-
-

cover_image
-

team_member
-

outline
-

preprocessing
-

features_engineering
-

models
-

improvements
-
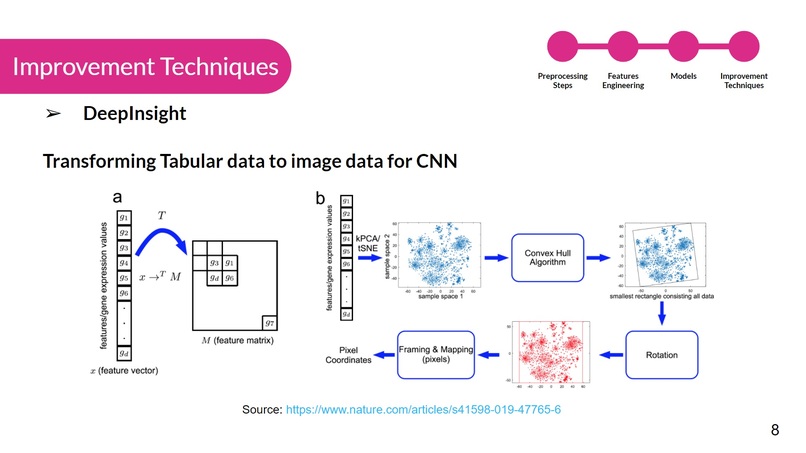
deep_insight
-

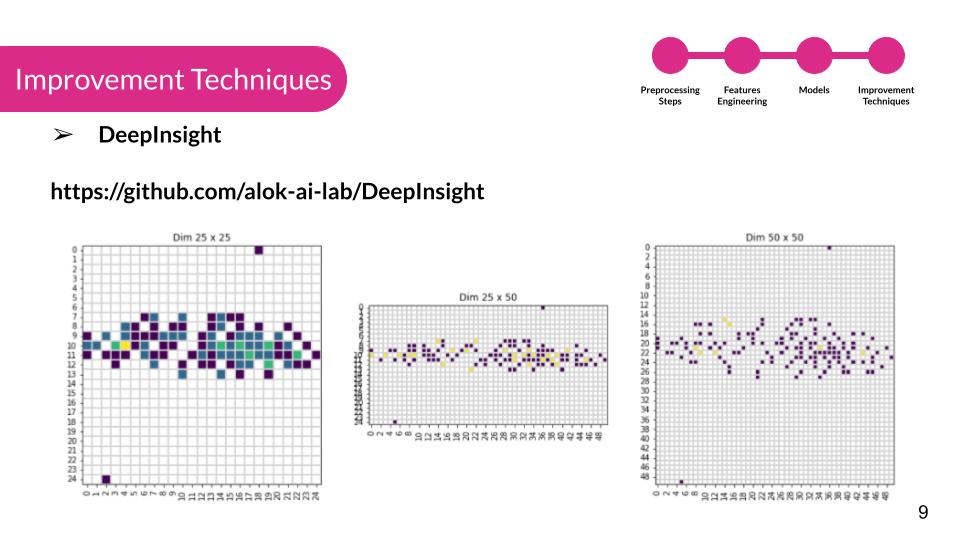
image_from_deep_insight
-

cnn_architecture_for_deep_insight
-

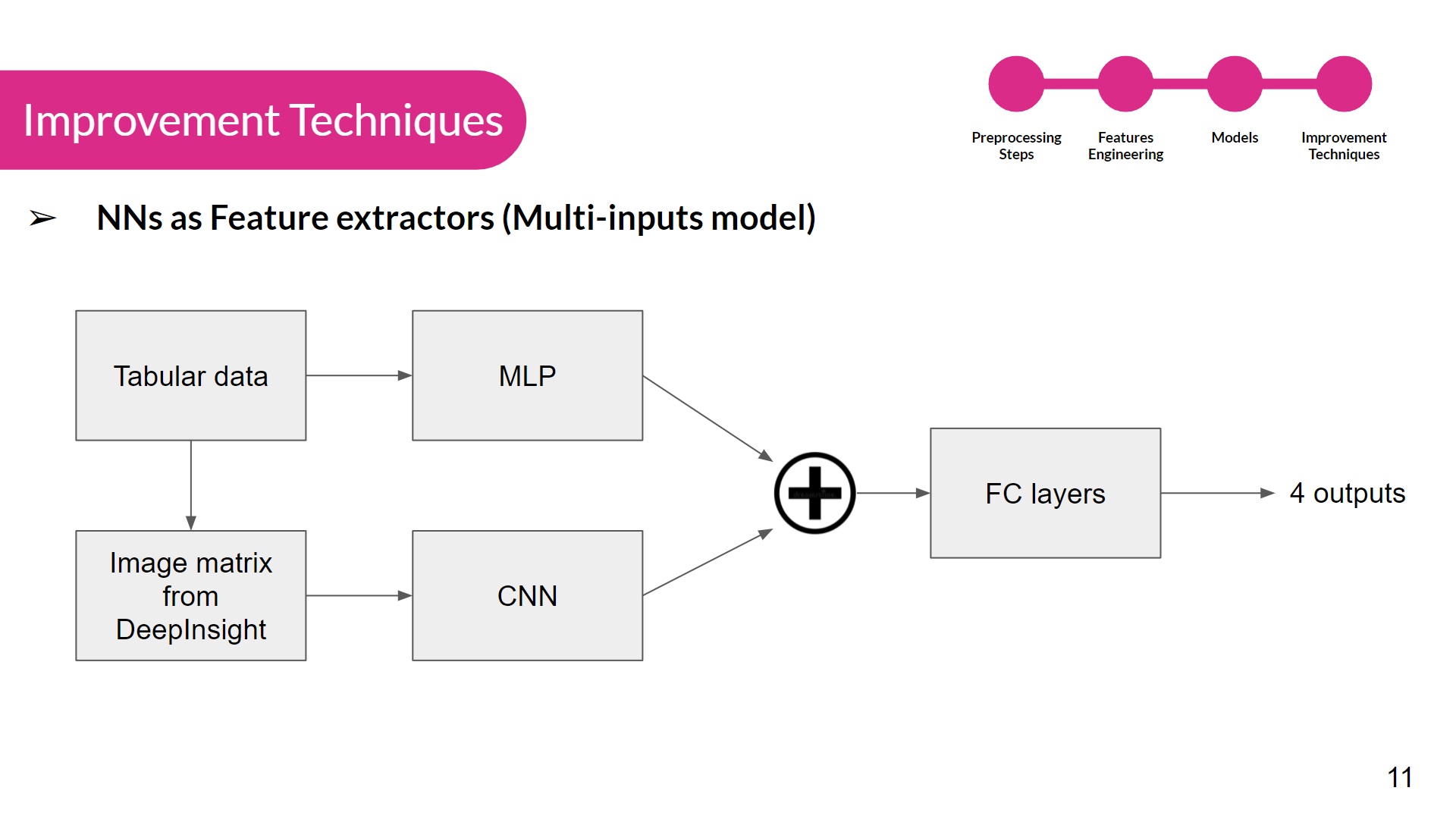
multi_inputs_model
-

features_importance
-

THANK_YOU











Inspiration
It's exciting to see how we can advance the chemistry field by leveraging the power of machine learning. Moreover, it would be fun to compete with other great competitors all around Thailand. That's why we formed the team and jumped in to do this work. :)
What it does
It's a machine learning model to predict the CO2 working capacity of Metal-organic frameworks (MOFs).
Extra files
Data
- train.csv (original train set): click
- test.csv (original test set): click
- train_extra_2.csv (train set with new features we built): click
- test_extra_2.csv (test set with new features we built): click
- train_feats_from_di_cnn.csv (train features from DeepInsight CNN model): click
- test_feats_from_di_cnn.csv (test features from DeepInsight CNN model): click
- train_feats_from_comb_cnn.csv (train features from Multi-Inputs model): click
- test_feats_from_comb_cnn.csv (test features from Multi-Inputs model): click
- atom_mass_vol_area.csv (features of each element in periodic table that we found and calculated): click
Models
- deepinsight_cnn.h5 (CNN trained with 50x50 pixels image data from DeepInsight with prediction head): click
- deepinsight_cnn_80_80.h5 (same with the one above but with 80x80 pixels image): click
- di_cnn_feats_ext.h5 (CNN trained with DeepInsight images without prediction head): click
- combined_deepinsight_cnn_50_50.h5 (Multi-Input model trained with 50x50 pixels images from DeepInsight with prediction head): click
- combined_di_cnn_feats_ext.h5 (same with the one above but without prediction head): click
How we built it
We'd like to break down our processes into 4 main steps; Preprocessing, Features Engineering, Modelling, and Model Improvement.
1. Preprocessing
- Dropping some serious outliers: From doing EDA, we found out that volume [A^3] > 100,000 and CO2/N2_selectivity > 10,000 are serious outliers. So, we decided to drop them out. Totally, we dropped 11 rows of the training set.
- Fill invalid values: There are a lot of missing values and invalid values to be concerned about. We started by filling void_volume with formula "void_volume = void_fraction / density". It turned out, for some rows, void_fraction is also missing along with void_volume. So, this formula doesn't work for all rows. After that, from several experiments, we decided to fill the rest of void_volume with 76.5th quantile which is 0.4734. When we had filled all rows of void_volume, the void_fraction column became easy to fill since we could converse the last formula to find void_fraction. We filled void_fraction with formula "void_fraction = density * void_volume". Lastly, again from a lot of experiments, we decided to fill heat_adsorption with the min value which is 1.6123.
- Surface_area imputation: We've found that the Monte Carlo approach to calculate surface_area took too much time to get done. So, we tried other ways to fill in this value and it turned out imputation gave the best result. We did impute surface_area by using the MICE method with a lot of features which are volume, weight, void_volume, CO2/N2_selectivity, n_atoms, and charges
2. Features Engineering
We built a total of 9 extra features apart from the original ones (+ 15 more features from NNs)
- density [g/cm^3] : ( weight [u] / volume [A^3] ) * 1.66054
- volume [cm^3/g] : volume [A^3] / ( weight [u] * 1.66054 )
- n_atoms : number of atoms in MOF unit cell
- mol_avg_mass [u] : weight [u] / n_atoms
- charges : ⅀common_charges
- mol_avg_radius [pm] : ( ⅀atom_radius[pm] ) / n_atoms
- atoms_volume [A^3] : ⅀( 4 * Pi * atom_radius[A]^3 ) / 3
- atoms_area [A^2] : ⅀( 4 * Pi * atom_radius[A]^2 )
- specific_heat [J/g.K] : ( heat_adsorption[kcal/mol] * 4.186 * 1000 ) / ( weight * ⋀Temp[K] )
3. Models
We have trained and tested a lot of models to find the best ones. Here are our Best 3 models according to the LMAE score of phase 2's test set: LightGBM, MLP (sklearn's implementation), and GradientBoosting.
4. Model improvement
We have experimented with a lot of techniques to improve our score and sadly 90-95% of them are NOT WORKING. Here are our techniques that worked for our models (please take a look into the .ipynb files for implementation detail):
- Hyperparameters tuning with Optuna
- Weighted average Ensemble
- DeepInsight - Transforming non-image data into image data for CNN
- Neural Networks as Feature Extractors - After we trained the CNN with image data from DeepInsight, it turned out the result is a bit worse than LightGBM (which is our best model) but it's not that bad. We came up with the idea that CNN might have learned something useful even its prediction is worse. So, we cut off the prediction head at the end and get the output from the layer before instead, then feed those output into training data for other models and it worked quite well.
- Multi-inputs models - The same idea from the one above, but we increase the complexity of the model to let the model learn something more meaningful by creating 2 inputs head and passed them into 2 different architectures, MLP and CNN, before concatenating them and output 4 new feats.
Challenges we ran into
- The libraries we used to transform .cif file into SMILES representation transform into the wrong SMILES (a lot of missing atoms). So, there are many features we planned to used, but they ended up not working.
- A lot of missing and invalid values, and they are difficult to fill in.
- We have only 1 member with chemistry knowledge.
- A lot of competitors are so freaking good.
Accomplishments that we're proud of
We are more likely to use a data-centric approach than a model-centric approach (just keep increasing the complexity of the model). That makes our work might be useful in the real-working environment/research and the model is not too complicated to reproduce. We have built a lot of new meaningful features and they increased the model performance significantly.
What we learned
There are too many things that we have learned to be addressed here. Some of them, we have already discussed in the sections above. But, most importantly, we have learned to be better team players and machine learning practitioners.
What's next for วัยรุ่นอเมริกา
Keep going, never give up, and never lose hope. Today is just not our day, but one day it will be ours. :D











Log in or sign up for Devpost to join the conversation.