-
-
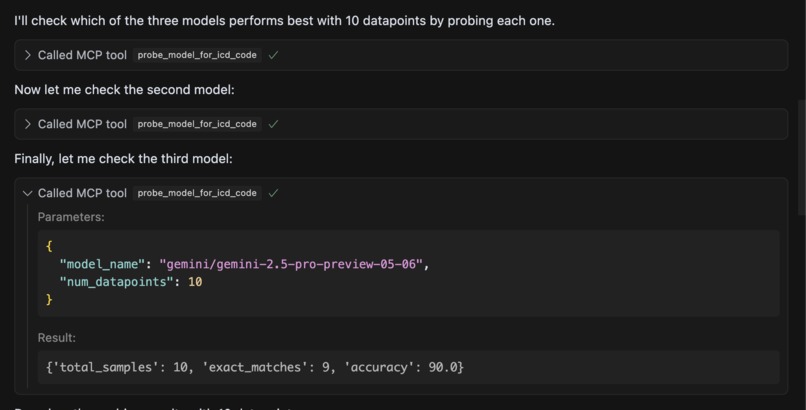
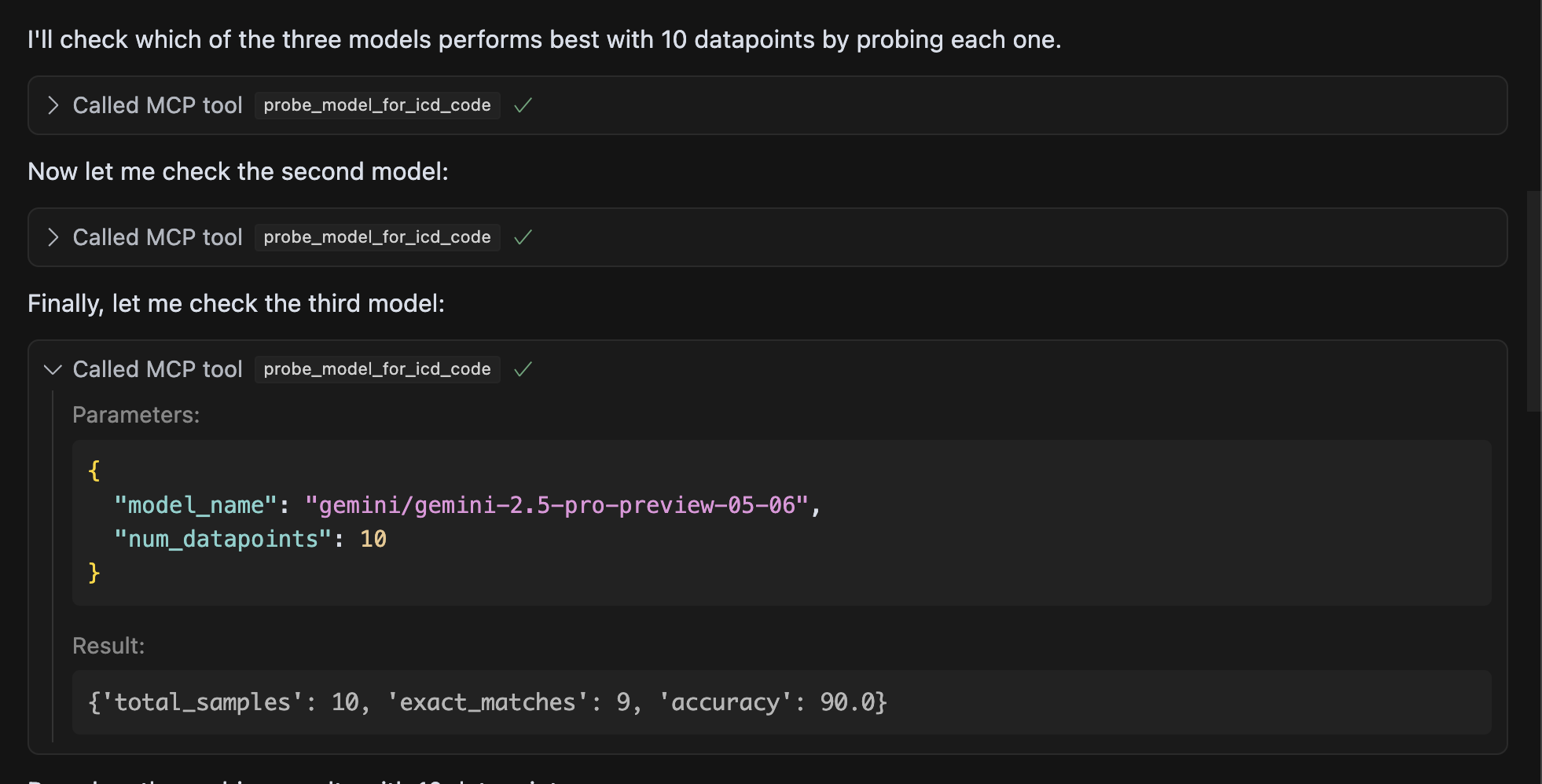
MCP server accurately identifying high performing model
-
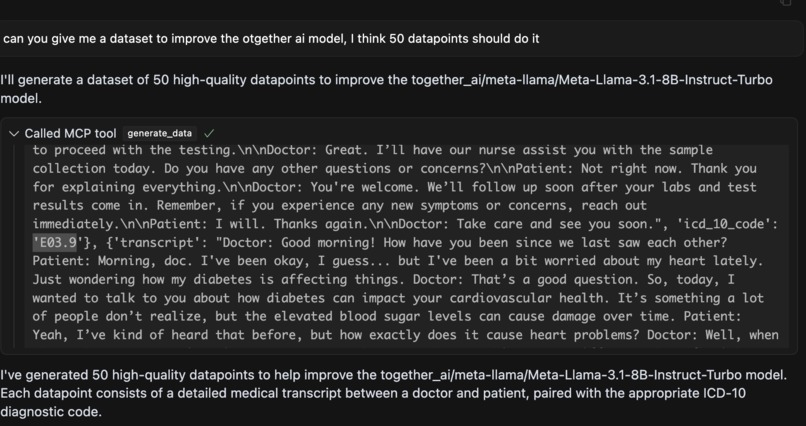
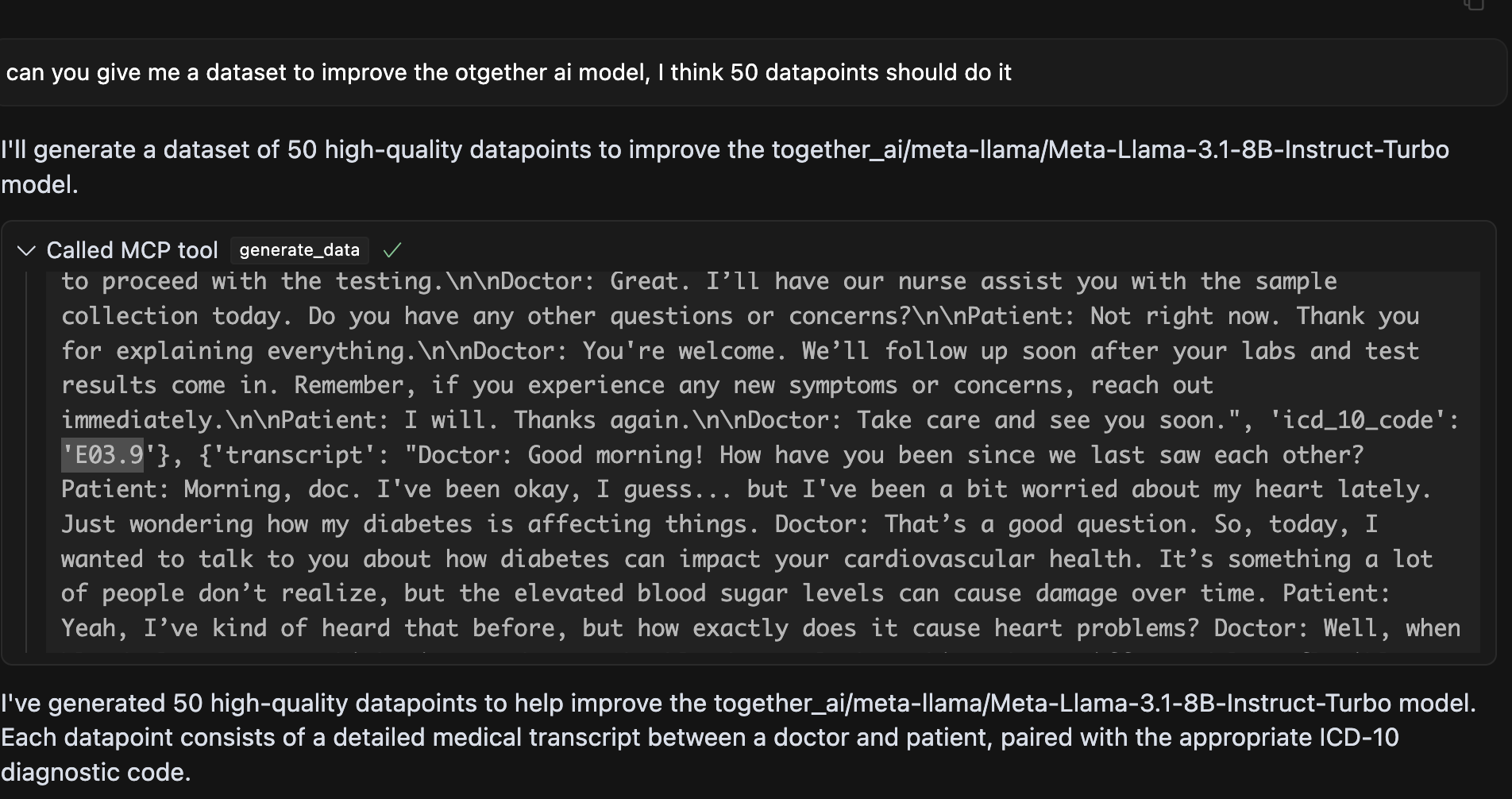
Dataet gen
Inspiration
ICD-10 coding is notoriously complex and high-stakes—each clinical diagnosis must be translated into one of ~70,000 codes, often governed by nuanced, payor-specific rules. Errors can lead to massive fines or audits. We wondered: How well do current models handle this task? How can we fix them when they fall short?
What it does
Our MCP tool:
- Evaluates how well any LLM performs ICD-10 coding from medical transcripts (model probing).
- Generates targeted data examples that can be used to patch the model.
For the demo, we compared three models—LLaMA, OpenAI GPT-4.1-mini, and Gemini Pro—on the ICD-10 coding task using our tool. The probing pipeline correctly identified Gemini Pro as the top performer. For the weaker models, particularly LLaMA, our system can automatically generated 50 targeted synthetic data points that could be used for future fine-tuning to improve performance.
How we built it
- We used the Anthropic Python package to wrap our logic into an MCP tool, and set up the MCP server using Cursor (Claude Desktop hit rate limits).
- For model probing, we designed a custom evaluation dataset and implemented a process to compare model-generated ICD-10 codes against ground truth to compute accuracy.
- For data generation, we built an agentic workflow using Starfish, which powers scalable and customizable generation of synthetic examples based on model errors.
- We kept the architecture modular and lightweight to allow quick iteration and easy extension to other tasks or domains.
Challenges we ran into
- Time constraints limited our ability to implement the full finetuning loop end-to-end.
- Setting up the MCP tool reliably took more effort than expected—ensuring the right sequence of tool calls, handling edge cases, and getting the server to consistently respond required debugging and iteration.
- Designing the model probing system to accurately evaluate ICD-10 predictions involved aligning model output formats and comparing them precisely to ground truth codes.
- Integration with Together.ai for future fine-tuning required setup and experimentation, which we couldn't fully complete during the hackathon window.
Accomplishments that we're proud of
- Built a working MCP pipeline for model probing and patching in just a few hours.
- Successfully compared multiple LLMs and generated targeted fix data automatically.
- Demonstrated a real-world use case in healthcare AI that has meaningful impact.
What we learned
- MCP is a strong abstraction for modular AI tooling—we see huge potential for auto-evaluation and patching workflows in industry.
- LLMs have wildly different performance on ICD 10 coding—probing is essential before deployment and MCP is a good programmatic interface.
- Agentic workflows are powerful tools for data generation but require thoughtful design and guardrails.
What's next for Probing and Patching LLMs for Medical ICD Coding
- Add automated fine-tuning based on generated patch data, completing the full loop: probe model weaknesses, generate targeted examples, and auto-apply fixes through retraining.
- Expand the system into a fully automated feedback loop—where a user can specify the desired model behavior (e.g., "be better at ICD-10 coding"), and the tool probes, diagnoses, generates patch data, and fine-tunes with minimal human input.
- Generalize the pipeline beyond medical coding—what we’ve built is currently tailored for ICD-10 and clinical transcripts, but the same workflow could be applied to any structured LLM task (e.g., code generation, legal tagging, financial classifications).
- Make the tool more configurable and reusable—so it can act as a plug-and-play MCP module for other domains, LLMs, or evaluation tasks.
Built With
- anthropic
- cursor
- python

Log in or sign up for Devpost to join the conversation.