-
-
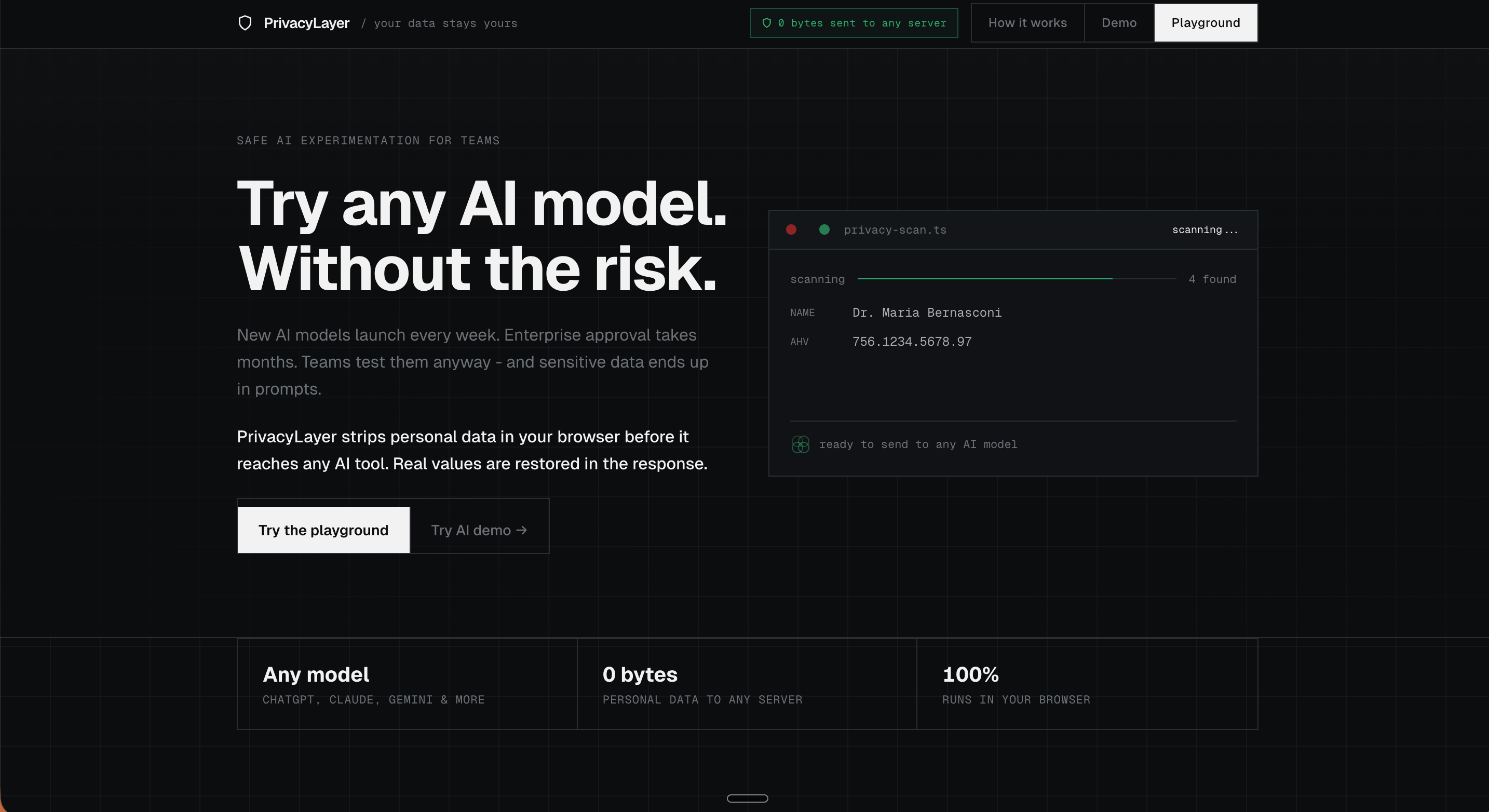
Landing Page
-
Chrome Extension
-
redaction
-
redaction2
Inspiration
I am the AI Lead of a major Swiss enterprise. My job is to help teams adopt AI faster and to implement new solutions.
Last year I watched a colleague paste a full patient record - name, insurance number, IBAN, AHV number - into ChatGPT to draft a response letter. He was not being careless. He was doing his job. The AI tool was faster than any alternative. The personal data is now on a US server. We have no idea what happens to it next.
This is not a one-off. It has a name:
Shadow AI. Every 10 days, a new model launches. IT approval takes 6 months. Teams do not wait - they paste real documents into unapproved tools because the tools work. In Swiss healthcare, legal, finance, and HR departments, this happens every single day.
Three things make this a crisis right now:
The procurement gap is widening. Claude Opus 4.6, GPT Codex 5.4, Gemini, Mistral, Llama - each one requires a new procurement cycle. By the time approval comes, the model is already outdated. Teams skip the process.
Swiss and European law is explicit. Under nDSG (Swiss data protection), GDPR, and EU AI Act Article 10, personal data cannot be processed by unauthorized foreign servers. AHV numbers, medical records, IBANs - none of this should reach a US data center. But it does, every day.
Existing tools solve the wrong problem. Every privacy tool I found required you to upload your document to their server to redact it. That is the problem, not the solution.
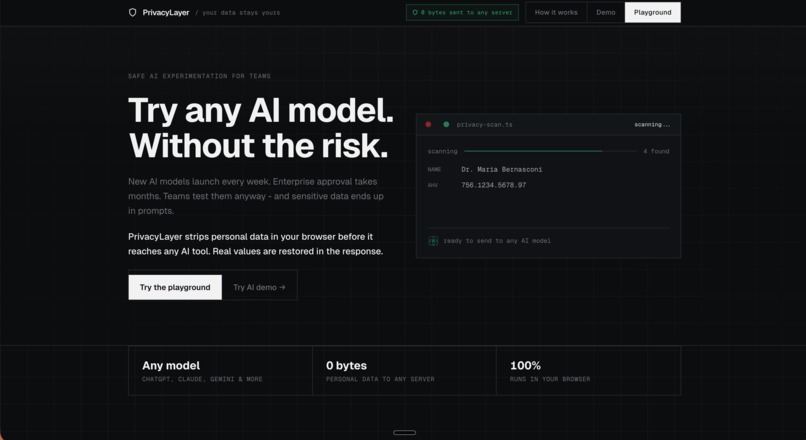
PrivacyLayer was built from a simple question: what if the AI never saw the real data in the first place?
What it does
PrivacyLayer has two surfaces for the same job: keep personal data out of AI prompts without disrupting the workflow.
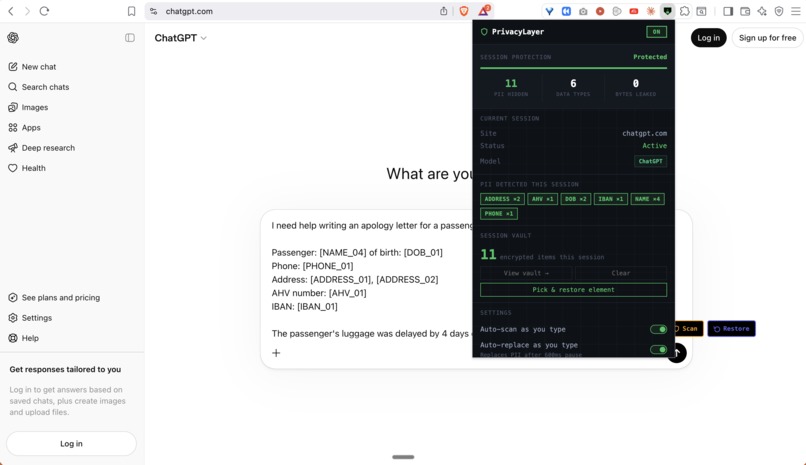
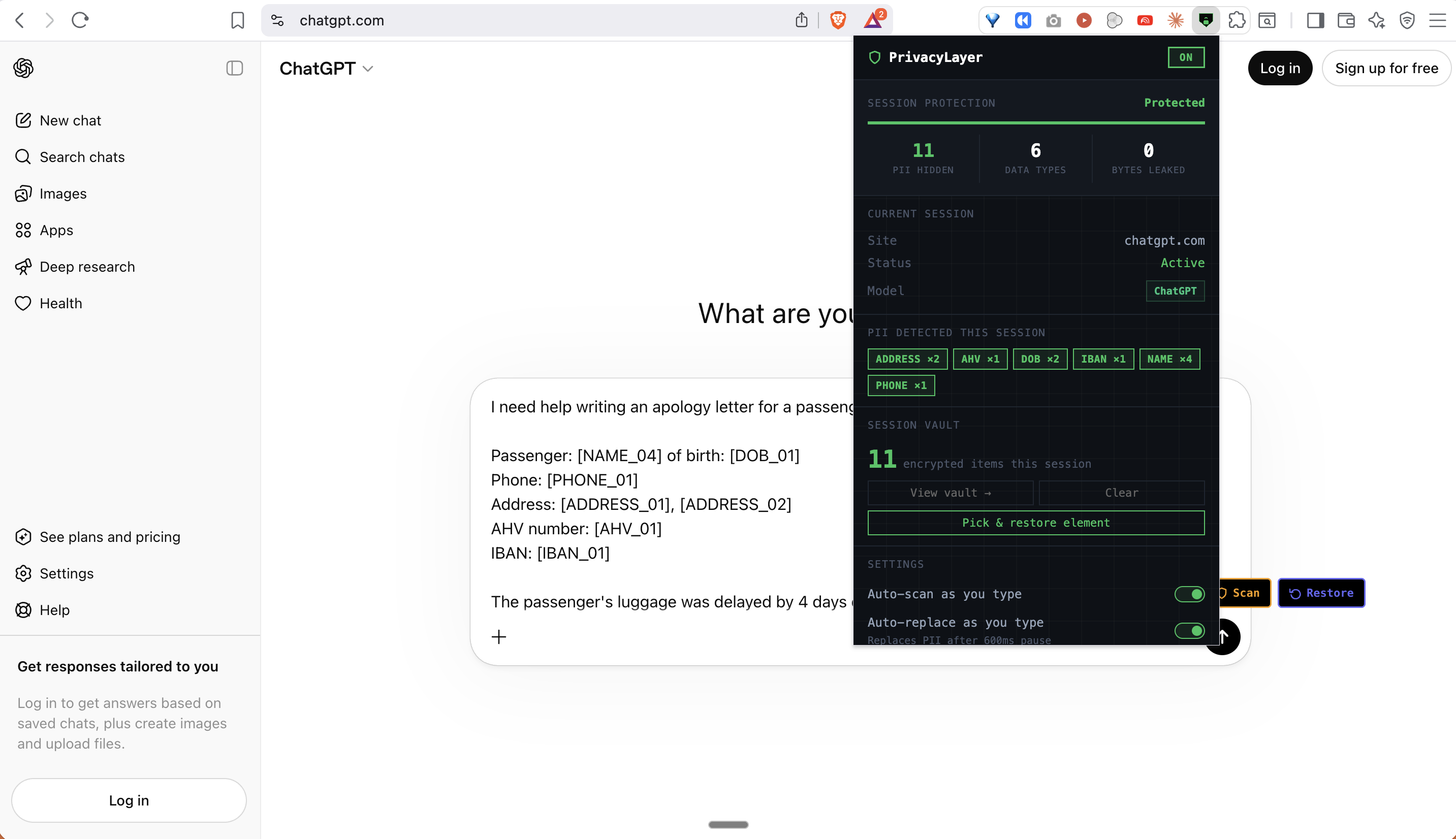
Surface 1: Chrome Extension — works inside live AI conversations
This is the demo. This is the differentiator no other submission has.
Install the extension. Open ChatGPT, Claude, Gemini, or Perplexity. Paste any text containing personal data. Click Protect. The extension detects and replaces every personal identifier with a safe placeholder token before the message is sent. The AI receives only tokens. It responds using tokens. The extension automatically restores real values in the response - highlighted in green - so you read a natural, complete answer.
The AI model never sees a single real name, date of birth, or account number. You never change your workflow.
This is the difference. Other tools redact a PDF before you upload it. PrivacyLayer intercepts the data inside the actual AI conversation - in ChatGPT's input field, in Claude's editor, in Gemini's compose box. No workflow change. No export step. No separate tool.
Supported platforms: ChatGPT · Claude · Gemini · Perplexity (+ generic fallback for any textarea or contenteditable)
Detected automatically:
- Full names — multilingual: German, French, Italian, Swiss, Turkish, Polish, Scandinavian (500+ first-name dictionary, catches names without titles)
- Email addresses
- Phone numbers — Swiss +41 format and international
- AHV/AVS numbers — 756.XXXX.XXXX.XX format with check digit
- Swiss IBANs — CH prefix
- Dates of birth
- Street addresses
- Passport and ID numbers
- Credit card numbers — with Luhn validation
- Insurance and patient IDs
- Tax IDs
- IP addresses
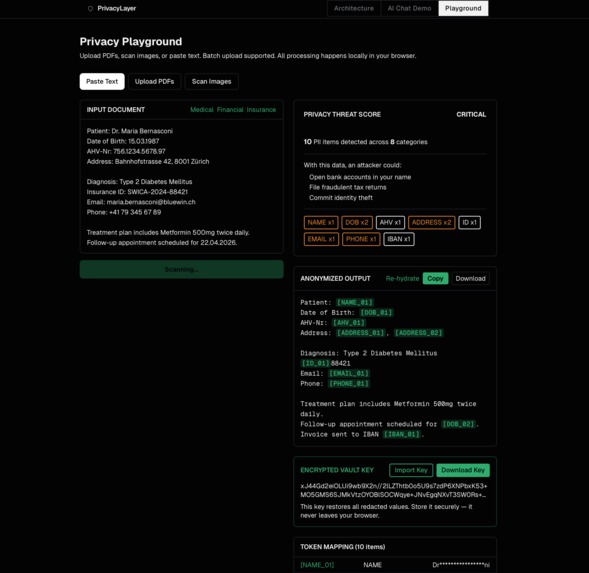
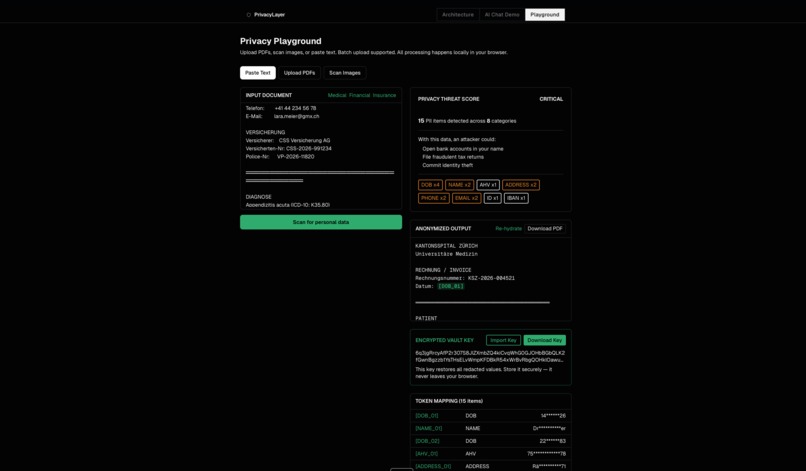
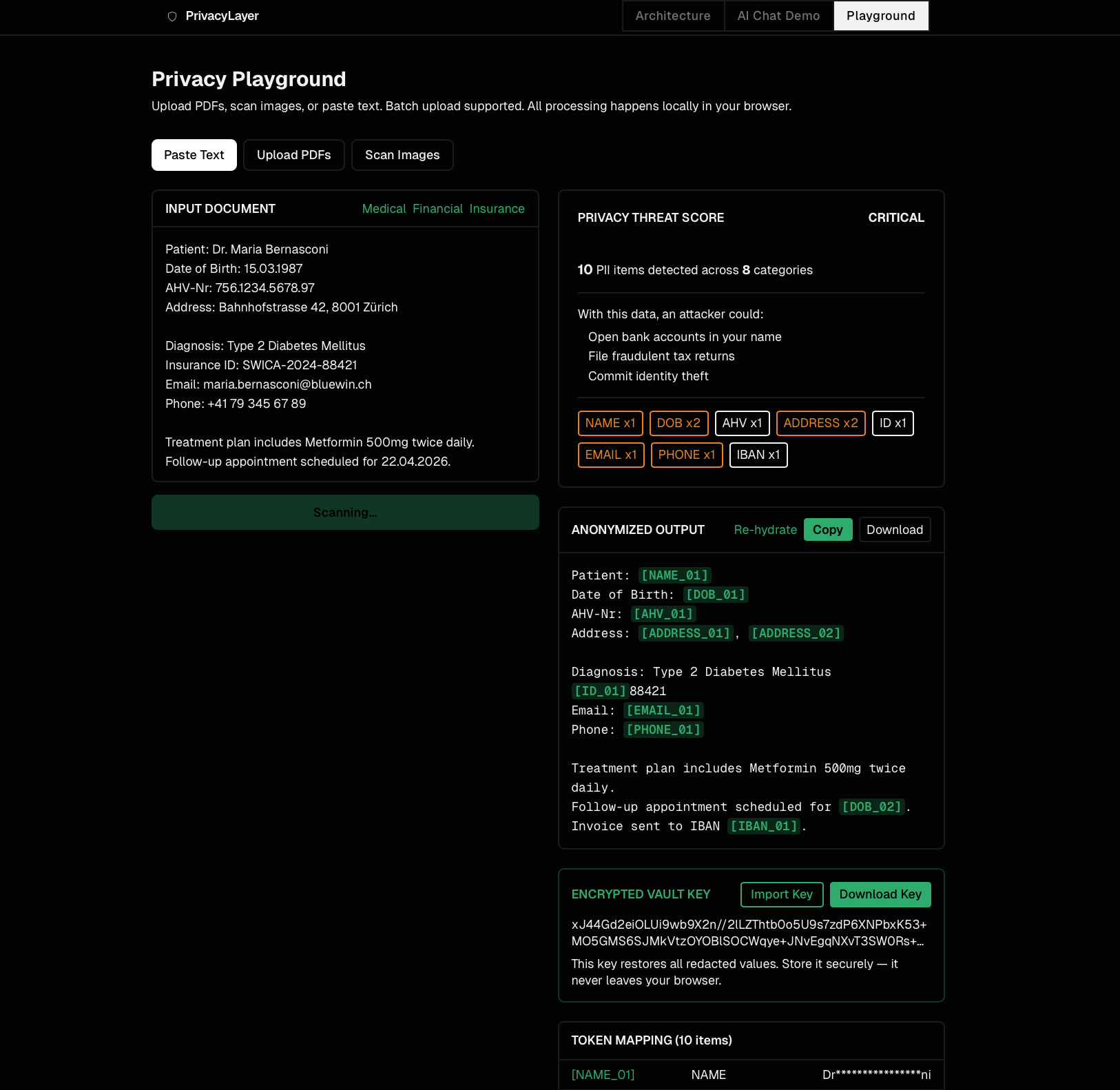
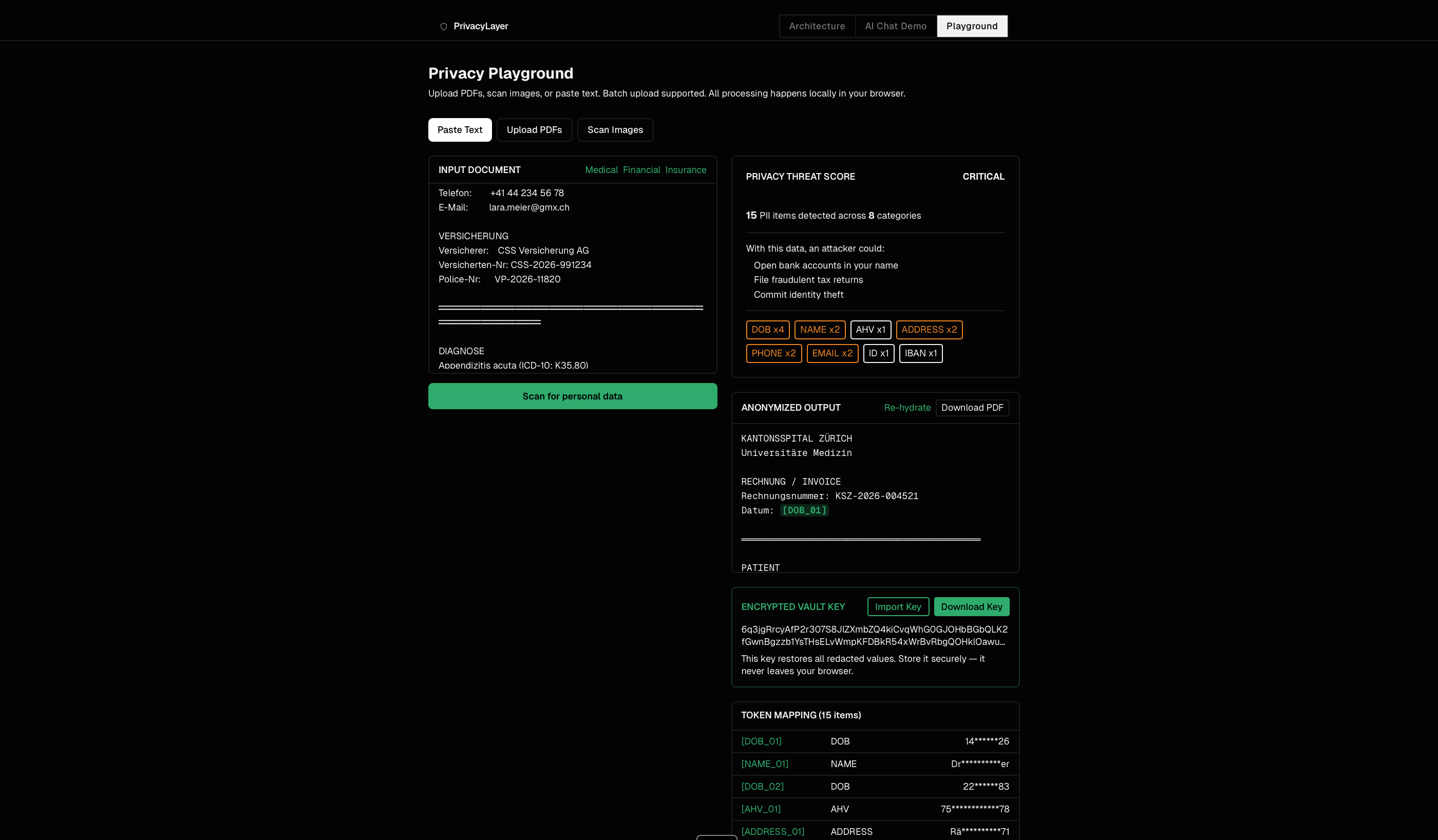
Surface 2: Web Playground - full document workflow
Upload PDFs, paste text, or photograph a physical letter. The same detection engine runs locally. Download a redacted PDF. Export an AES-256-GCM encrypted vault key. Import it later to restore all original values.
| Feature | PrivacyLayer | Other tools |
|---|---|---|
| Works inside live AI chat | Yes — Chrome extension | No |
| Processing location | 100% browser, zero uploads | Server-side or browser |
| Auto-restores real values in AI response | Yes — highlighted in green | No |
| Supports ChatGPT, Claude, Gemini, Perplexity | Yes — all four | No |
| BERT NER + generative AI risk summary | Yes — opt-in, browser-based | Partial |
| Reversible encryption | Yes — AES-256-GCM vault | Partial |
| Verifiable — open DevTools and check | Yes — zero outbound requests | Varies |
Open DevTools right now. Network tab. Zero personal data transmitted. This is not a promise — it is an architectural guarantee. There is no backend endpoint that receives personal data.
How we built it
Chrome Extension (Manifest V3)
- TypeScript + Vite build pipeline, produces Chrome and Edge packages from one codebase
- Content script injects a Protect button into the AI platform's input area using site-specific DOM selectors
- Background service worker stores the per-tab token vault in
chrome.storage.session- survives service worker restarts, cleared on tab close - Debounced MutationObserver (350ms) watches AI response elements as they stream in, replaces tokens with real values, marks each DOM node with
data-pl-hydratedto prevent double-processing requestAnimationFrameloop repositions the Protect button as the page layout shifts (handles SPA navigation in ChatGPT, Claude)- URL change detection resets vault and badge state between conversations
Detection engine - two-pass hybrid
Pass 1: Regex (instant, deterministic)
50+ patterns with risk classification (critical / high / medium / low). Each pattern type has explicit priority so overlapping detections resolve correctly - a Swiss AHV number is never misclassified as a phone number.
Pass 2: BERT NER (AI, opt-in, browser-based)
Xenova/bert-base-multilingual-cased-ner-hrl runs via @xenova/transformers (WebAssembly). Catches names that regex misses — plain names without titles, contextual references across 10+ languages. Downloaded once (~150MB quantized ONNX), cached in IndexedDB permanently. Opt-in to avoid interfering with the baseline detection flow.
Generative AI risk summary
LaMini-Flan-T5-77M (77MB) generates a human-readable risk narrative from the detected entity types: "This document exposes 2 names and 1 AHV number — sufficient for identity theft and fraudulent tax filing." Runs locally. Falls back to a deterministic template if the model has not yet loaded.
Encryption
Web Crypto API - AES-256-GCM with PBKDF2 key derivation (100,000 iterations, SHA-256). No library dependency. Runs natively in the browser. Vault is session-scoped in the extension; exportable as a key file in the playground.
Document processing
pdfjs-dist— client-side PDF extraction withhasEOLdetection for proper multi-page line breakspdf-lib— redacted PDF output with token overlaystesseract.js— browser-based OCR for scanned documents (English, German, French)
Challenges we ran into
Live token restoration during AI streaming. AI responses arrive character by character. The original MutationObserver fired hundreds of times per second — visible lag, race conditions, partial restorations. Solution: 350ms debounce + data-pl-hydrated flag on each processed DOM node. Each element is processed exactly once.
ContentEditable vs textarea. ChatGPT uses a React-controlled contenteditable div. Setting .innerText directly breaks React's synthetic event system — the input silently stops responding. The only reliable fix: document.execCommand("insertText") to trigger proper React state updates, with a fallback for browsers where execCommand is deprecated.
Reading contenteditable without creating gaps. innerText on a div with multiple <p> children returns \n\n between each paragraph. Re-inserting tokenized text with \n\n creates blank lines that were not in the original. Fix: walk <p> tags manually and join with single \n.
Multilingual name detection without titles. Swiss documents mix German, French, Italian, and English — sometimes in the same sentence. "Mehmet Yilmaz" and "Agnieszka Kowalski" need to be caught without any title prefix. Solution: 500+ first-name dictionary spanning 12 language families, with surname-continuation heuristic.
Surname-only leakage. If "Maria Bernasconi" is tokenized as NAME_01, and the AI responds with "Ms. Bernasconi" — the surname alone leaks. Solution: second pass extracts surname components from already-tokenized full names, matches them independently.
SPA navigation breaking state. ChatGPT reloads its input area on new conversation without a full page reload. URL change detection + 500ms polling resets badge, isAnonymized state, and vault reference between conversations.
Service worker crash loop. Unhandled exceptions in the background service worker cause Chrome to restart it silently, showing "Updating" indefinitely. Solution: try/catch on every message handler, with graceful fallback responses that never expose the crash to the user.
Accomplishments that we're proud of
The only solution that works inside live AI conversations. Not before. Not after. During. The Protect button lives inside ChatGPT's interface. The AI responds with tokens. The real names come back in green. That is a complete, end-to-end privacy layer for the actual workflow people use every day.
Zero server-side data processing — architecturally enforced. There is no API endpoint that accepts personal data. Open DevTools, go to the Network tab, paste a document full of sensitive information, click Protect, watch the requests. Nothing leaves. This is not a policy claim. It is a code guarantee anyone can verify.
52 passing tests across the full detection pipeline. PII detection accuracy, anonymization correctness, vault deduplication, rehydration fidelity, edge cases (surnames alone, multilingual names, overlapping patterns). 52/52 green before any user interaction.
Swiss-specific detection built in from day one. AHV/AVS numbers (756.XXXX.XXXX.XX with check digit validation), CH-prefix IBANs, +41 phone formats. Designed for the Zurich regulatory context — nDSG, GDPR, EU AI Act Article 10. Not retrofitted.
BERT NER + generative AI running in the browser. Two AI models loaded via WebAssembly - a multilingual BERT for named entity recognition and a Flan-T5 for generative risk summaries. Both cached permanently after first download. Both verified to produce zero outbound requests.
Deployed, functional, and usable today. The Chrome extension installs and works. The web playground processes real documents. The Chrome Web Store submission is in progress.
What we learned
The workflow matters more than the feature. Every privacy tool we looked at added friction - upload here, download there, import this key. The Chrome extension removes the friction entirely. The user does exactly what they were already doing, and the data never leaves.
Shadow AI is not a security failure - it is a procurement failure. The people pasting sensitive documents into ChatGPT are not reckless. They are productive. The answer is not better policies - it is a layer that removes the risk from the workflow without removing the workflow.
Client-side AI is genuinely viable now. Loading a 150MB BERT model into a browser tab via WebAssembly, caching it in IndexedDB, and running multilingual inference with no server - this was considered impractical two years ago. It is now a reasonable user experience with a good progress indicator.
Streaming responses are harder than static text. Building on top of a live AI response that renders token by token required more careful state management than processing a complete document. Race conditions, partial matches, double-restorations — each one required an explicit fix.
Privacy is felt, not just understood. Showing users "an attacker could file a fraudulent tax return in your name" - generated by an AI model from the actual detected data - converts abstract compliance into something that lands. The generative risk summary changed how people react to the scan results.
What's next
- Chrome Web Store release — submission in progress
- Microsoft Edge Add-ons store — build script already produces the Edge package
- Copilot and You.com support — extending the extension to AI platforms accessible without login
- SDK for developers — one line wraps any Vercel AI SDK model:
wrapLanguageModel(model, privacyLayer()) - Context-aware detection — catching implicit PII: "my brother in Zürich," "she mentioned taking insulin daily"
- Smaller NER model — distilled model under 30MB for faster first load
Built With
chrome-extension manifest-v3 typescript vite next-js tailwind-css xenova-transformers bert-ner flan-t5 web-crypto-api aes-256-gcm pbkdf2 pdf-js pdf-lib tesseract-js indexeddb web-assembly vercel
Built With
- aes-256-gcm
- css
- next.js
- pdf-lib
- pdf.js
- tailwind
- tesseract.js
- typescript
- vercel
- webcrypto


Log in or sign up for Devpost to join the conversation.