Inspiration
Every product team has lived this moment: a PRD ships with a confident claim, a feature request that quietly contradicts another, and three weeks later the support queue is full of evidence nobody connected back to the original assumption. We wanted to build the tool that catches this before it ships — not by summarizing a document, but by actually arguing about it, the way a real product council would.
We also wanted to answer a harder question: can an AI tool tell you something true that wasn't explicitly in your prompt? Most AI products are one good prompt away from being replicated in five minutes. We didn't want to build that.
What it does
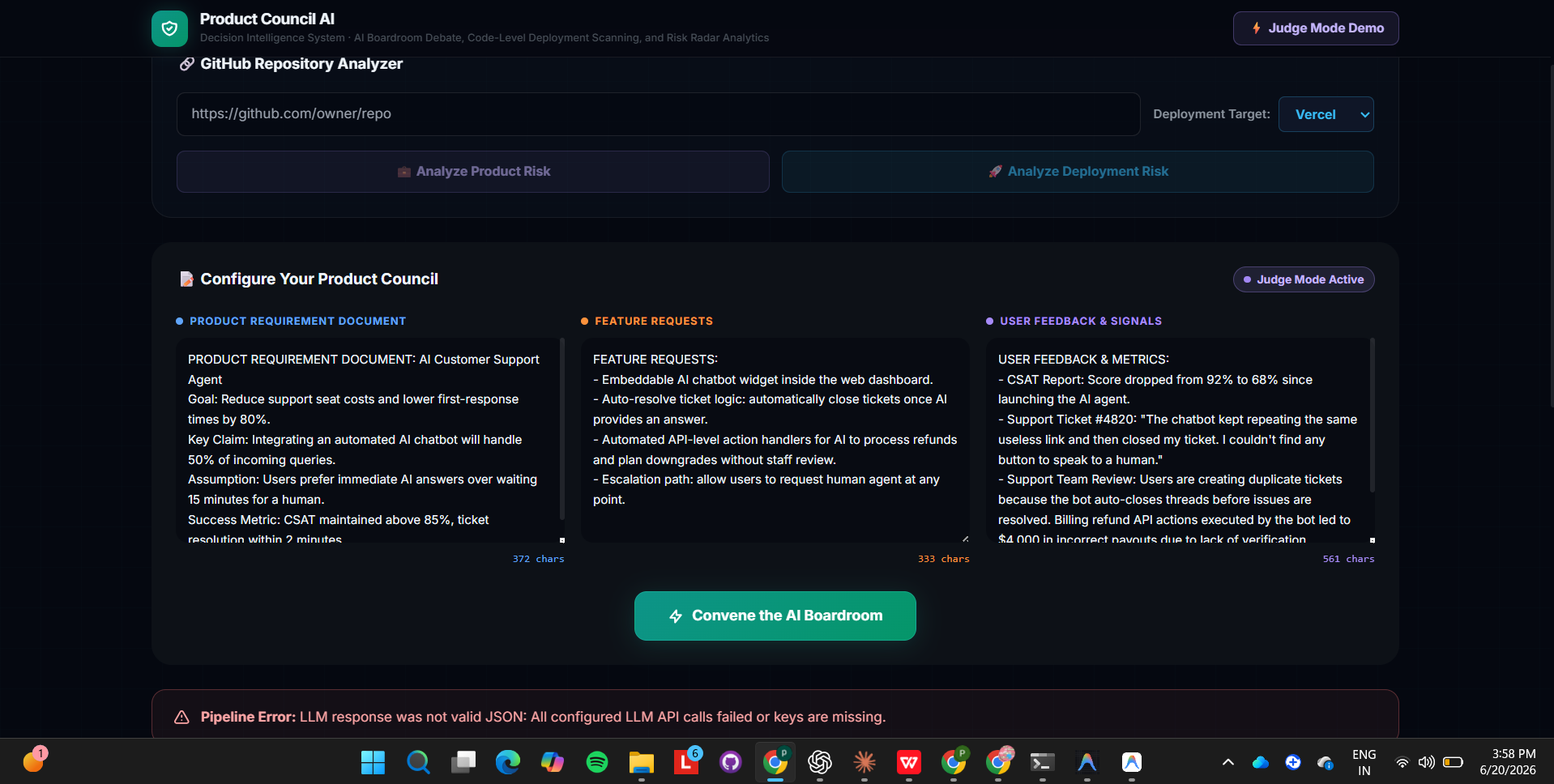
Product Council AI takes a single GitHub repo URL (or a pasted PRD, feature list, and feedback) and runs it through a multi-stage decision intelligence pipeline:
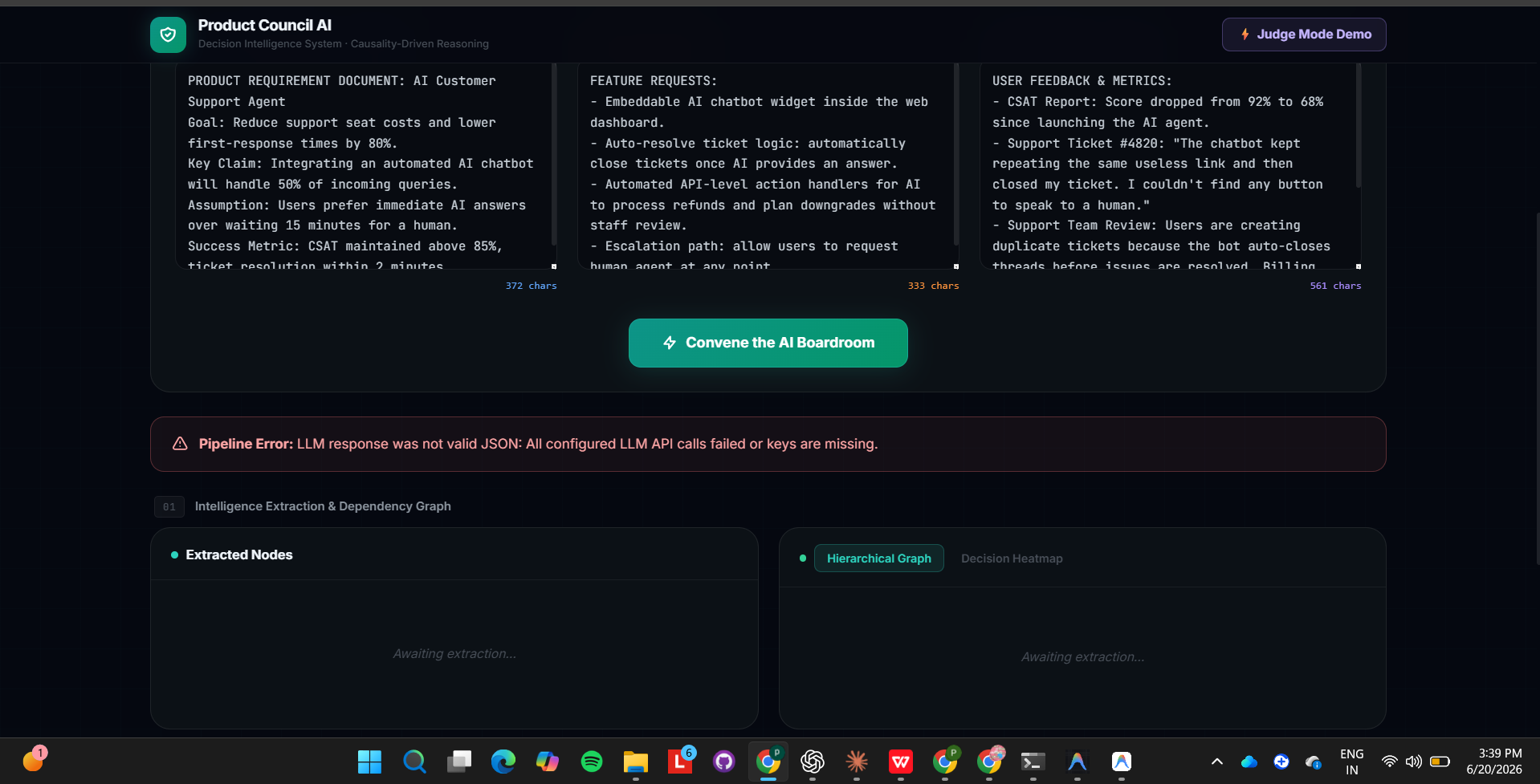
- Extraction & Dependency Graph — parses the input into atomic claims, assumptions, requirements, and feedback signals, then builds a real dependency graph between them and detects which nodes are stale (contradicted by feedback) or contested.
- AI Boardroom Debate — three distinct AI personas (Growth Optimist, Engineering Realist, User Advocate) debate every stale or contested item sequentially, each one reading and rebutting the previous agent's actual argument, not generating an isolated opinion.
- Deployment Intelligence — fetches real source files,
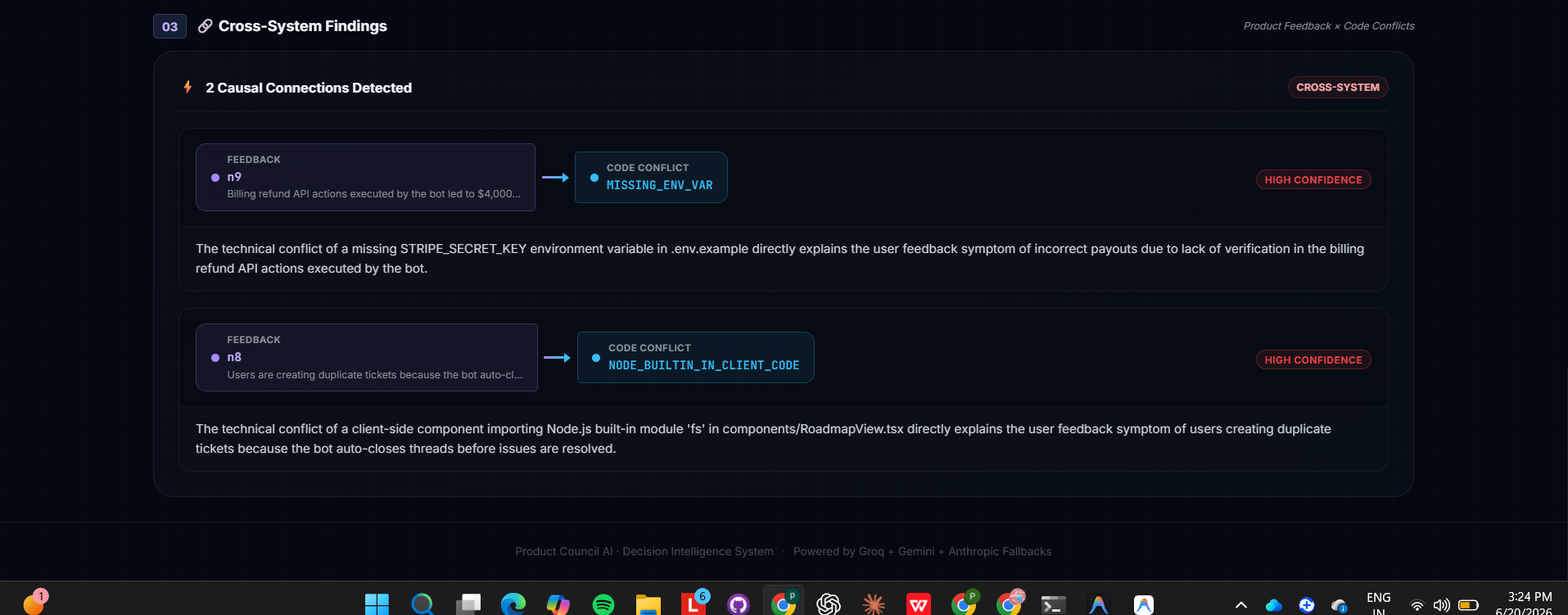
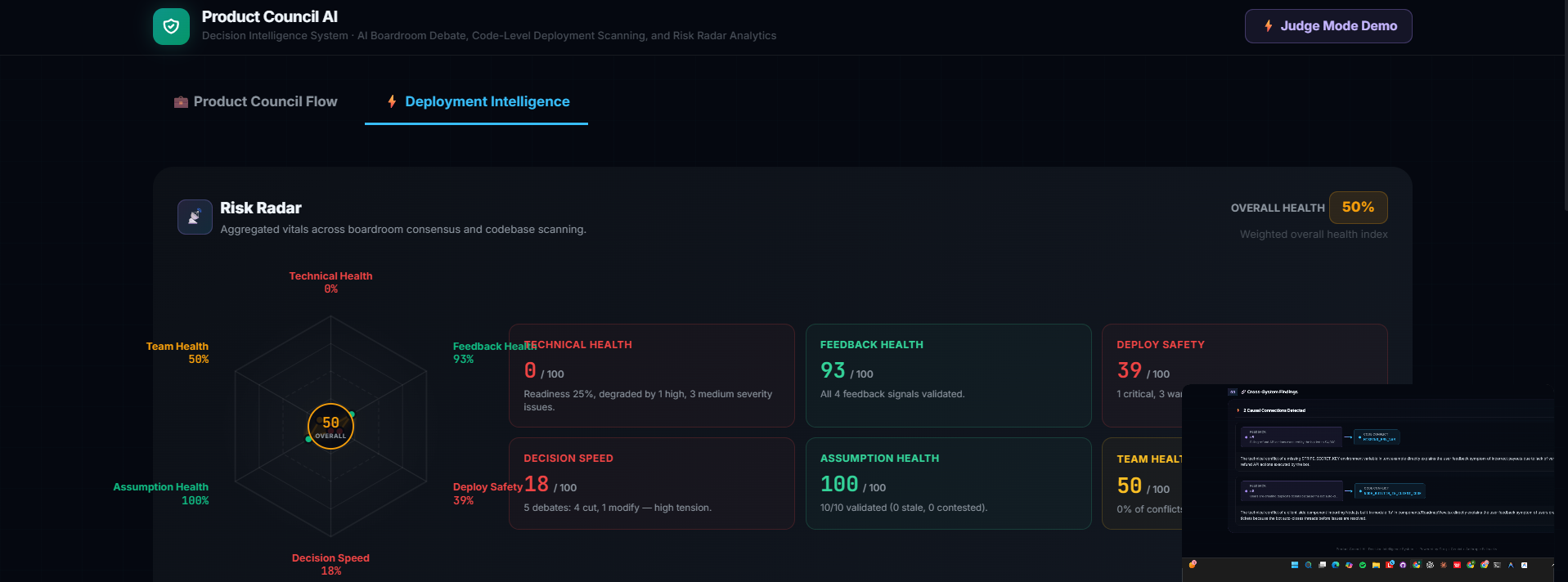
package.json, and the import graph from the actual codebase, and runs static analysis to detect platform-specific deployment risks (client code importing Node-only modules, missing env vars referenced in code but absent from config, peer dependency conflicts) — scored against a chosen deployment target (Vercel/Netlify/Railway). - Cross-System Findings — the feature we're proudest of: the system cross-references the product feedback signals against the code-level conflicts independently, and surfaces causal connections neither subsystem was looking for on its own (e.g. a customer complaint about broken refunds, matched automatically to a missing Stripe environment variable in the refund logic).
- Risk Radar — aggregates every subsystem's output into one live health score across six axes, updating in real time as each analysis stage completes.
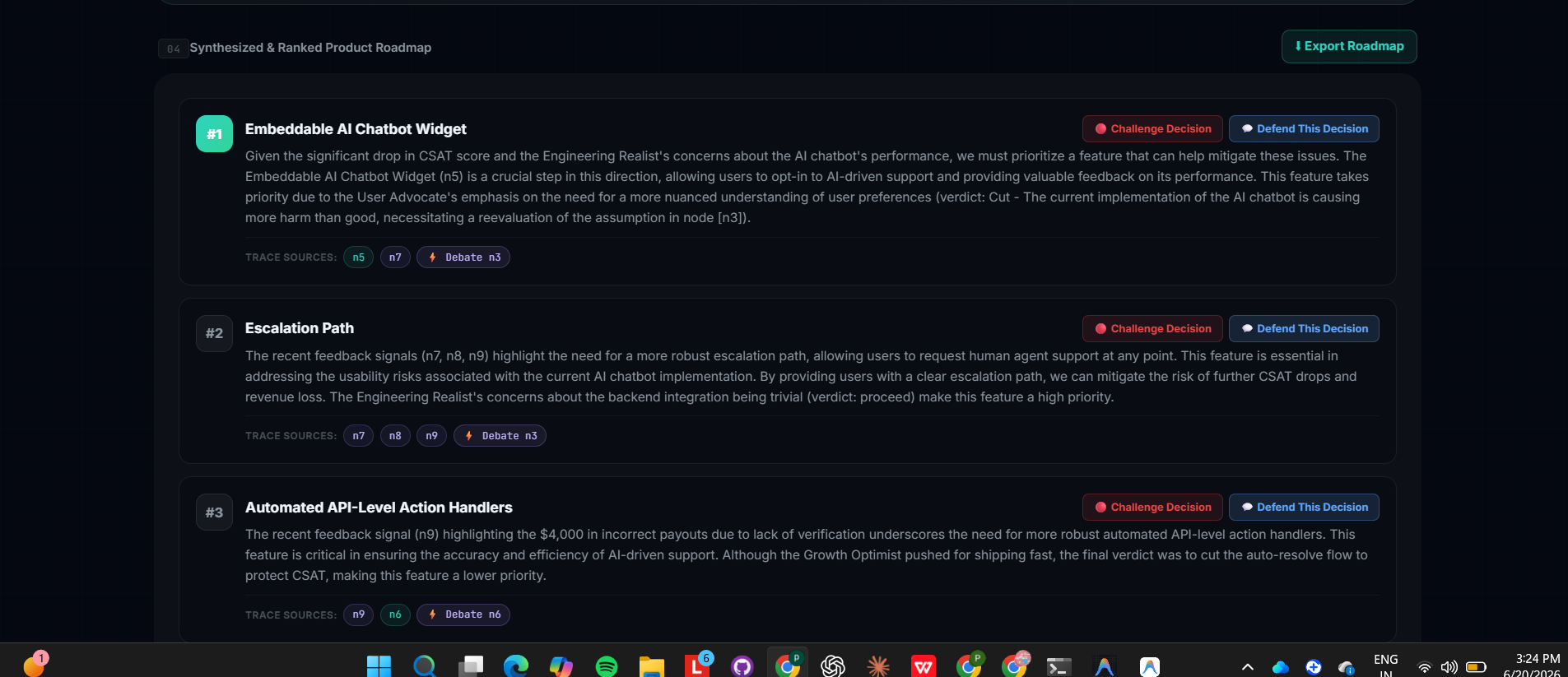
- Synthesized Roadmap — a final ranked roadmap where every item traces back to specific debate verdicts and specific graph nodes, so no recommendation is unexplained. ## How we built it The pipeline runs as a sequence of typed stages (TypeScript types shared across the app) rather than a single prompt: Extract → Graph → Debate → Deployment Scan → Cross-System Correlation → Synthesize. Each stage either does real deterministic computation (graph traversal via BFS for contradiction paths, regex-based import parsing, chronological merging of commit/issue timelines) or a tightly scoped LLM call constrained to reason only over data the previous stage already produced — never inventing new facts. The debate stage specifically chains API calls sequentially rather than in parallel, so each agent's prompt includes the previous agent's literal text and is instructed to rebut a specific point, producing genuine disagreement instead of three independent monologues.
The frontend is a single connected experience — Product Council Flow and Deployment Intelligence as two views of the same analysis, with a Risk Radar that visibly redraws as each subsystem completes, so the product never feels like separate tools bolted together.
Challenges we ran into
Getting multi-agent debate to feel alive instead of scripted was the hardest part — early versions had three agents giving parallel, non-interacting opinions that read as fake within seconds. Restructuring the calls to be strictly sequential, with each agent required to quote or directly address the previous agent's point, was the single change that made the biggest difference.
Parsing real import graphs from arbitrary repositories with regex (rather than a full AST parser) meant accepting imperfect coverage — we optimized for catching the common 80% of import patterns cleanly without crashing on the harder 20%, rather than chasing full correctness.
I also had to be deliberate about keeping every LLM call grounded: the Cross-System Findings feature is explicitly instructed to report "no correlation found" rather than force a connection, since a tool that always finds something stops being trustworthy.
Accomplishments that we're proud of
Building this from scratch and deployin this.
What we learned
The line between "an AI wrapper" and "a real system" isn't about how many LLM calls you make — it's about whether the system holds state and structure that a single chat prompt structurally cannot have access to. The moments that made testers say "wait, how did it know that" were never the LLM calls alone — they were the moments where two independently-computed real datasets (user feedback and static code analysis) were joined in code and handed to the model only to explain, not to invent.
What's next for Product Council AI
Real GitHub write-back (auto-generating PRs for suggested fixes), authenticated multi-repo comparison, and extending Deployment Intelligence with deeper AST-based parsing instead of regex.
Built With
- anthropic-claude-api
- d3.js
- github-rest-api
- next.js
- react
- tailwind-css
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.