-
-
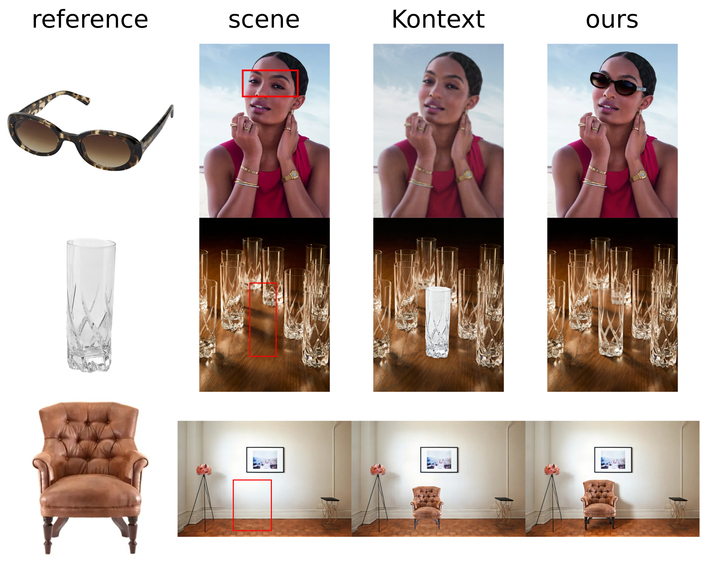
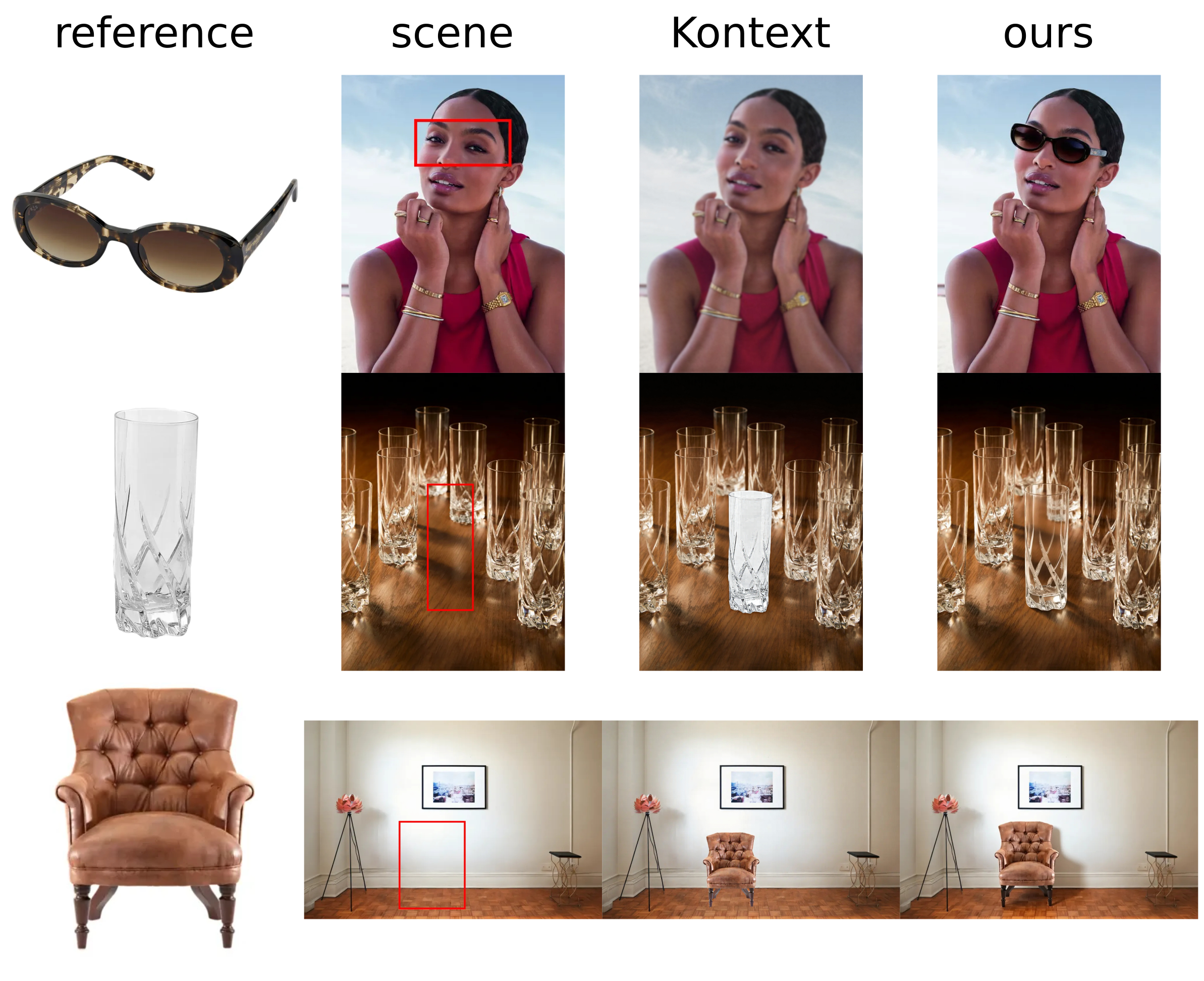
Comparison with raw Flux Kontext
Inspiration
Our company is working on image editing, with a focus on lightweight specialist models able to deliver higher quality and more control that generalist models, while being cheaper.
What it does
Our LoRA makes it possible to insert products into photos, as if they had always belonged. To do so, it extends FLUX Kontext [dev] with multi-image input support.
How we built it
We wrote a full blog post detailing the training procedure: https://blog.finegrain.ai/posts/product-placement-flux-lora-experiment/
Challenges we ran into
Super hard to gather high quality before / after pairs.
Accomplishments that we're proud of
We delivered an open source proof-of-concept, with a public Hugging Face space.
What we learned
- Consistency is critical in before/after pairs: e.g., objects must be in the exact same state in reference and ground-truth images (avoid lamp on vs. off, empty vs. full glass, ...)
- Text-only prompts are insufficient for fine-grained spatial control (placement & scale) - also, automatic annotations often lack accuracy and/or clarity.
- Leveraging FLUX Kontext’s visual cue capability with bounding boxes gives predictable placements.
- Hard to avoid burning base model capacity, especially around textures.
- Challenging to achieve strong relighting/perspective correction while preserving the subject with high fidelity.
What's next for Product Placement LoRA
Further time is needed to boost quality. We might do it if people get as excited as we are about this capability!
Built With
- amazon-web-services
- diffusers
- fiftyone
- finegrain
- pytorch




Log in or sign up for Devpost to join the conversation.