About the Project
Privacy policies are the contract that defines what happens to your data but they're written to be ignored. The average policy is 4,000+ words of legal language that still leaves you unsure whether the app sells your location or keeps your data forever.
I built Privacy Policy Analyzer to answer the questions that actually matter: Does this app share my data? Can I delete it? How long do they keep it?
How I Built It
Full-stack Python app with a three-stage LLM pipeline behind a Streamlit dashboard.
Pipeline (analyzer.py)
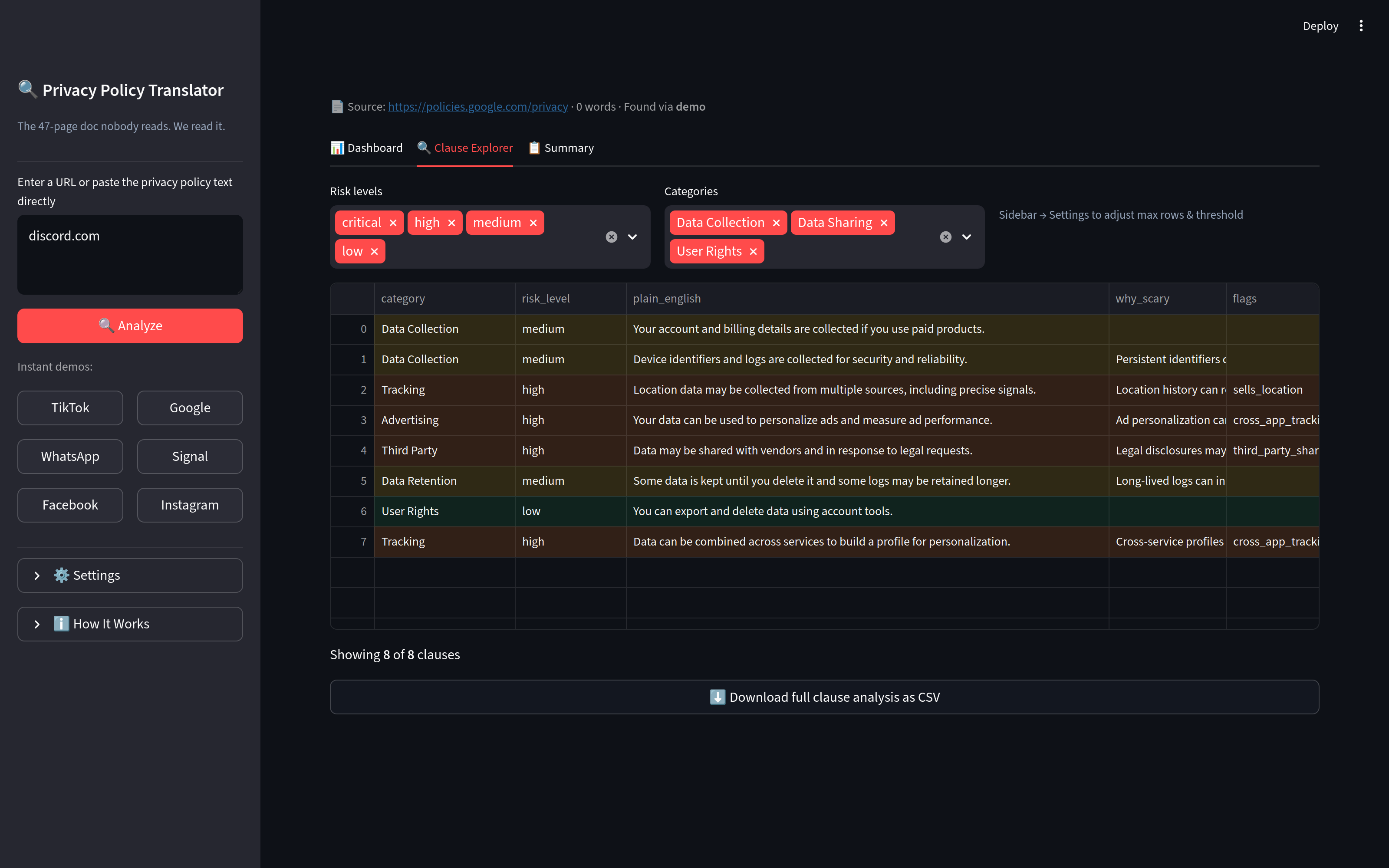
- Clause extraction: policy text is chunked and sent to the model to extract distinct data practices as structured JSON
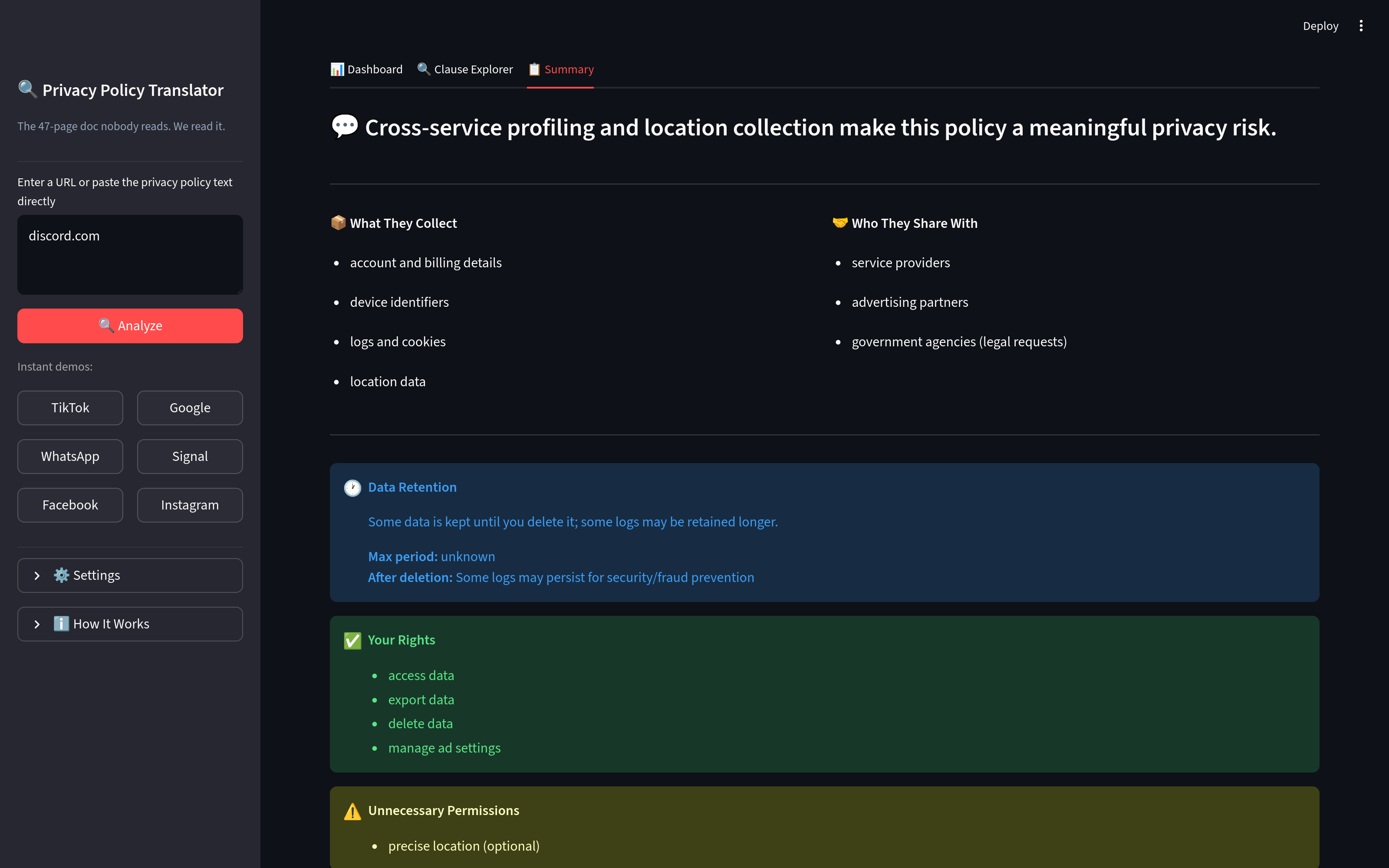
- Risk analysis: clauses are batched and each batch is analyzed for risk level, plain-English translation, and user action
- Summary generation: the full clause list is synthesized into an executive summary
OpenRouter is the primary provider with Ollama as a local fallback.
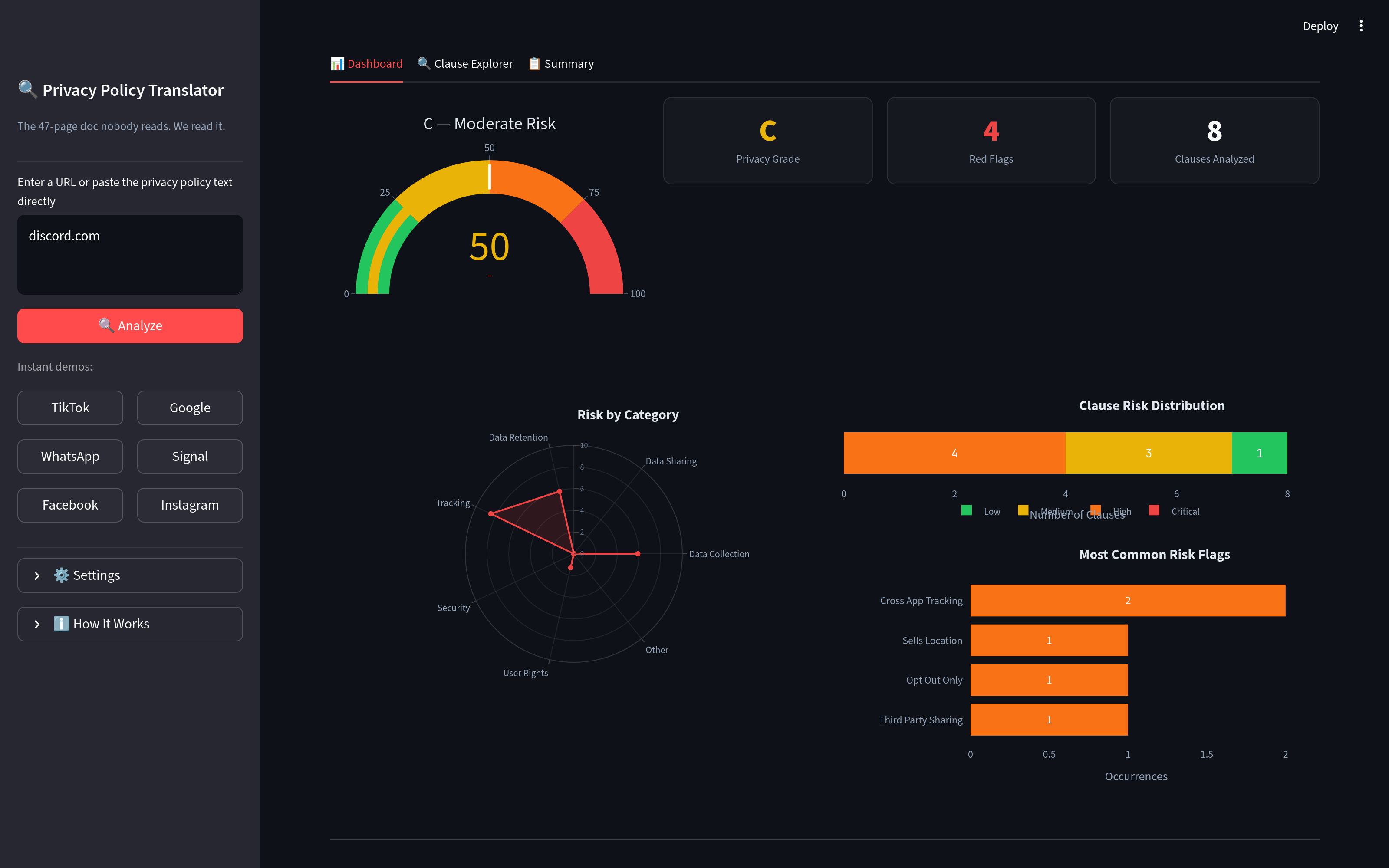
Scoring (scorer.py) Deterministic, no LLM involved. Clause risk levels are weighted and aggregated into a 0-100 score, letter grade, and category breakdown across 10 privacy dimensions. Keeps the dashboard stable even when model outputs vary.
Reliability
- Robust JSON parsing with 3 fallback strategies so one bad model response never crashes the app
- Precomputed demo JSON for TikTok, Google, WhatsApp, and Signal so the product is always demoable regardless of API conditions
What I Learned
- Prompting is only part of reliability. The real wins come from defensive engineering and graceful degradation
- Small batches beat large prompts. Sending 6 clauses at a time produced significantly better risk analysis than one large call
- Post-processing beats over-prompting. Normalizing categories deterministically after the LLM responds improved consistency without sacrificing chart quality

Log in or sign up for Devpost to join the conversation.