-
-
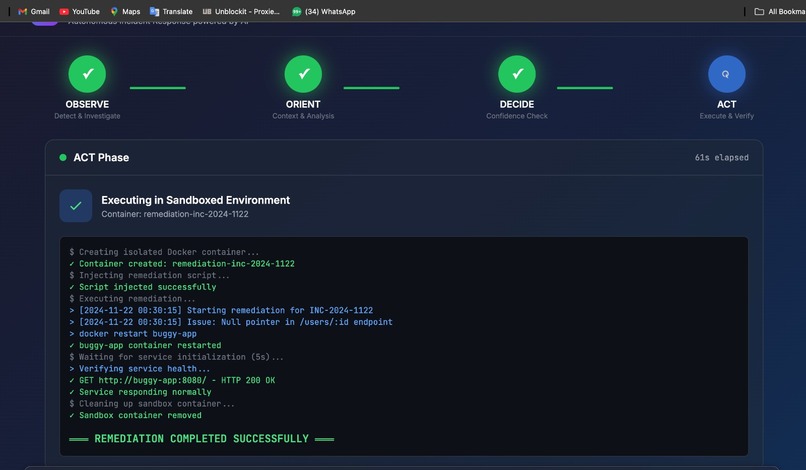
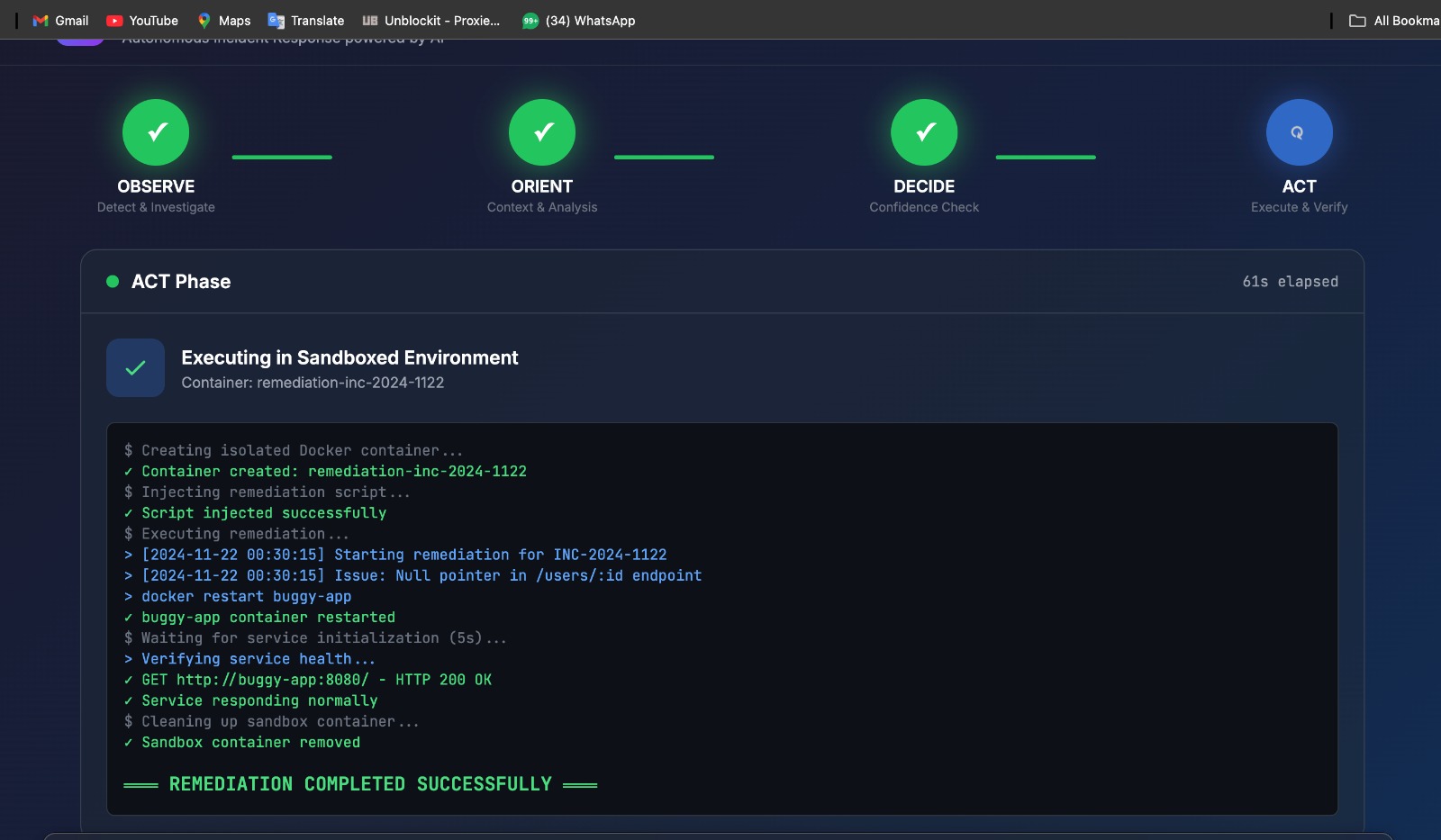
Deployment fixed
-
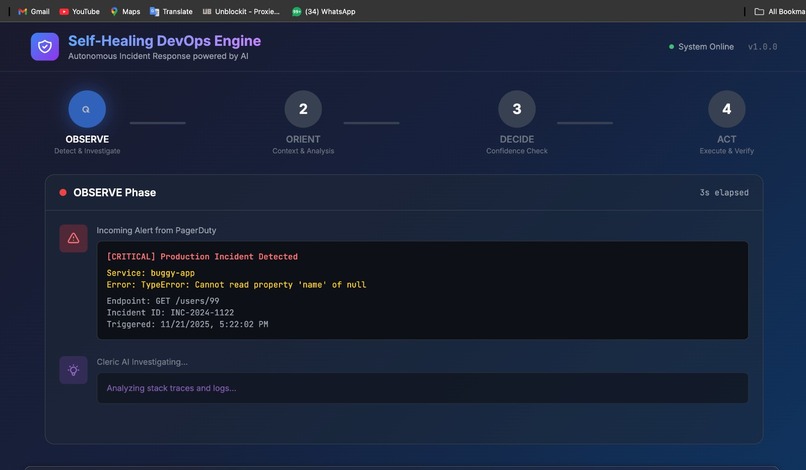
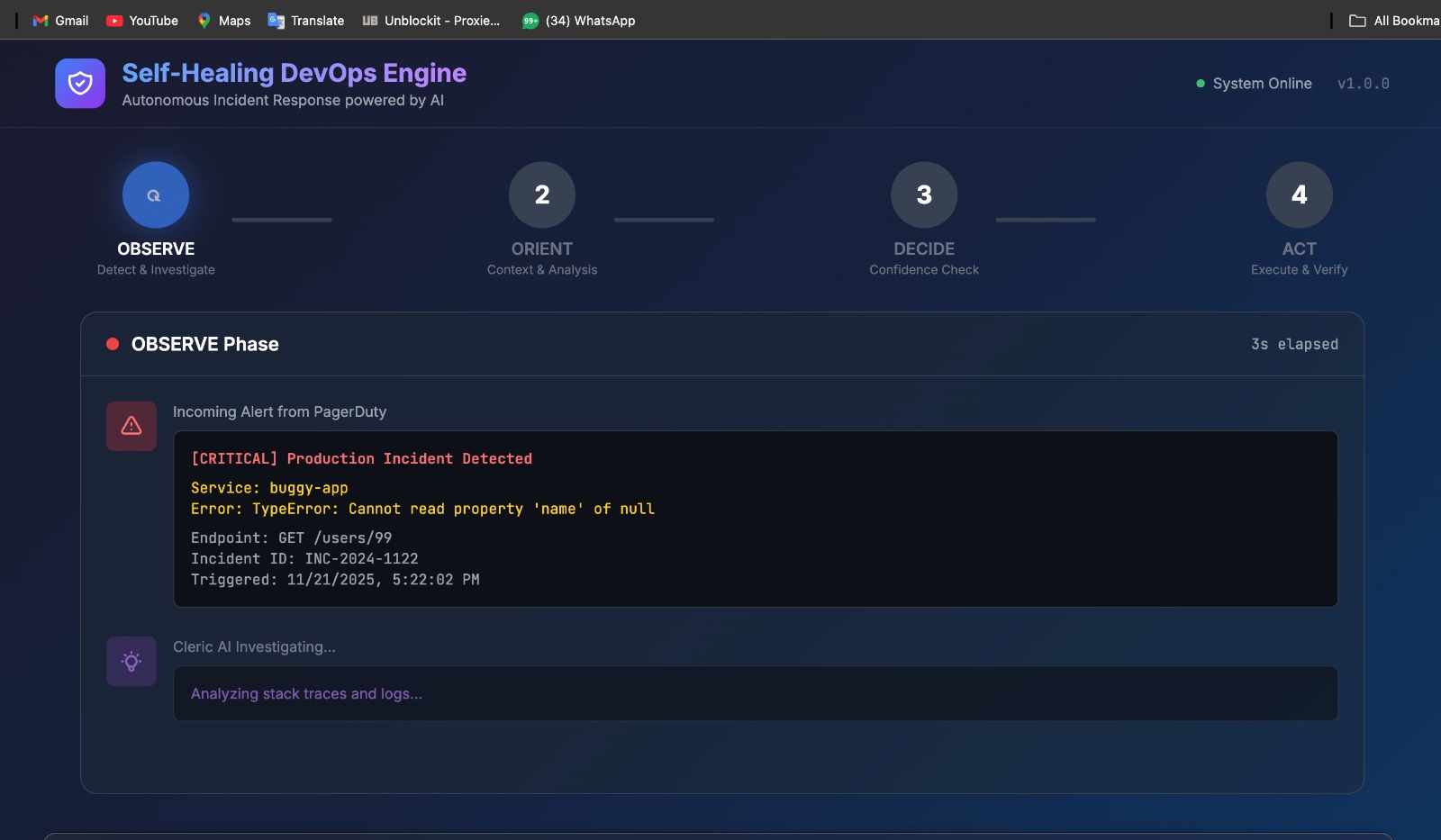
Error occured-> Agent triggered
Inspiration
It's 3 AM. A PagerDuty alert fires. An engineer wakes up, bleary-eyed, staring at a wall of logs trying to figure out why the payment service is timing out. By the time they identify a database lock and kill the offending query, it's 4:30 AM—and thousands of transactions have failed.
This scenario plays out every night across thousands of engineering teams. The modern microservices landscape has created an explosion of complexity that has outpaced human cognitive capacity. We're drowning in metrics, logs, and traces, yet Mean Time to Resolution (MTTR) keeps climbing.
We asked ourselves: What if the system could heal itself?
Not just alert a human. Not just suggest a fix. But actually observe, reason, decide, and act—autonomously, safely, and verifiably.
That question became Vigil.
What it does
Vigil is an Autonomous Reliability Engine that transforms incident response from "Human-in-the-Loop" to "Human-on-the-Loop." It doesn't just watch your infrastructure—it understands it, reasons about it, and heals it.
The Autonomic Loop (9-Stage Incident Lifecycle):
- TRIGGERED → Alert received from monitoring systems via PagerDuty
- INVESTIGATING → Cleric AI begins root cause analysis
- HYPOTHESIS_RECEIVED → Investigation findings posted to incident timeline
- CONTEXT_RETRIEVED → Sanity CMS returns relevant runbooks and past incidents
- SYNTHESIZING → Claude generates remediation using Chain-of-Thought reasoning
- EXECUTING → Coder provisions isolated Kubernetes pod to run the fix
- VERIFYING → Lightpanda verification swarm confirms the fix works
- RESOLVED → Incident automatically closed with full audit trail
- ESCALATED → Human intervention requested when confidence is low
The Confidence Protocol:
Vigil doesn't blindly execute. It implements a multi-layer safety system:
- Auto-execute: Cleric confidence > 90% AND runbook match > 85% AND risk = LOW
- Human approval: High-risk operations or low-confidence scenarios trigger Slack approval workflow
- PII Protection: Skyflow redacts sensitive data before any LLM processing
The result? Engineers wake up to resolved incidents, not active fires.
How we built it
We architected Vigil as three parallel development streams, integrated through a custom Orchestration Control Plane (OCP).
Technology Stack:
| Layer | Technology | Purpose |
|---|---|---|
| Runtime | Node.js 20, Express.js | Core OCP server |
| State | Redis 7 (ioredis) | Incident state machine, caching |
| Database | PostgreSQL 15 | Coder workspace metadata |
| Incident Management | PagerDuty | Webhooks, alerts, annotations |
| Knowledge Base | Sanity CMS | Runbooks, GROQ queries, semantic search |
| Reasoning | Anthropic Claude (claude-3-sonnet) | Chain-of-Thought remediation synthesis |
| Fallback AI | Google Gemini | Alternative LLM via factory pattern |
| Privacy | Skyflow | PII detection and redaction |
| Execution | Coder v2.28.3 + Terraform | Ephemeral Kubernetes workspaces |
| Verification | Lightpanda | Zig-based headless browser (10x faster than Chrome) |
| Approval | Slack | Human-in-the-loop workflow |
| Infrastructure | Docker, Kubernetes, Minikube | Container orchestration |
Architecture:
[Datadog Alert] ↓ [PagerDuty] ──webhook──→ [OCP: Express Server] ↓ [Redis: State Machine] ↓ ┌───────────────┼───────────────┐ ↓ ↓ ↓ [Cleric: RCA] [Sanity: Context] [Skyflow: PII] └───────────────┼───────────────┘ ↓ Claude: Reasoning ↓ ┌─────────┴─────────┐ ↓ ↓ [High Confidence] [Low Confidence] ↓ ↓ [Coder: Execute] [Slack: Approve] ↓ ↓ [Lightpanda: Verify] ←──────┘ ↓ [PagerDuty: Resolve]
Three Parallel Workstreams:
- Stream A (Signal & Control): OCP server, PagerDuty webhooks, HMAC signature verification, Redis state management, Cleric hypothesis parsing
- Stream B (Cognition & Memory): Sanity integration, runbook ingestion pipeline, Claude prompt engineering, edge case detection, Lightpanda verification library
- Stream C (Action & Environment): Coder deployment on Kubernetes, Terraform templates, NetworkPolicy isolation, SSH-based execution
Challenges we ran into
1. The Confidence Problem
How do you know when an AI is hallucinating versus when it has found the true root cause? An overconfident system creates more noise than signal.
Solution: We implemented multi-source validation with configurable thresholds. Cleric's hypothesis must correlate with Sanity's runbooks. We built an edge case detection system (edge-cases.js - 369 lines) that identifies ambiguous scenarios and automatically escalates to humans.
2. PII in Production Logs
Production incidents often contain sensitive data—API keys, customer emails, session tokens. Sending raw logs to an LLM is a privacy nightmare.
Solution: We integrated Skyflow's Detect API to identify and redact PII before any data reaches Claude. The original sensitive values never leave our infrastructure.
3. Asynchronous Orchestration Hell
Cleric posts findings as PagerDuty annotations (not a synchronous API). Coder workspaces take time to provision. The entire system is event-driven across 5+ services.
Solution: We built a 9-stage state machine in Redis with fallback to in-memory storage. Each incident maintains its lifecycle state as webhooks arrive asynchronously. The OCP is stateless but the state is persistent.
4. Blast Radius Containment
Executing AI-generated code on production is terrifying. One wrong command could cascade into catastrophe.
Solution: Every remediation runs in an ephemeral Coder workspace—a Kubernetes pod with:
NetworkPolicydenying all ingress, limited egress- Non-root security context
- Short-lived credentials injected via Terraform
rich_parameter_values - Automatic destruction after execution
5. Knowledge Poisoning Prevention
If a bad fix "works" temporarily (e.g., a restart that masks a memory leak), the system might learn it as valid.
Solution: Our incident-learner.js implements delayed ingestion with a stability period. If the alert re-fires within 24 hours, the previous resolution is marked as "ineffective" and won't be suggested again.
Accomplishments that we're proud of
- 2,172+ lines of production-grade service code across 12 integrated services
- End-to-end autonomous remediation with a 9-stage lifecycle
- Chain-of-Thought reasoning that forces Claude to analyze before acting—parseable confidence levels and risk assessment
- "First, Do No Harm" prompting with built-in safety rules (never DROP TABLE, never rm -rf, never disable auth)
- Verification Swarm using Lightpanda—hundreds of concurrent browser sessions at 10x the speed and 1/10th the memory of Chrome
- Privacy-first architecture with Skyflow PII redaction before any LLM processing
- Multi-LLM support via factory pattern (Claude primary, Gemini fallback)
- Zero-trust execution in isolated Kubernetes pods with network policies
What we learned
Integration > Innovation: The power isn't in any single tool—it's in the orchestration. Making PagerDuty, Sanity, Claude, Coder, Skyflow, and Lightpanda work as a unified system required deep API understanding and careful state management.
Confidence scoring is non-negotiable: An autonomous system without confidence handling creates chaos. The "Human-on-the-Loop" model only works when the system knows its own limitations.
Prompt engineering is systems engineering: Claude's effectiveness depended entirely on structured prompts—the 5-step Chain-of-Thought process, the "Cautious Senior SRE" persona, and explicit safety rules embedded in
system-prompts.js.Async is hard, state machines help: Event-driven architectures across multiple services need rigorous state tracking. Our 9-stage Redis state machine became the source of truth.
Security can't be an afterthought: HMAC signature verification, PII redaction, non-root containers, and network policies had to be designed in from day one.
Fallbacks are essential: Redis unavailable? Fall back to in-memory. Claude rate-limited? Fall back to Gemini. Every integration needs a graceful degradation path.
What's next for Vigil
Short-term:
- Complete Stream C Week 3-4: Full incident-triggered automation and integration testing
- Expand runbook coverage (currently: high-latency-api, memory-exhaustion, database-connection-pool)
- Production hardening and performance optimization
Medium-term:
- Predictive healing: Use historical patterns to remediate before alerts fire
- Multi-cloud execution: Extend Coder templates for AWS EKS, GCP GKE, Azure AKS
- Feedback learning loop: Engineer ratings on remediations to continuously improve prompts
- OneUptime integration: Alternative to PagerDuty for self-hosted monitoring
Long-term:
- Autonomous chaos engineering: Vigil proactively tests its own healing capabilities
- Cross-organization learning: Anonymized incident patterns (with consent) to build collective intelligence
- Custom LLM fine-tuning: Train specialized models on SRE remediation patterns
Vigil isn't just a tool—it's a shift in philosophy. From reactive to proactive. From firefighting to oversight. From "Human-in-the-Loop" to "Human-on-the-Loop."
Always watching. Always healing.
Built With
- anthropic-claude-api
- coder
- docker
- express.js
- google-gemini-api
- kubernetes
- lightpanda
- node.js
- pagerduty-api
- postgresql
- puppeteer
- redis
- sanity-cms
- skyflow
- slack-api
- terraform



Log in or sign up for Devpost to join the conversation.