs to make split-second decisions. They need to know why a competitor is suddenly faster or if their own driver is struggling with tire wear, not just stare at a wall of numbers.
- The Marketing Manager needs to engage fans. Lap times are boring, but the story of a driver overcoming a poor start, or a perfectly executed pit stop that gains three positions, is incredibly compelling.
Our inspiration was to build a system that bridges this gap—an autonomous team of AI agents that could not only analyze the data but also understand its context, synthesize a narrative, and craft outputs tailored to both strategy and fan engagement.
What it does
Project Apex is an autonomous, multi-agent system built on Google's Agent Development Kit (ADK) that transforms raw motorsport data into a real-time competitive advantage and a brand-building asset.
A user, such as a race strategist, simply uploads the raw race telemetry CSV and pit data JSON to our web portal. This single action triggers a sophisticated, autonomous workflow:
- Autonomous Analysis & Investigation: A team of agents collaborates to analyze the data. They don't just process it; they investigate it. If an anomaly is found—like a massive performance gap between teammates—the
InsightHunteragent autonomously calls on ourCoreAnalyzertoolbox for a detailed "drill-down" report on that specific issue. - Narrative Synthesis: Our
Arbiteragent acts as the Chief Strategist. It receives reports from theInsightHunterand theHistorian(which compares performance to previous years) and synthesizes them, resolving conflicts to create a single, coherent "master narrative" for the race. - Tailored Content Generation: This master narrative is then passed to our output agents:
- The
Scribeagent generates a professional, multi-page PDF engineering report for the pit wall, complete with an executive summary and AI-generated tactical recommendations. - The
Publicistagent, acting as a content strategist, autonomously decides which insights are most engaging, generates multiple tweet variations, and calls ourVisualizertool on-demand to create charts and graphs to accompany its posts.
- The
The result is a complete intelligence package, delivered automatically, turning raw data into decisive strategy and compelling stories.
How we built it
Project Apex is built entirely on Google Cloud, architected around the principles of the Agent Development Kit (ADK) to create a truly orchestrated and autonomous system.
Orchestration: The heart of the system is our ADK Orchestrator, a Cloud Run service that manages the entire workflow. It uses the ADK's
execution.Graphto define the sequence and dependencies of agent tasks, enabling complex parallel execution. For example, after the initial analysis, theInsightHunterandHistorianagents run simultaneously to accelerate the investigation phase.Agent Architecture: Each agent is a specialized, containerized Cloud Run service. This serverless design ensures scalability and cost-efficiency. The agents communicate via secure, authenticated HTTP requests managed by the ADK Orchestrator. We moved away from a simple Pub/Sub chain to this more robust, centrally managed model to fulfill the core promise of ADK.
Autonomous Tool Use: We implemented an "agent-as-a-toolbox" design pattern.
- The
CoreAnalyzerandVisualizerare not just pipeline steps; they are services with specific API endpoints (e.g.,/tools/driver_deltas,/plot/consistency). - Our "thinking" agents, like the
InsightHunterandPublicist, can make autonomous, on-demand calls to these tools when they decide more information or a visual is needed.
- The
Technology Stack:
- ADK: For defining and executing the multi-agent workflow graph.
- Vertex AI Gemini API: Powers the reasoning and content generation for our most advanced agents, including the
Arbiter(synthesis),Publicist(social media and self-correction), andScribe(executive summary). - Cloud Run: Hosts all of our containerized agents, providing a scalable, serverless execution environment.
- Streamlit: Powers our
UI Portalfor file upload and results visualization. - BigQuery: Serves as the long-term memory for our
Historianagent, storing past race analyses for year-over-year trend spotting. - Cloud Storage: Stores all raw data and final artifacts (PDF reports, JSON files, visuals).
- Pub/Sub: Initiates the entire workflow, decoupling the UI from the ADK Orchestrator.
Challenges we ran into
From Pipeline to Orchestration: Our initial design was a simple, reactive chain of agents linked by Pub/Sub. We quickly realized this wasn't true orchestration. The biggest challenge was refactoring the entire system to be controlled by a central ADK graph. This involved changing every agent from a passive listener to an active HTTP service and implementing a state dictionary to manage the flow of GCS paths between them.
Enabling True Autonomy: Prompting an LLM to generate text is straightforward. Prompting it to make decisions and call tools is far more complex. We spent significant time iterating on the prompts for the
ArbiterandPublicist, designing them to return structured JSON that specified which tools to call with which parameters. This required rigorous testing to ensure the LLM's output was reliable enough for our code to parse and execute.The Self-Correction Loop: Implementing the
Publicist's peer-review feature was a major challenge. We had to create a second "Reviewer" personality and a logic loop that could feed the critique back into the initial prompt for a retry. Making this loop stable and ensuring it actually improved the output on the second attempt required careful prompt engineering.
Accomplishments that we're proud of
The Arbiter Agent: We are incredibly proud of the
Arbiter. It represents a higher level of agentic behavior. It doesn't just process data; it synthesizes conflicting information from two specialist agents (InsightHunterandHistorian) to create a single, coherent master narrative. This is the central "brain" of our system.Autonomous Tool Use: The "agent-as-a-toolbox" architecture is a key accomplishment. Our
InsightHuntercan independently decide it needs more information and query theCoreAnalyzerfor a drill-down report. This dynamic, on-demand data retrieval is what makes our system feel truly intelligent.The Self-Improving Publicist: The
Publicist's ability to critique and revise its own work is a powerful demonstration of modern agentic patterns. It doesn't just generate content; it strives to generate good content, making it a far more valuable asset.
What we learned
Orchestration is About Control, Not Just Triggers: Our biggest takeaway is the power of a central orchestrator. Moving from a reactive Pub/Sub chain to an ADK-managed graph gave us explicit control over the workflow, state management, and parallel execution, making the entire system more robust and efficient.
Prompt Engineering is System Design: We learned that designing prompts for autonomous agents is a form of system design. Instead of just asking for output, we learned to ask the LLM to create a "plan" (a JSON object with decisions and tool calls), which our code could then reliably execute.
Agents as Services: Thinking of agents as callable services with specific tools (APIs) is a powerful paradigm. It makes the system modular, testable, and infinitely extensible.
What's next for Project Apex
We are just scratching the surface of what an autonomous agent team can do in motorsport. Our next steps are focused on increasing real-time interaction and predictive capabilities:
- Unified Data Model and Multi-Series Support: To scale beyond a single series, we will develop a universal data model. We'll create a new Adapter agent responsible for ingesting raw data from various motorsport series (e.g., Formula 1, FIA World Endurance Championship). This agent will act as a transformer, mapping series-specific data formats into our core, unified model before the CoreAnalyzer ever sees it. This abstracts the analysis logic from the data source, allowing our entire agent team to seamlessly analyze and generate insights for any race series without modification, turning Project Apex into a truly versatile and scalable motorsports intelligence platform.
2 Real-Time Ingestion & In-Race Alerts: Transition from file uploads to a live WebSocket or Kafka stream from the timing & scoring feed. This would allow the InsightHunter to provide real-time alerts to the pit wall during the race (e.g., "Critical Alert: Rival car #28 just had a 5-second slower pit stop than their average. They may have an issue.").
Human-in-the-Loop for Social Media: Add an approval step to the UI Portal. The
Publicistwill draft the posts and visuals, and the Marketing Manager will have a simple "Approve & Post" button that triggers a final function to post directly to the X/Twitter API.Predictive Strategy Tools: Leverage the historical data in BigQuery to train a simple Vertex AI AutoML model. The
Arbitercould then use this as a new tool, asking it questions like, "What is the probability of a podium finish if we pit under this yellow flag vs. staying out?" This would evolve the system from analysis to true predictive intelligence.
Built With
- adk
- python

Log in or sign up for Devpost to join the conversation.