-
-
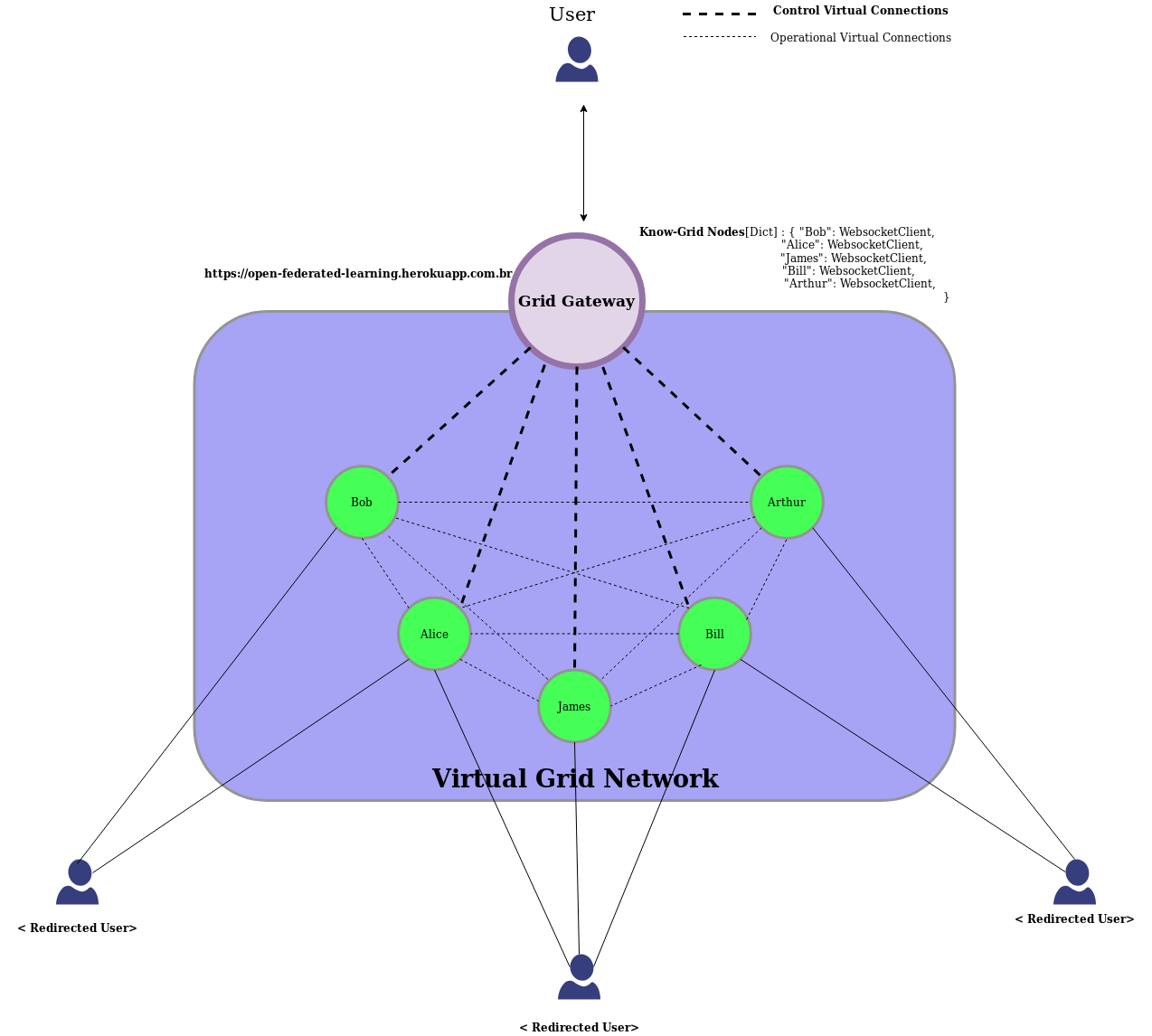
Grid gateway diagram
-
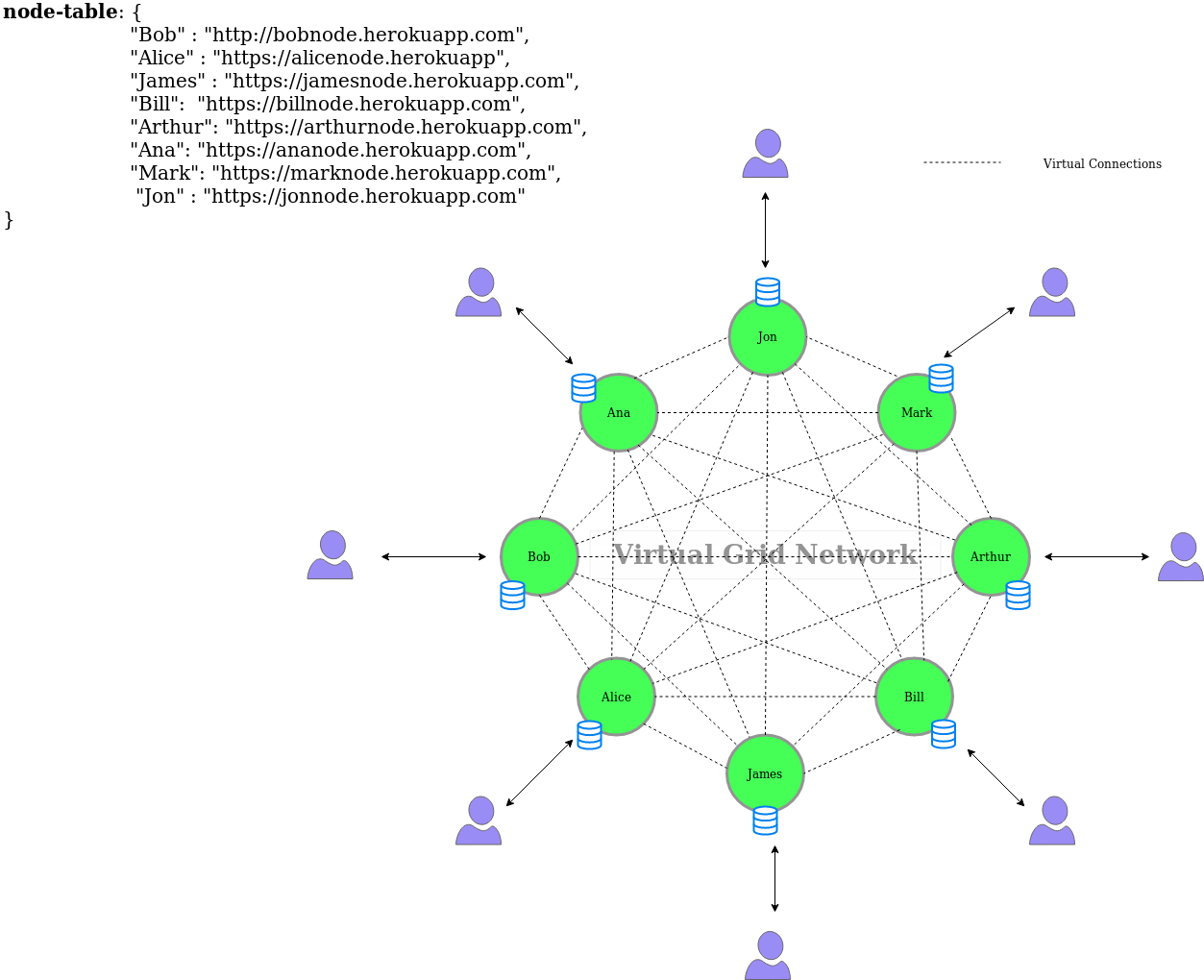
Grid network diagram
-

Logo
-
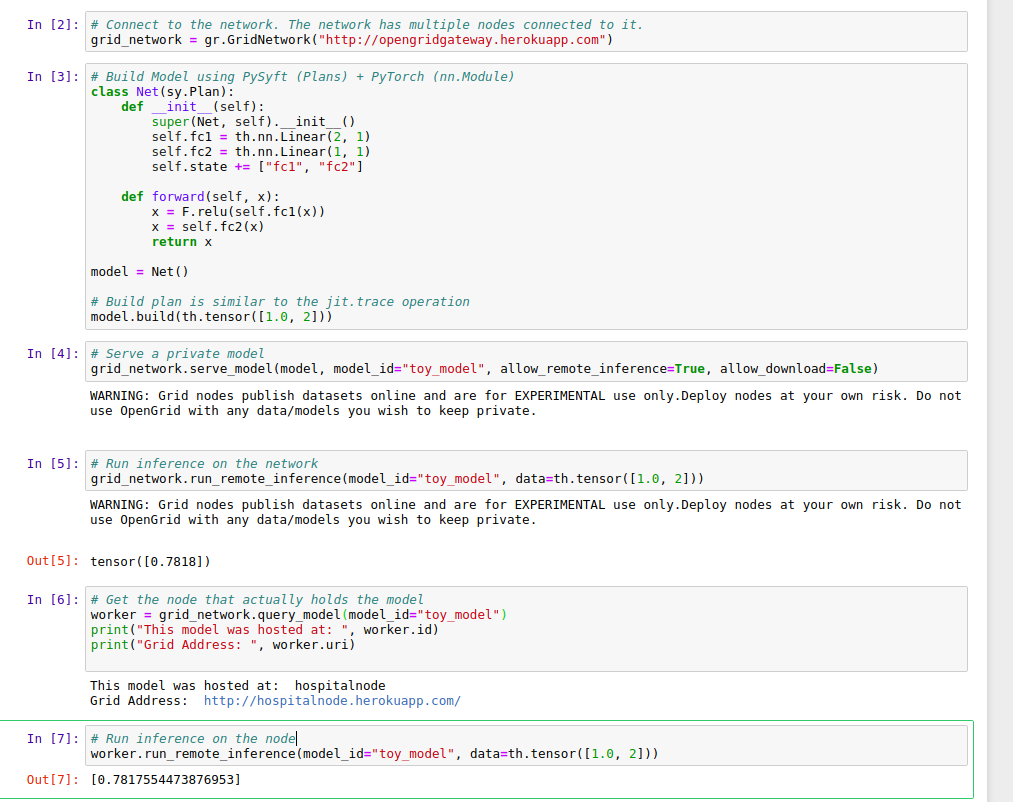
Notebook example of the grid network running
-
Grid node web page visualization. After starting a grid node users can see general information about it through a web page.


Private Machine Learning as a Service using PySyft
Introduction
Context
Data is the driver behind Machine Learning. Researchers and organizations collect massive amounts of data to train their machine learning models. They can then offer the use of such models as a service to outside actors who might not be able to create these models themselves but who still would like to use these models to make predictions on their own data.
For Machine Learning as a Service (MLaaS) to be widely adopted, trust mechanisms are needed. Model owners should be able to deploy its model with the guarantee that it can't be copied or stolen, and control how it is used by external users. While external users might have data that is considered too sensitive to be sent directly to the cloud, so encryption must be available to perform computation securely without compromising the data or the model.
We built a platform on top of PyTorch to perform secure and remote evaluation of sensitive data on real world neural network models.
Presentation
We present here Machine Learning as a Service (MLaaS) and Encrypted MLaaS applications that combine PySyft and Grid.
PySyft is a library that allows us to handle remote tensors, remote models and remote operations on these objects. It also makes possible to encrypt tensors in a way that still allows computation to be run on them, using a technique called Secure Multi-Party Computation (SMPC) which encrypts a variable by splitting it into multiple shares that operate as a private key (Check the references for more details). These building blocks are tightly connected to the native PyTorch concepts, and objects like a simple x = torch.tensor([1, 2]) can be sent to a remote worker bob just by calling x.send(bob), or even encrypted by calling x.share(...) ("share" refers to secret sharing in SMPC).
Grid is a collaborative platform for privacy-preserving machine learning. It provides the notion of remote workers, by allowing any python instance to connect to a distributed network, upload data tensors, send commands, download models, and more. It can be seen as an extension of PySyft to provide a collaborative network platform for data owners and data scientists who can collectively train and share AI models.
These two tools combined allow users to manage computation across non-trusting workers all across the world.
We extended PySyft and Grid in order to add support MLaaS and Encrypted MLaaS. We summarize our contributions by focusing on three different demos:
- Public Serving: a platform to download models and run them locally on private data, illustrated by serving a public GPT-2 model.
- Private Serving: a platform to query sensitive models, which allow benefiting from models inference power while protecting IP and mitigating risks of misuse. We'll serve the GPT-2 model to run predictions on uploaded data, and we validate this input data according to a certain policy.
- Encrypted Serving: A platform to use simultaneously sensitive models on private data. Users encrypt their data using secret sharing and download a model whose weights parameters are also secret shared. They can then evaluate the model over the data without disclosing any sensitive information. We show how to do this on a skin cancer prediction task.
Our Vision
Remote and encrypted computing techniques have made significant breakthroughs in the last years, and the theory behind these concepts is now quite well established. However, it is still incredibly hard for organizations or researchers to use them in AI projects and to benefit from the privacy and scalability guarantees they provide.
We believe that anyone should be able to implement privacy-preserving tools with very little effort. We have created a platform on top of PySyft to manage deployment, encryption, and access to models at scale.
The applications and demos developed for this hackathon were built on the last few weeks by a small group of people, but this was only possible because of the combined efforts from a very active community: OpenMined. OpenMined released several open-source libraries and we feature here Grid and PySyft, which we believe are the first open-source Federated Learning framework for building secure and scalable models.
How does it work?
Architecture
We rely mainly on three concepts: a Worker, a Grid Network and a Grid Gateway.
Worker
A Grid Worker is a type of PySyft worker that is capable of performing remote communication via a Rest API (Flask) or via WebSockets. Workers are composed of two parts: an app and a client.
The app
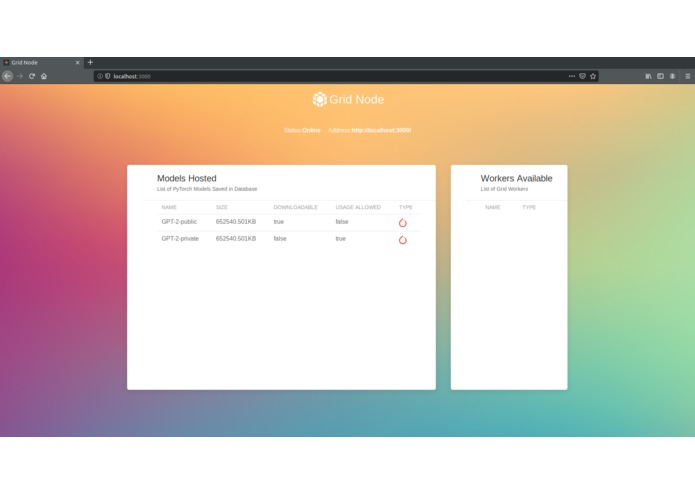
The app is a Flask app that represents a regular server that the client communicates with. We extend this server with the ability to store models and tensors on a PostgreSQL database. The app also presents a webpage where users can check general information about the worker at a glance. Users can: check the status of the worker (online or not), detailed information regarding the models hosted at the node and more.

The client
A client is a wrapper object that implements communication with the app. A user can talk to the client and seamlessly execute Pytorch and Pysyft operations via WebSocket or Rest API requests.
import grid as gr
import torch as th
import syft as sy
hook = sy.TorchHook(th)
worker = gr.WebsocketGridClient(hook, id="bob", addr="https://opengrid.herokuapp.com/")
# Connect to the worker
worker.connect()
# Send a tensor to the worker
th.tensor([1, 2, 3]).send(worker)
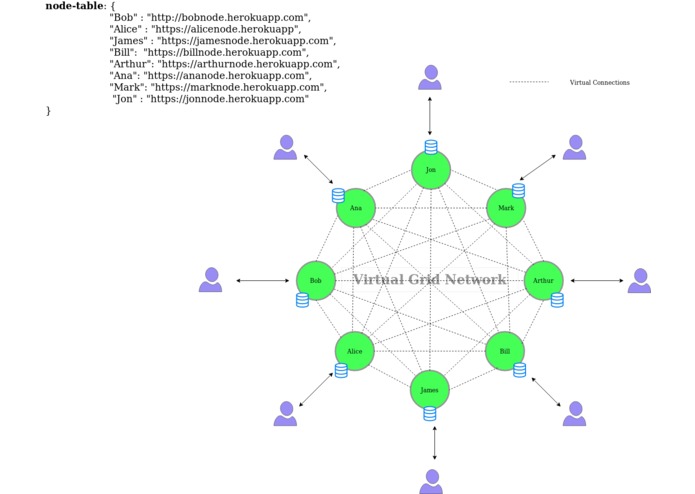
Grid Network
The Grid Network corresponds for a cluster of workers that are all connected to each other.

With this fully distributed and decentralized architecure we can provide fault tolerance in a very transparent way using the Grid Gateway.
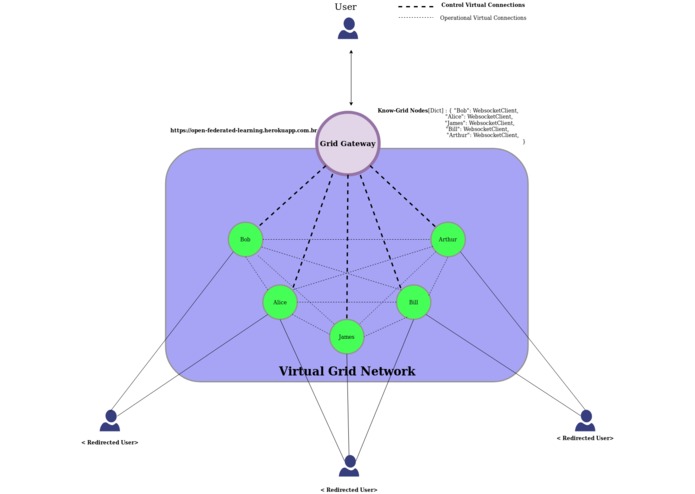
Grid Gateway
This network can be seen by a user as a single interface: the Grid Gateway. The Gateway works as a special DNS component, it will route nodes by queries instead of domain names.
It is important to emphasize: the Grid Gateway will not be able to perform any computation process on the nodes. It can not concentrate or centralize any data or model. It works as a bridge between a user that is outside of the grid network to get data/models that live inside the network.

Here's an example of how the interactions with the gateway look like:
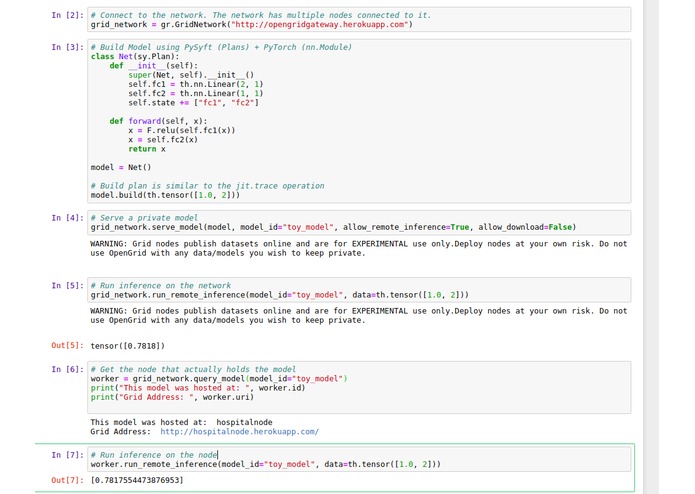
import grid as gr
import torch as th
import syft as sy
hook = sy.TorchHook(th)
# The Gateway acts as a representation of the entire network
gateway = gr.GridNetwork("https://opengrid.herokuapp.com/")
model = th.nn.Linear(1, 1)
traced_model = th.jit.trace(model, th.tensor([1.]))
# We can serve a model on the gateway and it will actually choose
# a worker (or multiple workers, here is where the fault tolerance happens)
# and serve the model there
gateway.serve_model(traced_model, "skin-cancer-grid-model", allow_remote_inference=True, allow_download=False)
# We can then run inference directly from the gateway!! No need to talk to any worker on the network
# or even to know that they exist!!!
gateway.run_remote_inference(model_id="skin-cancer-grid-model", dataset=data)
Model Sharing
In order to send a worker over the wire, it needs to be serializable. We support two ways of implementing models serialization:
- Using Jit modules. We can turn a regular torch model into a jit module. Jit modules use Torchscript.
Torchsript creates serializable and optimizable models from PyTorch code. Any code written in TorchScript can be saved from a Python process and loaded in a process where there is no Python dependency. This facility will allow us to send this model to remote workers. - jit documentation
- Using PySyft Plans. A Plan is intended to store a sequence of Pytorch and PySyft operations, just like a function, but it allows to send this sequence of operations to remote workers and to keep a reference to it. Check the references for more details on Plans.
Encryption
In order to support hosting and querying encrypted models, we rely on PySyft's implementation of SMPC and Plans.
Challenges
Extending PySyft plans to be able to call fetch on remote workers
We had to extend PySyft Plans abstraction in order to support copying models over the wire and also copying encrypted models over the wire. This demanded a lot of hard work on understanding and extending this part of PySyft's codebase to allow such operations.
Part of this work can be seen on this PR: https://github.com/OpenMined/PySyft/pull/2590
Database support
We added database support for the Grid apps, this required a broader understanding of PySyft's serialization module.
Support for sending large models over the wire
In order to host and query the GPT-2 model. We had to add support for sending and receiving streams of data over the wire which to the best of my knowledge has never been done before by the team members.
What we learned
The team working experience during the hackathon was very valuable: we had to organize and divide tasks between teammates, communicate clearly and set up goals and deadlines which certainly made some us better at managing people and resources.
We certainly learned a lot about how Pytorch (especially the Jit modules) and PySyft work so we could extend then correctly.
We had to implement unit tests that involved running multiple threads, remote execution and data being shared constantly and some times asynchronously. This required revisiting fundamental distributed computing concepts in practice.
We also had to think a lot about the user interface and how to make it friendly but yeat generalizable and flexible enough so that people can build their own ideas on top of our solution.
Future Work
We still have many things left out to do, but here are our most important challenges.
First, we want to add to the Grid library the ability to serve encrypted or non-encrypted models at its full potential. A clear next step is to add authentication to Grid. This is already in progress (https://github.com/OpenMined/Grid/pull/295).
Second, we also want to support Federated Learning and Encrypted Federated Learning on it. There has been a huge speed-up on development recently as it was waiting for PySyft to be mature enough to rely on it.
Last, we want to extend the scope of Grid by adding support running it on other devices, like web browsers or Android mobiles.
References
Built With
- flask
- heroku
- postgresql
- pysyft
- python
- pytorch
- pytorch-transformers
- sqlalchemy
- torchscript
- torchvision
- vue.js
- websockets







 Wagner")



Log in or sign up for Devpost to join the conversation.