-
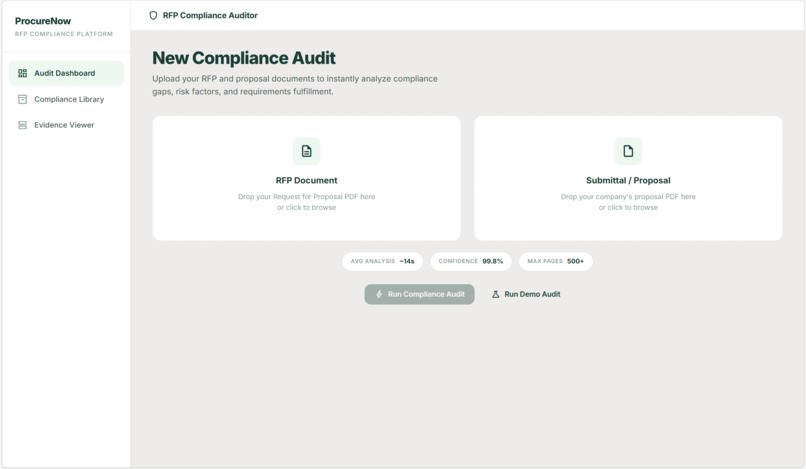
Audit Dashboard
-
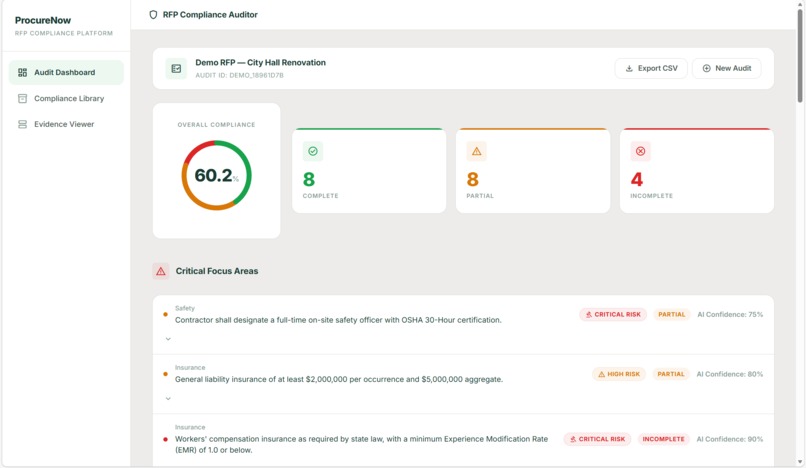
Report
-
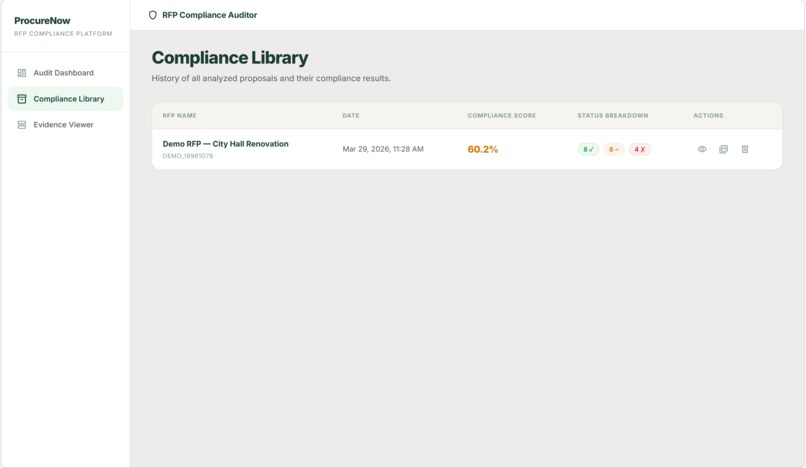
Compliance Library
-
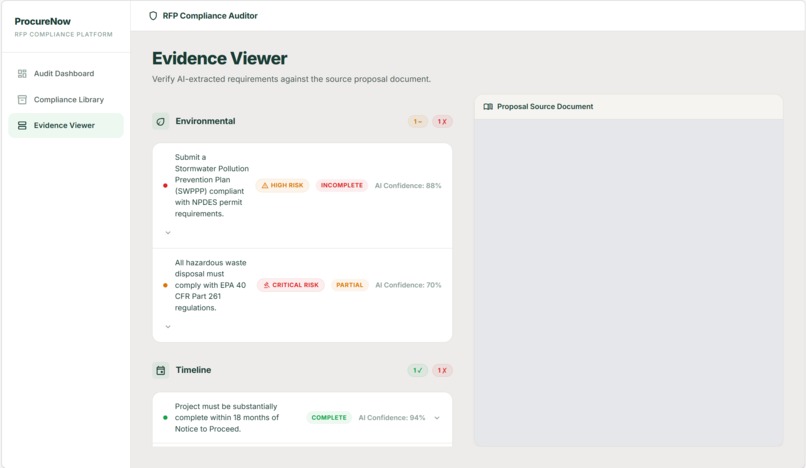
Evidence Viewer
Inspiration
ProcureNow was inspired by a very real and costly problem in construction and public procurement: missing a single requirement in an RFP can disqualify an otherwise strong proposal. Various missing or incomplete things are often caught too late, after submission or during formal evaluation. The idea was to build a system that acts like a “first-pass compliance auditor,” giving teams immediate feedback before those mistakes cost the entire project
How we built it
ProcureNow was built as a full-stack application centered around a four-phase AI pipeline:
Backend (FastAPI): Handles PDF ingestion, processing, audit orchestration, and persistence. Frontend (vanilla JS dashboard): Provides a simple interface for uploading documents and reviewing structured audit results. AI Layer (Gemini): Used for document understanding, requirement extraction, and compliance evaluation.
The pipeline works as follows:
Multimodal Ingestion: PDFs are converted into structured, page-aware markdown using Gemini’s file API (with a fallback to PyMuPDF if Gemini is unavailable). RFP Parsing: The system extracts a structured list of requirements from the RFP and optionally builds a page map of the proposal. Auditer: Requirements are evaluated in batches against the proposal using a rubric (Presence, Accuracy, Context), producing detailed compliance objects. Reporting & Storage: Results are aggregated into an AuditReport, saved in SQLite, and exported as CSV/PDF for downstream use.
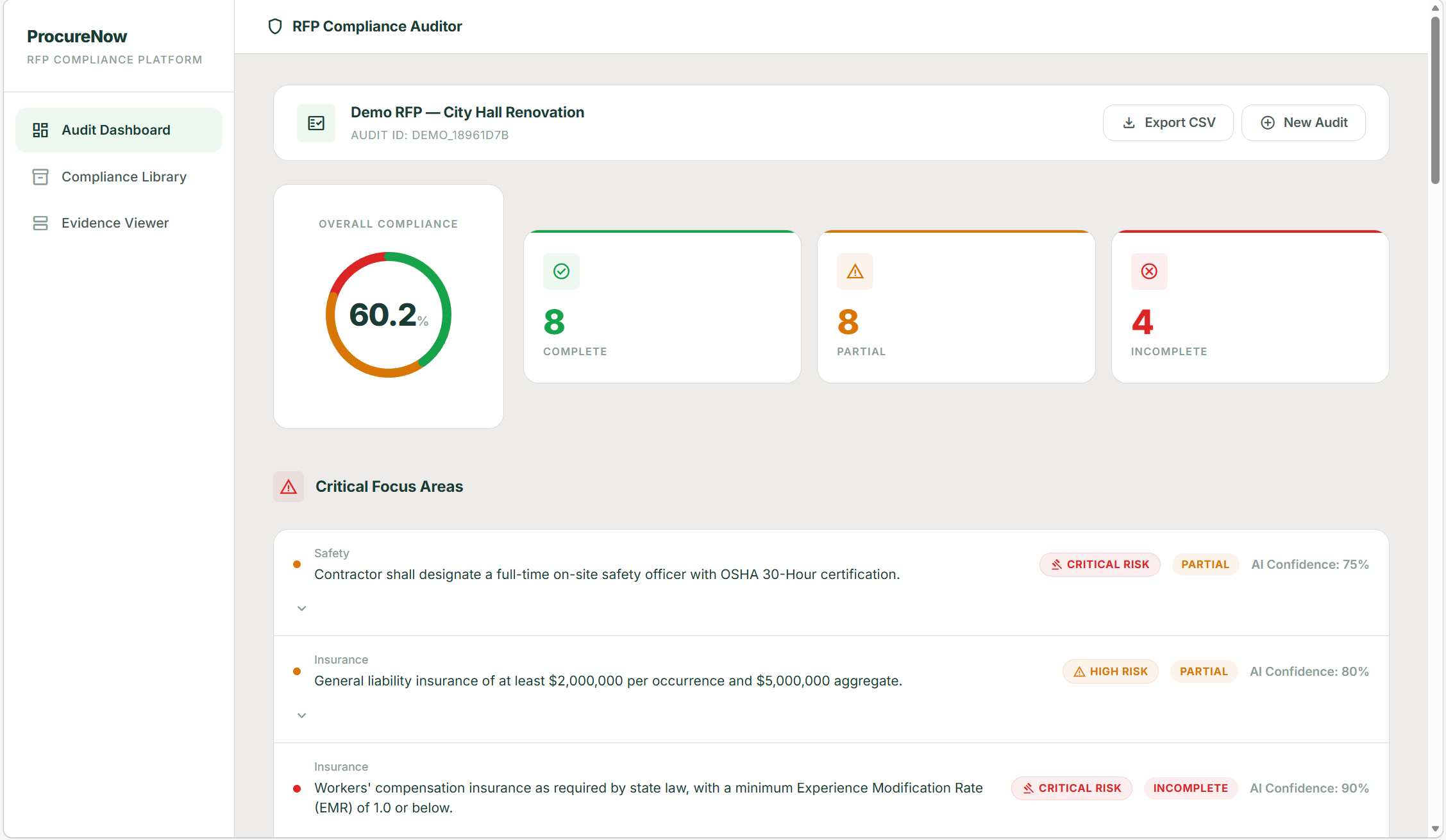
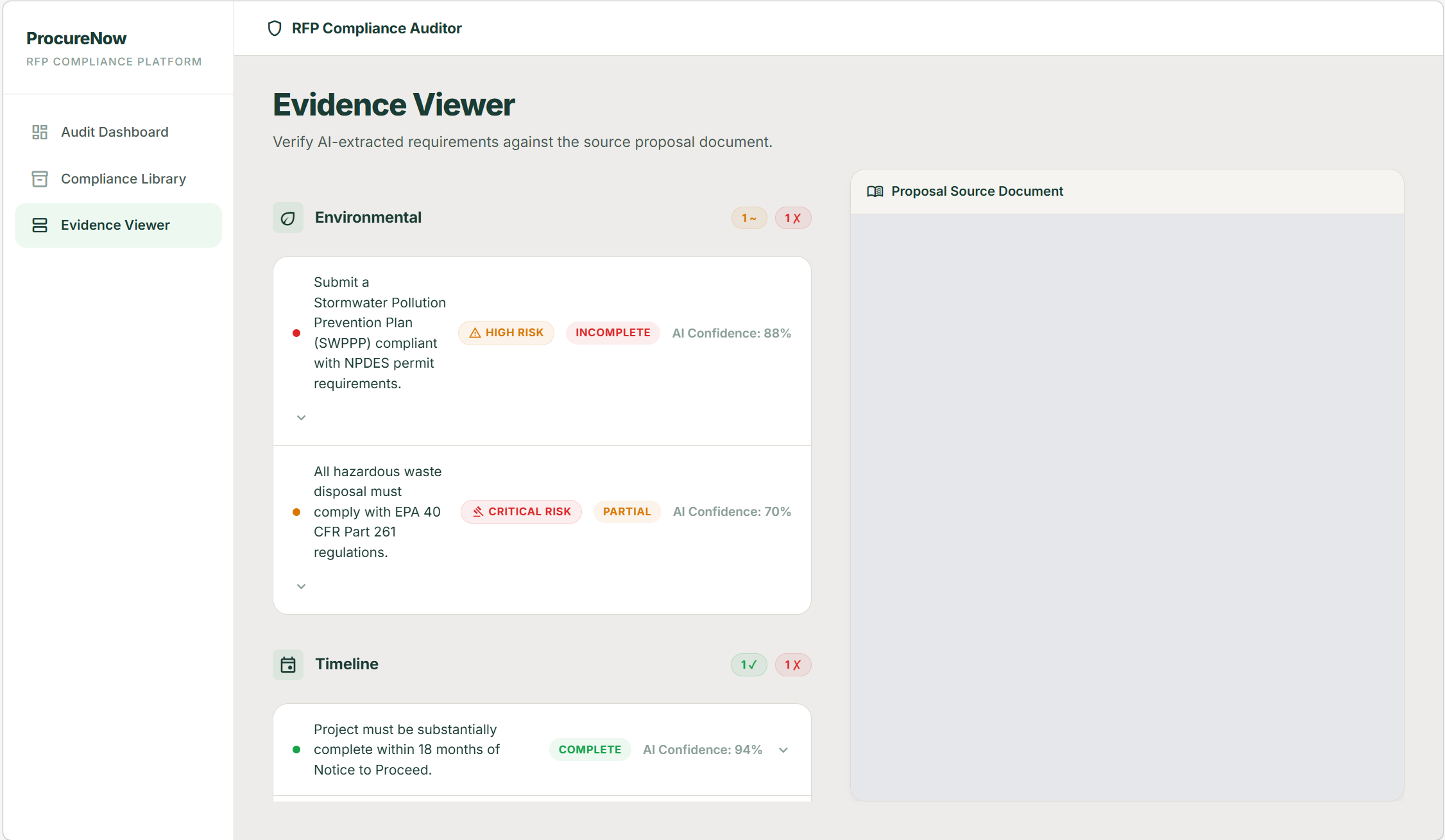
We focused heavily on making the output actionable. Each requirement includes evidence snippets, page references, confidence levels, and risk notes, not just a pass/fail label.
Challenges we ran into
The hardest challenges were around document variability and context management. RFPs and proposals are long, inconsistent, and often poorly structured. Even with page markers and batching, ensuring the model had the right context for each requirement was non-trivial.
Another challenge was partial implementation gaps. For example, we built infrastructure for section-based routing using a TOC/page map, but the current audit loop still relies mostly on full-document excerpts. Closing that gap to make audits more precise is an ongoing improvement.
We also ran into API and performance constraints, especially with large PDFs. This required truncation strategies, batching, and retry logic to keep the system stable.
Finally, aligning the frontend and backend contracts (like the CSV export endpoint) highlighted the importance of keeping interfaces tightly synchronized in a fast-moving project.
What we learned
One of the biggest takeaways was how complex “compliance” actually is. It’s not just about keyword matching. It requires context, interpretation, and structured reasoning. Designing prompts and schemas that consistently produce reliable, structured outputs was a big learning experience.
We also learned how to balance flexibility with structure. RFPs vary wildly in format, so building a system that can generalize across them, while still producing clean, tabular outputs—required careful schema design and batching strategies.
On the engineering side, we gained experience with:
. Multimodal document processing . Prompt engineering for structured JSON outputs . Designing resilient pipelines with fallbacks and retries . Bridging AI outputs with traditional systems like databases and exports

Log in or sign up for Devpost to join the conversation.