

Treble Trouble
Hum your orchestra. Conduct with your hands. Publish to the studio.
What is this?
Most composition tools assume you can already play instruments, read notation, or operate a DAW. Composing music has a steep on-ramp that filters out the people who actually have music stuck in their head and want to get it out.
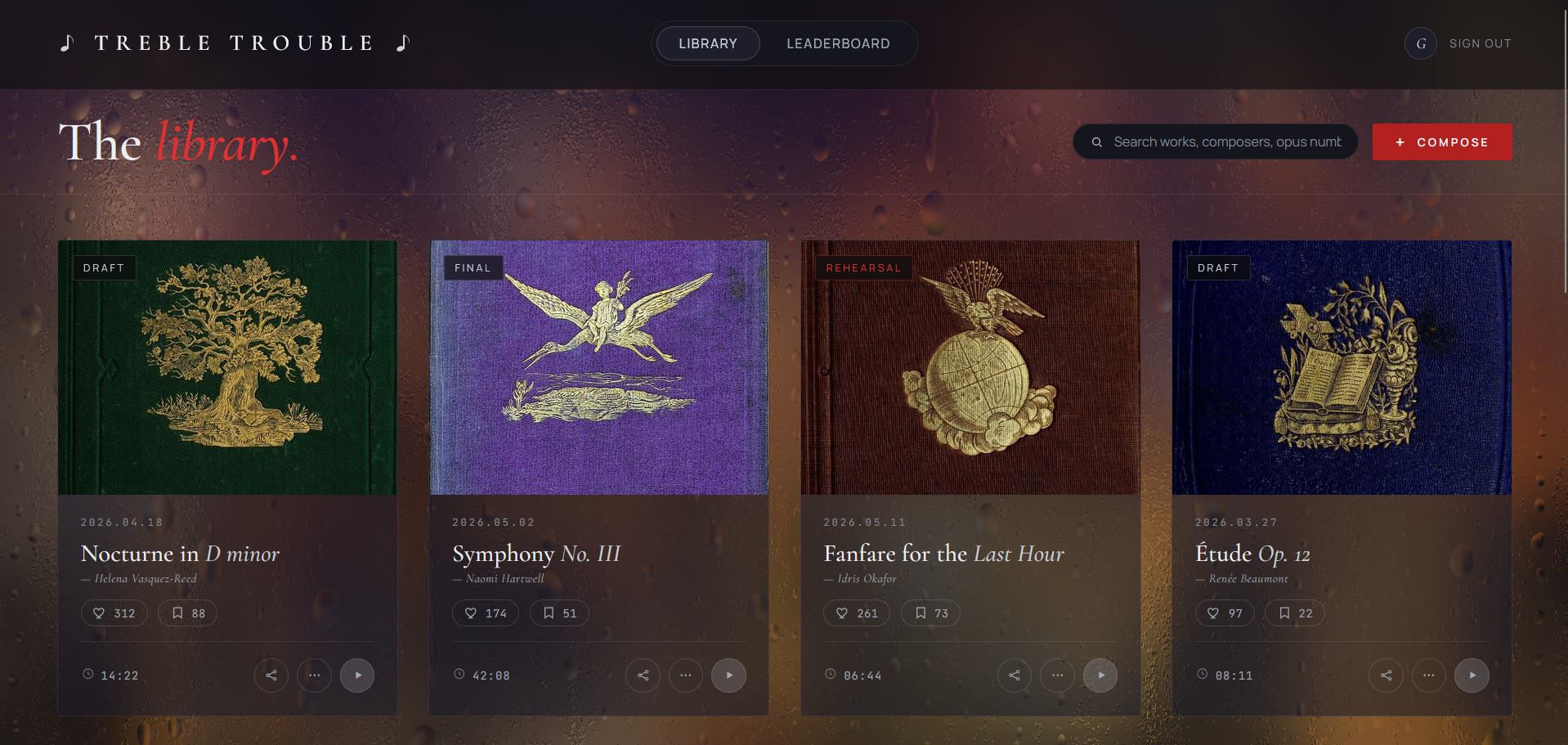
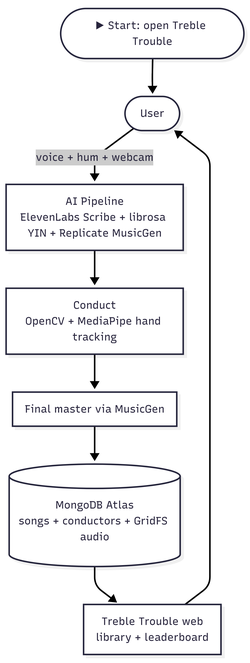
Treble Trouble assumes nothing. You hum four parts (piano, trumpet, violin, drums) into a microphone. The system turns each hum into a stem in the correct instrument, snaps timing to a shared grid, and hands the mix to you to conduct in front of a webcam. Wrist position selects the instrument, hand height controls the volume, a held fist commits the take.
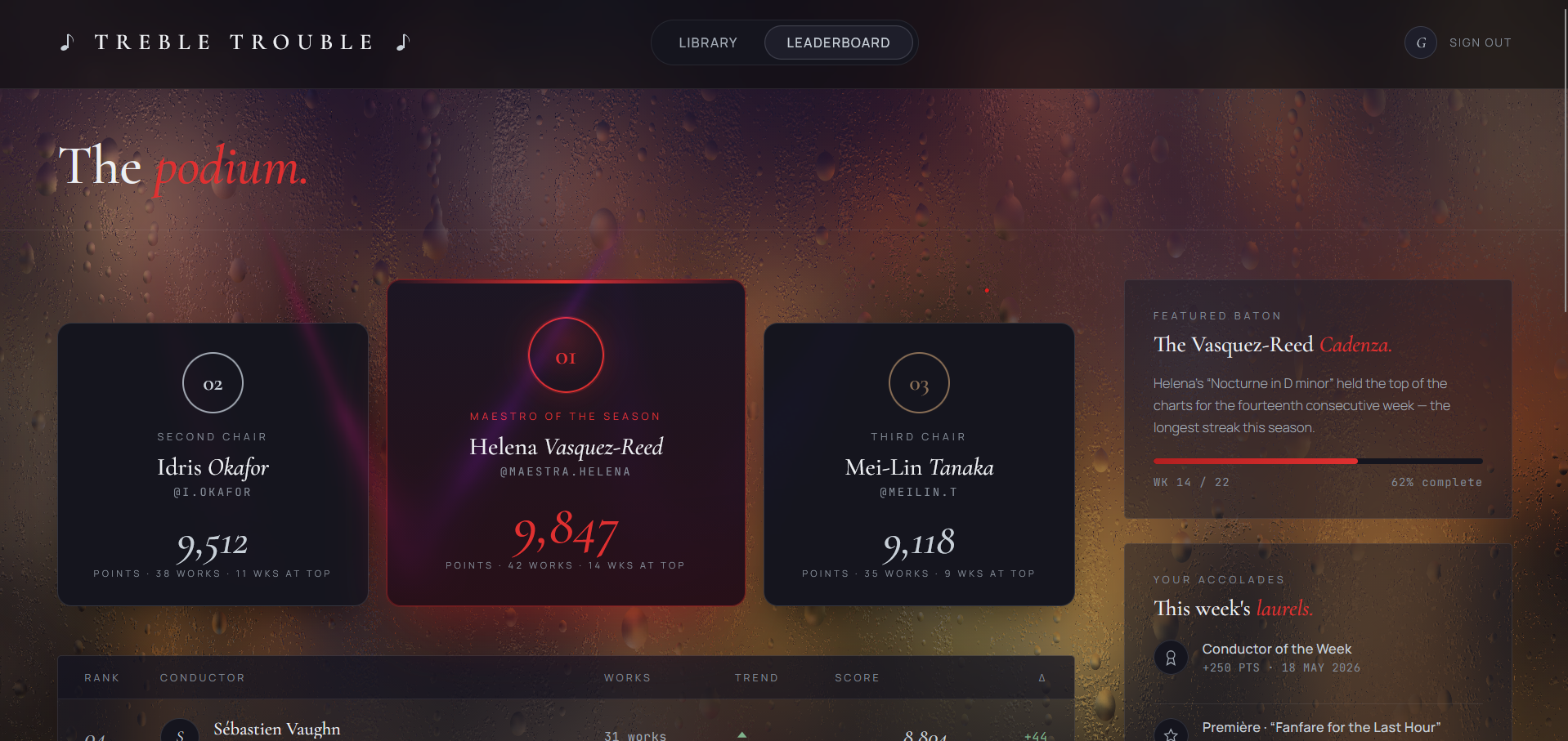
The polished result is published to a global studio (the Treble Trouble web app) where other conductors can like your piece and you climb the leaderboard.
- Speak or type a mood ("upbeat", "melancholy", "cinematic"). ElevenLabs Scribe v2 Realtime transcribes voice input in the background while you talk; no push-to-talk, no manual stop.
- Hum each of the five instruments for about 5 seconds. A windowed pitch detector extracts a quantized melodic contour from each hum.
- Stems render. Replicate's MusicGen produces an instrument-correct rendition when a token is set; otherwise a local FluidSynth + General MIDI SoundFont path fills in offline.
- Conduct the mix. OpenCV + MediaPipe HandLandmarker tracks your dominant hand at 30+ FPS. Five instrument zones span the screen; wrist X selects a zone, wrist Y becomes that stem's gain envelope, and a sustained closed fist (~0.5 s) commits the levels.
- Refine. The committed mix is passed back through MusicGen for AI mastering, or through a local mastering chain (high-pass, tilt EQ, multiband compression, soft limiter) if offline.
- Publish. The final WAV is POSTed to the Treble Trouble web app, stored in MongoDB Atlas GridFS, listed in the public Library, and credited on the Leaderboard. Likes on your piece increment your conductor score.
The point isn't that the output is a Mahler symphony. The point is that the time from "song stuck in my head" to "a mixed, instrument-correct recording on a global leaderboard" collapses from weeks of notation/DAW work to about two minutes of humming and a webcam wave.
Architecture
Sponsor Tracks
ElevenLabs
ElevenLabs Scribe v2 Realtime is the voice front-door of Treble Trouble. When step 1 launches, a SpeechListener (see webapp/stt.py and hackhcc/stt/) spawns a background thread that opens a Scribe v2 Realtime WebSocket and streams 16 kHz 16-bit mono PCM from the system microphone in ~100 ms frames using sounddevice. The session uses VAD commit strategy, so partial transcripts arrive as you speak and a committed transcript fires when you pause. There is no command syntax to learn.
The committed transcript is parsed into a structured mood / setup intent that drives stem generation: the parsed mood is what gets handed to MusicGen as a conditioning prompt later, so the entire downstream stack (instrument timbre, key character, tempo feel) is seeded by what the user said out loud. Scribe is reused inside the conduct loop too: spoken corrections during conducting ("brighter trumpet", "less drums") are transcribed mid-stream and merged into the next refine call without breaking the gesture flow.
The integration is wired carefully. The WebSocket lifecycle is owned by a single thread that exposes thread-safe partial_text / full_transcript properties, partial and committed transcripts surface as Python callback events, and SSL is forced through the certifi CA bundle so the realtime connect works on stock Windows and macOS Python without manual cert work. There is no local STT fallback, by design: if ELEVENLABS_API_KEY is missing, the voice path is hidden and --text is the only available mood entry, which makes the ElevenLabs dependency a real first-class part of the product rather than a swappable bolt-on.
MongoDB Atlas
MongoDB Atlas is the persistence backbone of the Treble Trouble web app. Every published piece, every conductor profile, and every audio blob lives in a single Atlas cluster (cluster0.klcgboc.mongodb.net, database maestro). The web app talks to Atlas through the official mongodb Node driver via an mongodb+srv:// SRV connection string, which gives the deployment TLS, automatic replica-set discovery, and IP-based network access control with zero extra config.
Atlas backs two collections and one GridFS bucket:
songs-- one document per published composition. Stored fields: title, composer name + handle, instrument tag, duration, like and save counters,audioId(a GridFS pointer), cover URL, andcreatedAt. The library page is afind({}).sort({ likes: -1 })against this collection.conductors-- one document per composer. Tracks lifetimescore,piecescount, weeks on the board, and trend direction. The doc is upserted on first publish (so a brand-new conductor appears immediately at zero) and then$inc-ed as their pieces collect likes. The leaderboard page is afind({}).sort({ score: -1 })against this collection: top three render on the laser-spotlight podium and the rest fill the ranked table.- GridFS bucket
audio-- the actual WAV bytes of every published mix. Files are written bywebapp/app/api/audio/upload/route.tsviabucket.openUploadStream(...)with the content type recorded in the file's metadata, and streamed back on demand fromwebapp/app/api/audio/[id]/route.tswith HTTP range support so a<audio>tag in the library can scrub a 2 minute piece without re-downloading.
Publishing is a single atomic-ish flow on top of Atlas. When the composer app POSTs a finished WAV, the upload route writes the bytes to GridFS, then createSong() in webapp/lib/db.ts inserts the song document with the resulting audioId and $setOnInsert / $inc-upserts the composer into conductors. A like becomes a findOneAndUpdate({ _id }, { $inc: { likes: 1 } }) on the song plus an updateOne({ handle }, { $inc: { score: POINTS_PER_LIKE } }) on the composer's leaderboard row. No transactions needed, since each call is a single document update.
The integration is wired to be cache-safe under Next.js dev hot-reloading: the MongoClient is cached on globalThis (see webapp/lib/mongodb.ts) so the dev server's per-request module reloads do not exhaust the connection pool. When MONGODB_URI is unset, every db function falls back to the mock data in webapp/lib/data.ts, so the UI renders identically with or without Atlas; the live deployment at https://www.trebletrouble.club hits Atlas for every read and write.
Stack
| Layer | Technology |
|---|---|
| Web app | Next.js 16 (App Router) + React 19 + TypeScript |
| Web auth | Auth.js / NextAuth v5 (Google OAuth + guest cookie) |
| Web styling | Vanilla CSS with three live WebGL wallpapers (rain-on-glass, vinyl grooves, laser labyrinth) |
| Web database | MongoDB Atlas (songs, conductors) + GridFS audio bucket |
| 3D composer | FastAPI + pywebview shell, Three.js scene (piano, trumpet, flute, rigged hand) |
| Voice intent | ElevenLabs Scribe v2 Realtime (scribe_v2_realtime) |
| Hand tracking | MediaPipe Tasks Vision HandLandmarker (GPU delegate), OpenCV capture |
| Stem generation | Replicate MusicGen (cloud) with local FluidSynth + SoundFont fallback |
| Refinement | Replicate MusicGen for AI mastering; local EQ + compression + limiting fallback |
Calculations
Mixing
Stems are aligned and summed in hackhcc/audio/. Each hum is recorded at 44.1 kHz mono and pitch is extracted per hum with librosa.yin (autocorrelation-style YIN), yielding a quantized MIDI contour. Tempo is recovered with librosa.beat.beat_track, and live pitch / tempo control during the conduct stage runs through librosa.effects.pitch_shift and librosa.effects.time_stretch. Stems are loop-padded to a 30 second canvas and summed with per-track gains from the conduct stage:
mix(t) = Σ_i g_i(t) · stem_i(t)
where g_i(t) is the per-instrument gain envelope from the conductor's wrist-Y trajectory, sampled at 30 Hz and linearly interpolated to the audio rate.
Local mastering fallback (applied in order)
- High-pass at 30 Hz (Butterworth, order 2) to clear DC and subsonic rumble.
- Tilt EQ: +1.5 dB shelf above 4 kHz, -1 dB shelf below 200 Hz.
- Multiband compression with crossovers at 200 Hz and 4 kHz; ratios 2:1 / 3:1 / 2.5:1.
- Soft limiter with -1 dBFS ceiling and 5 ms look-ahead.
Final loudness target: -14 LUFS integrated (Spotify / YouTube target).
Hand tracking math
hackhcc/vision/ opens the webcam at 30 FPS through OpenCV, feeds each BGR frame to MediaPipe HandLandmarker (hand_landmarker.task), and reads back 21 hand landmarks in normalized [0, 1] image space.
Instrument zone selection from wrist X (landmark 0):
zone = floor( wrist.x · 5 ) // 5 instrument zones across screen
Per-instrument gain from wrist Y, inverted so up is louder:
gain = clamp( 1 − wrist.y , 0 , 1 )
Fist detection (used to commit levels and advance stages) measures the closure of all four non-thumb fingers. For each finger, the tip-to-MCP distance is divided by the MCP-to-wrist distance:
finger_closed = | tip − mcp | / | mcp − wrist | < 0.55
A fist is registered when all four fingers report closed for 0.5 s of continuous frames (a debounce that survives a one-frame mediapipe miss). This is what advances stages: edit → mix → refine → playback → conduct → export.
Leaderboard score
A like on a published piece increments both the song's like count and the composer's conductor score:
conductor.score += POINTS_PER_LIKE
Fresh composers are upserted into the conductors collection on first publish with score = 0, pieces = 1, and trend = "flat", then climb organically as their pieces collect likes. The top three render on the laser-spotlight podium; everyone below renders in a ranked table.
Logic Flow
1. Setup (1_setup.py)
Captures mood + five hums.
If --text is passed, the mood is typed; otherwise SpeechListener opens, prints partial transcripts as you speak, and commits on VAD silence. For each of the five instruments, a 5 second mono recording is written to sessions/<id>/hums/<instr>.wav. Pitch is extracted per hum, the contour is saved to composition.json, and stems render: MusicGen if --musicgen is set and REPLICATE_API_TOKEN is present, otherwise the local SoundFont path. Step 1 writes .active_session so step 2 knows which session to open.
2. Conduct (2_conduct.py)
Five stages, hand-driven mixer.
- Edit. Five labeled vertical zones overlay the camera feed. Wrist X selects a zone; wrist Y sets that zone's gain;
Mmutes the active zone. A held fist saves the gain snapshot and advances. - Mixing. Stems are summed with the saved gains and written to
sessions/<id>/mix.wav. - Refining. MusicGen mastering if a Replicate token is set, otherwise local mastering. A refined WAV is written alongside the raw mix.
- Playback. Plays the refined mix once.
SPACEskips. - Conduct. Global pitch and tempo become live wrist parameters;
Eexports,SPACEreturns to edit,Qquits (always exports on quit).
Exports land in exports/<session>.wav.
3. 3D Composer (composer-app/)
FastAPI server with a pywebview window (or uvicorn app:app for plain browser use) hosting a Three.js scene: rigged hand model plus piano, trumpet, and flute meshes. The browser flow mirrors the CLI: start session, hum each track, render stems, conduct in-browser, master, finalize (MusicGen on master.wav → final.wav), publish.
The publish step prefers, in order: sessions/<id>/final.wav, then exports/<id>.wav, then a quick stem mixdown. The chosen file is multipart-POSTed to the web app's /api/audio/upload route alongside the song metadata.
4. Treble Trouble Web (webapp/)
Next.js 16 App Router. Routes:
/login. Google OAuth or guest cookie. Rain-on-glass wallpaper layered with a spinning vinyl groove iframe./library. Searchable, filterable grid of every published piece. Cards play their attached audio inline./leaderboard. Top three on the laser-spotlight podium plus a ranked table beneath. Likes promote conductors up the board./publish. Finishing step in the publish handoff: title the piece and confirm./api/songs,/api/audio/upload,/api/audio/[id],/api/leaderboard. Read and write routes.
Audio is stored as GridFS bytes in MongoDB Atlas and streamed back on demand at /api/audio/[id] with Content-Type: audio/mpeg and HTTP range support, so an <audio> tag in the library can scrub a 2 minute piece without re-downloading.
When MONGODB_URI is unset, the routes silently fall back to the mock data in webapp/lib/data.ts, so the UI is never blank during local development.
Running locally
Backend + CLI
python -m venv venv
source venv/bin/activate # macOS / Linux
# .\venv\Scripts\Activate.ps1 # Windows PowerShell
pip install -r requirements.txt
cp .env.example .env
# fill in ELEVENLABS_API_KEY, optionally REPLICATE_API_TOKEN
sudo dnf install fluidsynth # optional: better local piano stems (Fedora)
CLI workflow:
python 1_setup.py -s mysong # voice mood + five hums
python 2_conduct.py # conduct, refine, export
3D composer:
cd composer-app
python main.py # pywebview window at http://127.0.0.1:5000
Web app
cd webapp
cp .env.local.example .env.local # AUTH_SECRET, AUTH_GOOGLE_*, MONGODB_URI
npm install
npm run dev # http://localhost:3000
Google sign-in works once AUTH_GOOGLE_ID / AUTH_GOOGLE_SECRET are filled. Guest mode (the "Continue as guest conductor" button) works with no env config at all. Set MONGODB_URI to your Atlas connection string (mongodb+srv://...) and MONGODB_DB=maestro to back the library and leaderboard with real data.
Built for HackHCC 2026 by Deklen Nates, Mudit Upadhyay, Tushaar Sood, and Jordan Joelson
Built With
- elevenlabs
- mongodb-atlas
- mediapipe
- musicgen
- replicate
- librosa
- numpy
- scipy
- next.js
- react
- typescript
- nextauth
- three.js
- fastapi
- pywebview
- opencv
- fluidsynth
- vercel
Check it out
Built With
- elevenlabs
- fastapi
- javascript
- python
- three.js






Log in or sign up for Devpost to join the conversation.