-
-
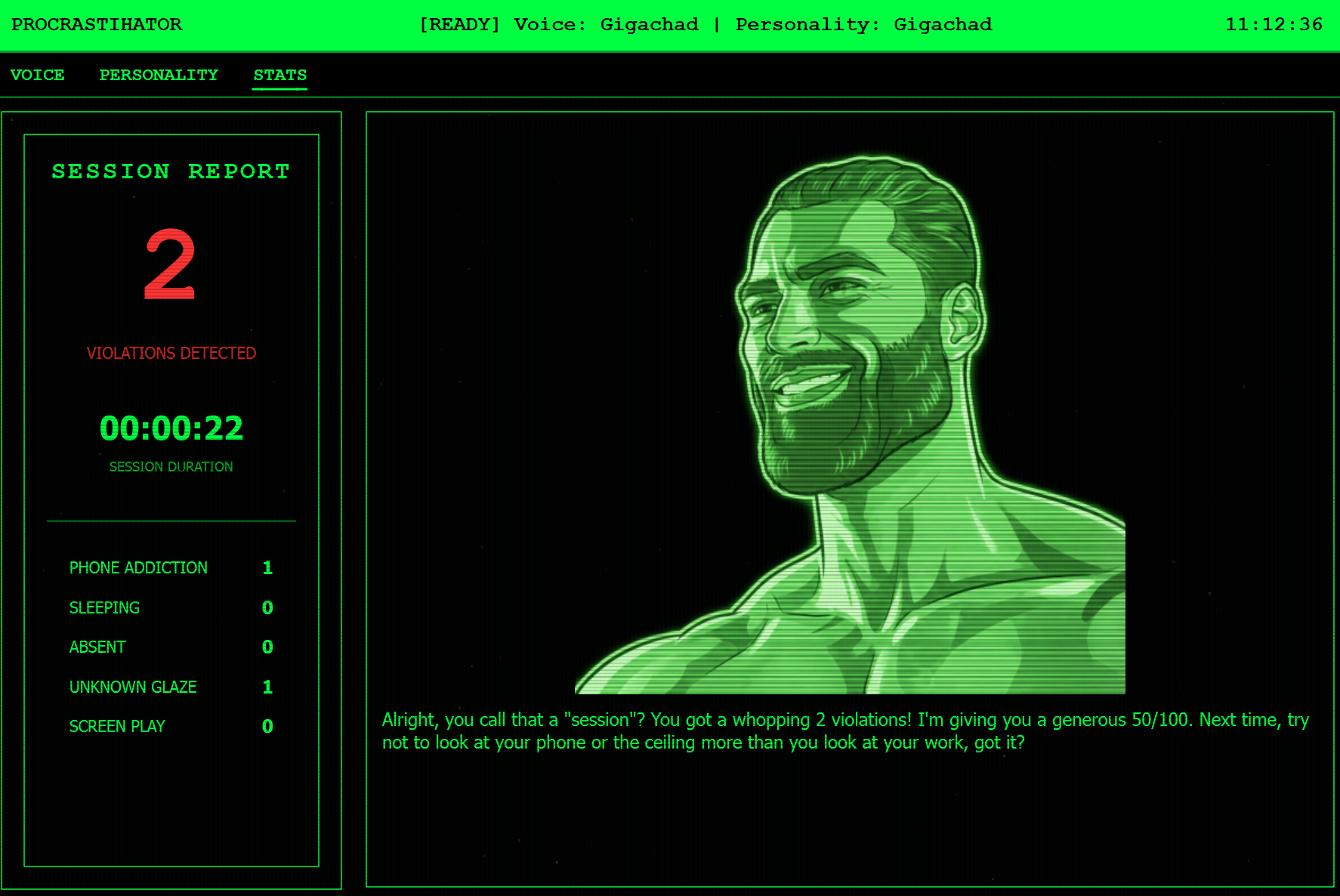
Personality - GigaChad
-
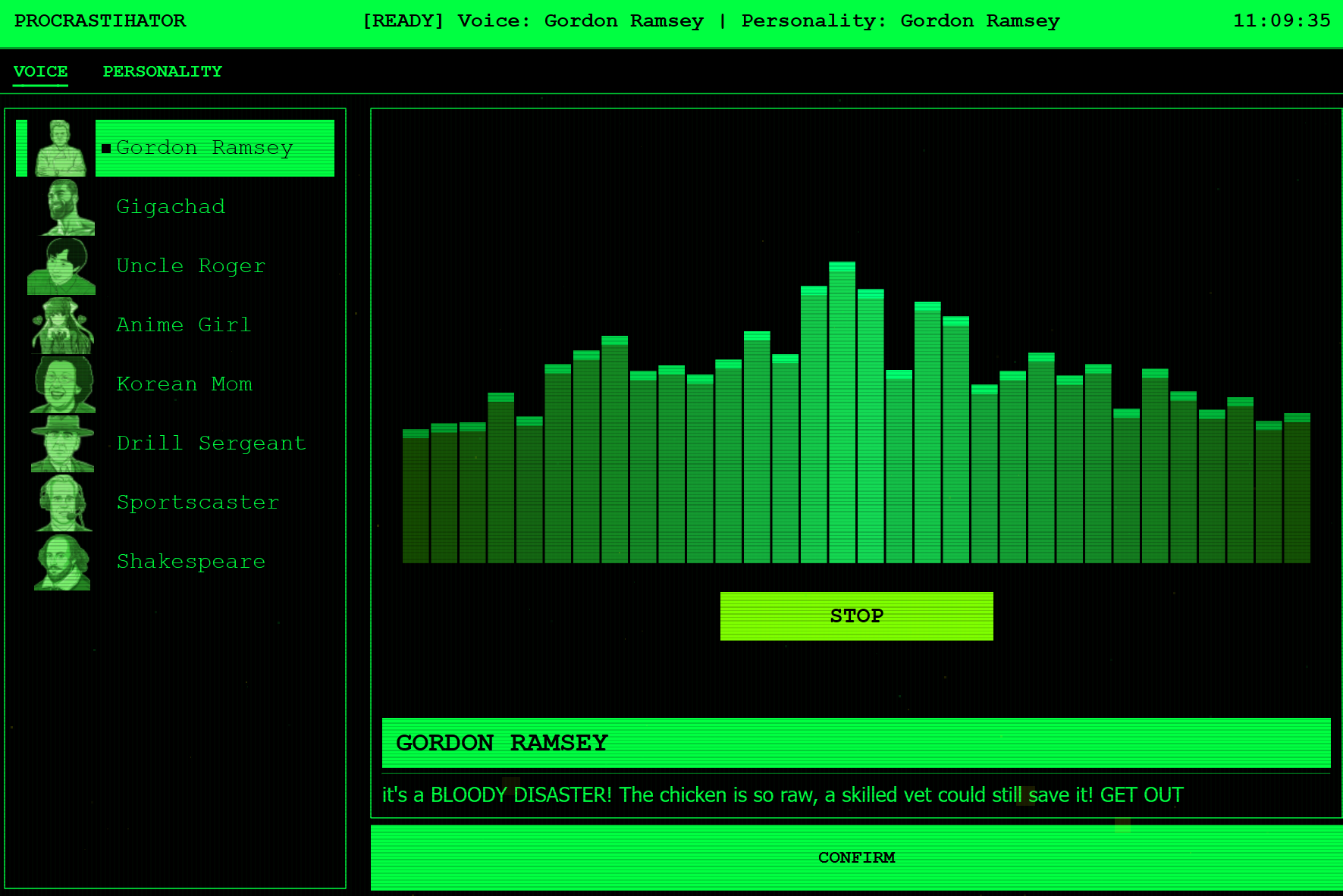
Personality - Gordon Ramsey
-
Voice sample
-
Draggable floating widget
-
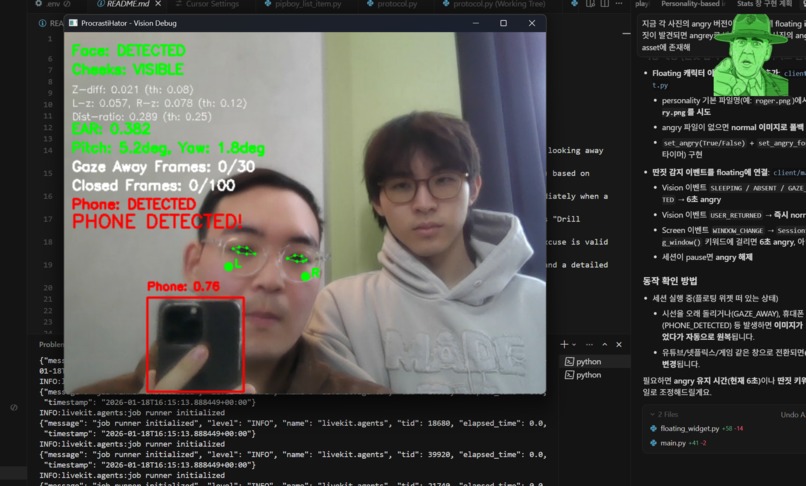
Computer vision processing
-
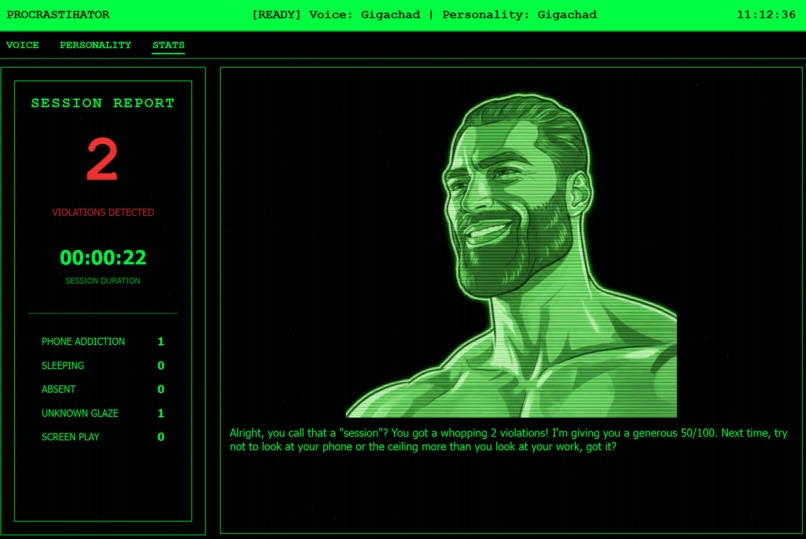
Session report
Inspiration
We’ve all been there: "I'll just watch one YouTube video," and suddenly it's 3 AM. Traditional productivity timers like Pomodoro are too passive—they rely on our willpower. But willpower fails. We realized that what we actually needed wasn't a gentle reminder; we needed a boss, a drill sergeant, or a terrifyingly strict parent watching over our shoulders. We wanted to build an AI that doesn't just track time but actively watches, judges, and verbally assaults you into being productive.
What it does
Procrasti-Hater is a real-time surveillance agent that forces you to focus. Once you start a session, it constantly monitors you through two channels:
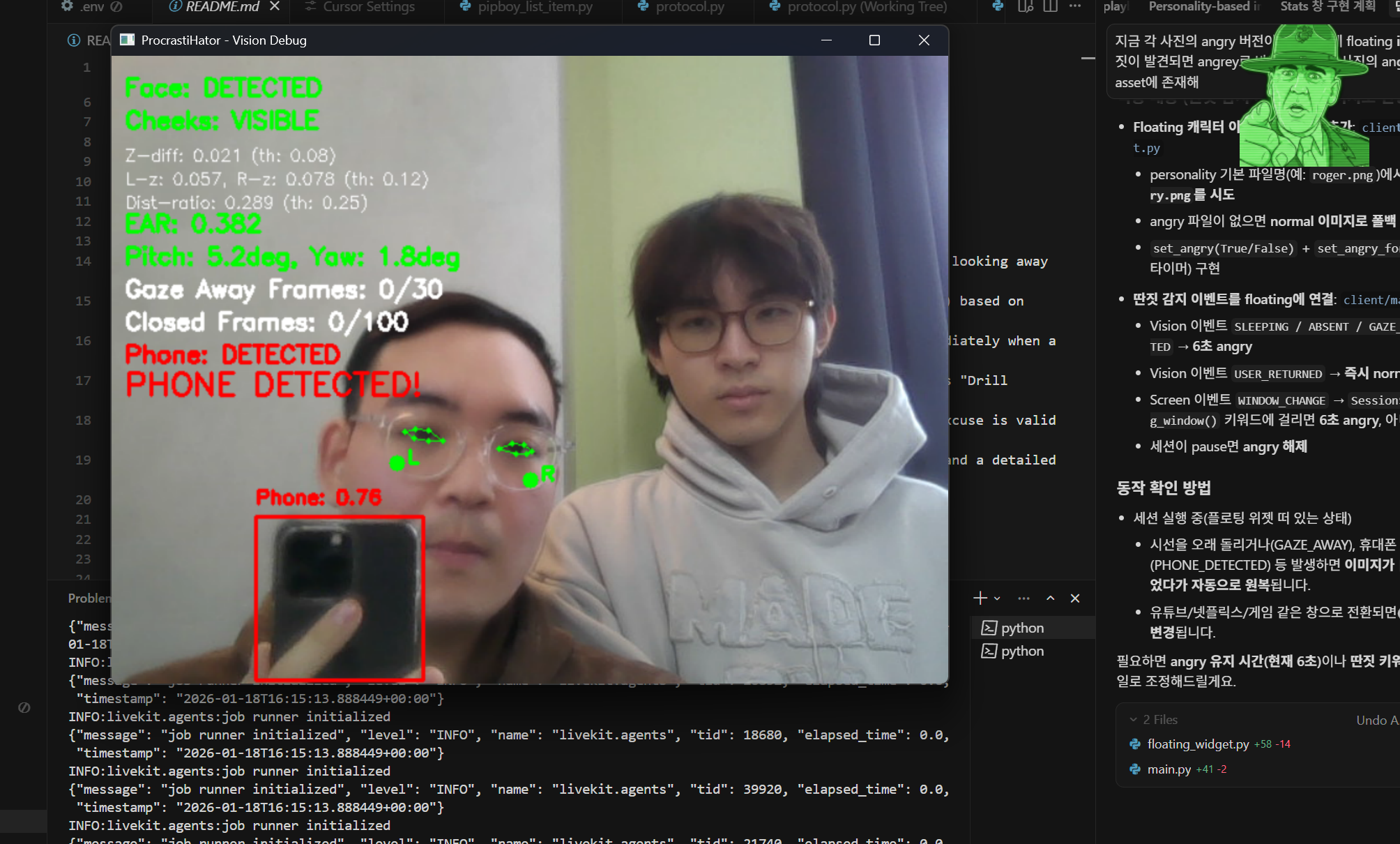
- Vision Tracking: Uses the webcam to detect if you are holding a phone, sleeping (eyes closed), absent, or looking away from the screen for too long.
- Screen Monitoring: Tracks your active window. If you switch to Netflix, Instagram, or X, it knows instantly.
When you slack off, the AI interrupts your peace. It mutes your audio and uses a distinct Persona (e.g., GigaChad, Gordon Ramsay, Korean Mom) to deliver a personalized, ruthless verbal scolding generated by an LLM.
But you can fight back. Using the Push-to-Talk (PTT) feature, you can interrupt the AI's rant to make excuses. Whether you claim "I'm just compiling code!" or "I need a coffee break!", the agent will listen, judge the validity of your excuse, and either let you off the hook or roast you even harder. Finally, it tracks your "Violation Stats" and gives you a humiliating report card at the end of the session.
How we built it
- Client (PyQt6): A retro "Pip-Boy" style UI that manages the webcam feed and user inputs. It captures video frames and processes them locally using MediaPipe for face landmarks and object detection (phones).
- Agent (LiveKit): The backend is built on the LiveKit Agents Framework. It handles real-time audio/video streaming and acts as the brain.
- Monitoring Logic:
- Vision: Using
mediapipeandcv2, we calculate eye aspect ratios (to detect sleep) and 3D face orientation (to detect looking away). - Screen: We hook into the OS window API to categorize active processes into "Productive," "Neutral," or "Distracting."
- Vision: Using
- Intelligence: When a violation is confirmed, we feed the context to Google Gemini. It generates a response based on the selected persona's detailed system prompt.
- Voice: The text is streamed to ElevenLabs for low-latency, high-quality speech synthesis that actually sounds angry or disappointed.
Challenges we ran into
- Real-time Multimodal Sync: Synchronizing the vision events ("User picked up phone") with the screen events ("User opened YouTube") without flooding the LLM was difficult. We had to implement a smart buffering and cooldown system so the agent wouldn't talk over itself.
- Facial gaze detection was tricky: our first approach used mouth-corner landmarks, but talking/expression changes made it noisy and unreliable. We switched to cheek landmarks and detected gaze-away based on cheek visibility (with simple depth/geometry checks), which was far more stable and consistent in real-world use.
- Architecting Elevenlabs Voice Personas: During the early stages of development, we noticed that the voice agent was hypersensitive to subtle word choices. Paradoxically, without a solid high-level framework, the output failed to capture the intended voice. The root cause was focusing on a list of features rather than defining a core identity. we resolved this by establishing a two-sentence high-level framework first, followed by more specific requirements.
Accomplishments that we're proud of
- Privacy-First Architecture: We process 100% of the sensitive video data locally on the client. The AI Agent never sees the user's raw webcam feed—it only receives text signals like PHONE_DETECTED or SLEEPING. We proved we could build an invasive surveillance tool without actually invading the user's data privacy.
- Persona Fidelity: It’s genuinely funny (and scary) to be yelled at by a Gordon Ramsay voice about how my code is "RAW" because I opened Instagram.
- Latency: The pipeline from detecting a phone to hearing the scolding feels almost instantaneous, preserving the immersion of being watched.
What we learned
- LiveKit Architecture: We learned how to build stateful, real-time agents that don't just respond to text, but respond to events in the physical world.
- The Power of Hybrid Compute: By offloading heavy vision tasks to the client (mediaPipe on local CPU) and intelligence tasks to the cloud (LiveKit/Elevenlabs), we achieved a sweet spot of privacy, low latency, and high capability that wouldn't be possible with a purely server-side approach.
- The Importance of Practical Structuring: We initially focused on organizing our logic through READMEs and comments. However, as the project scaled, we faced technical challenges such as cross-file variable dependencies and redundant function calls. Refactoring our code to remove overlaps and refine connections taught us the true value of organic code structure, allowing us to build a more scalable and efficient system.











Log in or sign up for Devpost to join the conversation.