-
-
Private HAR
Inspiration
The inspiration for Private HAR Scrubber stemmed from a real-life challenge I faced. When needing to share HAR (HTTP Archive) files with external providers for debugging purposes, I encountered the risk of exposing client information that existing scrubbers failed to remove adequately. This critical need for a secure, reliable, and efficient way to sanitize HAR files without compromising sensitive data motivated me to develop a tool that addresses this gap effectively.
What it does
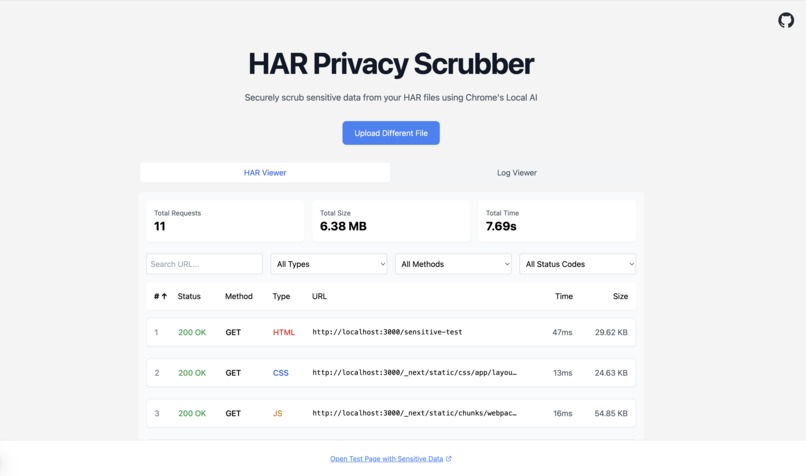
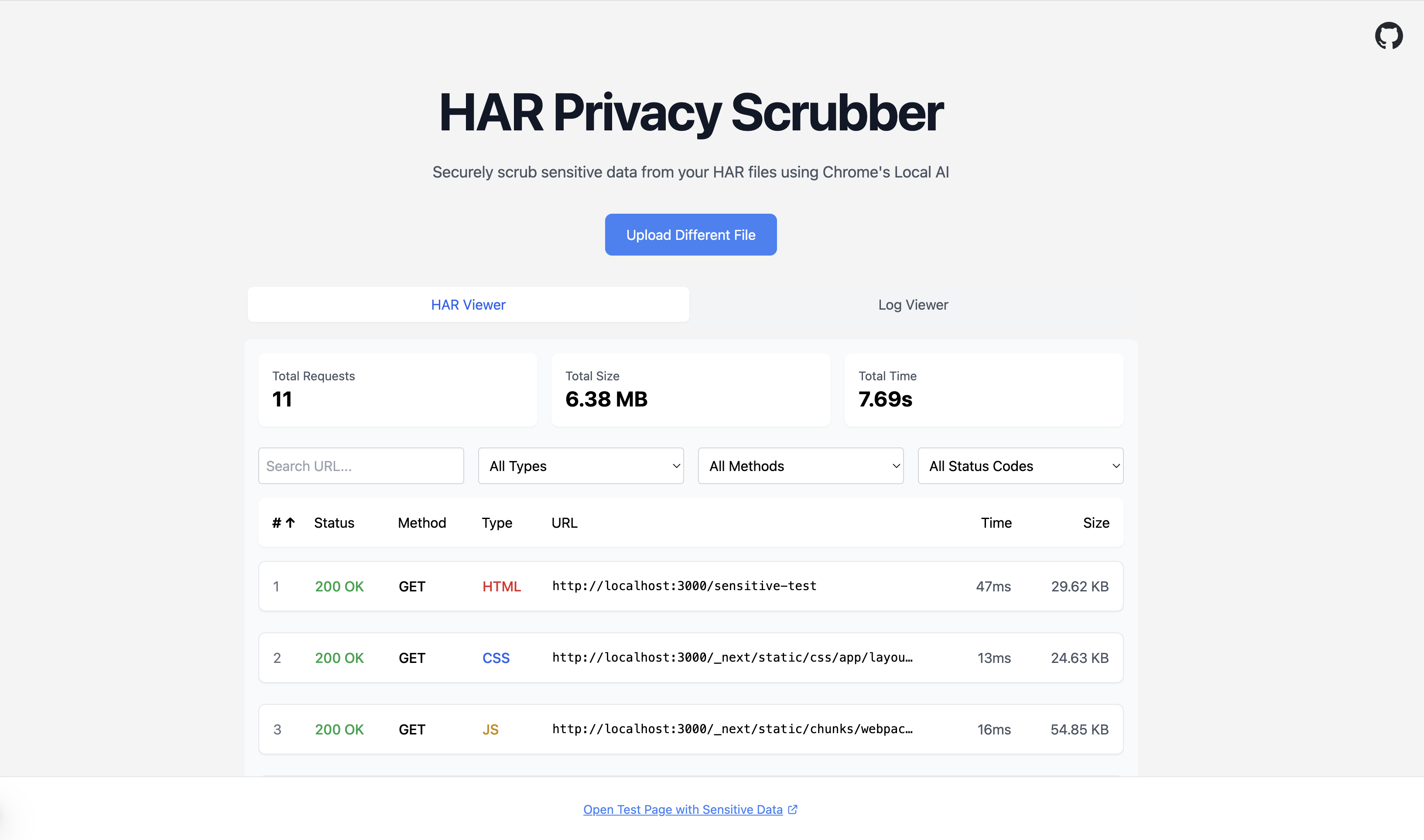
Private HAR Scrubber is a client-side web application that allows users to upload and scrub sensitive information from HAR files entirely within their browser. Utilizing Chrome's built-in AI capabilities—specifically, the Summarize Text and Prompt (Chat) APIs—the tool intelligently identifies and removes personal identifiable information (PII) and sensitive business data from both the response and, to some extent, the request sections of HAR files. Additionally, I incorporated a feature where the AI model summarizes what each network request does, providing users with valuable insights into their HAR file contents. All processing happens locally, ensuring that your data never leaves your machine. The project is open source, inviting community engagement and collaboration.
How we built it
I built the application using Next.js and TypeScript, focusing on client-side processing to maintain user privacy. By leveraging Web Workers, I offloaded intensive tasks from the main thread, enhancing performance within the browser. The tool integrates two key AI APIs available in Chrome: Summarize Text and Prompt (Chat). These APIs enable the application to perform intelligent scrubbing and summarization without relying on external servers. My approach required careful optimization to ensure smooth handling of large HAR files and efficient AI processing within the browser environment.
Challenges we ran into
AI Model Limitations with JSONs: The local AI model struggled with processing JSON content effectively. I had to find creative workarounds and, in some cases, compromise on the capabilities I initially wanted the tool to have. This involved simplifying the data structures or pre-processing the JSON to make it more digestible for the AI.
Performance Constraints: The AI model operated slower than expected for certain tasks, which necessitated strategic decisions about where to integrate AI processing versus traditional scrubbing methods. I aimed to balance performance with the intelligent capabilities provided by the AI.
Limited Context Handling: I was surprised by the limited context window of the local AI model, which affected its ability to process large amounts of data at once. This limitation required me to implement chunking mechanisms and manage context carefully to avoid errors, hoping for improvements in future model updates.
Accomplishments that we're proud of
Intuitive and User-Friendly Design: I'm proud of creating a feature that is both intuitive and friendly for users. The application's interface allows for easy HAR file uploading and provides clear progress indications during the scrubbing process.
Enhanced Performance with Web Workers: By incorporating Web Workers, I significantly improved the application's performance, allowing it to handle larger files and more complex processing without freezing the browser or degrading the user experience.
Network Request Summarization: Adding the ability for the AI model to summarize what each network request does not only enhances the tool's utility but also provides users with deeper insights into their HAR files.
Robust Logging Capabilities: I developed comprehensive logging within the application, which aids in monitoring the processing pipeline and debugging issues. This feature enhances transparency and reliability.
What we learned
Limitations of Local AI Models: Throughout the development process, I gained a deep understanding of the constraints associated with local AI models. I learned the importance of setting realistic expectations and adapting my approach when initial plans exceeded the model's capabilities.
Iterative Problem-Solving: I often had to scrap initial project ideas due to the AI model's limitations, which taught me the value of iterative development and flexibility. Each iteration brought new insights into how to better work within the model's constraints.
Optimizing Client-Side Applications: Developing a performance-intensive application that runs entirely in the browser required me to hone my skills in optimizing client-side code and managing resources effectively.
What's next for Private HAR
Expanding AI Capabilities: I plan to enhance the tool's ability to scrub sensitive data from the request sections of HAR files, not just the responses. This will involve improving how the AI model handles different data formats and possibly integrating more advanced AI techniques.
Improving JSON Handling: I intend to find better ways to work with JSON data, perhaps by developing custom parsers or pre-processors that can bridge the gap between complex JSON structures and the AI model's processing abilities.
Performance Enhancements: Continuing to optimize the application to run efficiently on devices with varying capabilities is a priority, ensuring accessibility and ease of use for all users.
Future AI Model Improvements: I hope to see future enhancements in local AI models, such as increased context windows and better error messaging, which would improve the tool's effectiveness and reliability.
Built With
- next
- react
- typescript

Log in or sign up for Devpost to join the conversation.