-
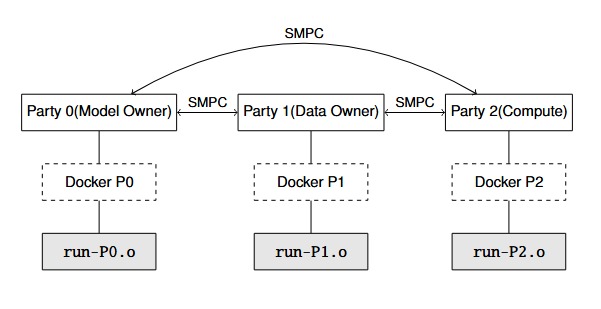
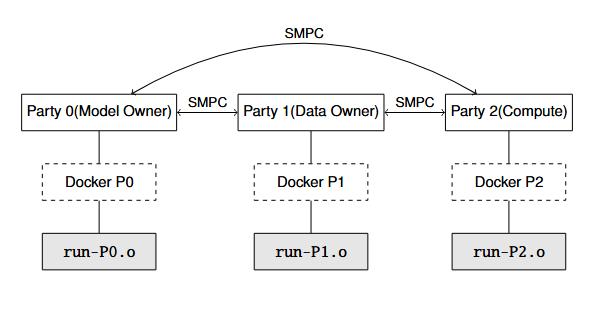
System Architecture
-
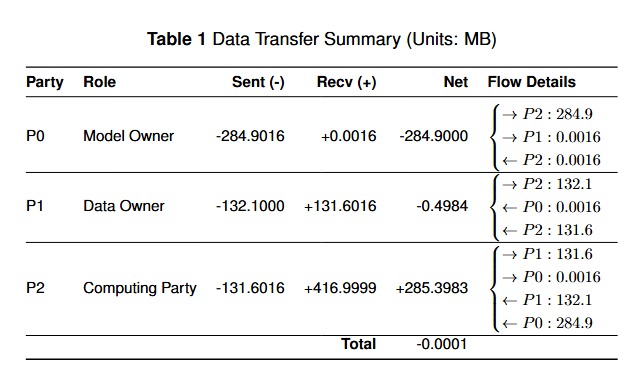
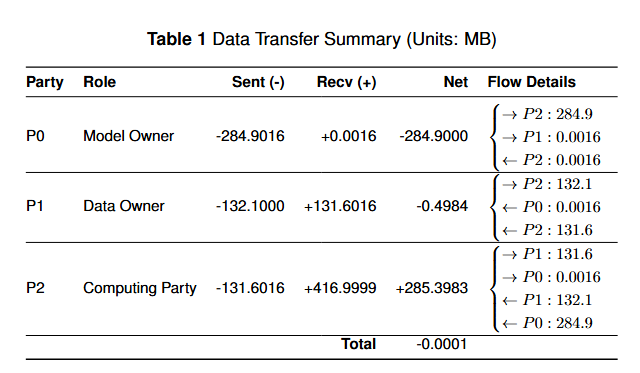
Data Transfer Summary
Secure Multiparty Computation (SMPC) Inference Evaluation Report
Bang An, Ke Xin, Yingtai Xu, Yifeng Zhou
Abstract
This project implements a 3-party secure multiparty computation (SMPC) system for performing privacy-preserving inference using a pre-trained convolutional neural network (VGG16). The implementation leverages the HPMPC framework and integrates Docker-based container isolation for secure multi-party orchestration.
1. Overview
Secure multiparty computation (SMPC) is a cryptographic technique enabling multiple parties to jointly compute a function over their inputs while keeping those inputs private. This paradigm is especially relevant in privacy-sensitive applications such as federated machine learning and collaborative inference.
In this project, we focus on the problem of secure neural network inference, where model weights and input data are separately held by different parties. Our objective is to design a three-party SMPC system that can jointly evaluate a deep convolutional neural network (VGG16) without revealing the model or input to any single party.
We leverage the HPMPC framework and deploy the protocol across Docker containers to enforce both computational and network-level isolation. Our system implements additive secret sharing under a semi-honest security model and applies it to the CIFAR-10 classification task. We report inference correctness, communication overhead, and runtime metrics in a reproducible environment.
2. Method
2.1 3-party private inference protocol
We implemented and deployed a secure 3-party private inference protocol based on the HPMPC framework, executing a pre-trained VGG16 model on CIFAR-10 test images under additive secret sharing. Each party (P0, P1, P2) plays a distinct role:
- P0: Model Owner (holds secret shares of the model weights)
- P1: Data Owner (holds secret shares of the test dataset)
- P2: Participates in computation to ensure non-collusion and protocol correctness
Our results were generated using a reduced dataset of 40 CIFAR-10 test images to demonstrate protocol functionality and efficiency.
2.2 Architecture Overview
- Framework: SMC with framework
hpmpc - Model: VGG16 trained on CIFAR-10, exported via Pygeon
- Execution: Each party runs a separate Docker container (p0, p1, p2)
- Synchronization: Model weights are split via secret sharing and exchanged securely
- Secure Inference: Executed layer-by-layer via precompiled circuit representation in C++
2.3 Security Model
- Semi-honest adversaries
- All three parties are non-colluding
- Communication is protected via Docker network isolation
- Data remains encrypted/shared at all times during execution
System Diagram
+---------+ +---------+ +---------+
| Party 0 | <--> | Party 1 | <--> | Party 2 |
+---------+ +---------+ +---------+
| | |
Docker P0 Docker P1 Docker P2
run-P0.o run-P1.o run-P2.o
3. Requirments
3.1 Repository Setup
Clone the project repository and initialize all required submodules:
git clone https://github.com/chart21/hpmpc.git
cd hpmpc
git submodule update --init --recursive
There is a re-develop and modified version: https://github.com/xajhab/hpmpc-cinephoto.git
3.2 Docker Environment
Pull the pre-built Docker image containing all required dependencies:
docker pull xajhab/cinephoto-club:v1
docker pull xajhab/cinephoto-club
Launch three containers for the three parties (P0, P1, P2) respectively. Each container should be run in a separate terminal.
make clean
docker run -it --network host --cap-add=NET_ADMIN ` -v "${PWD}:/hpmpc" ` --name p0 hpmpc
docker run -it --network host --cap-add=NET_ADMIN ` -v "${PWD}:/hpmpc" ` --name p1 hpmpc
docker run -it --network host --cap-add=NET_ADMIN ` -v "${PWD}:/hpmpc" ` --name p2 hpmpc
If the containers are stopped, they can be resumed using:
docker start -ai p0
docker start -ai p1
docker start -ai p2
3.3 Compilation Instructions
Optionally clean previous builds:
make clean
Compile the binaries inside each container as follows:
In container p0:
make -j PARTY=0 FUNCTION_IDENTIFIER=74 PROTOCOL=5 MODELOWNER=P_0 DATAOWNER=P_1 NUM_INPUTS=40 BITLENGTH=32 DATTYPE=32
In container p1:
make -j PARTY=1 FUNCTION_IDENTIFIER=74 PROTOCOL=5 MODELOWNER=P_0 DATAOWNER=P_1 NUM_INPUTS=40 BITLENGTH=32 DATTYPE=32
In container p2:
make -j PARTY=2 FUNCTION_IDENTIFIER=74 PROTOCOL=5 MODELOWNER=P_0 DATAOWNER=P_1 NUM_INPUTS=40 BITLENGTH=32 DATTYPE=32
3.4 Execution
Run the compiled executables to initiate the protocol. Each command should be issued in its respective container terminal.
./executables/run-P0.o
./executables/run-P1.o
./executables/run-P2.o
4. Application
4.1 Execution Summary
For Party P0, the output log includes the following initialization and execution highlights:
Mode: test
Save Directory: nn/Pygeon/models/pretrained
Data Directory: nn/Pygeon/data/datasets
Pretrained Model: vgg16_cifar_standard.bin
Image File: CIFAR-10_standard_test_images.bin
Label File: CIFAR-10_standard_test_labels.bin
accuracy(40 images): 57.50%
These logs indicate the use of a pre-trained VGG16 model applied to a small test batch, resulting in 57.5% accuracy over 40 samples, i.e., 23 correctly predicted examples. The setup is consistent across all three parties.
4.2 Timing Measurements
Time measured to initialize program: 19.60s
Time measured to perform computation clock: 9.15s
Time measured to perform computation getTime: 9.23s
Time measured to perform computation chrono: 9.23s
These measurements show the following phases:
- Initialization Time (~19.6s): Includes container boot, secure channel setup, circuit parsing, and share exchange.
- Inference Computation Time (~9.2s): Stable across multiple timing methods, validating low jitter.
4.3. Layer-wise Communication and Latency
Each layer in the model is logged with detailed statistics. The format is:
--NN_STATS (Individual)-- ID: <layer_id> <type> MB SENT: <x> MB RECEIVED: <y> ms LIVE: <latency>
Where:
ID: Layer indexTYPE: Type of operation (e.g., CONV2D, ACTIVATION, AVGPOOL2D, FLATTEN, LINEAR)MB SENT/RECEIVED: Amount of data exchanged with other partiesms LIVE: Time spent computing this layer on the local party
Example:
ID: 0 CONV2D MB SENT:10.4858 MB RECEIVED:0.0000 ms LIVE: 96.9390
This denotes that layer 0 is a convolutional layer, which sent ~10.49 MB of data, received none (as P0), and consumed ~97 ms of local compute time.
4.4. Aggregated Statistics
Aggregated performance metrics provide a global view of resource consumption:
--NN_STATS (Aggregated)-- CONV2D MB SENT:44.2368 MB RECEIVED:0.0000 ms LIVE: 6869.0740
--NN_STATS (Aggregated)-- ACTIVATION MB SENT:175.8899 MB RECEIVED:0.0000 ms LIVE: 1212.3940
--NN_STATS (Aggregated)-- AVGPOOL2D MB SENT:4.9971 MB RECEIVED:0.0000 ms LIVE: 29.5870
--NN_STATS (Aggregated)-- FLATTEN MB SENT:0.0000 MB RECEIVED:0.0000 ms LIVE: 0.0900
--NN_STATS (Aggregated)-- LINEAR MB SENT:0.0835 MB RECEIVED:0.0000 ms LIVE: 3.5760
Observations:
- CONV2D layers dominate computation time (>6.8 seconds)
- ACTIVATION layers generate the highest communication volume (>175 MB)
- LINEAR and FLATTEN layers are negligible in both latency and data exchange
These figures align with expectations: convolutional layers are compute-intensive, and activation functions often require reshare or re-encryption steps in SMPC.
5. Secure Multiparty Protocol Verification
To verify the correctness and integrity of our secure three-party computation architecture, we analyzed the runtime logs from each participant (P0, P1, and P2). The logs provide direct evidence that the protocol implements a full-fledged privacy-preserving inference pipeline under the HPMPC framework.
First, the system successfully establishes peer-to-peer connectivity across the three parties. As indicated in P1’s log segment, “All parties connected successfully, starting protocol and timer!”, the circuit setup and inter-party synchronization phase completes without error. This demonstrates the system’s ability to initiate a secure computation session that adheres to the three-party MPC communication model.
Second, each party reports having received only a secret share of the model parameters, rather than the complete model in plaintext. P1 and P2 explicitly log the message “Received Secret Share of Model Parameters”, confirming the implementation of additive secret sharing. Consequently, no individual party obtains a full view of the model, preserving confidentiality across the protocol.
Third, we investigate the data transfer during the three-party Secure Multiparty Computation (SMPC). It shows the data sent and received by each party, including the Model Owner (P0), Data Owner (P1), and Computing Party (P2). The net data flow indicates that the overall communication is balanced, with the Computing Party (P2) receiving more data and sending less. No significant data leakage is observed, as each party only communicates with its relevant counterparts. These communication records demonstrate the execution of privacy-preserving circuit evaluation without centralized aggregation.
Finally, the system outputs correct predictions over the provided dataset, achieving an accuracy of 57.50% on the CIFAR-10 evaluation batch. The presence of complete timing statistics (getTime, chrono, clock) and detailed per-layer communication and execution logs (as shown in the --NN_STATS entries) provide further operational transparency.
Together, these findings provide conclusive evidence that the deployed system adheres to the semantics of a secure three-party protocol. The protocol achieves both data confidentiality and collaborative inference across multiple parties, thus fulfilling the privacy guarantees and system architecture goals specified in the project design.
6. Conclusion
Our prototype system has successfully fulfilled the goals set by the Science Hackathon:
- Correct execution of 3-party SMPC inference pipeline
- Integration of PyTorch-trained VGG16 model with C++ SMPC runtime (HPMPC)
- Verified end-to-end performance with concrete accuracy and timing results
- Collected communication and timing metrics per layer, suitable for profiling and reporting



Log in or sign up for Devpost to join the conversation.