🚀 Inspiration
We started with a simple goal: build an optimized, production-grade LLM deployment system inspired by AWS Neuron’s efficiency principles.
While many AI demos focus on model accuracy, we wanted to tackle a deeper question — what makes an AI system actually performant in the real world?
In production, raw compute power is only part of the story. True performance comes from system-level optimization — caching, load balancing, observability, and resource management.
So instead of chasing hardware upgrades, we focused on architectural efficiency: designing a scalable, transparent, and measurable inference stack that can demonstrate real improvements in throughput, latency, and reliability.
By integrating tools like Docker, NGINX, Prometheus, and the ELK Stack, we built a reproducible, open-source deployment framework that captures the spirit of AWS Neuron’s hardware–software co-design philosophy — achieving quantifiable performance gains through intelligent system design.
⚙️ What it does
Our system deploys ONNX optimized open source LLM as a FastAPI microservice, wrapped with a full observability and performance monitoring stack.
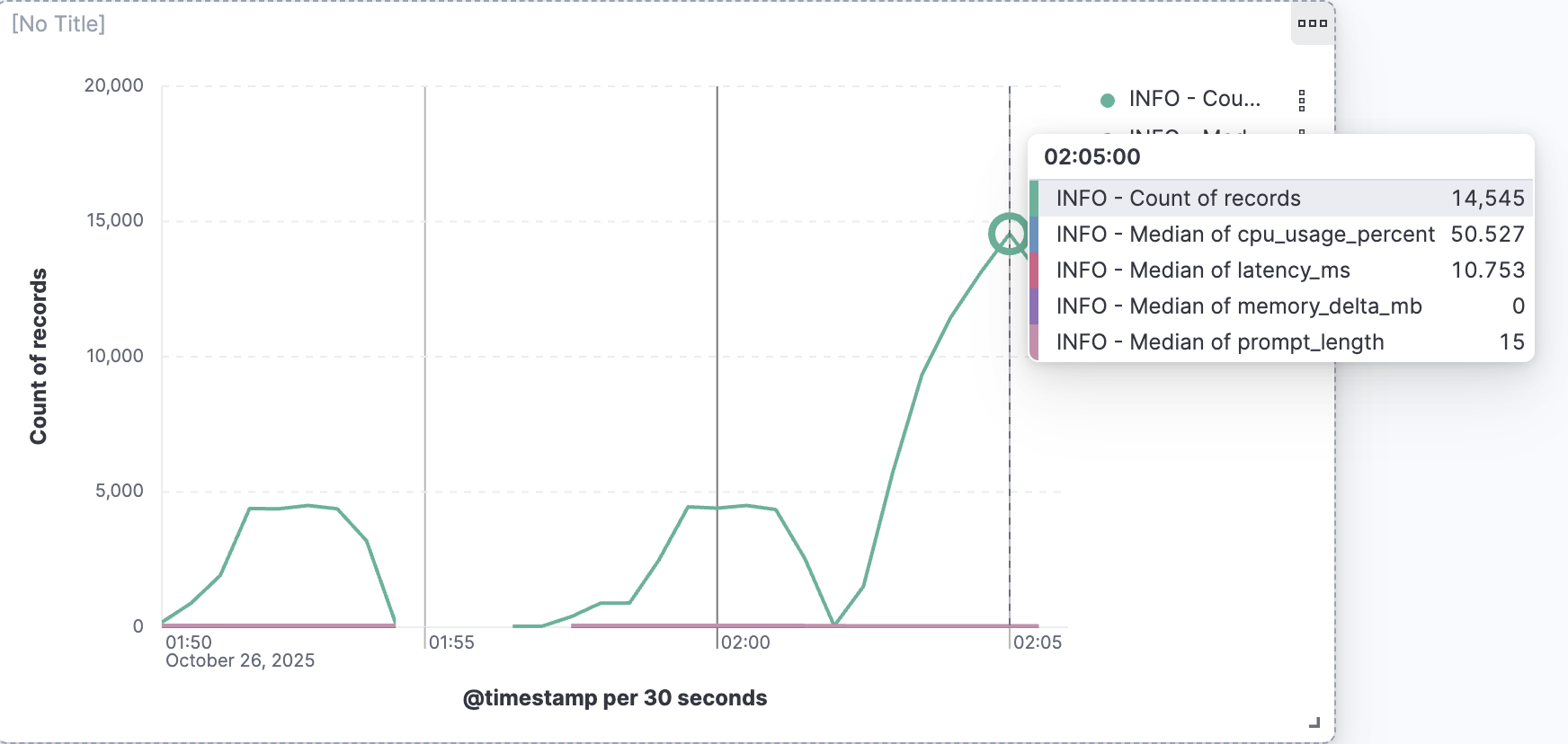
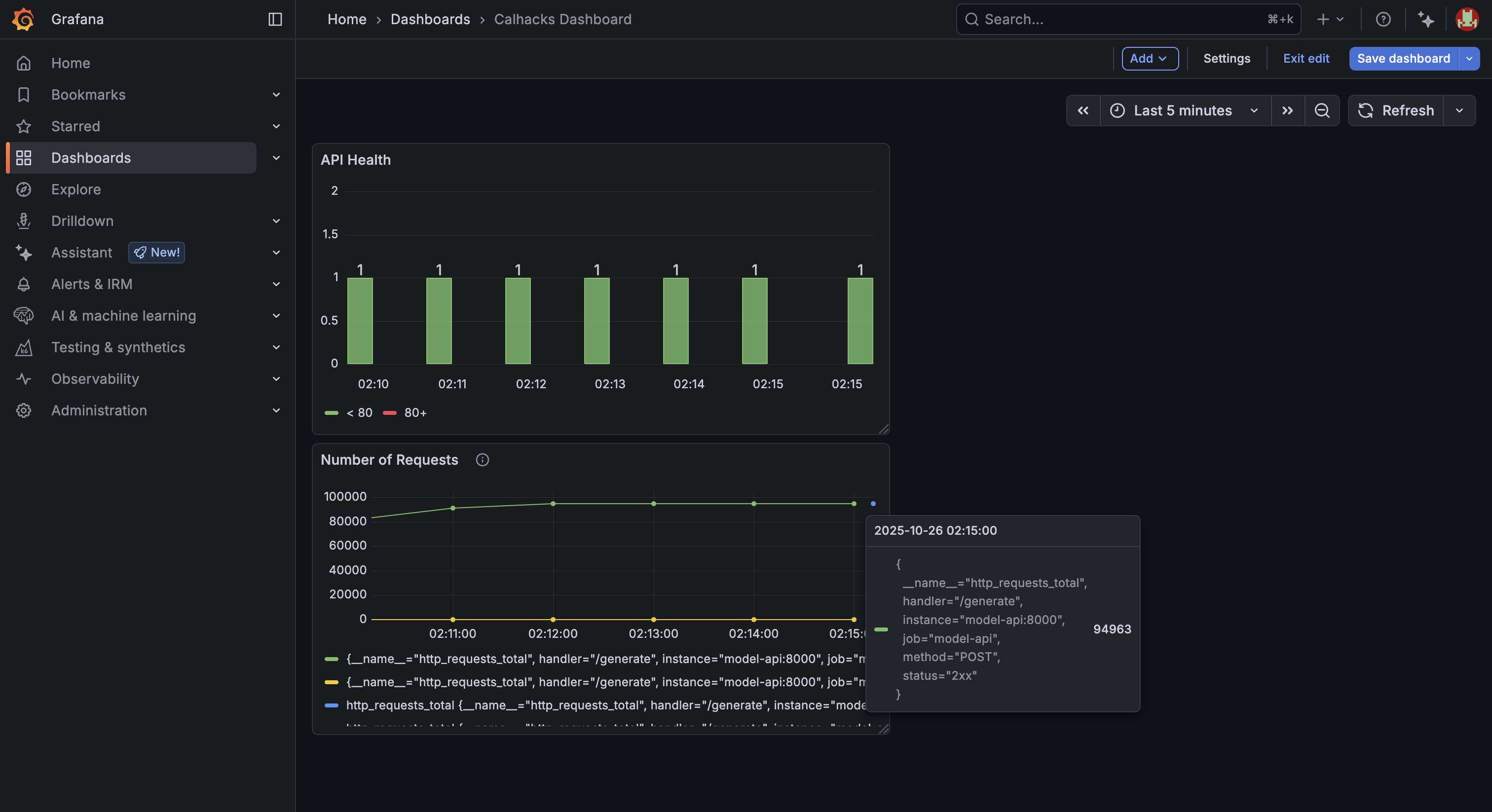
- Real-time metrics: Prometheus scrapes latency, throughput, CPU, and memory every 5 seconds, visualized in Grafana Cloud dashboards
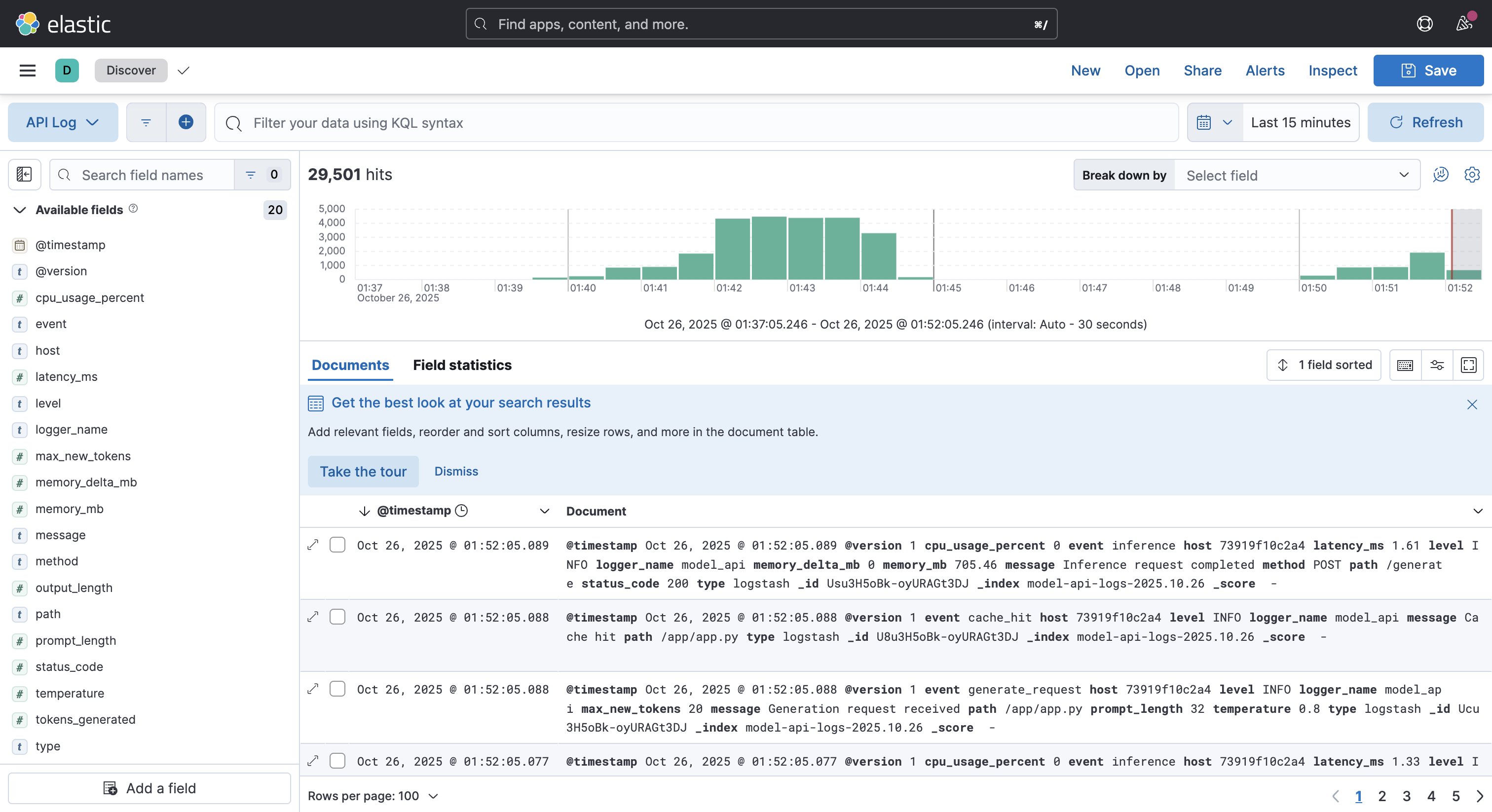
- Structured logging: Every inference request is sent to the ELK stack (Elasticsearch, Logstash, Kibana) with searchable metadata
- Load testing: k6 stress tests validate 50 concurrent users with consistent sub-15 ms latency
- Intelligent caching: MD5-based cache reduces redundant inferences, delivering 11× throughput improvement
- Health monitoring: Automated alerts track downtime, latency spikes, and error rates
Result:
📈 485 req/s peak throughput ⚡ 10.8 ms median latency 🟢 100% uptime under load
🏗️ How we built it
🧩 Architecture Stack
- FastAPI – REST API with async inference handling
- ONNX Runtime – optimized CPU inference engine
- Docker Compose – orchestrates six core services (API, NGINX, Prometheus, Elasticsearch, Logstash, Kibana)
- NGINX – load balancing for concurrent API replicas
- Prometheus + Grafana Cloud – live metrics collection and alerting
- ELK Stack – centralized structured logging and visualization
- k6 – automated load and stress testing
🔑 Key Implementation Details
1️⃣ CPU-Optimized Inference:
An Open Source LLM (GPT2) runs efficiently via ONNX Runtime on CPU, proving optimization can replace brute-force GPU scaling.
2️⃣ Response Caching:
Autoregressive inference is slow; MD5-based caching with a 100-entry limit accelerates repeated queries.
cache_key = hashlib.md5(f"{prompt}_{max_tokens}_{temp}".encode()).hexdigest()
if cache_key in response_cache:
return response_cache[cache_key]
Built With
- amazon-web-services
- docker
- elasticsearch
- fastapi
- grafana
- huggingface
- onnx
- prometheus
- python
- transformer



Log in or sign up for Devpost to join the conversation.