-
-

Team members: เหล่าวัยรุ่นทำปัญญาประดิษฐ์
-
Results: LMAE Heatmap of All Model-Representation Combinations
-
Results: LMAE Heatmap of All Model-Representation Combinations

Inspiration
สมาชิกในกลุ่มแต่ละคนได้ช่วยกันศึกษาชนิดและประสิทธิภาพของ machine learning model และ features representation ในรูปแบบต่าง ๆ จากงานวิจัยที่เกี่ยวข้อง และนำมาประยุกต์ในการสร้างโมเดลเพื่อใช้กับ representation ต่าง ๆ เพื่อหา machine learning model และ features representation ที่มีค่า LMAE จากการทำนาย working capacity ของ MOF แต่ละตัวน้อยที่สุด
What we do
กลุ่มของเราประยุกต์ algorithm ที่มีอยู่ก่อนหน้าและสร้าง Representation ของข้อมูลด้วยเทคนิคต่าง ๆ ได้แก่
- preprocessing โดยกำหนดค่าตัวเลขให้ metal group, metal element, functional group และ organic linkers ของ MOF แต่ละตัว
- binary matrix ของ functional group
- word embedding ของ functional group
- PCA ของ linear AP-RDF และ PCA ของ constant AP-RDF
- PCA ของ coordinates
- PCA ของ Bag of Atoms
โดยเลือก features ที่น่าจะมีผลต่อ working capacity มากที่สุดมาสร้าง representation สุดท้าย
Machine Learning model ในรูปแบบต่าง ๆ ได้แก่
- CatBoostRegressor
- XGBRegressor
- LightGBMRegressor
- RandomForestRegressor
- ExtraTreesRegressor
- GradientBoostingRegressor
- AdaBoostingRegressor
- Neural Networks
รวมไปถึงการประยุกต์เทคนิค Ensemble Method ในการรวมหลาย model มาใช้ในการทำนาย working capacity ของ MOF แต่ละตัว โดยโมเดลแต่ละชนิดกลุ่มของเราได้ปรับ parameter ของแต่ละโมเดลเพื่อประยุกต์เทคนิค GridSearch ในการหา parameter ที่ได้ผลดีที่สุด นอกจากนี้ กลุ่มของเราใช้ Optuna เพื่อปรับค่า hyperparameter ที่ดีที่สุดในการทำนายผลเพิ่มเติมอีกด้วย
จากนั้นนำโมเดลต่าง ๆ มาหาค่าความคลาดเคลื่อน (LMAE) จากการทำนาย working capacity ของ MOF แต่ละตัว โดยใช้ representation ของ features ที่ต่างกัน
ทั้งนี้ เพื่อการทดลองนำ representation ต่าง ๆ มาจับคู่กับโมเดลต่าง ๆ เป็นไปได้ง่ายขึ้น เราทำการสร้างโปรแกรมสำหรับการทดลองขึ้น (ดูที่ลิงก์นี้) ซึ่งทุกคนสามารถเข้าไปทดลองกับ representation หรือโมเดลของตัวเองได้ด้วยเช่นกัน ตามวิธีที่อธิบายไว้อยู่ในหน้าเว็บของ repository ซึ่งหวังว่าเครื่องมือนี้จะทำให้การค้นคว้าหา representation และโมเดลต่าง ๆ มีประสิทธิภาพยิ่งขึ้นสำหรับทุก ๆ คนในอนาคต
ตัวอย่างการรันโค้ดที่ทำการ train XGBRegressor แบบใช้ GridSearchCV โดยใช้ representation แบบ preprocessed กับ linear AP-RDF ร่วมกัน (หากต้องการใช้มากกว่านี้ สามารถเพิ่ม argument ต่อจาก linearAP-RDF ได้เลย) ซึ่งโมเดลที่ train เรียบร้อยแล้วจะถูกบันทึกไว้ในโฟลเดอร์ results เพื่อใช้สำหรับทำนาย test set ต่อไป
python main.py --reps preprocessed linearAP-RDF --model xgb --directory results --grid_search
How we built
ทุกโปรแกรมที่ใช้สร้าง representation และ machine learning model ถูกเขียนด้วยภาษา Python โดยนำ library หลายชนิดมาประยุกต์ใช้ เช่น
- numpy: ใช้จัดการการคำนวณตัวเลขและ matrix transformation
- pandas: ใช้จัดการ dataframe
- octadist: ใช้ศึกษาโครงสร้างของสารประกอบโลหะทรงแปดหน้า (octahedron)
- openbabel: ใช้แปลง .cif มาเป็น smile
- sklearn: ใช้จัดการ machine learning model
- tensorflow: ใช้สำหรับโมเดล neural network
- xgboost, lightgbm, catboost, nn: machine learning model ที่ใช้ทำนาย working capacity ของ CO2
- altair: ใช้สร้าง heatmap เพื่อนำเสนอค่าความคาดเคลื่อน LMAE ของการทำนาย Working Capacity ของ MOF
- gensim: ใช้สำหรับการสร้างเวกเตอร์ของคำในการ represent feature แบบ word embedding
Results and Conclusion
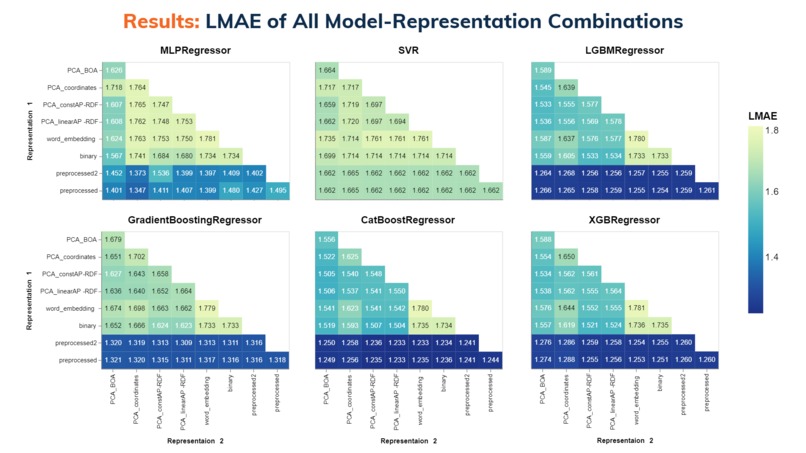
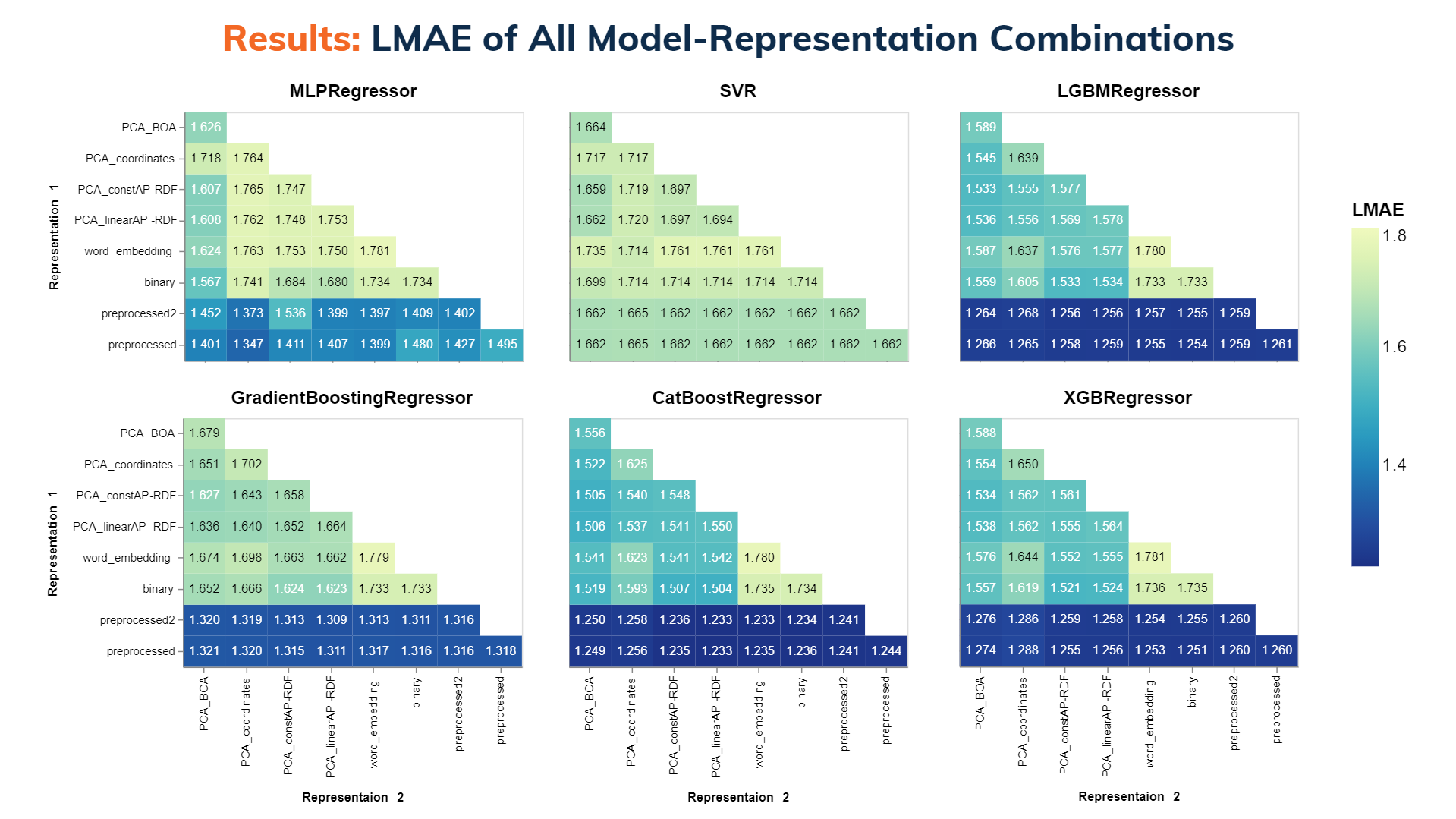
จากการทดลอง พวกเราได้พบว่า ชนิดของโมเดล Machine Learning ที่ใช้และรูปแบบการนำเสนอข้อมูล (representation) ที่ต่างกันออกไปมีผลกับค่าความคลาดเคลื่อน (LMAE) ของการทำนาย Working Capacity ของ MOF ต่าง ๆ อย่างเห็นได้ชัด โดยพวกเราได้นำเสนอข้อมูล LMAE ของแต่ละโมเดลและ representation ที่ต่างกันออกไปในรูปแบบของ Heatmap โดยใช้ Altair python library พวกเราได้ข้อสรุปต่าง ๆ ดังนี้
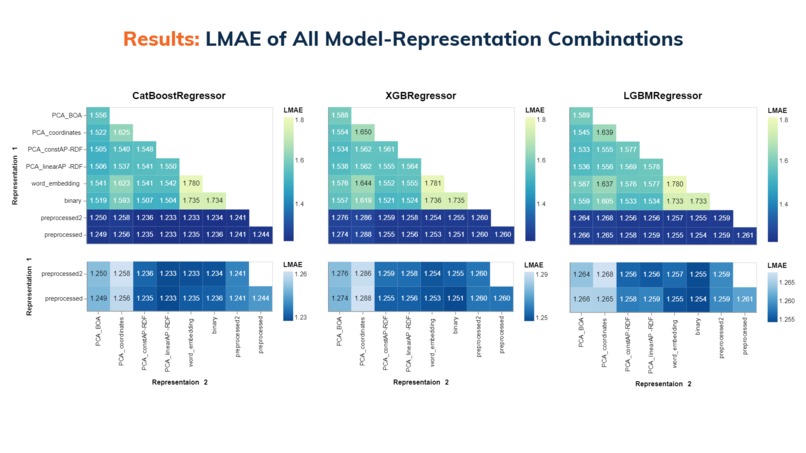
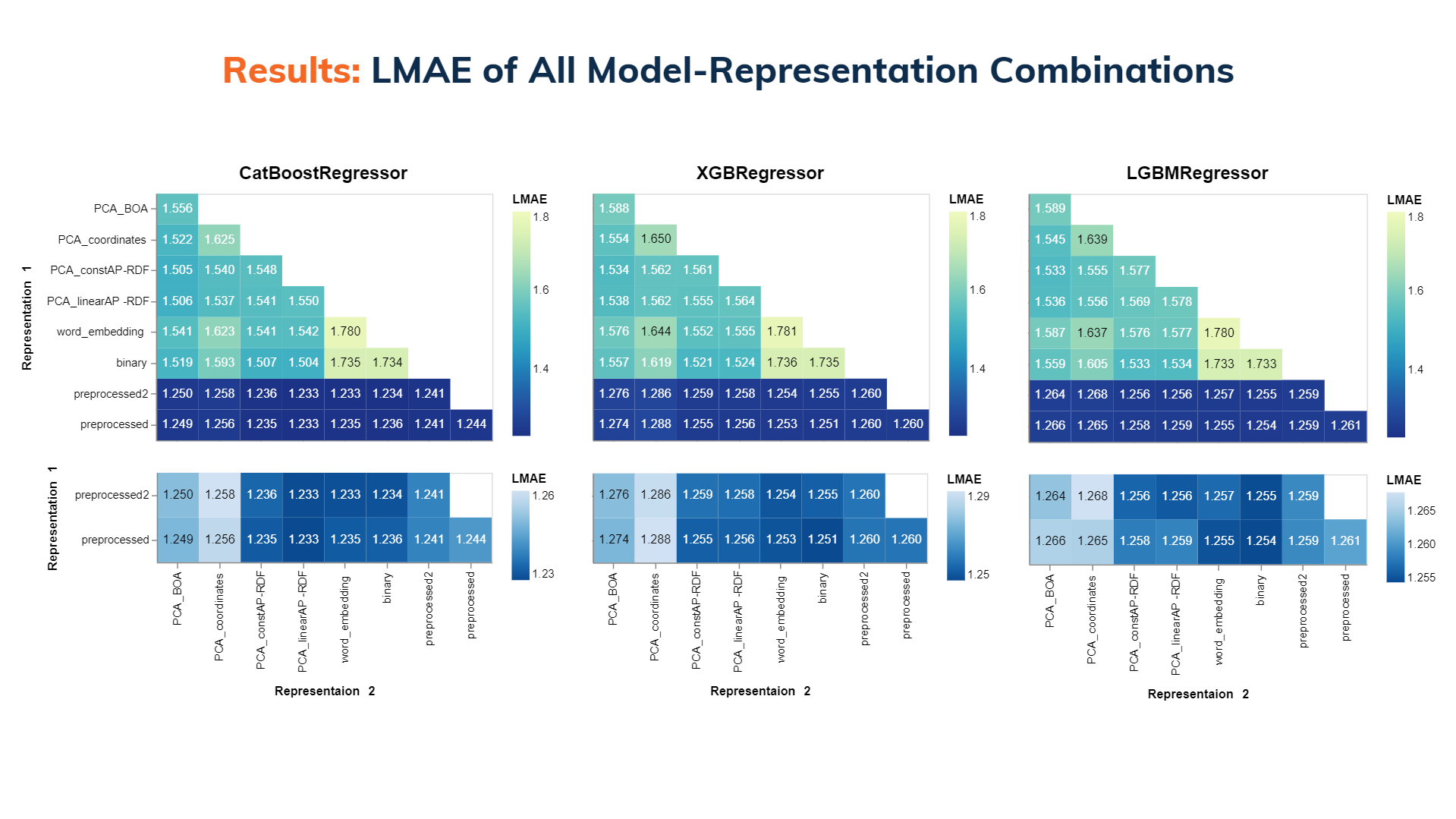
- โมเดลจำพวก Decision Tree เช่น CatBoostRegressor, XGBRegressor, และ LightGBMRegressor เป็นโมเดลที่ใช้ได้ดีกับข้อมูลต่าง ๆ ที่พวกเรามีอยู่
- Representation ที่มีชื่อว่า preprocessed และ preprocessed2 เป็น representation ที่นำค่าต่าง ๆ จากไฟล์ .csv มาใช้โดยตรง จะเห็นได้ว่าค่า LMAE ของ representation สองตัวนี้หรือการรวมกันที่มี representation อันใดอันหนึ่งในนี้จะให้ค่า LMAE ที่น้อยที่สุด โดยจะอยู่ในช่วง 1.23 - 1.29
- นอกจากนั้นเพื่อพัฒนาความสามารถของ ML สามตัวดังกล่าว เราใช้ Optuna ซึ่งเป็น library ที่สร้างบน python เพื่อปรับ hyperparameter ในแต่ละโมเดล เราค้นพบว่าค่าความคลาดเคลื่อน (LMAE) ลดลงอย่างมีนัยสำคัญ เมื่อเราได้ทดสอบกับข้อมูลที่มี preprocessed และ preprocessed2 ค่า LMAE จะลดลงอยู่ในช่วง 1.229 - 1.240
สุดท้ายนี้ เราได้ทดลองใช้ voting ensemble ในการเฉลี่ยผลลัพธ์จากการทำนาย working capacity ของ MOF ที่ได้จากโมเดล 3 ตัวที่ดีที่สุด เราได้พบว่าการใช้ ensemble สามารถลดการ overfitting ของข้อมูลได้และให้ค่า LMAE อยู่ที่ 1.222 ซึ่งเป็นผลลัพธ์ที่ดีที่สุดของทีม
Challenges we ran into
เนื่องจากสมาชิกในทีมแต่ละคนมีพื้นฐานทางความรู้ที่แตกต่างกันมาก เราแก้ไขปัญหานี้โดยการอธิบายหลักการทางเคมี แลกเปลี่ยนความรู้ สอนการใช้งานโปรแกรมเบื้องต้น ลดความซับซ้อนของโปรแกรม และ มีการสรุปความคืบหน้าคร่าว ๆ ในทุกครั้งของการประชุม นอกจากนี้ช่วงเวลาที่สะดวกของสมาชิกในทีมไม่ตรงกันเนื่องจากการสอบในมหาวิทยาลัยและ timezone ของแต่ละคน เนื่องจากการเข้าใจอุปสรรคของสมาชิกแต่ละคนพร้อมกับความตั้งใจในการแข่งขันครั้งนี้ ทีมของเราสามารถก้าวข้ามและประสานงานได้ราบรื่น
Accomplishments that our group proud of
จากการแลกเปลี่ยนความรู้และการได้ฝึกฝนการเขียนโปรแกรม สมาชิกในทีมได้รับความรู้และประสบการณ์จากการแข่งขันครั้งนี้ซึ่งจะช่วยให้การทำงานทางด้าน coding และ representation ข้อมูลในอนาคตง่ายมากขึ้น รวมถึงการประยุกต์ใช้โปรแกรม ML กับความรู้แขนงอื่น ๆ
What we have learnt
- ประสบการณ์เกี่ยวกับการนำ ML มาประยุกต์ใช้ในโจทย์เคมี
- การนำเสนอข้อมูลทางเคมีในรูปแบบที่คอมพิวเตอร์สามารถเข้าใจและนำไปใช้ต่อได้
- ความรู้เกี่ยวกับ Metal Organic Framework
- Deepnote กับ tensorflow มี negative synergy กัน การใช้งานอาจยังไม่เสถียรมากนัก








Log in or sign up for Devpost to join the conversation.