
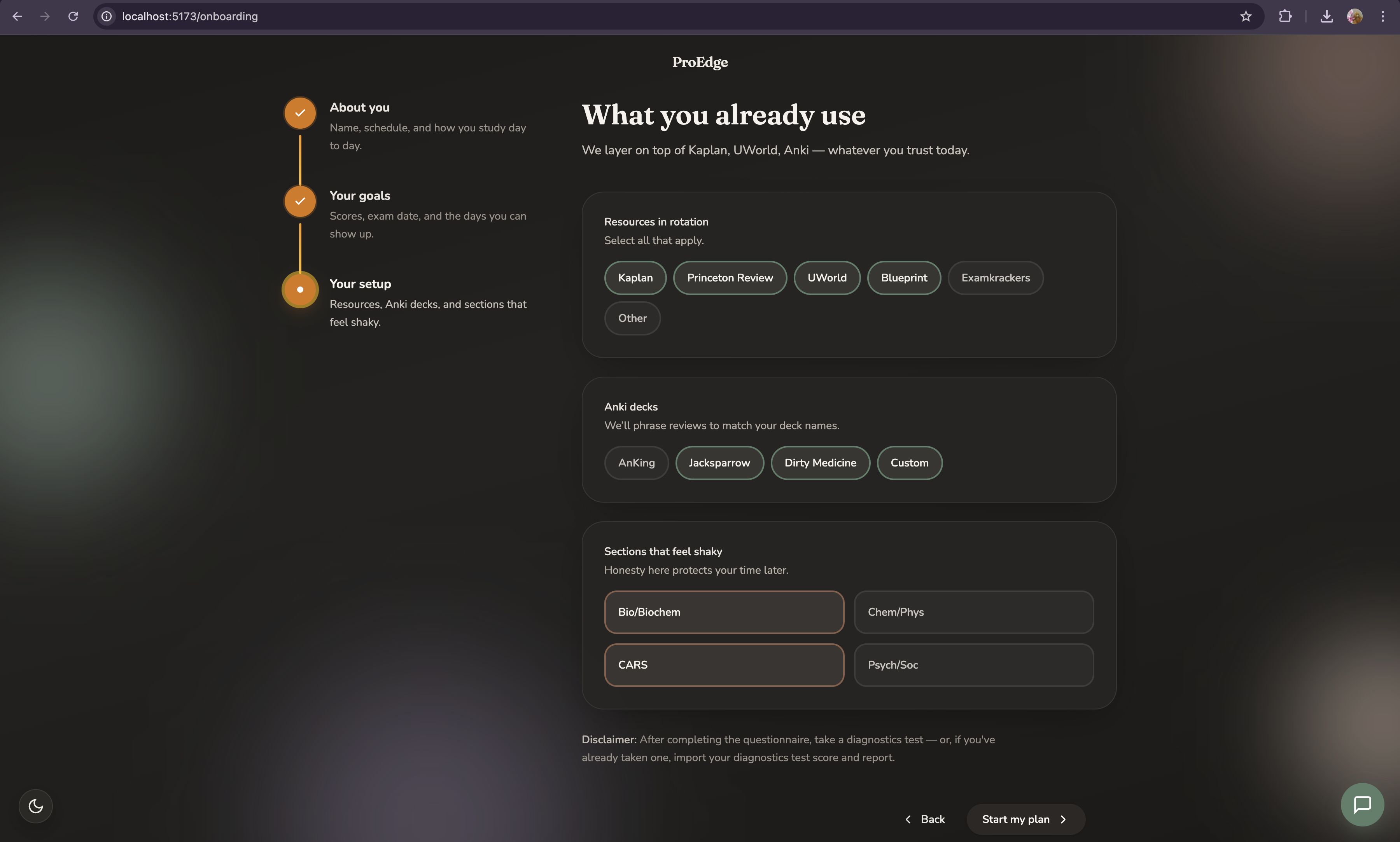
Inspiration
Every MCAT student has 12 tabs open, three spreadsheets, and still no idea if it's working.
One of us is that student. A pre-med senior juggling a full course load, a job, research, and family responsibilities still stuck in phase one after three months of prep. Every resource assumes six free hours a day and zero obligations. Every schedule collapses by week two. Every practice exam gives a score but never answers the real question:
Why do I keep getting the same questions wrong?
We looked at the entire MCAT prep landscape and found the same gap everywhere. Tools that deliver content. None that deliver intelligence. No app had ever noticed she was burning out. No app had ever adjusted a single thing based on how she felt that morning.
ProEdge is the missing brain that ties everything together.
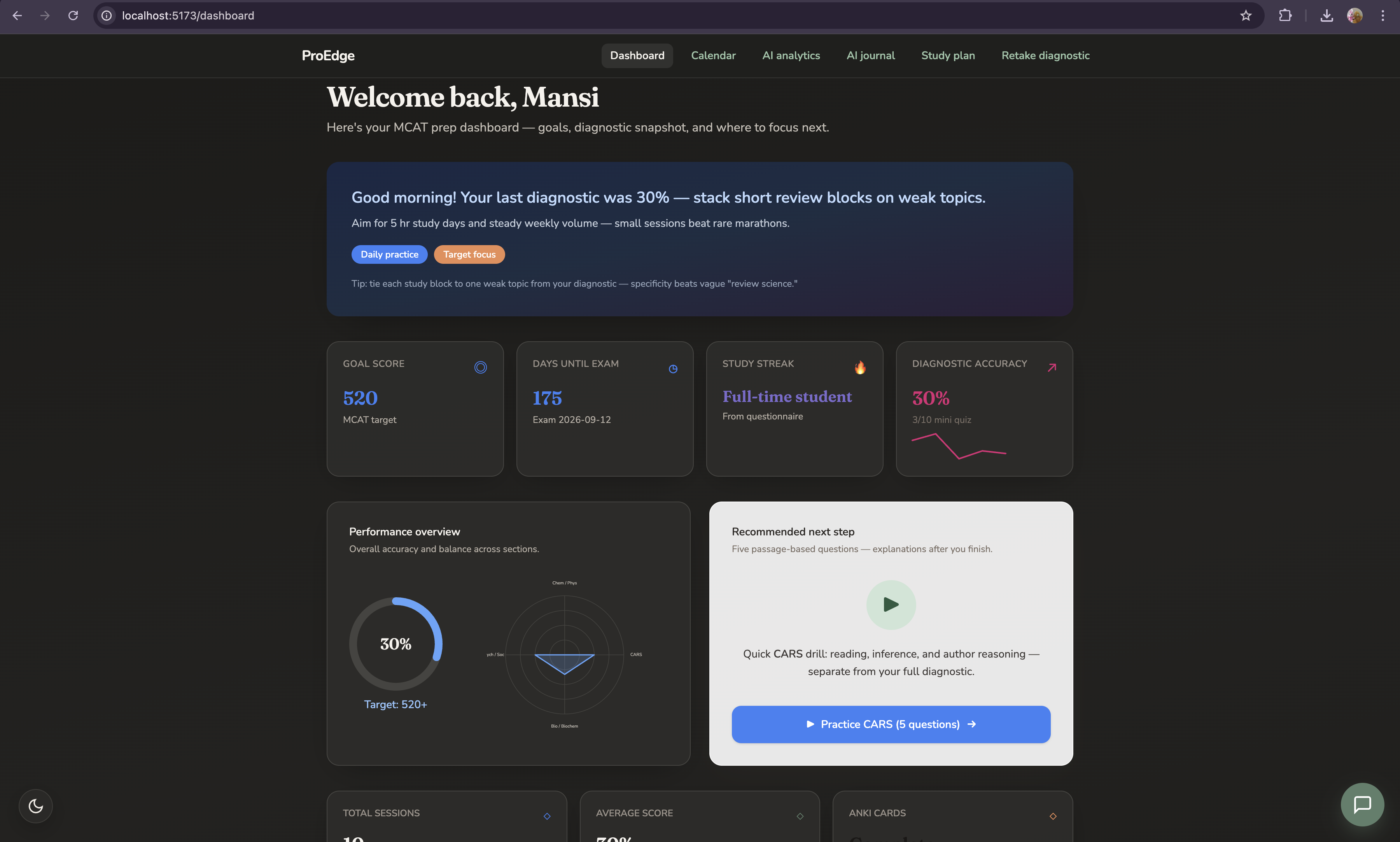
What it does
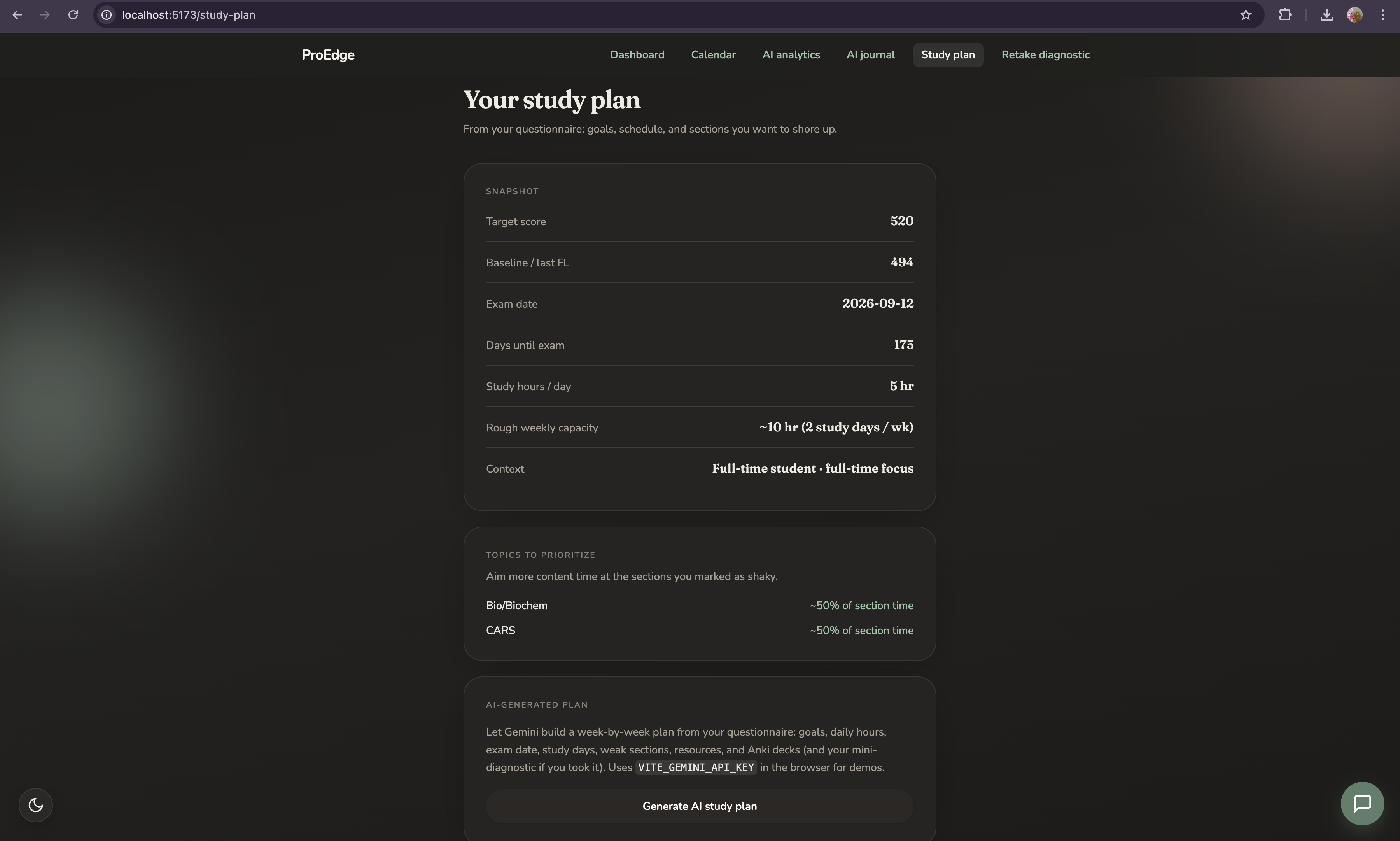
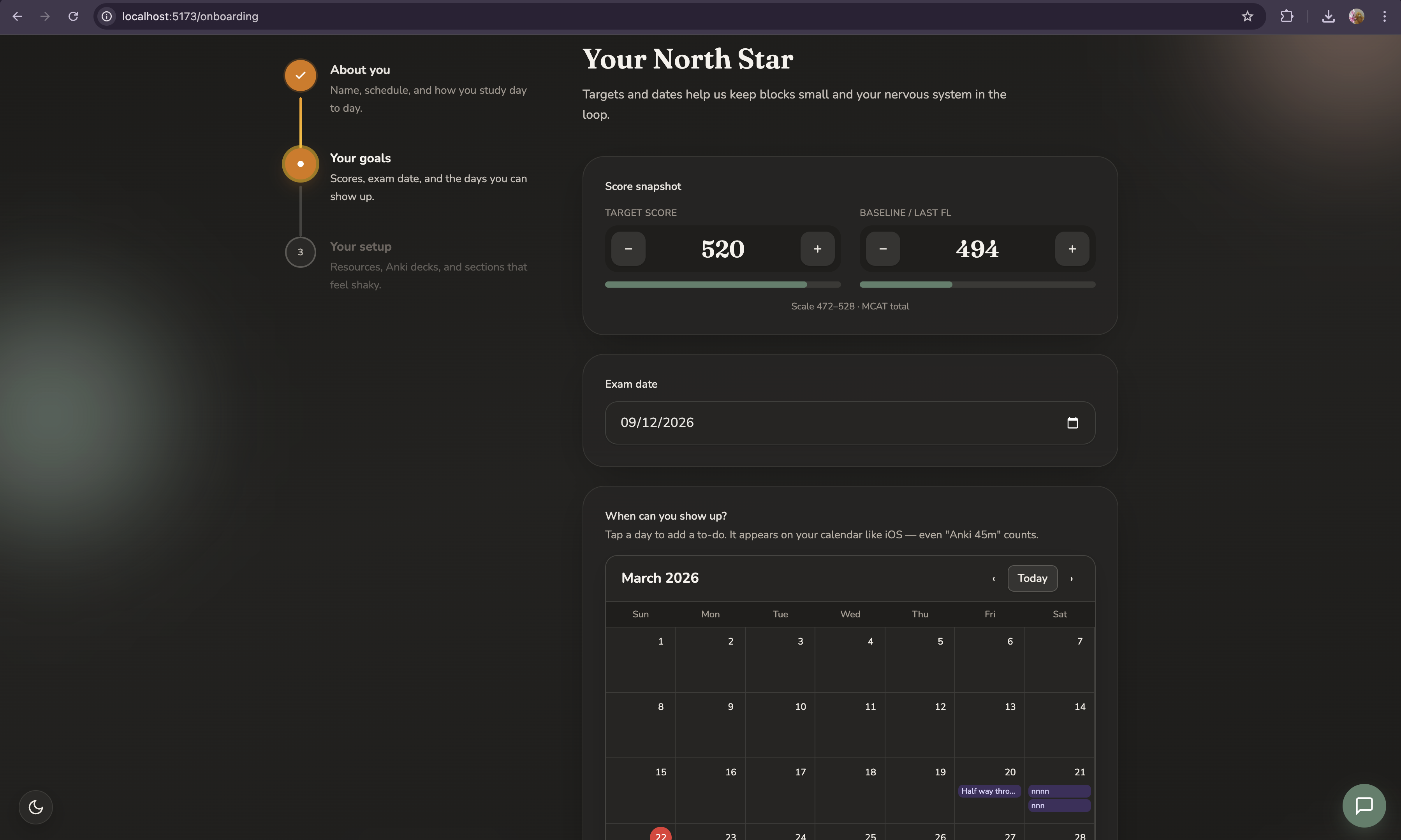
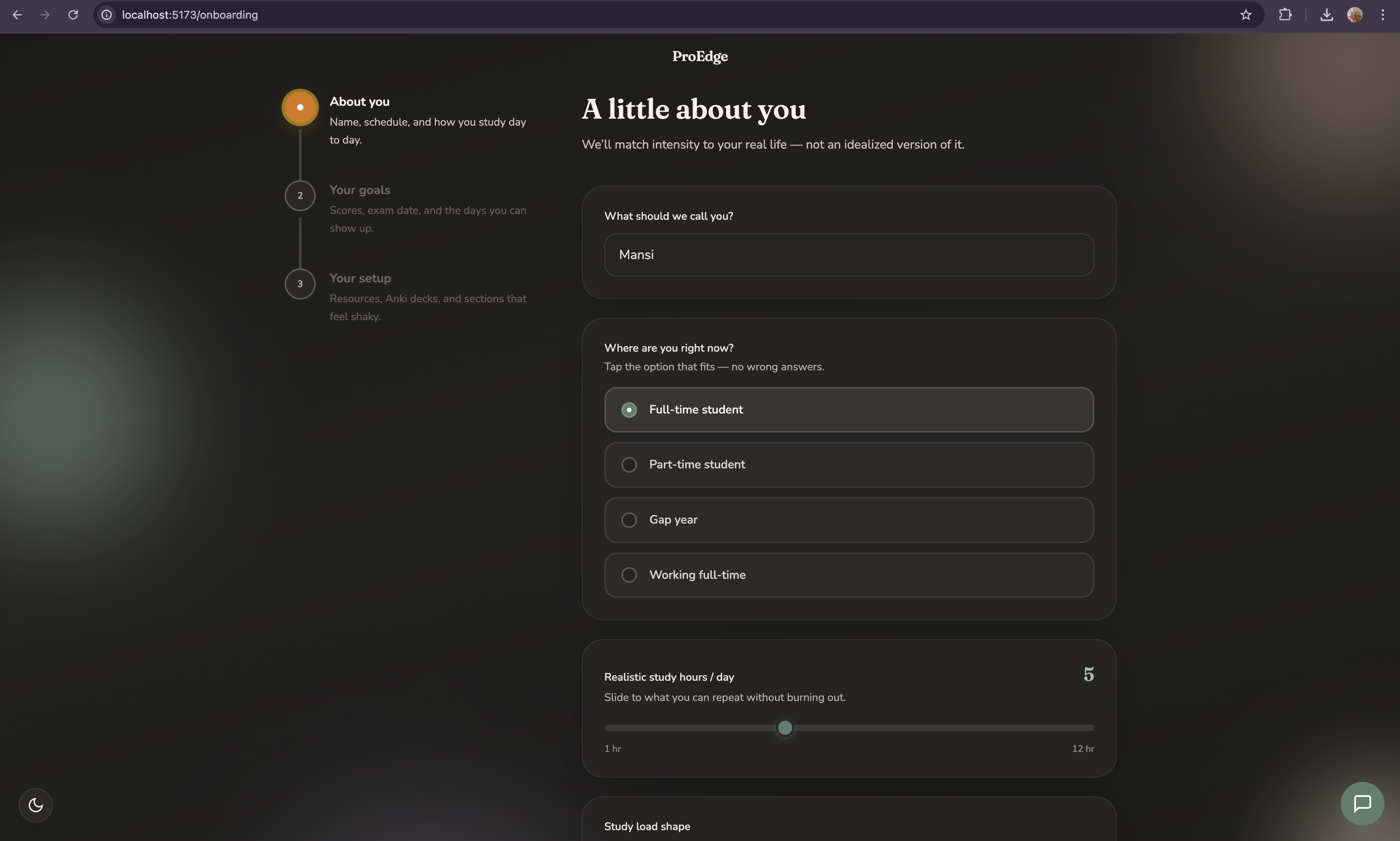
Personalized onboarding
ProEdge starts by asking about your life, not just your score. Study situation, realistic daily hours, specific available days, resources you actually own, weak sections, exam date, and baseline score. From this it generates a phased study plan calibrated to your real constraints not the textbook's version of your schedule.
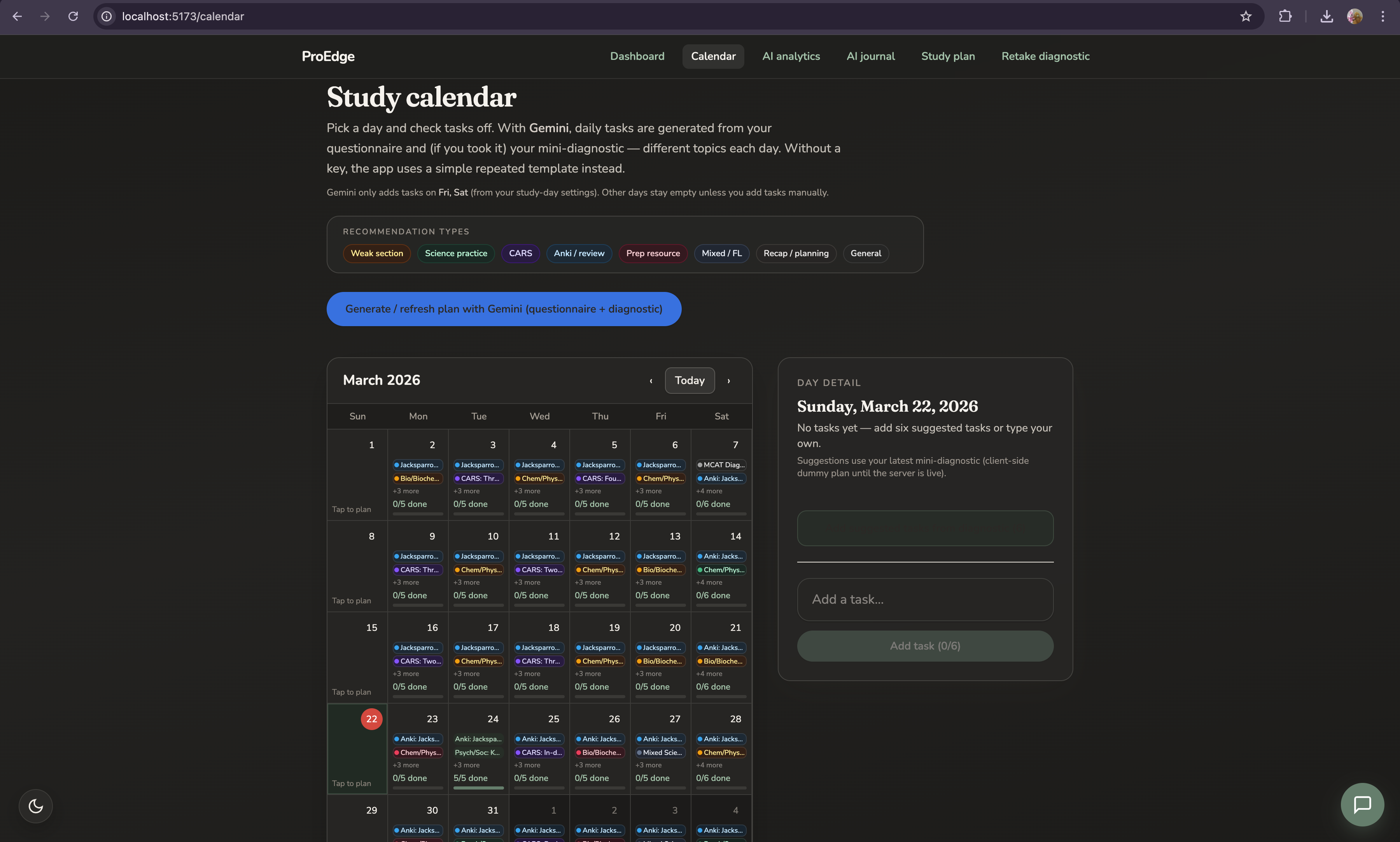
Adaptive study calendar
Every available day has a task list matched to the resources you own and the sections where you're weakest. When you import new practice data, the calendar reshapes itself automatically. The plan is never static.
AI concept gap analysis
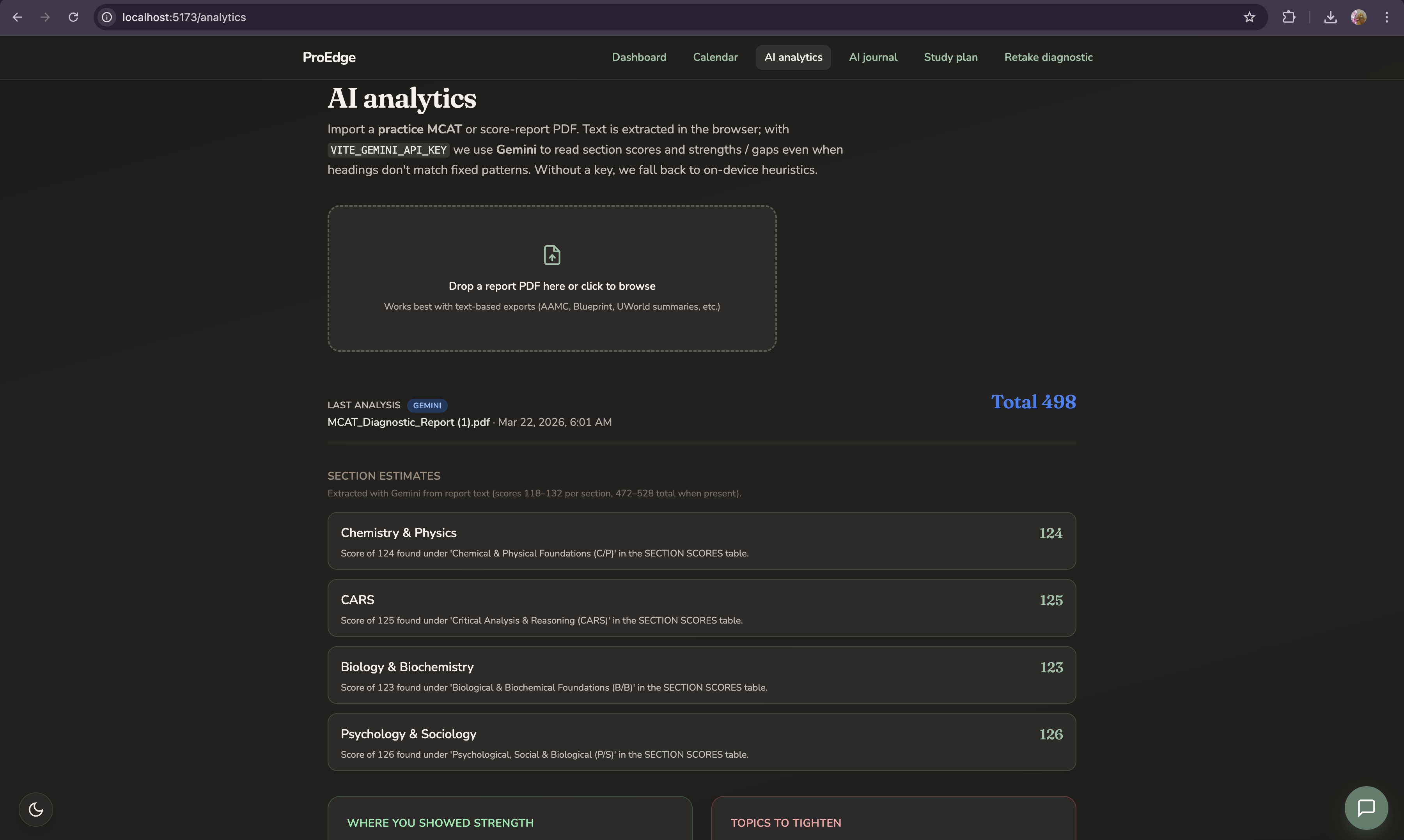
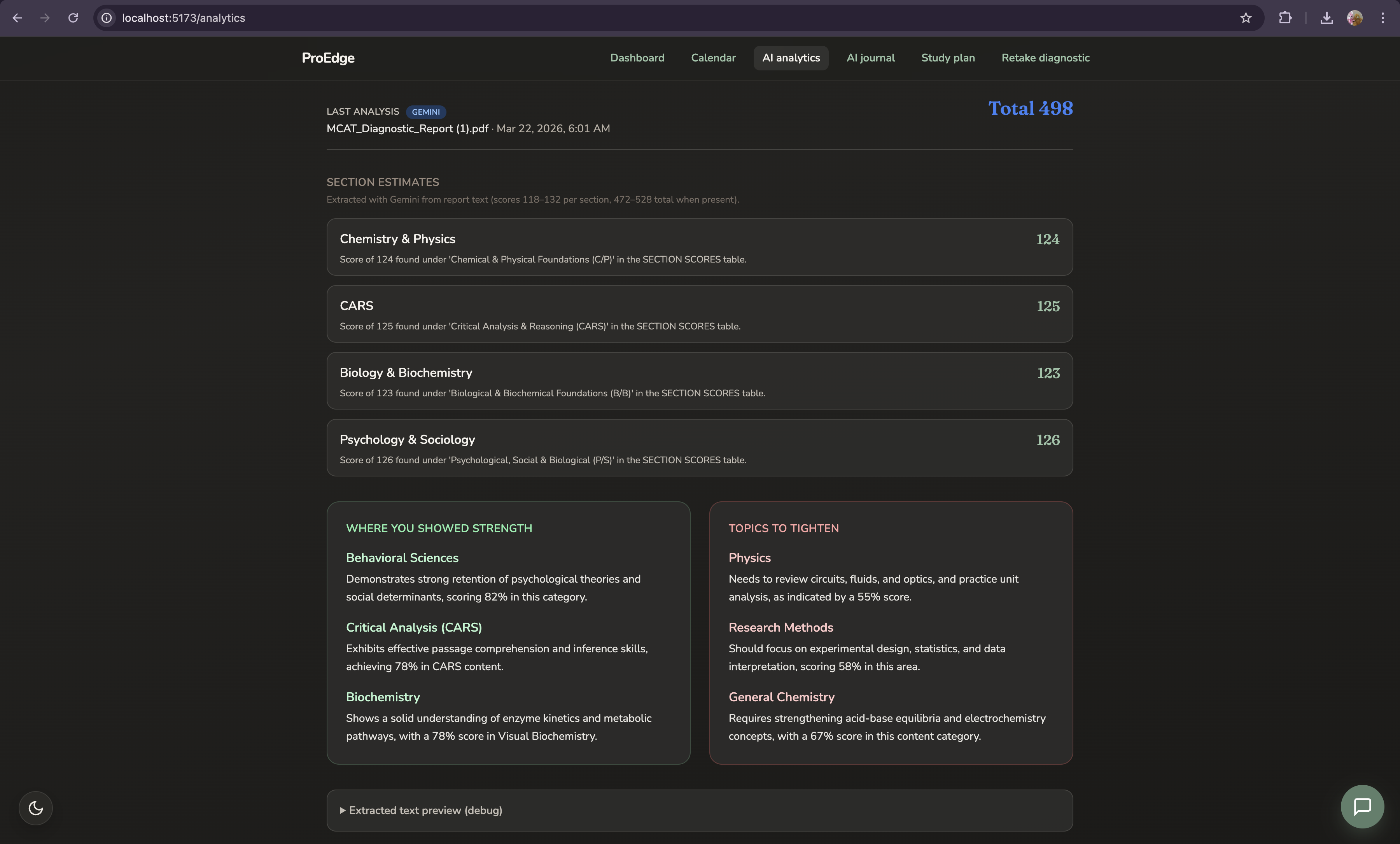
After any practice session UWorld, AAMC, Blueprint, anywhere you import your results. ProEdge doesn't just surface what you got wrong. It identifies why your brain keeps choosing the wrong answer. For example, distinguishing a confounding variable from a measurement validity threat requires recognizing that a confound must be an independent alternative explanation for the dependent variable not just a flaw in the instrument. That distinction is the difference between a content gap and a reasoning gap, and they require completely different fixes.
The cross-session pattern engine reads across every exam you have ever imported:
$$\text{Pattern strength} = \frac{\text{repeat misses on concept } C}{\text{total sessions}} \quad \text{flagged when } \geq 2 \text{ sessions}$$
This surfaces concept-level patterns no single practice exam ever could.
Miss Tracker
A living log of every wrong answer not just the topic, but the full context:
| Field | Description |
|---|---|
| Section + topic | e.g. Psych/Soc → Confounding variables |
| Why I got it wrong | The exact reasoning error |
| Why the right answer is right | The principle that makes it correct |
| Status | Review → Studying → Mastered |
| Source | AI import or manual entry |
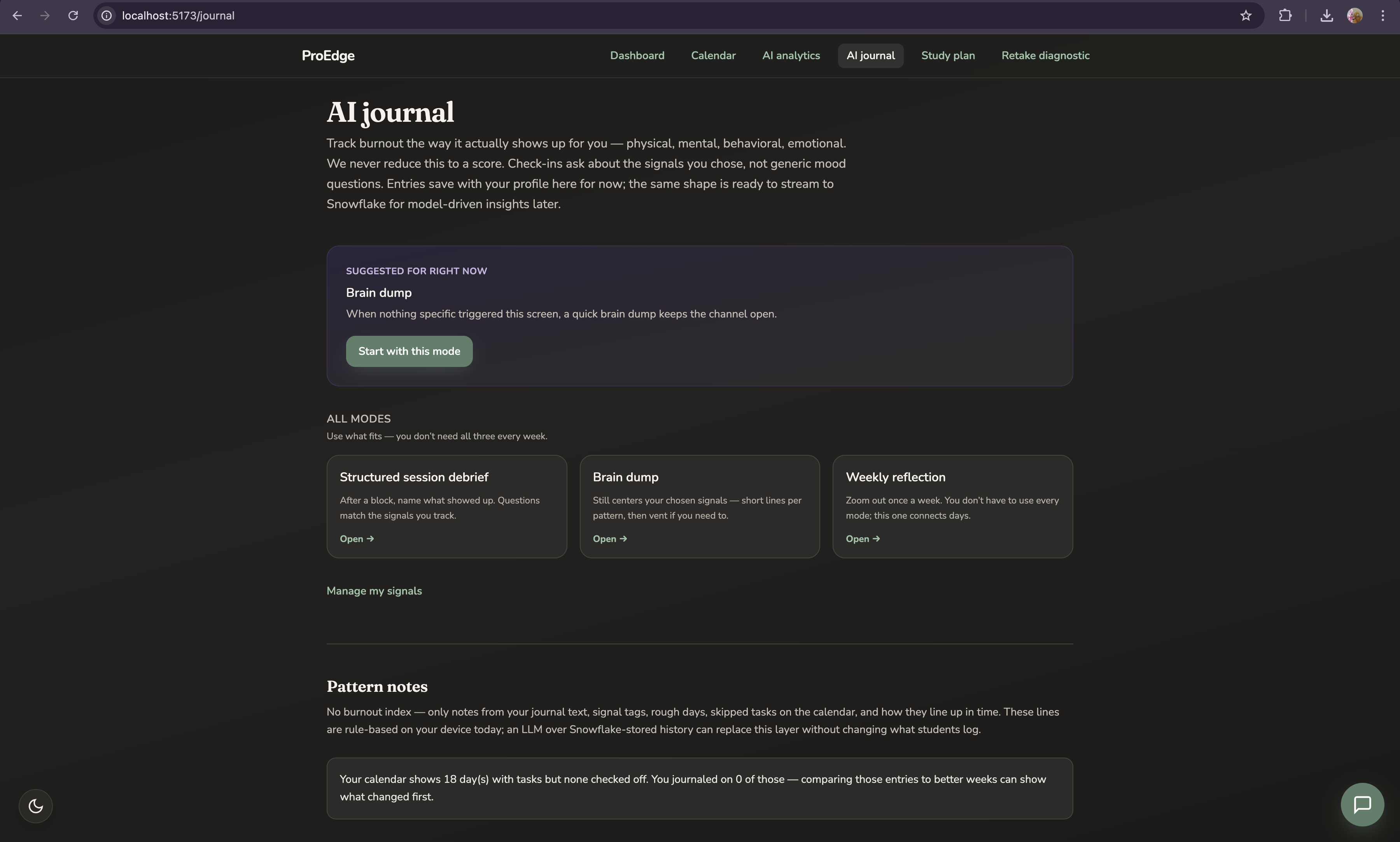
Burnout Shield
There is no burnout score. No formula. Because burnout is not universal a gap-year student's threshold is not the same as a pre-med carrying 18 credits and a job.
At onboarding, students define their own burnout fingerprint by selecting from four signal categories:
- Physical — sleeping more than usual, headaches, skipping workouts
- Mental — can't focus past 20 minutes, reading the same paragraph five times, brain fog
- Behavioral — doom scrolling instead of studying, skipping sessions and making excuses
- Emotional — dreading opening the app, feeling like nothing is working
The journal then asks specifically about the signals that student chose not a generic mood check. After two to three weeks, the app identifies what preceded the student's bad days:
"The last two times your accuracy dropped 15%, you had written negative journal entries for two consecutive days before it. Your stress rating was > 4 both times."
That is a real, observable, student-confirmed pattern. When it detects that pattern forming again, it adjusts the study plan before the student crashes not after.
ProEdge is the first MCAT app that tells you to stop studying. And means it.
How we built it
Stack
| Layer | Technology |
|---|---|
| Frontend | Next.js 14, Tailwind CSS, Recharts |
| Backend | Next.js API routes |
| Database | PostgreSQL via Prisma ORM |
| Auth | Clerk |
| AI | Anthropic Claude API (claude-sonnet-4-20250514) |
| Hosting | Vercel + Railway |
AI pipeline
Every Claude call goes through a server-side API route the key is never exposed to the client. Prompts are tightly structured to return clean JSON only:
{
"concepts": [
{
"name": "Confounding variables",
"priority": "high",
"review": "Selected measurement validity threat instead of independent confound",
"resource": "Kaplan Psych/Soc Ch.8 · Research Methods"
}
],
"recommendation": "2–3 sentence personalized next-day plan"
}
The cross-session pattern engine aggregates MissEntry records by topic and section
across all PracticeSession records for a user, flagging any concept where:
$$\text{times_missed} \geq 2 \quad \text{and} \quad \Delta t_{\text{last}} \leq 14 \text{ days}$$
Burnout Shield logic
No scoring formula. The system stores PulseCheckIn records with energy, stress, and
confidence, cross-referenced against JournalEntry sentiment tags and
PracticeSession accuracy deltas. A pattern is flagged only after the student has confirmed
it app never acts on unvalidated data.
Data models (simplified)
User → PulseCheckIn (energy, stress, confidence, date)
User → PracticeSession (section, topic, correct, attempted, aiConcepts)
User → MissEntry (topic, whyWrong, whyRight, status, timesMissed)
User → ChecklistDay (tasks[], completedPct, pulseScore)
User → JournalEntry (mode, signals[], content, sentimentTags)
The full pipeline — onboarding → calendar generation → AI analyzer → Miss Tracker → Burnout Shield was built and integrated end-to-end in under 24 hours.
Challenges we ran into
Keeping AI medically accurate without hallucinating MCAT content. Claude is powerful but general. MCAT content is specific Michaelis-Menten kinetics, dopaminergic pathways, Henderson-Hasselbalch and a wrong explanation is worse than no explanation. We solved this with tightly constrained output prompts, JSON-only responses, and explicit instructions to cite specific resources rather than generate explanations from scratch.
Balancing onboarding depth against drop-off. The questionnaire needed to capture life load, schedule constraints, resources, baseline score, and weak areas without feeling like a form. We stripped every field that didn't directly drive a downstream feature and reworded every question to sound like a conversation, not an intake form.
Making the Burnout Shield feel like a coach, not a therapist. The earliest versions surfaced burnout warnings that felt clinical and alarming. The fix was structural: remove the score, remove the diagnosis, and put the student in control of defining what their burnout looks like. The app observes and reflects. The student interprets and confirms. That distinction changed everything about how the feature felt.
Building a cross-session pattern engine in 24 hours. Aggregating meaningful signals across sessions with enough data to be useful but not so much that the first-time user sees nothing required careful threshold design. We landed on flagging patterns after confirmed misses within a 14-day window, which surfaces signal fast enough to be useful in the early weeks of prep.
Accomplishments that we're proud of
The first MCAT app that tells you to stop studying and backs it with real, student-confirmed behavioral data rather than a formula.
A cross-session pattern engine that surfaces concept gaps no single practice exam ever could. The gap between what you got wrong and why your brain keeps choosing it is where MCAT prep actually breaks down. We built the tool that closes that gap.
A burnout system that is personalized by design, not by algorithm. Every student defines their own fingerprint. The app learns from confirmed patterns, not population averages.
A full working pipeline onboarding through AI debrief through adaptive calendar shipped in one 24-hour hackathon by a team of four.
What we learned
The gap isn't content. Students already have too much content.
The gap is intelligence something that looks across all your data, knows your actual life, and tells you exactly what matters right now. Not in a week. Not after the next full-length. Right now, today, given how you slept and what you got wrong yesterday.
We also learned that the most powerful feature we built wasn't the AI analyzer. It was asking a student to define what burnout looks like for them and then actually remembering the answer. No other tool does that. Not because it's technically hard. Because nobody thought the student's emotional state was worth tracking.
We think it's the whole point.
What's next for ProEdge
Full-length test score tracker with Pulse correlation map your emotional state directly to your FL performance over time.
Spaced repetition engine built on the Miss Tracker concepts you keep missing come back at the right interval automatically, calibrated to your personal error frequency:
$$t_{\text{next review}} = t_{\text{last miss}} + \frac{k}{\text{times_missed}^{\alpha}}$$
Voice debrief mode talk through your wrong answers out loud, transcript fed directly into the AI analyzer pipeline via Web Speech API.
Mobile app for the daily Pulse check-in 30 seconds on the way to class, not at a desk.
Peer study groups share your Miss Tracker with a study partner, battle on each other's weak concepts, see who closes their gaps faster.
ProEdge: Every MCAT app is built around content. Ours is built around the student.
Built With
- fastapi
- nextjs
- python




Log in or sign up for Devpost to join the conversation.