
INSPIRATION
What inspired us to build Project AETHER was the critical need for transparent, multi-perspective analysis in decision-making processes. Traditional AI systems often provide single-perspective recommendations without exploring counterarguments or alternative viewpoints. We wanted to create a system that mimics the Socratic method of debate, where every claim is challenged, evidence is scrutinized, and synthesis emerges from structured opposition.
The name AETHER represents the “invisible medium” through which reasoning flows. Just as the classical aether was thought to pervade space, our system creates a structured reasoning context that allows multiple AI agents to debate and synthesize insights transparently.
We were inspired by:
The need for explainable AI that exposes its reasoning process
Academic debate formats where thesis and antithesis lead to synthesis
The challenge of analyzing complex documents such as business reports and research papers
Preventing AI hallucination by grounding all reasoning strictly in provided context
WHAT IT DOES
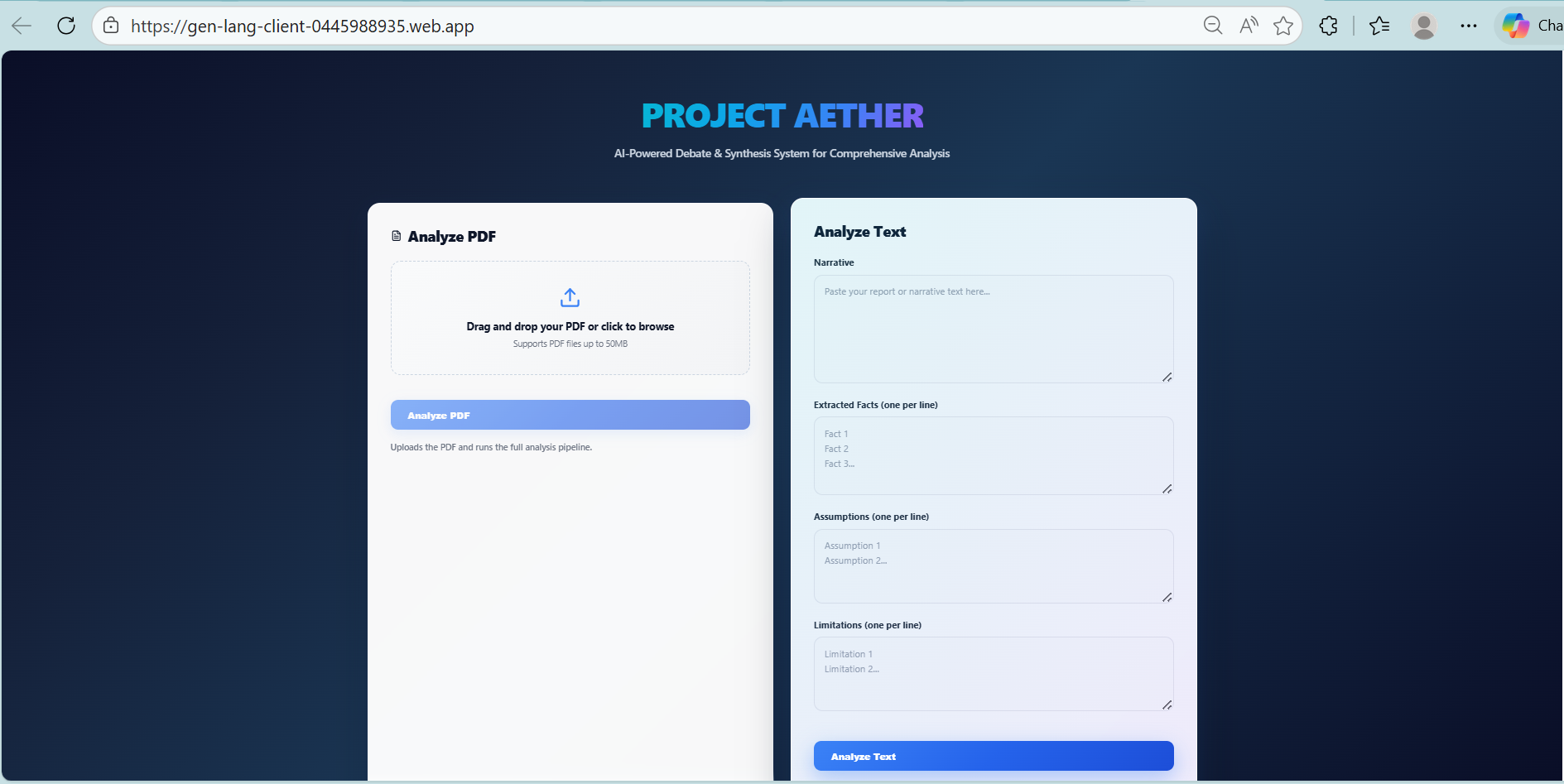
Project AETHER is a coordinator-driven multi-agent AI system that performs structured debate, opposition, and synthesis over business documents and structured data.
Workflow:
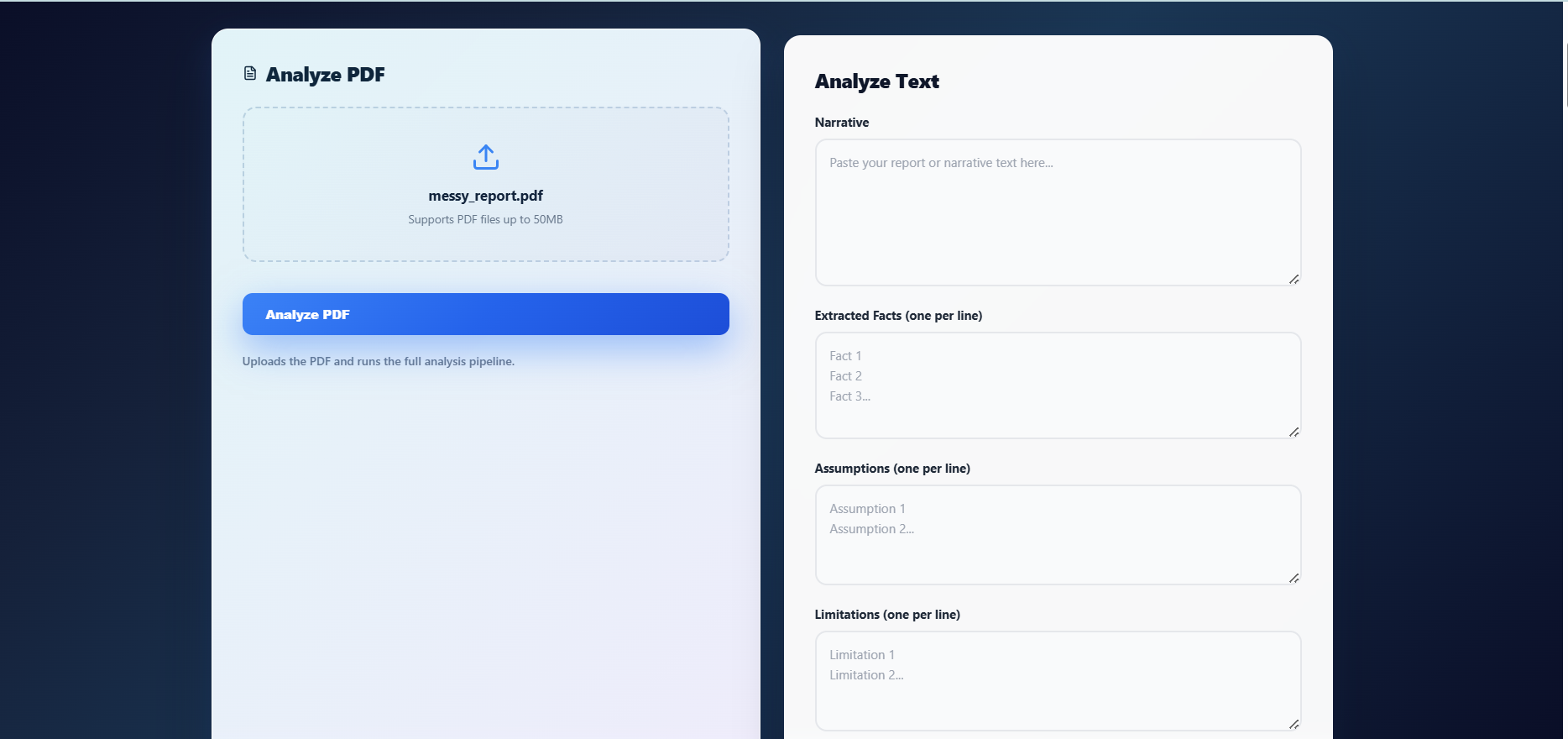
Users upload a PDF document or provide structured input
A factor extraction agent identifies debatable points
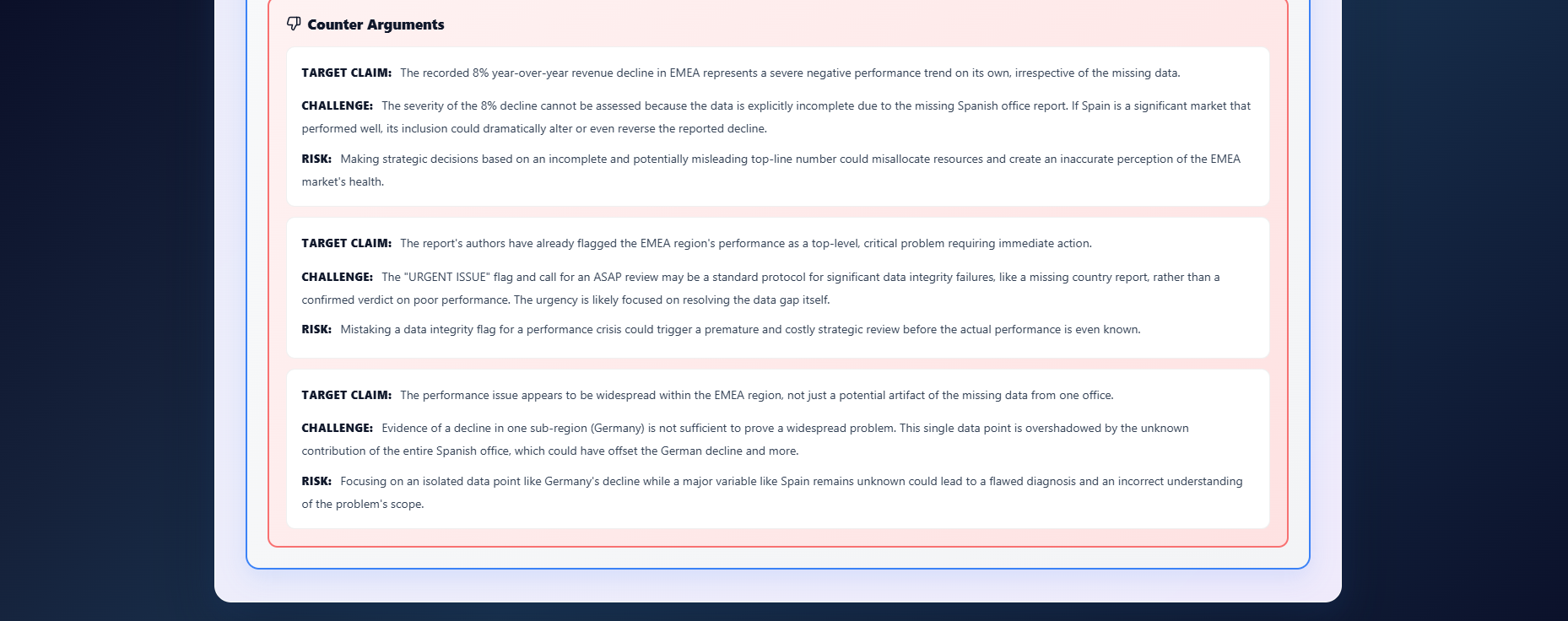
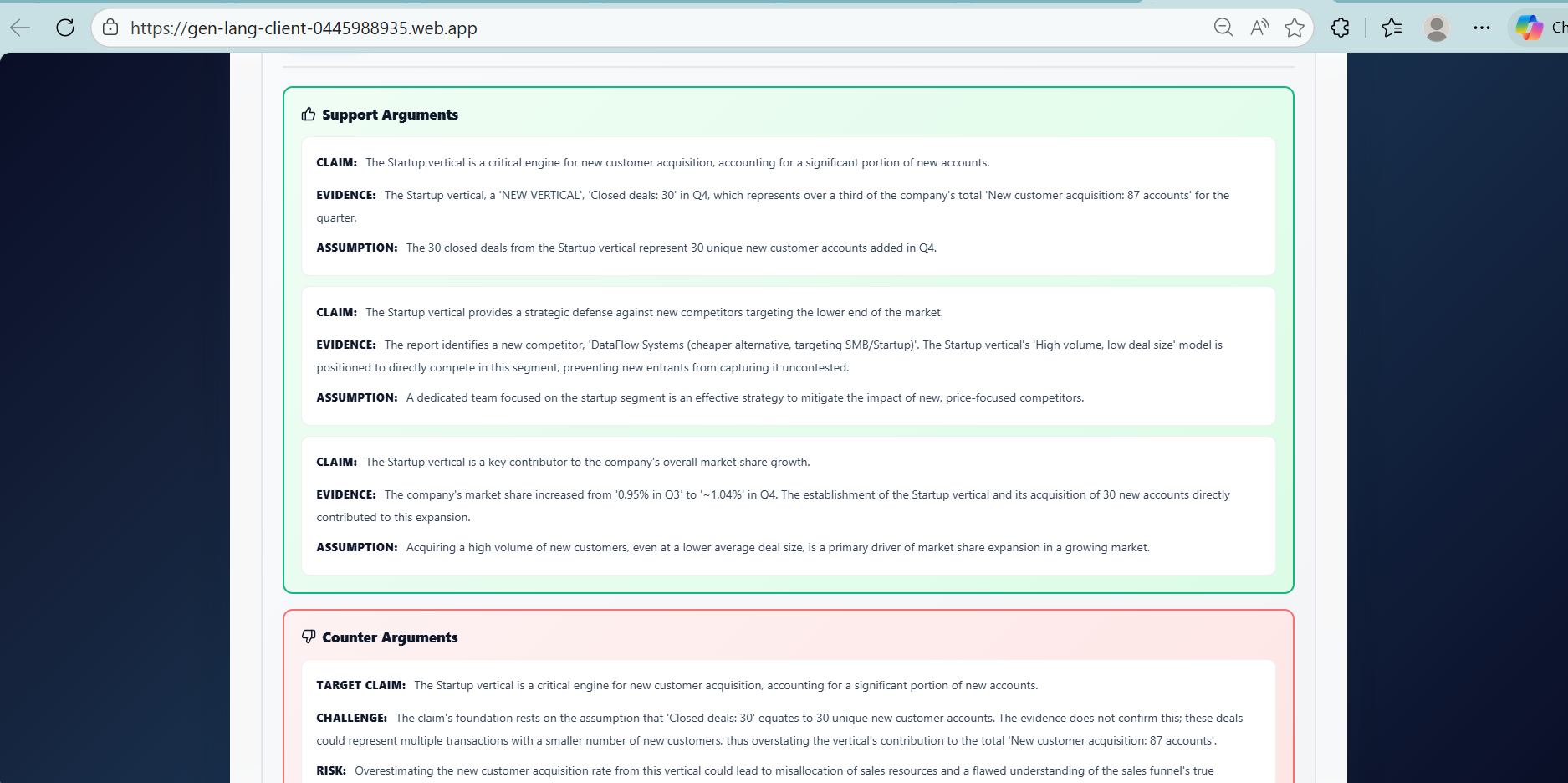
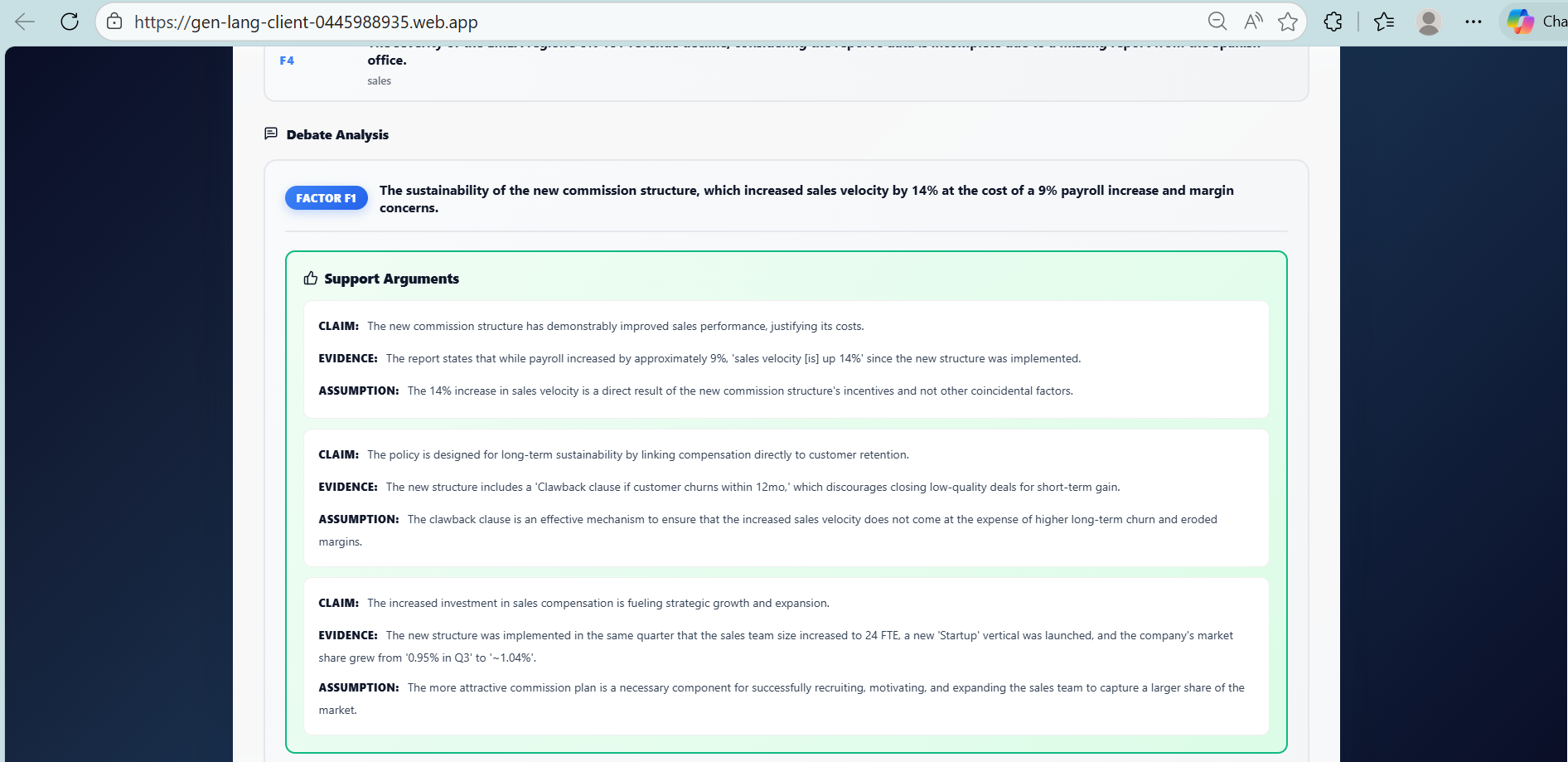
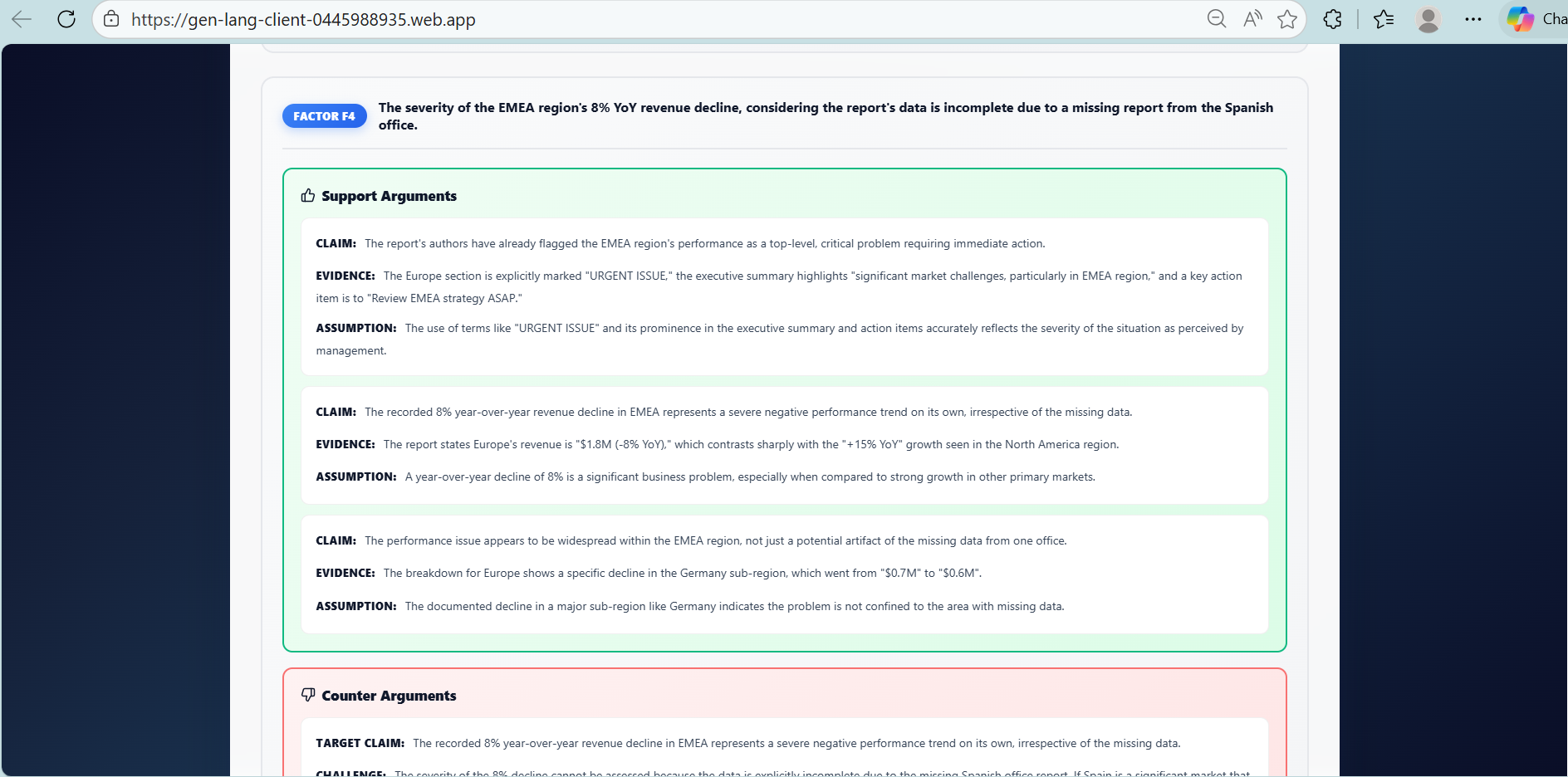
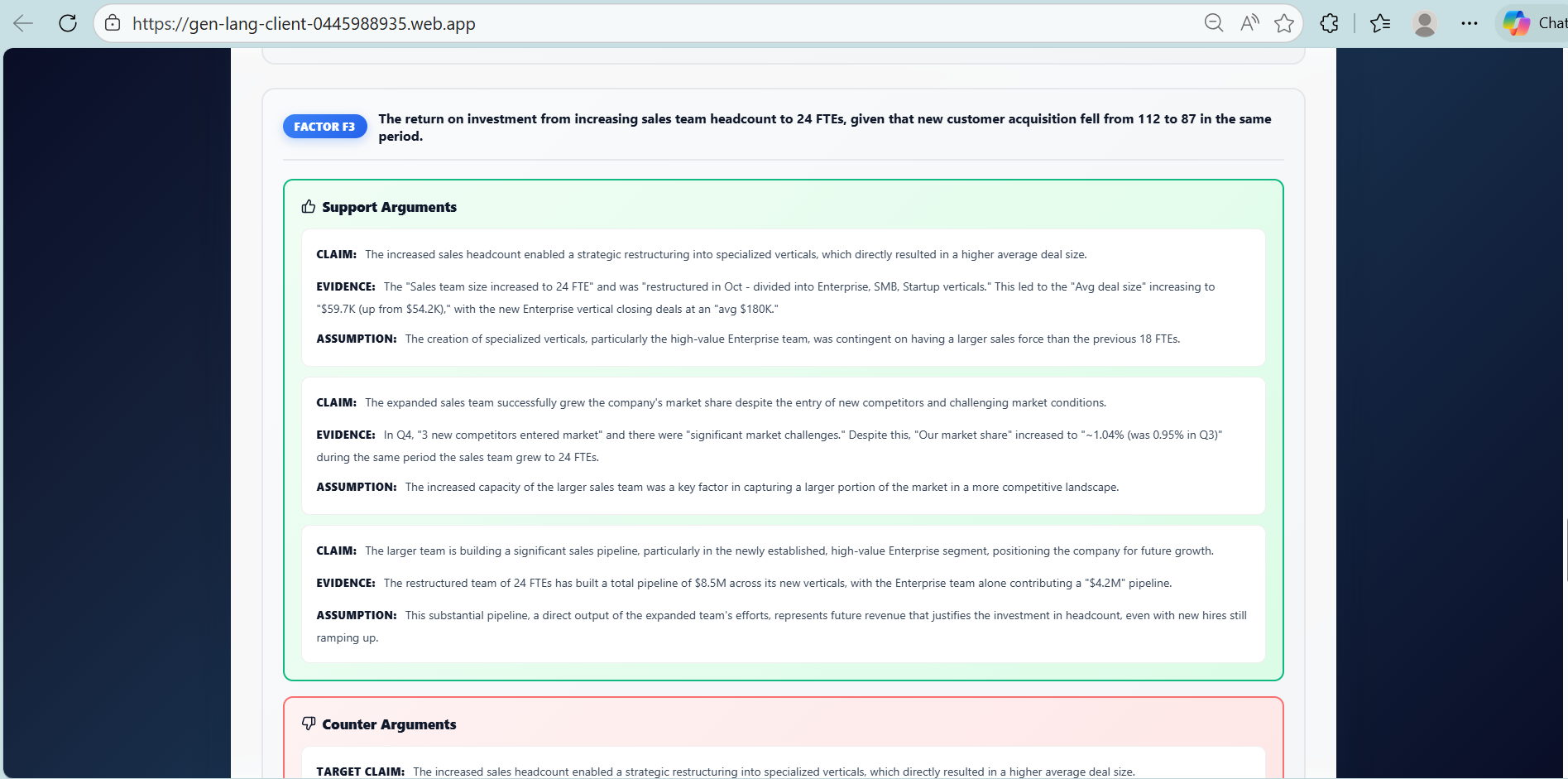
A support agent generates evidence-backed arguments
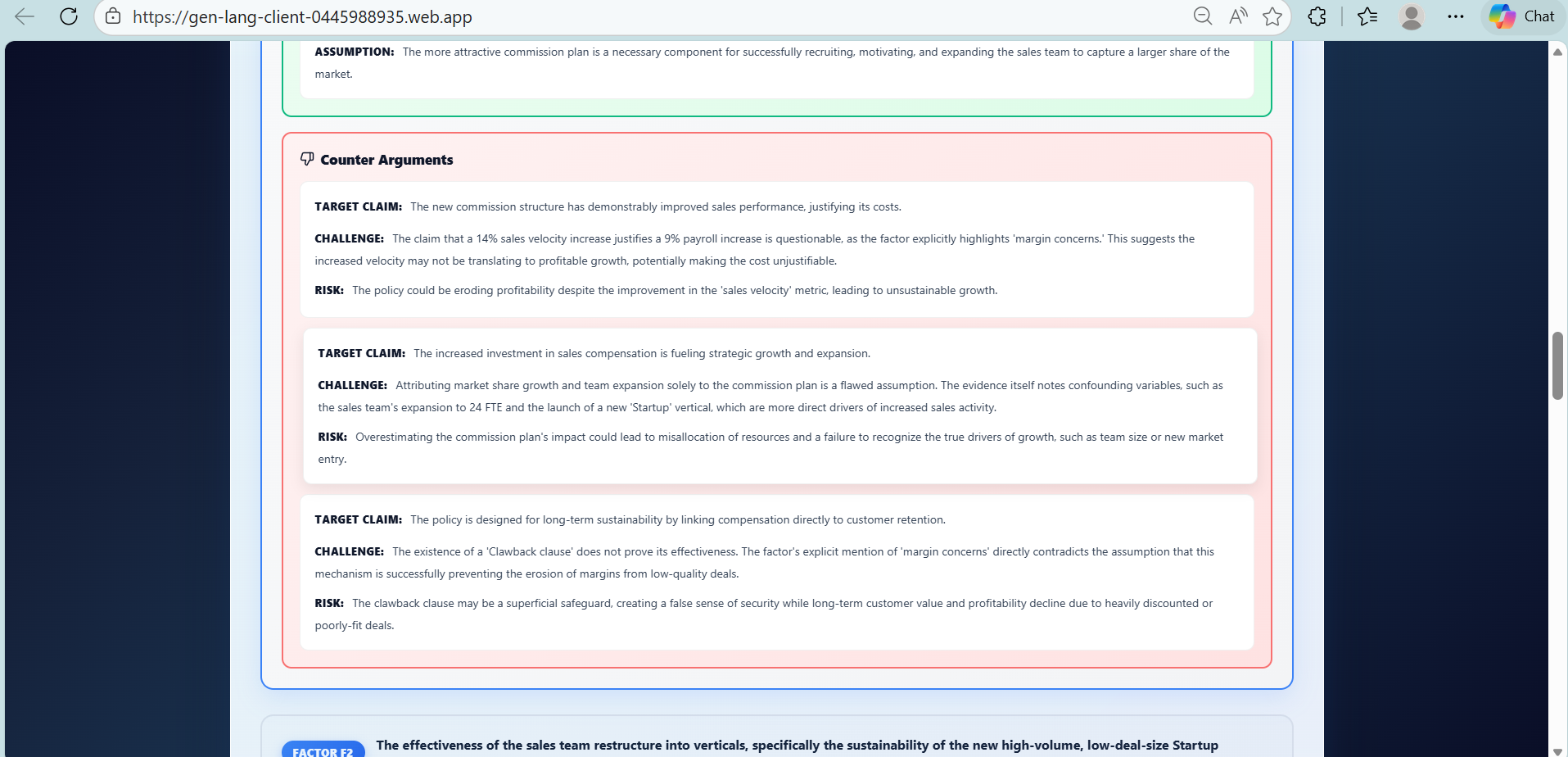
An opposition agent challenges each argument
A synthesizer agent combines all perspectives into a final report
Key features:
PDF text and table extraction
Multi-agent architecture with strict orchestration
Structured debate for every identified factor
Automatic metric extraction from tables
Professional PDF report generation
Transparent reasoning with full JSON logs
Domain-aware categorization (sales, policy, statistics, organization)
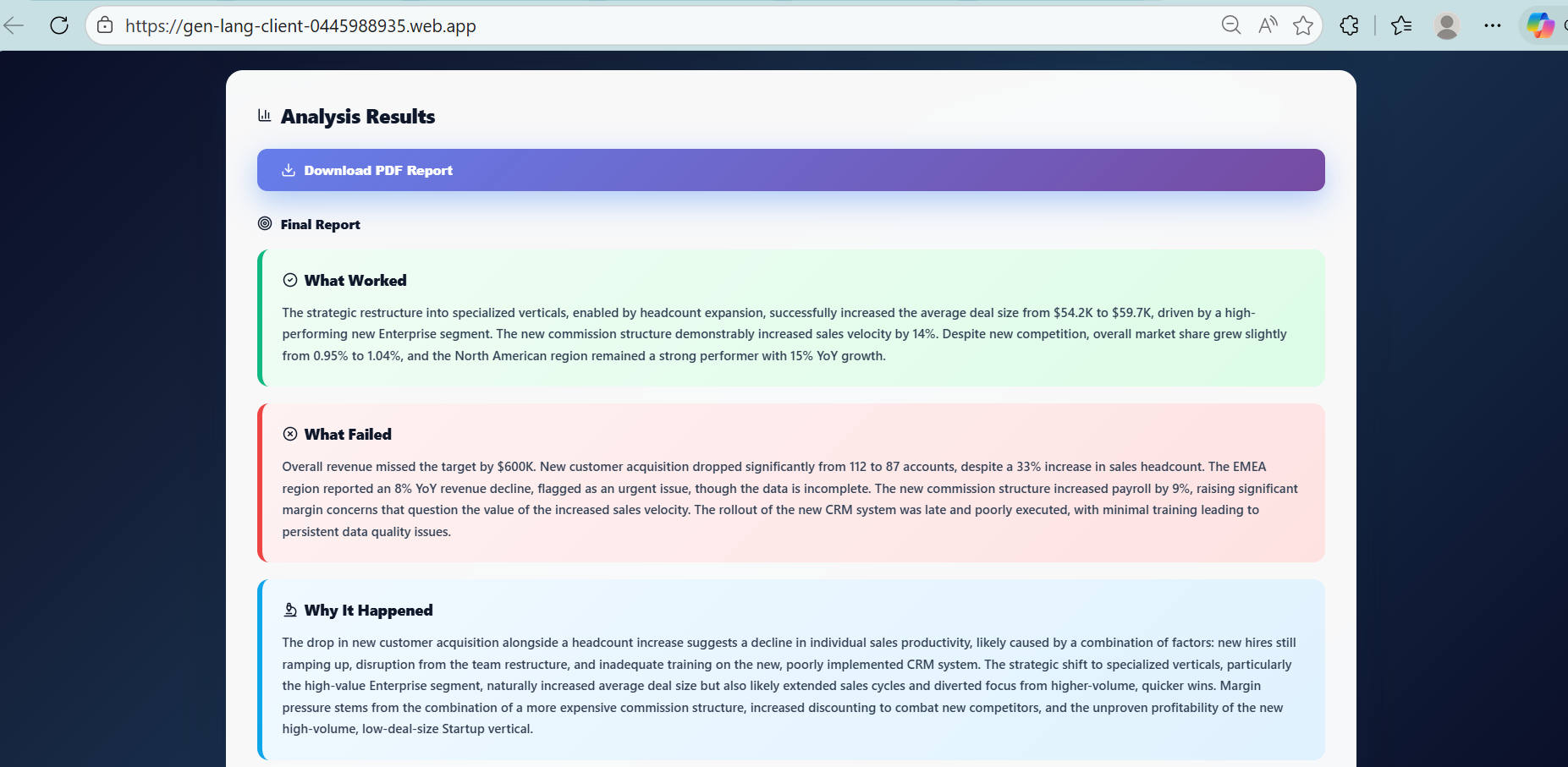
The output is a comprehensive analysis showing:
What worked and what did not
Why outcomes occurred, with evidence
Actionable recommendations
Confidence scores for synthesized conclusions
Mathematical foundation:
Final confidence score is calculated as a weighted average of individual factor confidences.
Debate quality is evaluated based on the balance between supporting arguments, opposing arguments, and extracted factors.
HOW WE BUILT IT
Technology Stack
Backend:
Python 3.10+
FastAPI
Pydantic v2
Google Gemini via Vertex AI
PyPDF2 for PDF text extraction
Camelot for table extraction
ReportLab for PDF report generation
Frontend:
React 19
Vite
CSS3
Fetch API
Infrastructure:
Google Cloud Platform (Vertex AI)
Structured JSON logging
Architecture Principles:
No direct agent-to-agent communication
Deterministic execution flow
Strict schema validation for all outputs
Graceful degradation for optional features
Context-bound reasoning to prevent hallucination
Execution Flow: Request → Validation → PDF Processing (optional) → Factor Extraction → Support Agent → Opposition Agent → Synthesizer Agent → JSON response and PDF report
CHALLENGES WE RAN INTO
Agent hallucination prevention LLMs can generate plausible but incorrect information. We enforced strict context binding so agents can only reference provided inputs. All outputs are validated against the input context.
PDF table extraction PDF tables have no standard structure. We used multiple parsing strategies and implemented graceful fallback behavior so failures do not break the pipeline.
Orchestration complexity Managing dependencies across multiple agents required a centralized orchestrator enforcing execution order and state transitions.
Debate quality control Some counter-arguments were weak or generic. We refined prompts to require targeted challenges, evidence-based reasoning, and risk assessment.
JSON parsing reliability Malformed JSON responses were handled with retry logic and strict schema validation using Pydantic.
Performance optimization Sequential LLM calls increased latency. We optimized using async execution, connection reuse, and reduced token usage.
ACCOMPLISHMENTS THAT WE’RE PROUD OF
Built a zero-hallucination, context-bound AI pipeline
Created a meaningful debate-based reasoning system
Implemented robust PDF and table processing
Designed a clean and extensible agent architecture
Delivered production-ready error handling and validation
Generated professional, presentation-ready PDF reports
WHAT WE LEARNED
Technical learnings:
Prompt engineering directly impacts system reliability
Schema validation significantly reduces debugging time
Async Python patterns are essential for LLM pipelines
Centralized orchestration simplifies multi-agent systems
PDFs require defensive programming and fallbacks
Conceptual learnings:
Structured opposition improves reasoning quality
Transparency increases user trust
Context grounding is essential for practical AI systems
Process learnings:
Iterative development enables complexity growth
Early validation prevents large refactors
Documentation accelerates collaboration
WHAT’S NEXT FOR AETHER
Short-term:
OCR support for scanned PDFs
Chart and graph extraction
Multi-language document support
Analysis history and version comparison
Parallel agent execution
Medium-term:
Custom domain-specific agents
Human-in-the-loop interactive debate
Advanced confidence trend tracking
Expanded REST APIs
Enhanced report customization
Long-term:
Collaborative multi-user workspaces
Memory layer for learning across analyses
LLM-agnostic provider support
Enterprise features such as audit logs and role-based access
Educational mode for teaching critical thinking

Log in or sign up for Devpost to join the conversation.